
 Périphériques technologiques
IA
Transformateur multimodal : pour une détection d'objets 3D rapide et robuste
Périphériques technologiques
IA
Transformateur multimodal : pour une détection d'objets 3D rapide et robuste
Transformateur multimodal : pour une détection d'objets 3D rapide et robuste


Actuellement, les véhicules autonomes sont équipés de divers capteurs de collecte d'informations, tels que le lidar, le radar à ondes millimétriques et les capteurs de caméra. Du point de vue actuel, une variété de capteurs ont montré de grandes perspectives de développement dans les tâches de perception de la conduite autonome. Par exemple, les informations d'image 2D collectées par la caméra capturent de riches caractéristiques sémantiques, et les données de nuages de points collectées par lidar peuvent fournir des informations de position précises et des informations géométriques de l'objet pour le modèle de perception. En utilisant pleinement les informations obtenues par différents capteurs, l'apparition de facteurs d'incertitude dans le processus de perception de la conduite autonome peut être réduite, tandis que la robustesse de détection du modèle de perception peut être améliorée. Aujourd'hui, nous présentons un article sur la perception de la conduite autonome de Megvii. et a été accepté à la conférence visuelle ICCV2023 de cette année. La principale caractéristique de cet article est un algorithme de perception BEV de bout en bout similaire au PETR (il ne nécessite plus l'utilisation d'opérations de post-traitement NMS pour filtrer les cases redondantes dans les résultats de perception. ). Dans le même temps, les informations du nuage de points du lidar sont également utilisées pour améliorer les performances de perception du modèle. Il s'agit d'un très bon article sur l'orientation de la perception de la conduite autonome. Le lien vers l'article et l'entrepôt open source officiel. Les liens sont les suivants :
Lien papier : https://arxiv.org/pdf/2301.01283.pdf- Lien code : https://github.com/junjie18/CMT
Ensuite, nous examinerons la structure du réseau du modèle de perception CMT. Une introduction générale est donnée, comme le montre la figure ci-dessous :
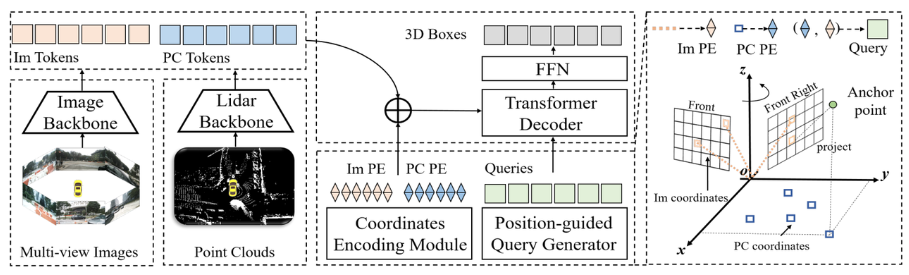 Comme le montre l'ensemble du schéma fonctionnel de l'algorithme, l'ensemble du modèle d'algorithme comprend principalement trois parties
Comme le montre l'ensemble du schéma fonctionnel de l'algorithme, l'ensemble du modèle d'algorithme comprend principalement trois parties
- et Image Token
- (Im Tokens)**Génération du codage de position : Pour les informations de données collectées par différents capteurs, Im Tokens
- Générez le code de position de coordonnées correspondant Im PE, PC Tokens générez le code de position de coordonnées correspondant PC PE et Object Queries génèrent également le code de position de coordonnées correspondantQuery EmbeddingTransformer Decoder+FFN network : L'entrée est Object Queries
- + Query Embedding et les Im Tokens et codés en position. Les jetons PC sont utilisés pour calculer l'attention croisée, et FFN est utilisé pour générer la prédiction finale des boîtes 3D + catégorie Présentation en détail du réseau Après la structure globale, les trois sous-parties mentionnées ci-dessus seront présentées en détail
Réseau fédérateur Lidar + réseau fédérateur de caméra (Image Backbone + Lidar Backbone)
Réseau fédérateur Lidar- Extraction du réseau fédérateur Lidar habituellement utilisé Les fonctionnalités de données de nuage de points comprennent les cinq parties suivantes
- Encodage des fonctionnalités Voxel
- Le Backbone 3D (réseau VoxelResBackBone8x couramment utilisé) extrait les caractéristiques 3D du résultat de l'encodage des caractéristiques voxel
- Le Backbone 3D extrait l'axe Z de la caractéristique et le compresse pour obtenir les caractéristiques dans l'espace BEV
