
 Périphériques technologiques
IA
Le modèle mondial brille ! Le réalisme de ces plus de 20 données de scénarios de conduite autonome est incroyable...
Périphériques technologiques
IA
Le modèle mondial brille ! Le réalisme de ces plus de 20 données de scénarios de conduite autonome est incroyable...
Le modèle mondial brille ! Le réalisme de ces plus de 20 données de scénarios de conduite autonome est incroyable...

Pensez-vous que c'est une vidéo de conduite autonome ennuyeuse ?

Le sens original de ce contenu n'a pas besoin d'être modifié, il doit être réécrit en chinois
Aucune seule image n'est "réelle".

Différentes conditions routières, diverses conditions météorologiques, plus de 20 situations peuvent être simulées, et l'effet est comme la réalité.

Le modèle mondial démontre une fois de plus son rôle puissant ! Cette fois, LeCun l'a transmis avec enthousiasme après l'avoir vu

L'effet ci-dessus est apporté par la dernière version de GAIA-1.
Il a une échelle de 9 milliards de paramètres et est formé avec 4700 heuresde vidéos de conduite pour obtenir l'effet de générer des vidéos de conduite autonome en saisissant des vidéos, du texte ou des opérations.
L'avantage le plus direct est la capacité de mieux prédire les événements futurs. Il peut simuler plus de 20 scénarios, améliorant ainsi encore la sécurité de la conduite autonome et réduisant les coûts

L'équipe créative a déclaré que cela changerait les règles du jeu de la conduite autonome !
Comment GAIA-1 est-il implémenté ? En fait, nous avons déjà présenté en détail le GAIA-1 développé par l'équipe Wayve dans Autonomous Driving Daily : un modèle mondial génératif pour la conduite autonome. Si cela vous intéresse, vous pouvez vous rendre sur notre compte officiel pour lire le contenu pertinent !
Plus l'échelle est grande, meilleur est l'effet
GAIA-1 est un modèle mondial génératif multimodal qui peut comprendre et générer des expressions du monde en intégrant plusieurs méthodes de perception telles que la vision, l'audition et le langage. Ce modèle utilise des algorithmes d’apprentissage profond pour apprendre et raisonner sur la structure et les lois du monde à partir d’une grande quantité de données. L'objectif de GAIA-1 est de simuler la perception humaine et les capacités cognitives pour mieux comprendre et interagir avec le monde. Ses applications sont nombreuses dans de nombreux domaines, notamment la conduite autonome, la robotique et la réalité virtuelle. Grâce à une formation et une optimisation continues, GAIA-1 continuera d'évoluer et de s'améliorer, devenant un modèle mondial plus intelligent et plus complet.
Il utilise la vidéo, le texte et les actions comme entrée et génère des vidéos de scènes de conduite réalistes, tout en permettant la conduite autonome. Comportement et scène du véhicule les caractéristiques sont finement contrôlées
et les vidéos peuvent être générées avec uniquement des invites textuelles.

