
 Périphériques technologiques
IA
Réécriture du titre : excellent suivi des papiers des étudiants ICCV 2023, Github a obtenu 1,6K étoiles, des informations complètes comme par magie !
Périphériques technologiques
IA
Réécriture du titre : excellent suivi des papiers des étudiants ICCV 2023, Github a obtenu 1,6K étoiles, des informations complètes comme par magie !
Réécriture du titre : excellent suivi des papiers des étudiants ICCV 2023, Github a obtenu 1,6K étoiles, des informations complètes comme par magie !

1. Informations sur l'article
Le meilleur article étudiant de l'ICCV2023 de cette année a été décerné à Qianqian Wang de l'Université Cornell, qui est actuellement chercheur postdoctoral à l'Université de Californie à Berkeley !
2.
Dans le domaine de l'estimation de mouvement vidéo, l'auteur souligne que les méthodes traditionnelles sont principalement divisées en deux types : le suivi de caractéristiques clairsemées et le flux optique dense. Bien que les deux méthodes se soient révélées efficaces dans leurs applications respectives, aucune ne capture entièrement le mouvement en vidéo. Le flux optique apparié ne peut pas capturer les trajectoires de mouvement dans des fenêtres temporelles longues, tandis que le suivi clairsemé ne peut pas modéliser le mouvement de tous les pixels. Pour combler cet écart, de nombreuses études ont tenté d'estimer simultanément les trajectoires de pixels denses et à longue portée dans les vidéos. Les méthodes de ces études varient de la simple liaison des champs de flux optique de deux images à la prédiction directe de la trajectoire de chaque pixel sur plusieurs images. Cependant, ces méthodes ne prennent souvent en compte qu’un contexte limité lors de l’estimation du mouvement et ignorent les informations éloignées dans le temps ou dans l’espace. Cette myopie peut conduire à une accumulation d’erreurs sur les longues trajectoires, ainsi qu’à des incohérences spatio-temporelles dans l’estimation du mouvement. Bien que certaines méthodes prennent en compte le contexte à long terme, elles fonctionnent toujours dans le domaine 2D, ce qui peut conduire à une perte de suivi lors des événements d'occlusion. Globalement, l'estimation de trajectoires denses et à longue portée dans les vidéos reste un problème non résolu dans le domaine. Ce problème implique trois défis principaux : 1) Comment maintenir la précision de la trajectoire dans de longues séquences, 2) Comment suivre l'emplacement des points sous occlusion, 3) Comment maintenir la cohérence spatio-temporelle
Globalement, l'estimation de trajectoires denses et à longue portée dans les vidéos reste un problème non résolu dans le domaine. Ce problème implique trois défis principaux : 1) Comment maintenir la précision de la trajectoire dans de longues séquences, 2) Comment suivre l'emplacement des points sous occlusion, 3) Comment maintenir la cohérence spatio-temporelle
Dans cet article, les auteurs proposent une nouvelle vidéo de mouvement méthode d'estimation qui utilise toutes les informations de la vidéo pour estimer conjointement la trajectoire de mouvement complète de chaque pixel. Cette méthode s'appelle "OmniMotion" et utilise une représentation quasi-3D. Dans cette représentation, un volume 3D standard est mappé sur un volume local à chaque image. Ce mappage sert d’extension flexible de la géométrie dynamique multi-vues et peut simuler simultanément le mouvement de la caméra et de la scène. Cette représentation garantit non seulement la cohérence de la boucle, mais garde également une trace de tous les pixels pendant les occultations. Les auteurs optimisent cette représentation pour chaque vidéo, fournissant une solution pour le mouvement tout au long de la vidéo. Après optimisation, cette représentation peut être interrogée sur n'importe quelles coordonnées continues de la vidéo pour obtenir des trajectoires de mouvement couvrant l'intégralité de la vidéo.
La méthode proposée dans cet article peut : 1) Générer une représentation complète globalement cohérente pour tous les points de l'ensemble des trajectoires de mouvement de la vidéo. , 2) suivi des points par occlusion et 3) traitement de vidéos réelles avec diverses combinaisons d'actions de caméra et de scène. Sur le benchmark de suivi vidéo TAP, la méthode fonctionne bien, dépassant de loin les méthodes précédentes.
