

Les modèles à grande échelle font le saut entre le langage et la vision, promettant de comprendre et de générer de manière transparente du contenu texte et image. Dans une série d'études récentes, l'intégration de fonctionnalités multimodales est non seulement une tendance croissante, mais a déjà conduit à des avancées clés allant des conversations multimodales aux outils de création de contenu. Les grands modèles de langage ont démontré des capacités inégalées en matière de compréhension et de génération de textes. Cependant, générer simultanément des images avec des récits textuels cohérents reste encore un domaine à développer
Récemment, une équipe de recherche de l'Université de Californie à Santa Cruz a proposé MiniGPT-5, une méthode basée sur le concept de « vote générateur » technologie de génération de langage visuel entrelacé.

Combinant un mécanisme de diffusion stable avec LLM via un jeton visuel spécial « vote génératif », MiniGPT-5 annonce une nouvelle voie pour un modèle de génération multimodale qualifié. Dans le même temps, la méthode de formation en deux étapes proposée dans cet article souligne l’importance de l’étape de base sans description, permettant au modèle de prospérer même lorsque les données sont rares. La phase générale de la méthode ne nécessite pas d'annotations spécifiques au domaine, ce qui distingue notre solution des méthodes existantes. Afin de garantir que le texte et les images générés sont harmonieux, la stratégie de double perte de cet article entre en jeu, qui est encore renforcée par la méthode de vote génératif et la méthode de classification
Sur la base de ces techniques, ce travail marque une approche transformatrice. En utilisant ViT (Vision Transformer) et Qformer et un grand modèle de langage, l'équipe de recherche convertit les entrées multimodales en votes génératifs et les associe de manière transparente à Stable Diffusion2.1 haute résolution pour obtenir une génération d'images contextuelles. Cet article combine des images comme entrée auxiliaire avec des méthodes d'ajustement des instructions et est pionnier dans l'utilisation des pertes de génération de texte et d'images, élargissant ainsi la synergie entre le texte et la vision