Le principe du modèle est similaire au principe des grands modèles de langage, c'est-à-dire prédire le prochain jeton
Le modèle peut utiliser la représentation de quantification vectorielle pour distinguer les images vidéo, puis prédire les scènes futures, qui sont converties en prédiction le suivant dans le jeton de séquence. Le modèle de diffusion est ensuite utilisé pour générer des vidéos de haute qualité à partir de l’espace linguistique du modèle mondial.
Les étapes spécifiques sont les suivantes :
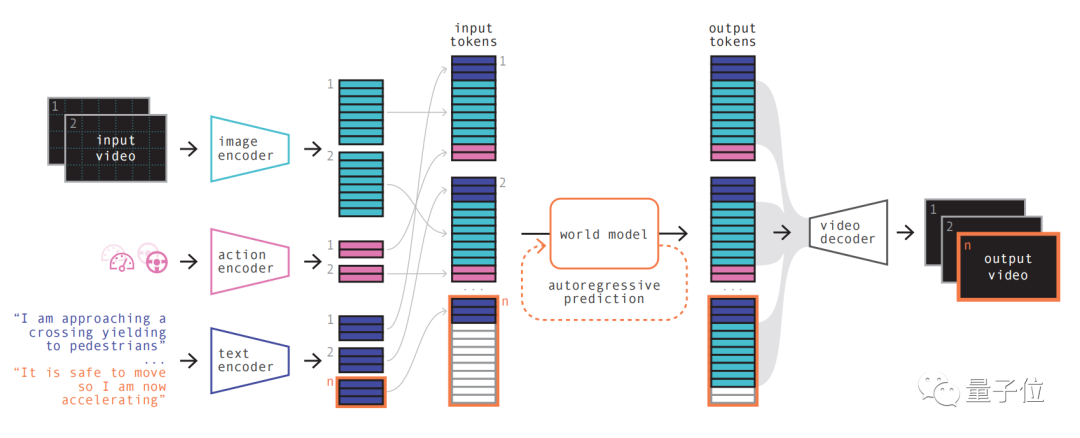
La première étape est simple à comprendre, qui consiste à recoder, organiser et combiner diverses entrées.
Différentes entrées peuvent être projetées dans une représentation partagée en utilisant des encodeurs spécialisés pour coder diverses entrées. Les encodeurs texte et vidéo séparent et intègrent l'entrée, tandis que les représentations opérationnelles sont projetées individuellement dans une représentation partagée
Ces représentations codées sont temporellement cohérentes
Après les permutations, la partie clé World Model entre en scène.
En tant que transformateur autorégressif, il a la capacité de prédire le prochain ensemble de jetons d'image dans la séquence. Il prend non seulement en compte les jetons d'image précédents, mais prend également en compte simultanément les informations contextuelles du texte et des actions
Le contenu généré par le modèle maintient non seulement la cohérence avec l'image, mais également avec le texte et les actions prédits
Présentation de l'équipe, GAIA La taille du modèle mondial en -1 est 6,5 milliards de paramètres, qui a été entraîné sur 64 A100 pendant 15 jours.
En utilisant un décodeur vidéo et un modèle de diffusion vidéo, ces jetons sont finalement reconvertis en vidéo
Cette étape concerne la qualité sémantique, la précision de l'image et la cohérence temporelle de la vidéo.
Le décodeur vidéo deGAIA-1 a une échelle de 2,6 milliards de paramètres et a été formé à l’aide de 32 A100 pendant 15 jours.
Il convient de mentionner que GAIA-1 est non seulement similaire en principe au grand modèle de langage, mais montre également les caractéristiques de à mesure que l'échelle du modèle s'agrandit, la qualité de la génération s'améliore.

L'équipe a comparé la première version publiée précédemment en juin avec le dernier effet
Ce dernier est 480 fois plus grand que le premier.
Vous pouvez intuitivement voir que les détails et la résolution de la vidéo ont été considérablement améliorés.

En termes d'applications pratiques, GAIA-1 a également eu un impact. Son équipe créative a déclaré que cela changerait les règles de la conduite autonome.

Les raisons viennent de trois aspects :
- Sécurité
- Données de formation complètes
- Scénario à longue traîne
Tout d'abord, en termes de sécurité, le modèle mondial peut simuler le futur et donner à l'IA le capacité à prendre ses propres décisions, ce qui est très important pour la sécurité de la conduite autonome.
Deuxièmement, les données d'entraînement sont également très critiques pour la conduite autonome. Les données générées sont plus sécurisées, moins chères et infiniment évolutives.
L'IA générative peut résoudre un défi majeur auquel est confrontée la conduite autonome : les scénarios à longue traîne. Il peut gérer davantage de cas extrêmes, comme rencontrer des piétons traversant la route par temps de brouillard. Cela améliorera encore les performances de la conduite autonome
Qui est Wayve ?
GAIA-1 vient de la startup britannique de conduite autonome Wayve.
Wayve a été fondée en 2017. Parmi les investisseurs figurent Microsoftetc., et sa valorisation a atteint Licorne.
Les fondateurs sont les PDG actuels Alex Kendall et Amar Shah (la page de leadership du site officiel de l'entreprise ne contient plus d'informations. Tous deux sont diplômés de l'Université de Cambridge et possèdent un doctorat en apprentissage automatique

Sur la feuille de route technique). , comme Tesla, Wayve prône une solution purement visuelle utilisant des caméras, abandonnant très tôt les cartes de haute précision et s'engageant résolument dans la voie de la « perception instantanée ».
Il y a peu, un autre grand modèle LINGO-1 sorti par l'équipe a également fait sensation.
Ce modèle autonome peut générer des explications en temps réel pendant la conduite, améliorant ainsi encore l'interprétabilité du modèle
En mars de cette année, Bill Gates a également fait un essai routier dans la voiture autonome de Wayve.