3. MéthodeL'article propose une méthode basée sur l'optimisation du temps de test pour estimer les mouvements denses et longue distance à partir de séquences vidéo. Tout d'abord, donnons un aperçu de la méthode proposée dans l'article :
Entrée
: La méthode de l'auteur prend en entrée un ensemble de trames et de paires d'estimations de mouvement bruyantes (telles que des champs de flux optique).- Opérations de la méthode
- : à l'aide de ces entrées, la méthode cherche à trouver une représentation de mouvement complète et globalement cohérente pour l'ensemble de la vidéo. Caractéristiques des résultats
- : Après optimisation, cette représentation peut être interrogée avec n'importe quel pixel de n'importe quelle image de la vidéo, ce qui entraîne une trajectoire de mouvement fluide et précise sur toute la vidéo. Cette méthode identifie également quand un point est obstrué et peut suivre les points qui passent par l'occlusion. Contenu principal
- :
- Représentation OmniMotion : Dans la section suivante, les auteurs décrivent d'abord leur représentation de base, appelée OmniMotion.
- Processus d'optimisation
- : Ensuite, les auteurs décrivent le processus d'optimisation permettant de récupérer cette représentation à partir de la vidéo. Cette méthode peut fournir une représentation de mouvement vidéo complète et cohérente et peut résoudre efficacement des problèmes difficiles tels que l'occlusion. Apprenons-en maintenant plus à ce sujet
- Pas d'inversible : Cette version supprime le composant "réversibilité". Par rapport à la méthode complète, toutes ses métriques chutent significativement, notamment sur AJ et , ce qui montre que la réversibilité joue un rôle crucial dans l'ensemble du système.
- Pas de photométrique : Cette version supprime le composant "photométrique". Bien que ses performances soient inférieures à la version "Full", elle est plus performante que la version "irréversible". Cela montre que même si la composante photométrique joue un certain rôle dans l'amélioration des performances, son importance peut être inférieure à celle de la composante réversible.
- Échantillonnage uniforme : Cette version utilise une stratégie d'échantillonnage unifiée. Elle est également légèrement moins performante que la version complète, mais toujours meilleure que les versions "irréversibilité" et "aluminium".
- Full : Il s'agit de la version complète avec tous les composants et elle atteint les meilleures performances sur toutes les métriques. Cela montre que chaque composant contribue à l'amélioration des performances, en particulier lorsque tous les composants sont intégrés, le système peut atteindre les meilleures performances.
3.1 Volume 3D canonique
Le contenu vidéo est représenté par un volume typique nommé G, qui agit comme une carte tridimensionnelle de la scène observée. Semblable à ce qui a été fait dans NeRF, ils ont défini un réseau basé sur des coordonnées nerf qui mappe chaque coordonnée 3D typique uvw dans G à une densité σ et une couleur c. La densité stockée dans G nous indique où se trouve la surface dans un espace typique. Combiné avec des bijections 3D, cela nous permet de suivre des surfaces sur plusieurs images et de comprendre les relations d'occlusion. La couleur stockée dans G nous permet de calculer la perte photométrique lors de l'optimisation.
3.2 Bijections 3D
Cet article présente une cartographie de bijection continue, notée , qui transforme les points 3D d'un système de coordonnées local en un système de coordonnées 3D canonique. Cette coordonnée canonique sert de référence cohérente ou « d'index » dans le temps pour un point de scène ou une trajectoire 3D. Le principal avantage de l’utilisation des mappages bijectifs est la cohérence périodique qu’ils procurent aux points 3D entre différentes images, puisqu’ils proviennent tous du même point canonique.
L'équation de cartographie des points 3D d'un cadre local à un autre est la suivante :
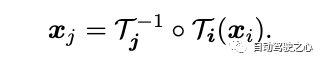
Pour capturer un mouvement complexe du monde réel, ces bijections sont paramétrées en tant que réseaux de neurones inversibles (DCI). Le choix de Real-NVP comme modèle a été influencé par sa simplicité et ses propriétés analytiquement réversibles. Real-NVP implémente le mappage bijectif en utilisant des transformations de base appelées couches de couplage affine. Ces couches divisent l'entrée de sorte qu'une partie reste inchangée tandis que l'autre partie subit une transformation affine.