- Utilisez le Backbone 2D pour effectuez un ajustement supplémentaire des fonctionnalités sur les fonctionnalités projetées dans l'espace BEV
- Étant donné que le nombre de canaux de la carte de fonctionnalités générée par le backbone 2D est différent de la sortie de l'image, le nombre de canaux est incohérent et une couche convolutive est utilisée pour aligner le nombre de canaux (pour le modèle de cet article, un alignement du nombre de canaux est effectué, mais il n'appartient pas à la catégorie originale d'extraction d'informations sur les nuages de points)
- Le réseau fédérateur de caméras généralement utilisé pour L'extraction des caractéristiques de l'image 2D comprend les deux parties suivantes :
- Sortie : sous-échantillonnage 16x et 32x Fusion des caractéristiques de l'image pour obtenir une carte de caractéristiques sous-échantillonnée 16 fois
Tensor([bs * N, 1024, H / 16, W / 16])Tensor([bs * N,2048,H / 16,W / 16])-
需要重新写的内容是:张量([bs * N,256,H / 16,W / 16])Tenseur([bs * N, 3, H, W])Tensor([bs * N,3,H,W]) 输出张量:
Tensor([bs * N,1024,H / 16,W / 16])输出张量:``Tensor([bs * N,2048,H / 32,W / 32])`
需要进行改写的内容是:2D骨架提取图像特征
Neck(CEFPN)
Tenseur([bs * N, 1024, H/16, W/16])位置编码的生成
根据以上介绍,位置编码的生成主要包括三个部分,分别是图像位置嵌入、点云位置嵌入和查询嵌入。下面将逐一介绍它们的生成过程
- Image Position Embedding(Im PE)
Image Position Embedding的生成过程与PETR中图像位置编码的生成逻辑是一样的(具体可以参考PETR论文原文,这里不做过多的阐述),可以总结为以下四个步骤:
- 在图像坐标系下生成3D图像视锥点云
- 3D图像视锥点云利用相机内参矩阵变换到相机坐标系下得到3D相机坐标点
- 相机坐标系下的3D点利用cam2ego坐标变换矩阵转换到BEV坐标系下
- 将转换后的BEV 3D 坐标利用MLP层进行位置编码得到最终的图像位置编码
- Point Cloud Position Embedding(PC PE)
Point Cloud Position Embedding的生成过程可以分为以下两个步骤 -
在BEV空间的网格坐标点利用
pos2embed()
Tenseur de sortie :Tensor([bs * N, 1024, H/16, W/ 16] )
Tenseur de sortie : ``Tensor([bs * N, 2048, H/32, W/32])` -
Le contenu qui doit être réécrit est : Extraction du squelette 2D Image fonctionnalités
Cou (CEFPN)
Génération du code de position
Selon l'introduction ci-dessus, la génération du code de position comprend principalement trois parties, à savoir l'intégration de la position de l'image et le nuage de points Intégration d’emplacement et intégration de requêtes. Ce qui suit présentera leur processus de génération un par unIncorporation de position d'image (Im PE)Le processus de génération d'intégration de position d'image est le même que la logique de génération d'encodage de position d'image dans PETR (pour plus de détails, veuillez vous référer à l'article PETR original, qui ne sera pas fait ici Trop d'élaboration), qui peut être résumé dans les quatre étapes suivantes :
Générer un nuage de points de tronc d'image 3D dans le système de coordonnées de l'image
Nuage de points du tronc de l'image 3D Utilisez la matrice de paramètres internes de la caméra pour transformer le système de coordonnées de la caméra afin d'obtenir le point de coordonnées de la caméra 3D
Le point 3D dans le système de coordonnées de la caméra est converti en système de coordonnées BEV à l'aide du Matrice de transformation de coordonnées cam2ego
- Incorporation de position du nuage de points (PC PE)
Le processus de génération du nuage de points L'intégration de position peut être divisée en deux étapes suivantes
Points de coordonnées de la grille dans l'espace BEV Utiliser
La fonction transforme les deux- points de coordonnées horizontales et verticales dimensionnelles dans un espace de caractéristiques de grande dimensionpos2embed()Intégration de requêtes
- Pour effectuer des calculs similaires entre les requêtes d'objet, le jeton d'image et le jeton Lidar. L'intégration de requêtes dans le document sera générée en utilisant la logique du Lidar et de la caméra pour générer un encodage de position spécifiquement, l'intégration de requêtes. = Incorporation de la position de l'image (identique à rv_query_embeds ci-dessous) + Incorporation de la position du nuage de points (identique à bev_query_embeds ci-dessous).