MiniGPT-5 correspond à des modèles tels que les contraintes CLIP, fusionnant intelligemment le modèle de diffusion avec MiniGPT-4 permet d'obtenir de meilleurs résultats multimodaux sans s'appuyer sur des annotations spécifiques au domaine. Plus important encore, notre stratégie peut tirer parti des avancées des modèles de base du langage visuel multimodal et fournir un nouveau modèle pour améliorer les capacités génératives multimodales.
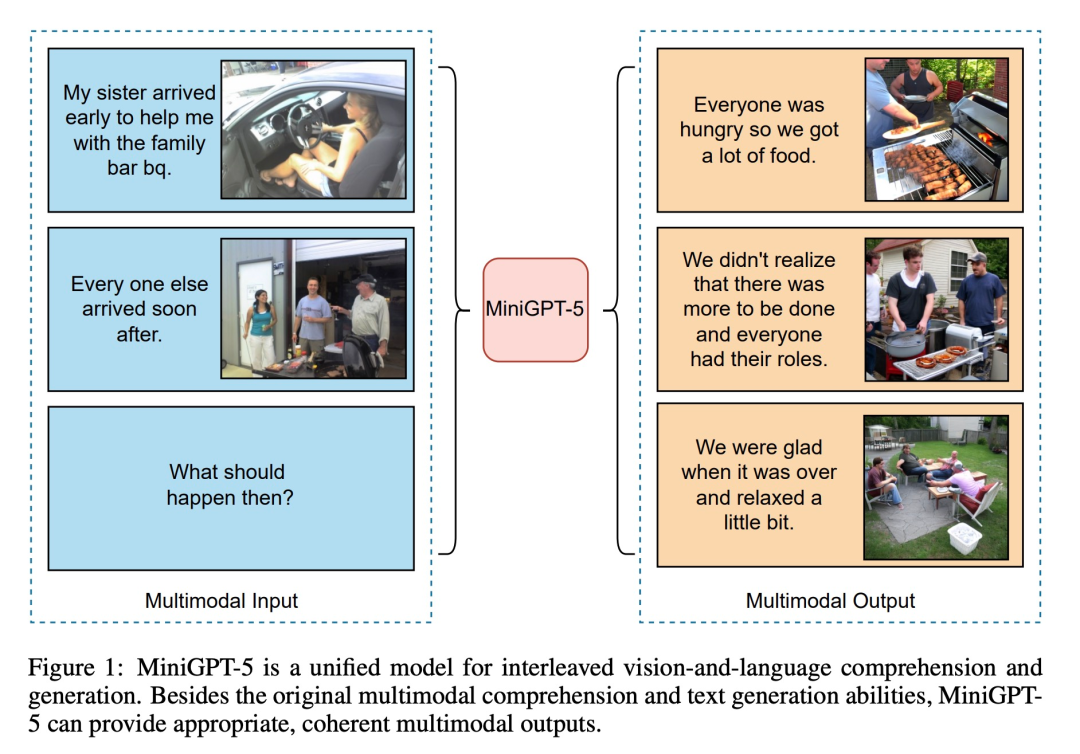
Comme le montre la figure ci-dessous, en plus des capacités originales de compréhension multimodale et de génération de texte, MiniGPT5 peut également fournir une sortie multimodale raisonnable et cohérente :
La contribution de cet article est se reflète sous trois aspects :
Maintenant, comprenons en détail le contenu de cette recherche
Afin de permettre de grands modèles de langage dotés de capacités de génération multimodale, les chercheurs ont introduit un cadre structuré pour Des modèles de langage multimodaux pré-entraînés à grande échelle et des modèles de génération de texte en image sont intégrés. Afin de résoudre les différences entre les différents domaines de modèles, ils ont introduit des symboles visuels spéciaux « votes génératifs » (votes génératifs), qui peuvent être entraînés directement sur les images originales. De plus, une méthode de formation en deux étapes est avancée, combinée à une stratégie d'amorçage sans classificateur, pour améliorer encore la qualité de la génération.
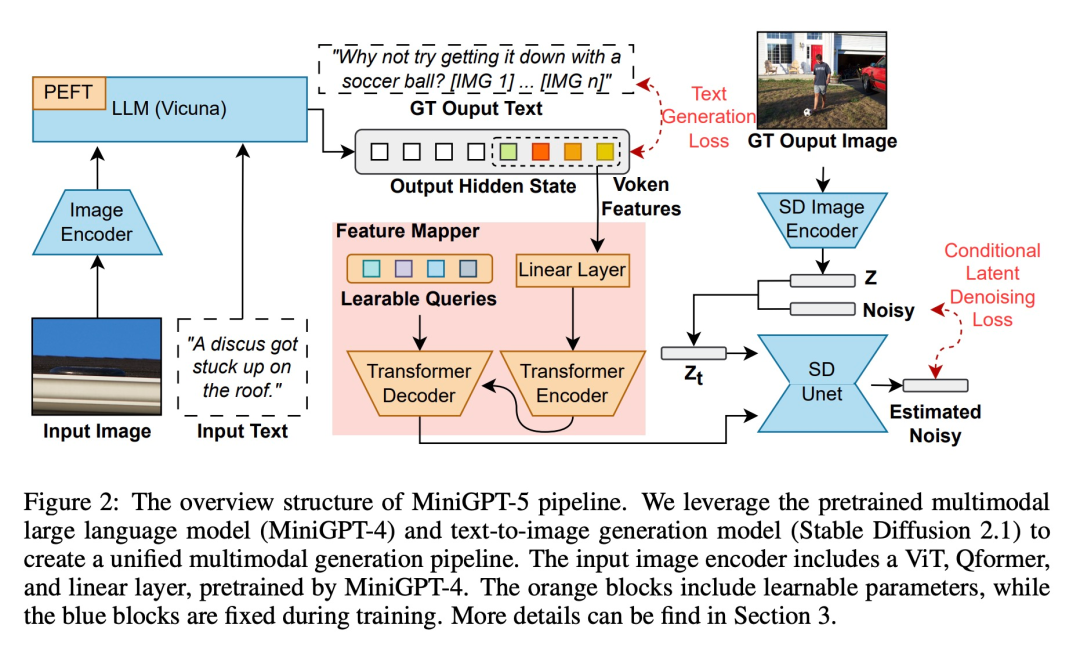
Étape d'entrée multimodale
Les progrès récents dans les grands modèles multimodaux (tels que MiniGPT-4) se concentrent principalement sur la compréhension multimodale, étant capable de gérer les images comme des entrées continues. Pour étendre ses fonctionnalités à la génération multimodale, les chercheurs ont introduit des Vokens génératifs spécialement conçus pour produire des fonctionnalités visuelles. En outre, ils ont également adopté une technologie de réglage fin efficace des paramètres dans le cadre du Large Language Model (LLM) pour l'apprentissage de la sortie multimodale
Génération de sortie multimodale