Pour améliorer encore cette architecture, nous pouvons le faire en conditionnant le code latent latent_i de chaque frame. Par conséquent, tous les mappages réversibles i sont déterminés par un seul réseau de cartographie réversible, mais ils ont des codes latents différents
3.3 Calcul du mouvement image par image
Recalcul du mouvement inter-image
Cette section décrit comment calculer le mouvement 2D pour tout pixel de requête dans le cadre i. Intuitivement, les pixels de requête sont d'abord « soulevés » en 3D en échantillonnant des points sur les rayons, puis ces points 3D sont « mappés » sur le cadre cible j à l'aide du mappage de bijection i et du mappage j, suivi d'une composition alpha à partir de différents échantillons. Ces points 3D cartographiés sont "rendu" et enfin "projeté" en 2D pour obtenir une correspondance supposée.

4. Comparaison expérimentale
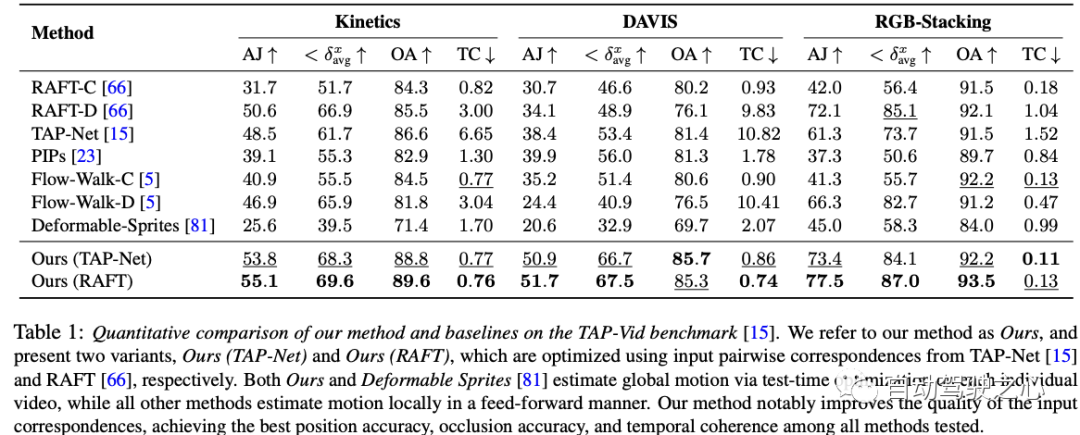
Ce tableau de données expérimentales montre les performances de diverses méthodes d'estimation de mouvement sur trois ensembles de données - Cinétique, DAVIS et RGB-Stacking. Pour évaluer les performances des méthodes individuelles, quatre métriques sont utilisées : AJ, avg, OA et TC. En plus des deux méthodes proposées par les auteurs (la nôtre (TAP-Net) et notre (RAFT)), il existe 7 autres méthodes. Il convient de noter que les méthodes des deux auteurs fonctionnent bien sur la plupart des métriques et des ensembles de données. Plus précisément, notre méthode (RAFT) obtient les meilleurs résultats sur AJ, avg et OA pour les trois ensembles de données, tout en étant la deuxième meilleure sur TC. Notre méthode (TAP-Net) atteint également d’excellentes performances similaires sur certaines mesures. Pendant ce temps, d’autres méthodes ont des performances mitigées sur ces mesures. Il convient de mentionner que la méthode de l'auteur et la méthode "Deformable Sprites" estiment le mouvement global grâce à une optimisation du temps de test sur chaque vidéo, tandis que toutes les autres méthodes utilisent une approche directe pour effectuer une estimation du mouvement localement. En résumé, la méthode de l'auteur surpasse toutes les autres méthodes testées en termes de précision de position, de précision d'occlusion et de continuité temporelle, montrant des avantages significatifs

Il s'agit d'un tableau des résultats des expériences d'ablation pour l'ensemble de données DAVIS. Des expériences d'ablation sont menées pour vérifier la contribution de chaque composant aux performances globales du système. Il existe quatre méthodes répertoriées dans ce tableau, dont trois sont des versions qui suppriment certains composants clés, et la version finale « complète » inclut tous les composants.