logique de génération bev_query_embeds
Étant donné que la requête d'objet dans l'article est initialement initialisée dans l'espace BEV, l'encodage de position et la fonction bev_embedding() dans la logique de génération d'incorporation de position de nuage de points sont directement réutilisés, c'est-à-dire que oui, le code clé correspondant est le suivant :
🎜🎜🎜🎜🎜🎜rv_query_embeds la logique de génération doit être réécrite🎜🎜🎜🎜Dans le contenu susmentionné, Object Query est le point initial dans le système de coordonnées BEV. Afin de suivre le processus de génération de l'incorporation de position d'image, le document doit d'abord projeter les points de l'espace 3D dans le système de coordonnées BEV sur le système de coordonnées d'image, puis utiliser la logique de traitement de la génération précédente d'incorporation de position d'image pour garantir que la logique du processus de génération est la même. Voici le code de base : 🎜# 点云位置编码`bev_pos_embeds`的生成bev_pos_embeds = self.bev_embedding(pos2embed(self.coords_bev.to(device), num_pos_feats=self.hidden_dim))def coords_bev(self):x_size, y_size = (grid_size[0] // downsample_scale,grid_size[1] // downsample_scale)meshgrid = [[0, y_size - 1, y_size], [0, x_size - 1, x_size]]batch_y, batch_x = torch.meshgrid(*[torch.linspace(it[0], it[1], it[2]) for it in meshgrid])batch_x = (batch_x + 0.5) / x_sizebatch_y = (batch_y + 0.5) / y_sizecoord_base = torch.cat([batch_x[None], batch_y[None]], dim=0) # 生成BEV网格.coord_base = coord_base.view(2, -1).transpose(1, 0)return coord_base# shape: (x_size *y_size, 2)def pos2embed(pos, num_pos_feats=256, temperature=10000):scale = 2 * math.pipos = pos * scaledim_t = torch.arange(num_pos_feats, dtype=torch.float32, device=pos.device)dim_t = temperature ** (2 * (dim_t // 2) / num_pos_feats)pos_x = pos[..., 0, None] / dim_tpos_y = pos[..., 1, None] / dim_tpos_x = torch.stack((pos_x[..., 0::2].sin(), pos_x[..., 1::2].cos()), dim=-1).flatten(-2)pos_y = torch.stack((pos_y[..., 0::2].sin(), pos_y[..., 1::2].cos()), dim=-1).flatten(-2)posemb = torch.cat((pos_y, pos_x), dim=-1)return posemb# 将二维的x,y坐标编码成512维的高维向量
Copier après la connexion🎜Grâce à la transformation ci-dessus, le point dans le système de coordonnées spatiales BEV est d'abord projeté sur le système de coordonnées de l'image, puis le processus de génération de rv_query_embeds à l'aide de la logique de traitement pour générer l'intégration de la position de l'image est terminé. . 🎜🎜Intégration de la dernière requête = rv_query_embeds + bev_query_embeds🎜🎜🎜🎜def _bev_query_embed(self, ref_points, img_metas):bev_embeds = self.bev_embedding(pos2embed(ref_points, num_pos_feats=self.hidden_dim))return bev_embeds# (bs, Num, 256)
Copier après la connexion
Transformer Decoder+FFN network
- Transformer Decoder
La logique de calcul ici est exactement la même que celle du décodeur dans Transformer, mais les données d'entrée sont un peu différentes
- Le premier point est la mémoire : la mémoire ici est l'image Token Le résultat après concat avec Lidar Token (peut être compris comme la fusion des deux modalités
- Le deuxième point est l'encodage de position : l'encodage de position ici est le résultat de la concat entre rv_query_embeds et bev_query_embeds, query_embed est rv_query_embeds + bev_query_embeds ;
- Réseau FFN
La fonction de ce réseau FFN est exactement la même que celle du PETR. Les résultats de sortie spécifiques peuvent être trouvés dans le texte original du PETR, je n'entrerai donc pas trop dans les détails ici
Le. les résultats expérimentaux de l'article
seront mis en premier. Des expériences comparatives entre CMT et d'autres algorithmes de perception de conduite autonome ont été publiées. Les auteurs de l'article ont effectué des comparaisons sur les ensembles de test et de val de nuScenes.