Afin de garantir que le système génératif token est Pour générer un alignement précis des modèles, les chercheurs ont développé un module de cartographie compact pour la correspondance dimensionnelle et ont introduit plusieurs pertes supervisées, notamment la perte d'espace de texte et la perte de modèle de diffusion latente. La perte d'espace de texte aide le modèle à connaître avec précision l'emplacement des jetons, tandis que la perte de diffusion latente aligne directement les jetons avec les caractéristiques visuelles appropriées. Puisque les caractéristiques des symboles génératifs sont directement guidées par les images, cette méthode ne nécessite pas de descriptions complètes des images et permet un apprentissage sans description
stratégie d'entraînement
Étant donné qu'il existe une existence non négligeable entre le domaine du texte et le domaine de l'image Changement de domaine, les chercheurs ont découvert que l'entraînement directement sur un ensemble limité de données de texte et d'image entrelacées peut entraîner un désalignement et une dégradation de la qualité de l'image.
Ils ont donc utilisé deux stratégies d'entraînement différentes pour atténuer ce problème. La première stratégie consiste à utiliser des techniques d'amorçage sans classificateur pour améliorer l'efficacité des jetons générés tout au long du processus de diffusion ; la deuxième stratégie se déroule en deux phases : une phase initiale de pré-formation axée sur l'alignement approximatif des fonctionnalités, suivie d'une phase de réglage fin. sur l'apprentissage de fonctionnalités complexes.
Afin d'évaluer l'efficacité du modèle, les chercheurs ont sélectionné plusieurs critères et mené une série d'évaluations. Le but de l'expérience est de répondre à plusieurs questions clés :
Afin d'évaluer les performances du modèle MiniGPT-5 à différentes étapes de formation, nous avons effectué une analyse quantitative, et les résultats sont présentés dans la figure 3 :

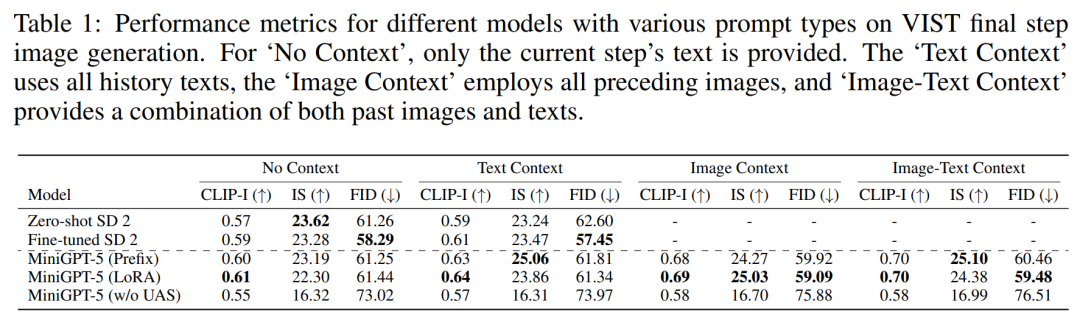
Pour démontrer la polyvalence et la robustesse du modèle proposé, nous l'avons évalué, couvrant à la fois les domaines visuels (métriques liées à l'image) et linguistiques (métriques textuelles). évaluation de l'étape , c'est-à-dire que l'image correspondante est générée selon le modèle d'invite de la dernière étape et les résultats sont présentés dans le tableau 1.