Dans l'ensemble, les résultats de cette expérience d'ablation montrent que bien que chaque composant présente une certaine amélioration des performances, la réversibilité est probablement le composant le plus important, car sans elle, la perte de performances sera très grave
5. Discussion

Les expériences d'ablation réalisées sur l'ensemble de données DAVIS dans ce travail nous fournissent des informations précieuses, révélant le rôle critique de chaque composant sur les performances globales du système. D’après les résultats expérimentaux, nous pouvons clairement voir que la composante de réversibilité joue un rôle crucial dans le cadre global. Lorsque ce composant essentiel est manquant, les performances du système diminuent considérablement. Cela souligne encore l’importance de prendre en compte la réversibilité dans l’analyse vidéo dynamique. Dans le même temps, bien que la perte de la composante photométrique entraîne également une dégradation des performances, elle ne semble pas avoir un impact aussi important sur les performances que la réversibilité. De plus, bien que la stratégie d'échantillonnage unifié ait un certain impact sur les performances, son impact est relativement faible par rapport aux deux premières. Enfin, l’approche complète intègre tous ces composants et nous montre les meilleures performances réalisables toutes considérations confondues. Dans l'ensemble, ce travail nous offre une opportunité précieuse de mieux comprendre comment les différents composants de l'analyse vidéo interagissent les uns avec les autres et leur contribution spécifique à la performance globale, soulignant ainsi la nécessité d'une approche intégrée lors de la conception et de l'optimisation des algorithmes de traitement vidéo.
Cependant, comme de nombreuses méthodes d'estimation de mouvement, notre méthode est confrontée à des difficultés dans la gestion de mouvements rapides et très non rigides et de petites structures. Dans ces scénarios, les méthodes de correspondance par paires peuvent ne pas fournir une correspondance suffisamment fiable pour que notre méthode puisse calculer un mouvement global précis. De plus, en raison de la nature hautement non convexe du problème d’optimisation sous-jacent, nous observons que pour certaines vidéos difficiles, notre processus d’optimisation peut être très sensible à l’initialisation. Cela peut conduire à des minima locaux sous-optimaux, par exemple un ordre de surface incorrect ou des objets en double dans l'espace canonique, qui sont parfois difficiles à corriger par l'optimisation.
Enfin, notre méthode peut être coûteuse en calcul dans sa forme actuelle. Premièrement, le processus de collecte de flux implique un calcul complet de tous les flux par paires, qui croissent quadratiquement avec la longueur de la séquence. Mais nous pensons que l’évolutivité de ce processus peut être améliorée en explorant des méthodes de correspondance plus efficaces, telles que les arbres de vocabulaire ou la correspondance basée sur des images clés, et en s’inspirant du mouvement structurel et de la littérature SLAM. Deuxièmement, comme d’autres méthodes utilisant des représentations neuronales implicites, notre méthode implique un processus d’optimisation relativement long. Des recherches récentes dans ce domaine peuvent contribuer à accélérer ce processus et à l'étendre davantage à des séquences plus longues
6 Conclusion
Cet article propose une nouvelle méthode d'optimisation du temps de test pour estimer l'intégralité du mouvement vidéo dans son ensemble, cohérente avec la situation globale. . Une nouvelle représentation de mouvement vidéo est introduite, appelée OmniMotion, qui consiste en un volume standard quasi-3D et des bijections canoniques locales pour chaque image. OmniMotion peut traiter une vidéo ordinaire avec différents paramètres de caméra et dynamiques de scène et produire des mouvements longue distance précis et fluides grâce à l'occlusion. Des améliorations significatives sont obtenues par rapport aux méthodes de pointe précédentes, tant qualitativement que quantitativement.

Le contenu qui doit être réécrit est : Lien original : https://mp.weixin.qq.com/s/HOIi5y9j-JwUImhpHPYgkg
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Pourquoi le Gaussian Splatting est-il si populaire dans la conduite autonome que le NeRF commence à être abandonné ?
Jan 17, 2024 pm 02:57 PM
Pourquoi le Gaussian Splatting est-il si populaire dans la conduite autonome que le NeRF commence à être abandonné ?
Jan 17, 2024 pm 02:57 PM
Écrit ci-dessus et compréhension personnelle de l'auteur Le Gaussiansplatting tridimensionnel (3DGS) est une technologie transformatrice qui a émergé dans les domaines des champs de rayonnement explicites et de l'infographie ces dernières années. Cette méthode innovante se caractérise par l’utilisation de millions de gaussiennes 3D, ce qui est très différent de la méthode du champ de rayonnement neuronal (NeRF), qui utilise principalement un modèle implicite basé sur les coordonnées pour mapper les coordonnées spatiales aux valeurs des pixels. Avec sa représentation explicite de scènes et ses algorithmes de rendu différenciables, 3DGS garantit non seulement des capacités de rendu en temps réel, mais introduit également un niveau de contrôle et d'édition de scène sans précédent. Cela positionne 3DGS comme un révolutionnaire potentiel pour la reconstruction et la représentation 3D de nouvelle génération. À cette fin, nous fournissons pour la première fois un aperçu systématique des derniers développements et préoccupations dans le domaine du 3DGS.