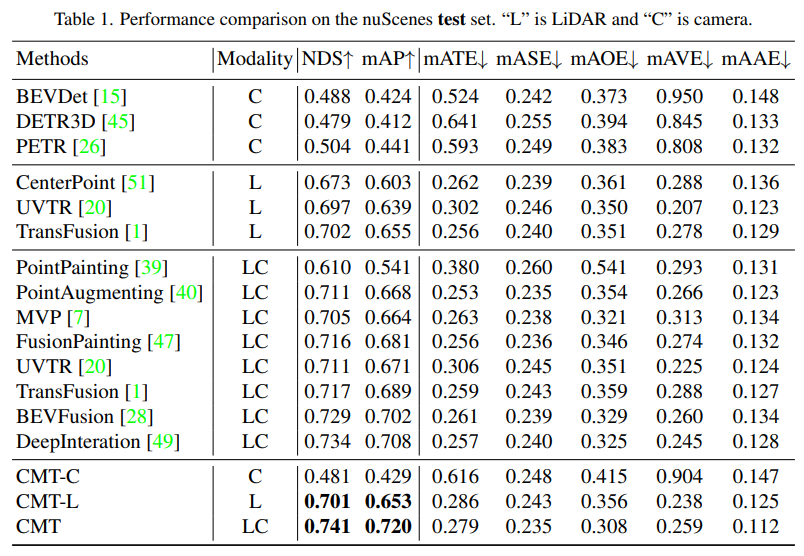
- Comparaison des résultats de perception de chaque algorithme de perception sur l'ensemble de test de nuScenes
- Dans le tableau, la modalité représente la catégorie de capteur entrée dans l'algorithme de perception, C représente le capteur de la caméra et le modèle alimente uniquement les données de la caméra. capteur, et le modèle alimente uniquement les données de nuages de points. LC représente les capteurs lidar et caméra, et le modèle entre plusieurs données modales. Il peut être vu à partir des résultats expérimentaux que les performances du modèle CMT-C sont supérieures à celles du modèle CMT-C. BEVDet et DETR3D Les performances du modèle CMT-L sont supérieures à celles des modèles d'algorithmes de perception lidar purs tels que CenterPoint et UVTR. Après avoir utilisé les données de nuages de points lidar et les données de caméra, il a surpassé toutes les méthodes monomodales existantes et obtenu des résultats SOTA. . Comparaison des résultats de perception du modèle sur l'ensemble val de nuScenes
à travers des résultats expérimentaux. On peut voir que les performances du modèle de perception de CMT-L surpassent FUTR3D et UVTR lors de l'utilisation simultanée des données de nuages de points lidar et des données de caméra. CMT surpasse largement les algorithmes de perception multimodaux existants, tels que FUTR3D, UVTR, TransFusion et BEVFusion, qui ont obtenu des résultats SOTA sur val set
- La prochaine étape est l'expérience d'ablation qui fait partie de l'innovation CMT
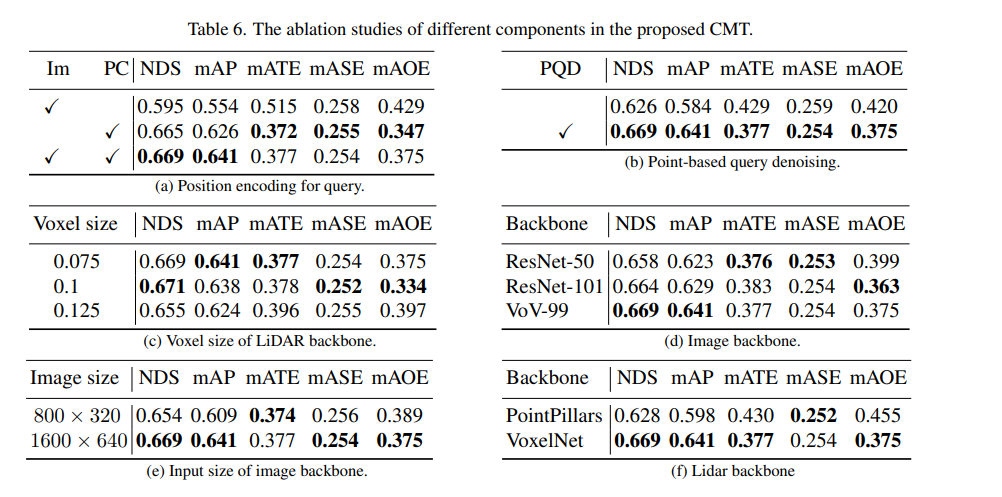
