
 Périphériques technologiques
IA
Les capacités de raisonnement de type humain de GPT-4 ont été grandement améliorées ! L'Académie chinoise des sciences a proposé une « penser la communication », la pensée analogique va au-delà du CoT et peut être appliquée immédiatement
Périphériques technologiques
IA
Les capacités de raisonnement de type humain de GPT-4 ont été grandement améliorées ! L'Académie chinoise des sciences a proposé une « penser la communication », la pensée analogique va au-delà du CoT et peut être appliquée immédiatement
Les capacités de raisonnement de type humain de GPT-4 ont été grandement améliorées ! L'Académie chinoise des sciences a proposé une « penser la communication », la pensée analogique va au-delà du CoT et peut être appliquée immédiatement

De nos jours, des modèles de réseaux neuronaux géants tels que GPT-4 et PaLM ont émergé et ont démontré d'étonnantes capacités d'apprentissage sur quelques échantillons.
À partir de simples instructions, ils peuvent raisonner sur un texte, écrire des histoires, répondre à des questions, programmer...
Des chercheurs de l'Académie chinoise des sciences et de l'Université de Yale ont proposé un nouveau cadre, nommé « Propagation de la pensée ». , vise à améliorer la capacité de raisonnement du LLM grâce à la « pensée analogique »

Adresse papier : https://arxiv.org/abs/2310.03965
La « communication par la pensée » s'inspire de la cognition humaine, qui est que lorsque nous rencontrons un nouveau problème, nous le comparons souvent à des problèmes similaires que nous avons déjà résolus pour en dériver des stratégies.
La clé de cette approche est donc d'explorer des problèmes « similaires » liés à l'entrée avant de résoudre le problème d'entrée
Enfin, leurs solutions peuvent être utilisées hors des sentiers battus, ou pour extraire des informations pour une planification utile.
Il est prévisible que la « communication pensée » propose de nouvelles idées sur les limitations inhérentes aux capacités logiques du LLM, permettant aux grands modèles d'utiliser « l'analogie » pour résoudre des problèmes comme ceux des humains.
Le raisonnement en plusieurs étapes LLM, vaincu par les humains
De toute évidence, LLM est bon pour le raisonnement de base basé sur des invites, mais il a encore des difficultés lorsqu'il s'agit de problèmes complexes en plusieurs étapes, tels que l'optimisation et la planification.
D’un autre côté, les humains s’appuieront sur leur intuition issue d’expériences similaires pour résoudre de nouveaux problèmes.
L'incapacité des grands modèles à y parvenir est due à ses limites inhérentes
Parce que la connaissance du LLM provient entièrement des modèles présents dans les données d'entraînement et ne peut pas vraiment comprendre le langage ou les concepts. Par conséquent, en tant que modèles statistiques, ils sont difficiles à réaliser des généralisations combinatoires complexes.
LLM manque de capacités de raisonnement systématique et ne peut pas raisonner étape par étape comme les humains pour résoudre des problèmes difficiles, ce qui est le plus important
De plus, comme le raisonnement des grands modèles est partiel et à courte vue, il est donc difficile pour LLM de trouver la meilleure solution, et il est difficile de maintenir la cohérence du raisonnement sur une longue période de temps
Pour résumer, les problèmes des grands modèles en preuve mathématique, planification stratégique et raisonnement logique peut principalement être attribué à deux facteurs fondamentaux :
- L'incapacité de réutiliser les connaissances de l'expérience précédente.
Les humains accumulent des connaissances et des intuitions réutilisables issues de la pratique, ce qui aide à résoudre de nouveaux problèmes. En revanche, LLM aborde chaque problème « à partir de zéro » et n’emprunte pas aux solutions précédentes.
Les erreurs composées dans le raisonnement en plusieurs étapes font référence aux erreurs qui se produisent lors d'un raisonnement en plusieurs étapes.
Les humains surveillent leurs propres chaînes de raisonnement et modifient les étapes initiales si nécessaire. Cependant, les erreurs commises par LLM dans les premières étapes du raisonnement seront amplifiées car elles conduiront le raisonnement ultérieur dans la mauvaise direction. Les faiblesses ci-dessus empêchent sérieusement LLM de traiter des situations complexes qui nécessitent une optimisation globale ou une planification à long terme. .