 Comment résoudre le problème de la longue traîne dans les scénarios de conduite autonome ?
Jun 02, 2024 pm 02:44 PM
Comment résoudre le problème de la longue traîne dans les scénarios de conduite autonome ?
Jun 02, 2024 pm 02:44 PM
Hier, lors de l'entretien, on m'a demandé si j'avais posé des questions à longue traîne, j'ai donc pensé faire un bref résumé. Le problème à longue traîne de la conduite autonome fait référence aux cas extrêmes dans les véhicules autonomes, c'est-à-dire à des scénarios possibles avec une faible probabilité d'occurrence. Le problème perçu de la longue traîne est l’une des principales raisons limitant actuellement le domaine de conception opérationnelle des véhicules autonomes intelligents à véhicule unique. L'architecture sous-jacente et la plupart des problèmes techniques de la conduite autonome ont été résolus, et les 5 % restants des problèmes à longue traîne sont progressivement devenus la clé pour restreindre le développement de la conduite autonome. Ces problèmes incluent une variété de scénarios fragmentés, de situations extrêmes et de comportements humains imprévisibles. La « longue traîne » des scénarios limites dans la conduite autonome fait référence aux cas limites dans les véhicules autonomes (VA). Les cas limites sont des scénarios possibles avec une faible probabilité d'occurrence. ces événements rares
 Choisir une caméra ou un lidar ? Une étude récente sur la détection robuste d'objets 3D
Jan 26, 2024 am 11:18 AM
Choisir une caméra ou un lidar ? Une étude récente sur la détection robuste d'objets 3D
Jan 26, 2024 am 11:18 AM
0. Écrit à l'avant&& Compréhension personnelle que les systèmes de conduite autonome s'appuient sur des technologies avancées de perception, de prise de décision et de contrôle, en utilisant divers capteurs (tels que caméras, lidar, radar, etc.) pour percevoir l'environnement et en utilisant des algorithmes et des modèles pour une analyse et une prise de décision en temps réel. Cela permet aux véhicules de reconnaître les panneaux de signalisation, de détecter et de suivre d'autres véhicules, de prédire le comportement des piétons, etc., permettant ainsi de fonctionner en toute sécurité et de s'adapter à des environnements de circulation complexes. Cette technologie attire actuellement une grande attention et est considérée comme un domaine de développement important pour l'avenir des transports. . un. Mais ce qui rend la conduite autonome difficile, c'est de trouver comment faire comprendre à la voiture ce qui se passe autour d'elle. Cela nécessite que l'algorithme de détection d'objets tridimensionnels du système de conduite autonome puisse percevoir et décrire avec précision les objets dans l'environnement, y compris leur emplacement,
 Le papier Stable Diffusion 3 est enfin publié, et les détails architecturaux sont révélés. Cela aidera-t-il à reproduire Sora ?
Mar 06, 2024 pm 05:34 PM
Le papier Stable Diffusion 3 est enfin publié, et les détails architecturaux sont révélés. Cela aidera-t-il à reproduire Sora ?
Mar 06, 2024 pm 05:34 PM
L'article de StableDiffusion3 est enfin là ! Ce modèle est sorti il y a deux semaines et utilise la même architecture DiT (DiffusionTransformer) que Sora. Il a fait beaucoup de bruit dès sa sortie. Par rapport à la version précédente, la qualité des images générées par StableDiffusion3 a été considérablement améliorée. Il prend désormais en charge les invites multithèmes, et l'effet d'écriture de texte a également été amélioré et les caractères tronqués n'apparaissent plus. StabilityAI a souligné que StableDiffusion3 est une série de modèles avec des tailles de paramètres allant de 800M à 8B. Cette plage de paramètres signifie que le modèle peut être exécuté directement sur de nombreux appareils portables, réduisant ainsi considérablement l'utilisation de l'IA.