Le MiniGPT-5 surpasse le SD 2 affiné dans les trois paramètres. Notamment, le score CLIP du modèle MiniGPT-5 (LoRA) surpasse systématiquement les autres variantes sur plusieurs types d'invites, en particulier lors de la combinaison d'invites d'image et de texte. D'autre part, le score FID met en évidence la compétitivité du modèle MiniGPT-5 (Prefix), indiquant qu'il peut y avoir un compromis entre la qualité d'intégration de l'image (reflétée par le score CLIP) et la diversité et l'authenticité de l'image (reflétée par le score CLIP). score FID). Par rapport à un modèle formé directement sur VIST sans inclure d'étape d'enregistrement à modalité unique (MiniGPT-5 sans UAS), bien que le modèle conserve la capacité de générer des images significatives, la qualité et la cohérence des images sont considérablement réduites. Cette observation met en évidence l'importance de la stratégie de formation en deux étapes
Évaluation en plusieurs étapes VIST
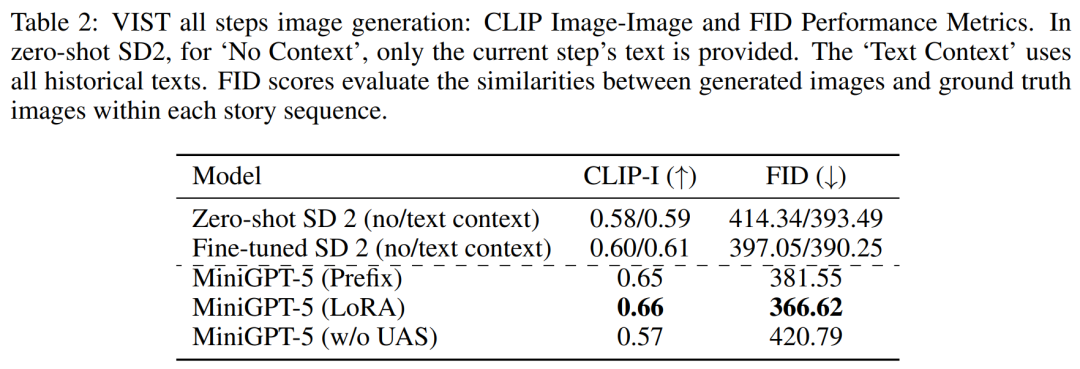
 Dans une évaluation plus détaillée et plus complète, les chercheurs ont systématiquement alimenté le modèle avant l'historique. contexte, et les images et récits qui en résultent sont ensuite évalués à chaque étape.
Dans une évaluation plus détaillée et plus complète, les chercheurs ont systématiquement alimenté le modèle avant l'historique. contexte, et les images et récits qui en résultent sont ensuite évalués à chaque étape.
Le Tableau 2 et le Tableau 3 résument les résultats de ces expériences, fournissant un aperçu des performances respectivement sur les métriques d'image et de langage. Les résultats expérimentaux montrent que MiniGPT-5 est capable d'exploiter des signaux d'entrée multimodaux de long niveau pour générer des images cohérentes et de haute qualité sur toutes les données sans compromettre les capacités de compréhension multimodale du modèle original. Cela met en évidence l'efficacité du MiniGPT-5 dans différents environnements 8 % générés plus pertinents les récits textuels dans 52,06 % des cas, ont fourni une meilleure qualité d'image dans 52,06 % des cas et ont généré une sortie multimodale plus cohérente dans 57,62 % des scènes. Comparées à une base de référence en deux étapes qui adopte une narration invite texte-image sans mode subjonctif, ces données démontrent clairement ses plus fortes capacités de génération multimodale.