Adresse papier : https://arxiv.org/abs/2309.17080

Le contenu qui doit être réécrit est : Lien original : https://mp.weixin.qq. com/ s/bwTDovx9-UArk5lx5pZPag
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1393
1393
 52
1207
24
52
1207
24

 Comment résoudre le problème de la longue traîne dans les scénarios de conduite autonome ?
Jun 02, 2024 pm 02:44 PM
Comment résoudre le problème de la longue traîne dans les scénarios de conduite autonome ?
Jun 02, 2024 pm 02:44 PM
Hier, lors de l'entretien, on m'a demandé si j'avais posé des questions à longue traîne, j'ai donc pensé faire un bref résumé. Le problème à longue traîne de la conduite autonome fait référence aux cas extrêmes dans les véhicules autonomes, c'est-à-dire à des scénarios possibles avec une faible probabilité d'occurrence. Le problème perçu de la longue traîne est l’une des principales raisons limitant actuellement le domaine de conception opérationnelle des véhicules autonomes intelligents à véhicule unique. L'architecture sous-jacente et la plupart des problèmes techniques de la conduite autonome ont été résolus, et les 5 % restants des problèmes à longue traîne sont progressivement devenus la clé pour restreindre le développement de la conduite autonome. Ces problèmes incluent une variété de scénarios fragmentés, de situations extrêmes et de comportements humains imprévisibles. La « longue traîne » des scénarios limites dans la conduite autonome fait référence aux cas limites dans les véhicules autonomes (VA). Les cas limites sont des scénarios possibles avec une faible probabilité d'occurrence. ces événements rares
 Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Imaginez un modèle d'intelligence artificielle qui non seulement a la capacité de surpasser l'informatique traditionnelle, mais qui permet également d'obtenir des performances plus efficaces à moindre coût. Ce n'est pas de la science-fiction, DeepSeek-V2[1], le modèle MoE open source le plus puissant au monde est ici. DeepSeek-V2 est un puissant mélange de modèle de langage d'experts (MoE) présentant les caractéristiques d'une formation économique et d'une inférence efficace. Il est constitué de 236B paramètres, dont 21B servent à activer chaque marqueur. Par rapport à DeepSeek67B, DeepSeek-V2 offre des performances plus élevées, tout en économisant 42,5 % des coûts de formation, en réduisant le cache KV de 93,3 % et en augmentant le débit de génération maximal à 5,76 fois. DeepSeek est une entreprise explorant l'intelligence artificielle générale
 L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L’IA change effectivement les mathématiques. Récemment, Tao Zhexuan, qui a prêté une attention particulière à cette question, a transmis le dernier numéro du « Bulletin de l'American Mathematical Society » (Bulletin de l'American Mathematical Society). En se concentrant sur le thème « Les machines changeront-elles les mathématiques ? », de nombreux mathématiciens ont exprimé leurs opinions. L'ensemble du processus a été plein d'étincelles, intense et passionnant. L'auteur dispose d'une équipe solide, comprenant Akshay Venkatesh, lauréat de la médaille Fields, le mathématicien chinois Zheng Lejun, l'informaticien de l'Université de New York Ernest Davis et de nombreux autres universitaires bien connus du secteur. Le monde de l’IA a radicalement changé. Vous savez, bon nombre de ces articles ont été soumis il y a un an.
 Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Les performances de JAX, promu par Google, ont dépassé celles de Pytorch et TensorFlow lors de récents tests de référence, se classant au premier rang sur 7 indicateurs. Et le test n’a pas été fait sur le TPU présentant les meilleures performances JAX. Bien que parmi les développeurs, Pytorch soit toujours plus populaire que Tensorflow. Mais à l’avenir, des modèles plus volumineux seront peut-être formés et exécutés sur la base de la plate-forme JAX. Modèles Récemment, l'équipe Keras a comparé trois backends (TensorFlow, JAX, PyTorch) avec l'implémentation native de PyTorch et Keras2 avec TensorFlow. Premièrement, ils sélectionnent un ensemble de
 Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas entre officiellement dans l’ère des robots électriques ! Hier, l'Atlas hydraulique s'est retiré "en larmes" de la scène de l'histoire. Aujourd'hui, Boston Dynamics a annoncé que l'Atlas électrique était au travail. Il semble que dans le domaine des robots humanoïdes commerciaux, Boston Dynamics soit déterminé à concurrencer Tesla. Après la sortie de la nouvelle vidéo, elle a déjà été visionnée par plus d’un million de personnes en seulement dix heures. Les personnes âgées partent et de nouveaux rôles apparaissent. C'est une nécessité historique. Il ne fait aucun doute que cette année est l’année explosive des robots humanoïdes. Les internautes ont commenté : Les progrès des robots ont fait ressembler la cérémonie d'ouverture de cette année à des êtres humains, et le degré de liberté est bien plus grand que celui des humains. Mais n'est-ce vraiment pas un film d'horreur ? Au début de la vidéo, Atlas est allongé calmement sur le sol, apparemment sur le dos. Ce qui suit est à couper le souffle
 KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
Plus tôt ce mois-ci, des chercheurs du MIT et d'autres institutions ont proposé une alternative très prometteuse au MLP – KAN. KAN surpasse MLP en termes de précision et d’interprétabilité. Et il peut surpasser le MLP fonctionnant avec un plus grand nombre de paramètres avec un très petit nombre de paramètres. Par exemple, les auteurs ont déclaré avoir utilisé KAN pour reproduire les résultats de DeepMind avec un réseau plus petit et un degré d'automatisation plus élevé. Plus précisément, le MLP de DeepMind compte environ 300 000 paramètres, tandis que le KAN n'en compte qu'environ 200. KAN a une base mathématique solide comme MLP est basé sur le théorème d'approximation universelle, tandis que KAN est basé sur le théorème de représentation de Kolmogorov-Arnold. Comme le montre la figure ci-dessous, KAN a
 Parlons des systèmes de conduite autonome de bout en bout et de nouvelle génération, ainsi que de quelques malentendus sur la conduite autonome de bout en bout ?
Apr 15, 2024 pm 04:13 PM
Parlons des systèmes de conduite autonome de bout en bout et de nouvelle génération, ainsi que de quelques malentendus sur la conduite autonome de bout en bout ?
Apr 15, 2024 pm 04:13 PM
Au cours du mois dernier, pour des raisons bien connues, j'ai eu des échanges très intensifs avec divers professeurs et camarades de classe du secteur. Un sujet inévitable dans l'échange est naturellement le populaire Tesla FSDV12 de bout en bout. Je voudrais profiter de cette occasion pour trier certaines de mes pensées et opinions en ce moment pour votre référence et votre discussion. Comment définir un système de conduite autonome de bout en bout et quels problèmes devraient être résolus de bout en bout ? Selon la définition la plus traditionnelle, un système de bout en bout fait référence à un système qui saisit les informations brutes des capteurs et génère directement les variables pertinentes pour la tâche. Par exemple, en reconnaissance d'images, CNN peut être appelé de bout en bout par rapport à la méthode traditionnelle d'extraction de caractéristiques + classificateur. Dans les tâches de conduite autonome, saisir les données de divers capteurs (caméra/LiDAR
 FisheyeDetNet : le premier algorithme de détection de cible basé sur une caméra fisheye
Apr 26, 2024 am 11:37 AM
FisheyeDetNet : le premier algorithme de détection de cible basé sur une caméra fisheye
Apr 26, 2024 am 11:37 AM
La détection de cibles est un problème relativement mature dans les systèmes de conduite autonome, parmi lesquels la détection des piétons est l'un des premiers algorithmes à être déployés. Des recherches très complètes ont été menées dans la plupart des articles. Cependant, la perception de la distance à l’aide de caméras fisheye pour une vue panoramique est relativement moins étudiée. En raison de la distorsion radiale importante, la représentation standard du cadre de délimitation est difficile à mettre en œuvre dans les caméras fisheye. Pour alléger la description ci-dessus, nous explorons les conceptions étendues de boîtes englobantes, d'ellipses et de polygones généraux dans des représentations polaires/angulaires et définissons une métrique de segmentation d'instance mIOU pour analyser ces représentations. Le modèle fisheyeDetNet proposé avec une forme polygonale surpasse les autres modèles et atteint simultanément 49,5 % de mAP sur l'ensemble de données de la caméra fisheye Valeo pour la conduite autonome.