Des chercheurs ont proposé une toute nouvelle solution à ce problème, à savoir la propagation de la pensée
Le cadre TP
Grâce à la pensée analogique, le LLM peut raisonner comme les humains
Chez les chercheurs, il semble que le raisonnement à partir de zéro échoue de réutiliser les connaissances acquises lors de la résolution de problèmes similaires et peut conduire à une accumulation d'erreurs dans les étapes de raisonnement intermédiaires.
Et "Thought Spread" peut explorer des problèmes similaires liés au problème d'entrée et s'inspirer de solutions à des problèmes similaires.
La figure ci-dessous montre la comparaison entre la « propagation de la pensée » (TP) et d'autres technologies représentatives. Pour le problème d'entrée p, IO, CoT et ToT doivent tous raisonner à partir de zéro pour arriver à la solution s
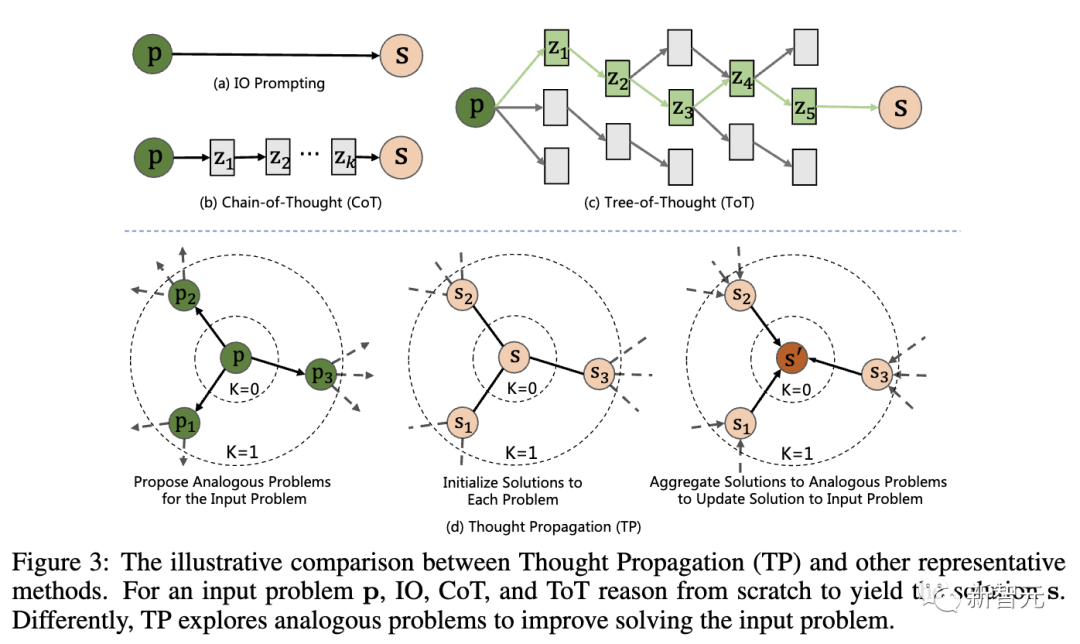
Plus précisément, TP comprend trois étapes :
1. LLM génère un ensemble de questions similaires via des invites qui présentent des similitudes avec la question d'entrée. Cela guidera le modèle pour récupérer des expériences antérieures potentiellement pertinentes.
2. Résolvez des problèmes similaires : Laissez LLM résoudre tous les problèmes similaires grâce à la technologie d'invite existante, telle que CoT.
3. Solution récapitulative : Il existe 2 manières différentes : déduire directement une nouvelle solution au problème d'entrée basée sur la solution analogue ; dériver un plan avancé en comparant la solution analogue au problème ou à la stratégie d'entrée.