 MMDialog Plusieurs cycles d'évaluation
MMDialog Plusieurs cycles d'évaluation
Selon les résultats du tableau 5, MiniGPT-5 est plus précis que le modèle de base Divter pour générer des réponses textuelles. Bien que les images générées soient de qualité similaire, MiniGPT-5 surpasse le modèle de base en termes de corrélations MM, ce qui suggère qu'il est mieux à même d'apprendre à positionner la génération d'images de manière appropriée et de générer des réponses multimodales hautement cohérentes
Jetons un coup d'œil aux résultats de MiniGPT-5 et voyons à quel point il est efficace. La figure 7 ci-dessous montre la comparaison entre MiniGPT-5 et le modèle de base sur l'ensemble de vérification CC3M
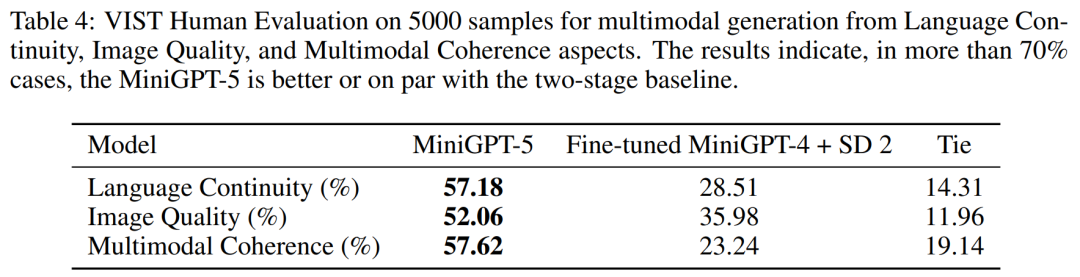
La figure 8 ci-dessous montre la comparaison entre MiniGPT-5 et le modèle de base sur l'ensemble de vérification VIST
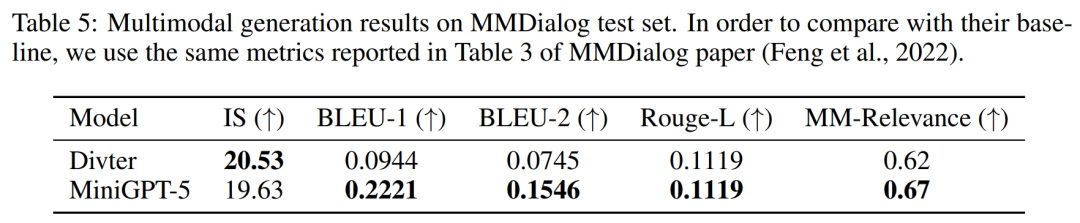 La figure 9 ci-dessous montre la comparaison entre MiniGPT-5 et le modèle de base sur l'ensemble de test MMDialog.
La figure 9 ci-dessous montre la comparaison entre MiniGPT-5 et le modèle de base sur l'ensemble de test MMDialog.
 Pour plus de détails sur la recherche, veuillez vous référer à l'article original.
Pour plus de détails sur la recherche, veuillez vous référer à l'article original.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment lier des données dans une liste déroulante
Comment lier des données dans une liste déroulante
 Comment définir la taille de la police HTML
Comment définir la taille de la police HTML
 technologie informatique en nuage
technologie informatique en nuage
 La différence entre counta et count
La différence entre counta et count
 Les membres Weibo peuvent-ils consulter les enregistrements des visiteurs ?
Les membres Weibo peuvent-ils consulter les enregistrements des visiteurs ?
 Introduction aux modificateurs de contrôle d'accès Java
Introduction aux modificateurs de contrôle d'accès Java
 Utilisation de while
Utilisation de while
 Plateforme formelle de trading de devises numériques
Plateforme formelle de trading de devises numériques








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