Tout d'abord, nous avons mené une série d'expériences d'ablation pour déterminer s'il fallait utiliser le codage de position. Grâce aux résultats expérimentaux, il a été constaté que les indicateurs NDS et mAP obtenaient les meilleurs résultats en utilisant à la fois la position de l'image et la position lidar. codage. Ensuite, dans (c) et (c) de l’expérience d’ablation, partie f), nous avons expérimenté différents types et tailles de voxels du réseau fédérateur de nuages de points. Dans les expériences d'ablation des parties (d) et (e), nous avons fait différentes tentatives sur le type de réseau fédérateur de caméra et la taille de la résolution d'entrée. Ce qui précède n'est qu'un bref résumé du contenu expérimental. Si vous souhaitez connaître des expériences d'ablation plus détaillées, veuillez vous référer à l'article original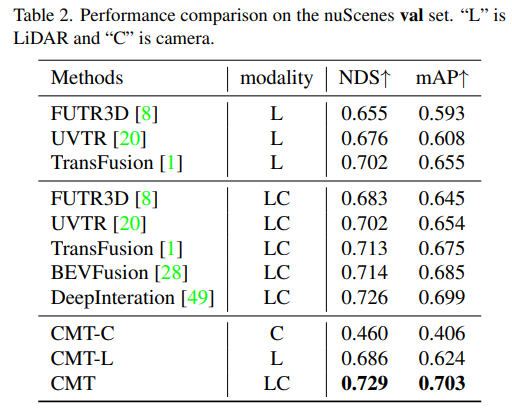
Résumé
Actuellement, la fusion de diverses modalités pour améliorer les performances perceptuelles du modèle est devenue une direction de recherche populaire (en particulier dans les véhicules autonomes, équipés de divers capteurs). Parallèlement, CMT est un algorithme de perception entièrement de bout en bout qui ne nécessite aucune étape de post-traitement supplémentaire et atteint une précision de pointe sur l'ensemble de données nuScenes. Cet article présente cet article en détail, j'espère qu'il sera utile à tout le monde Le contenu qui doit être réécrit est : Lien original : https://mp.weixin.qq.com/s/Fx7dkv8f2ibkfO66-5hEXA
Le contenu qui doit être réécrit est : Lien original : https://mp.weixin.qq.com/s/Fx7dkv8f2ibkfO66-5hEXA
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment résoudre le problème de la longue traîne dans les scénarios de conduite autonome ?
Jun 02, 2024 pm 02:44 PM
Comment résoudre le problème de la longue traîne dans les scénarios de conduite autonome ?