 Avez-vous vraiment maîtrisé la conversion des systèmes de coordonnées ? Des enjeux multi-capteurs indispensables à la conduite autonome
Oct 12, 2023 am 11:21 AM
Avez-vous vraiment maîtrisé la conversion des systèmes de coordonnées ? Des enjeux multi-capteurs indispensables à la conduite autonome
Oct 12, 2023 am 11:21 AM
Le premier article pilote et clé présente principalement plusieurs systèmes de coordonnées couramment utilisés dans la technologie de conduite autonome, et comment compléter la corrélation et la conversion entre eux, et enfin construire un modèle d'environnement unifié. L'objectif ici est de comprendre la conversion du véhicule en corps rigide de caméra (paramètres externes), la conversion de caméra en image (paramètres internes) et la conversion d'image en unité de pixel. La conversion de 3D en 2D aura une distorsion, une traduction, etc. Points clés : Le système de coordonnées du véhicule et le système de coordonnées du corps de la caméra doivent être réécrits : le système de coordonnées planes et le système de coordonnées des pixels Difficulté : la distorsion de l'image doit être prise en compte. La dé-distorsion et l'ajout de distorsion sont compensés sur le plan de l'image. 2. Introduction Il existe quatre systèmes de vision au total : système de coordonnées du plan de pixels (u, v), système de coordonnées d'image (x, y), système de coordonnées de caméra () et système de coordonnées mondiales (). Il existe une relation entre chaque système de coordonnées,
 Cet article vous suffit pour en savoir plus sur la conduite autonome et la prédiction de trajectoire !
Feb 28, 2024 pm 07:20 PM
Cet article vous suffit pour en savoir plus sur la conduite autonome et la prédiction de trajectoire !
Feb 28, 2024 pm 07:20 PM
La prédiction de trajectoire joue un rôle important dans la conduite autonome. La prédiction de trajectoire de conduite autonome fait référence à la prédiction de la trajectoire de conduite future du véhicule en analysant diverses données pendant le processus de conduite du véhicule. En tant que module central de la conduite autonome, la qualité de la prédiction de trajectoire est cruciale pour le contrôle de la planification en aval. La tâche de prédiction de trajectoire dispose d'une riche pile technologique et nécessite une connaissance de la perception dynamique/statique de la conduite autonome, des cartes de haute précision, des lignes de voie, des compétences en architecture de réseau neuronal (CNN&GNN&Transformer), etc. Il est très difficile de démarrer ! De nombreux fans espèrent se lancer dans la prédiction de trajectoire le plus tôt possible et éviter les pièges. Aujourd'hui, je vais faire le point sur quelques problèmes courants et des méthodes d'apprentissage introductives pour la prédiction de trajectoire ! Connaissances introductives 1. Existe-t-il un ordre d'entrée pour les épreuves de prévisualisation ? R : Regardez d’abord l’enquête, p
 SIMPL : un benchmark de prédiction de mouvement multi-agents simple et efficace pour la conduite autonome
Feb 20, 2024 am 11:48 AM
SIMPL : un benchmark de prédiction de mouvement multi-agents simple et efficace pour la conduite autonome
Feb 20, 2024 am 11:48 AM
Titre original : SIMPL : ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving Lien article : https://arxiv.org/pdf/2402.02519.pdf Lien code : https://github.com/HKUST-Aerial-Robotics/SIMPL Affiliation de l'auteur : Université des sciences de Hong Kong et technologie Idée DJI Paper : cet article propose une base de référence de prédiction de mouvement (SIMPL) simple et efficace pour les véhicules autonomes. Par rapport au cent agent traditionnel
 Parlons des systèmes de conduite autonome de bout en bout et de nouvelle génération, ainsi que de quelques malentendus sur la conduite autonome de bout en bout ?
Apr 15, 2024 pm 04:13 PM
Parlons des systèmes de conduite autonome de bout en bout et de nouvelle génération, ainsi que de quelques malentendus sur la conduite autonome de bout en bout ?
Apr 15, 2024 pm 04:13 PM
Au cours du mois dernier, pour des raisons bien connues, j'ai eu des échanges très intensifs avec divers professeurs et camarades de classe du secteur. Un sujet inévitable dans l'échange est naturellement le populaire Tesla FSDV12 de bout en bout. Je voudrais profiter de cette occasion pour trier certaines de mes pensées et opinions en ce moment pour votre référence et votre discussion. Comment définir un système de conduite autonome de bout en bout et quels problèmes devraient être résolus de bout en bout ? Selon la définition la plus traditionnelle, un système de bout en bout fait référence à un système qui saisit les informations brutes des capteurs et génère directement les variables pertinentes pour la tâche. Par exemple, en reconnaissance d'images, CNN peut être appelé de bout en bout par rapport à la méthode traditionnelle d'extraction de caractéristiques + classificateur. Dans les tâches de conduite autonome, saisir les données de divers capteurs (caméra/LiDAR