Jun 02, 2024 pm 02:44 PM
Hier, lors de l'entretien, on m'a demandé si j'avais posé des questions à longue traîne, j'ai donc pensé faire un bref résumé. Le problème à longue traîne de la conduite autonome fait référence aux cas extrêmes dans les véhicules autonomes, c'est-à-dire à des scénarios possibles avec une faible probabilité d'occurrence. Le problème perçu de la longue traîne est l’une des principales raisons limitant actuellement le domaine de conception opérationnelle des véhicules autonomes intelligents à véhicule unique. L'architecture sous-jacente et la plupart des problèmes techniques de la conduite autonome ont été résolus, et les 5 % restants des problèmes à longue traîne sont progressivement devenus la clé pour restreindre le développement de la conduite autonome. Ces problèmes incluent une variété de scénarios fragmentés, de situations extrêmes et de comportements humains imprévisibles. La « longue traîne » des scénarios limites dans la conduite autonome fait référence aux cas limites dans les véhicules autonomes (VA). Les cas limites sont des scénarios possibles avec une faible probabilité d'occurrence. ces événements rares
 Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Imaginez un modèle d'intelligence artificielle qui non seulement a la capacité de surpasser l'informatique traditionnelle, mais qui permet également d'obtenir des performances plus efficaces à moindre coût. Ce n'est pas de la science-fiction, DeepSeek-V2[1], le modèle MoE open source le plus puissant au monde est ici. DeepSeek-V2 est un puissant mélange de modèle de langage d'experts (MoE) présentant les caractéristiques d'une formation économique et d'une inférence efficace. Il est constitué de 236B paramètres, dont 21B servent à activer chaque marqueur. Par rapport à DeepSeek67B, DeepSeek-V2 offre des performances plus élevées, tout en économisant 42,5 % des coûts de formation, en réduisant le cache KV de 93,3 % et en augmentant le débit de génération maximal à 5,76 fois. DeepSeek est une entreprise explorant l'intelligence artificielle générale
 L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L’IA change effectivement les mathématiques. Récemment, Tao Zhexuan, qui a prêté une attention particulière à cette question, a transmis le dernier numéro du « Bulletin de l'American Mathematical Society » (Bulletin de l'American Mathematical Society). En se concentrant sur le thème « Les machines changeront-elles les mathématiques ? », de nombreux mathématiciens ont exprimé leurs opinions. L'ensemble du processus a été plein d'étincelles, intense et passionnant. L'auteur dispose d'une équipe solide, comprenant Akshay Venkatesh, lauréat de la médaille Fields, le mathématicien chinois Zheng Lejun, l'informaticien de l'Université de New York Ernest Davis et de nombreux autres universitaires bien connus du secteur. Le monde de l’IA a radicalement changé. Vous savez, bon nombre de ces articles ont été soumis il y a un an.
 Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Les performances de JAX, promu par Google, ont dépassé celles de Pytorch et TensorFlow lors de récents tests de référence, se classant au premier rang sur 7 indicateurs. Et le test n’a pas été fait sur le TPU présentant les meilleures performances JAX. Bien que parmi les développeurs, Pytorch soit toujours plus populaire que Tensorflow. Mais à l’avenir, des modèles plus volumineux seront peut-être formés et exécutés sur la base de la plate-forme JAX. Modèles Récemment, l'équipe Keras a comparé trois backends (TensorFlow, JAX, PyTorch) avec l'implémentation native de PyTorch et Keras2 avec TensorFlow. Premièrement, ils sélectionnent un ensemble de
 Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas entre officiellement dans l’ère des robots électriques ! Hier, l'Atlas hydraulique s'est retiré "en larmes" de la scène de l'histoire. Aujourd'hui, Boston Dynamics a annoncé que l'Atlas électrique était au travail. Il semble que dans le domaine des robots humanoïdes commerciaux, Boston Dynamics soit déterminé à concurrencer Tesla. Après la sortie de la nouvelle vidéo, elle a déjà été visionnée par plus d’un million de personnes en seulement dix heures. Les personnes âgées partent et de nouveaux rôles apparaissent. C'est une nécessité historique. Il ne fait aucun doute que cette année est l’année explosive des robots humanoïdes. Les internautes ont commenté : Les progrès des robots ont fait ressembler la cérémonie d'ouverture de cette année à des êtres humains, et le degré de liberté est bien plus grand que celui des humains. Mais n'est-ce vraiment pas un film d'horreur ? Au début de la vidéo, Atlas est allongé calmement sur le sol, apparemment sur le dos. Ce qui suit est à couper le souffle
 KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
Plus tôt ce mois-ci, des chercheurs du MIT et d'autres institutions ont proposé une alternative très prometteuse au MLP – KAN. KAN surpasse MLP en termes de précision et d’interprétabilité. Et il peut surpasser le MLP fonctionnant avec un plus grand nombre de paramètres avec un très petit nombre de paramètres. Par exemple, les auteurs ont déclaré avoir utilisé KAN pour reproduire les résultats de DeepMind avec un réseau plus petit et un degré d'automatisation plus élevé. Plus précisément, le MLP de DeepMind compte environ 300 000 paramètres, tandis que le KAN n'en compte qu'environ 200. KAN a une base mathématique solide comme MLP est basé sur le théorème d'approximation universelle, tandis que KAN est basé sur le théorème de représentation de Kolmogorov-Arnold. Comme le montre la figure ci-dessous, KAN a
 Parlons des systèmes de conduite autonome de bout en bout et de nouvelle génération, ainsi que de quelques malentendus sur la conduite autonome de bout en bout ?
Apr 15, 2024 pm 04:13 PM
Parlons des systèmes de conduite autonome de bout en bout et de nouvelle génération, ainsi que de quelques malentendus sur la conduite autonome de bout en bout ?
Apr 15, 2024 pm 04:13 PM
Au cours du mois dernier, pour des raisons bien connues, j'ai eu des échanges très intensifs avec divers professeurs et camarades de classe du secteur. Un sujet inévitable dans l'échange est naturellement le populaire Tesla FSDV12 de bout en bout. Je voudrais profiter de cette occasion pour trier certaines de mes pensées et opinions en ce moment pour votre référence et votre discussion. Comment définir un système de conduite autonome de bout en bout et quels problèmes devraient être résolus de bout en bout ? Selon la définition la plus traditionnelle, un système de bout en bout fait référence à un système qui saisit les informations brutes des capteurs et génère directement les variables pertinentes pour la tâche. Par exemple, en reconnaissance d'images, CNN peut être appelé de bout en bout par rapport à la méthode traditionnelle d'extraction de caractéristiques + classificateur. Dans les tâches de conduite autonome, saisir les données de divers capteurs (caméra/LiDAR
 NuScenes dernier SOTA SparseAD : les requêtes clairsemées contribuent à une conduite autonome efficace de bout en bout !
Apr 17, 2024 pm 06:22 PM
NuScenes dernier SOTA SparseAD : les requêtes clairsemées contribuent à une conduite autonome efficace de bout en bout !
Apr 17, 2024 pm 06:22 PM
Écrit à l'avant et point de départ Le paradigme de bout en bout utilise un cadre unifié pour réaliser plusieurs tâches dans les systèmes de conduite autonome. Malgré la simplicité et la clarté de ce paradigme, les performances des méthodes de conduite autonome de bout en bout sur les sous-tâches sont encore loin derrière les méthodes à tâche unique. Dans le même temps, les fonctionnalités de vue à vol d'oiseau (BEV) denses, largement utilisées dans les méthodes de bout en bout précédentes, rendent difficile l'adaptation à davantage de modalités ou de tâches. Un paradigme de conduite autonome de bout en bout (SparseAD) centré sur la recherche clairsemée est proposé ici, dans lequel la recherche clairsemée représente entièrement l'ensemble du scénario de conduite, y compris l'espace, le temps et les tâches, sans aucune représentation BEV dense. Plus précisément, une architecture clairsemée unifiée est conçue pour la connaissance des tâches, notamment la détection, le suivi et la cartographie en ligne. De plus, lourd