De cette façon, les grands modèles peuvent tirer parti de l'expérience et des heuristiques antérieures, et leur raisonnement initial peut être recoupé avec des solutions analogiques pour affiner davantage ces solutionsIl convient de mentionner que "Penser la propagation" n'a rien à voir avec le modèle et peut effectuer une seule étape de résolution de problème basée sur n'importe quelle méthode d'invite
Le caractère unique de cette méthode est de stimuler la pensée analogique LLM, guidant ainsi le processus de raisonnement complexe
"Penser "Communication" peut faire en sorte que le LLM ressemble davantage à un être humain, mais les résultats réels devront parler d'eux-mêmes.
Des chercheurs de l'Académie chinoise des sciences et de Yale ont évalué dans 3 tâches :
- Raisonnement sur le plus court chemin : Besoin de trouver le meilleur chemin entre les nœuds dans un graphe nécessitant une planification et une recherche globales. Même sur des graphiques simples, les techniques standards échouent.
- Écriture créative : Générer des histoires cohérentes et créatives est un défi ouvert. Lorsqu'on lui donne des invites générales de haut niveau, LLM perd souvent sa cohérence ou sa logique.
- Planification des agents LLM : Les agents LLM interagissant avec des environnements textuels ont du mal avec des stratégies à long terme. Leurs plans « dérivent » souvent ou restent bloqués dans des cycles.
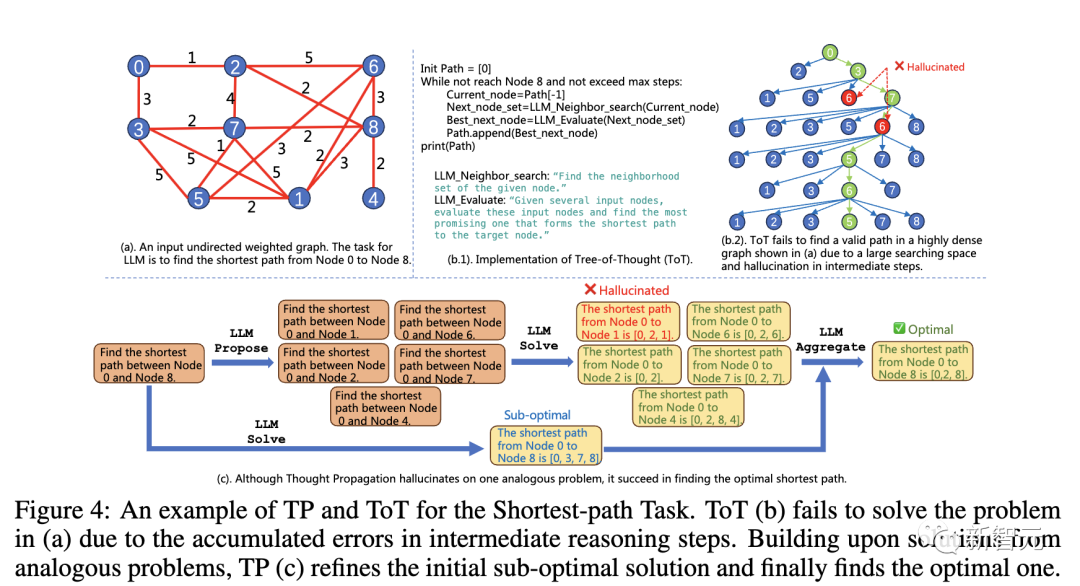
Inférence du plus court cheminDans la tâche d'inférence du plus court chemin, les méthodes existantes rencontrent des problèmes insolubles
Bien que le graphique en (a) soit très simple, puisque l'inférence commence à partir de 0, ces La méthode ne peut que permettre à LLM de trouver des solutions sous-optimales (b, c), ou même de visiter à plusieurs reprises le nœud intermédiaire (d)

En raison de l'intermédiaire étape d'inférence Les erreurs s'accumulent et ToT (b) ne parvient pas à résoudre le problème en (a). Sur la base de solutions à des problèmes similaires, TP (c) affine la solution sous-optimale initiale et trouve finalement la solution optimale.
De plus, en raison de la valeur la plus faible de la réécriture en ligne (OLR), le chemin effectif généré (TP) est le plus proche du chemin optimal par rapport à la ligne de base
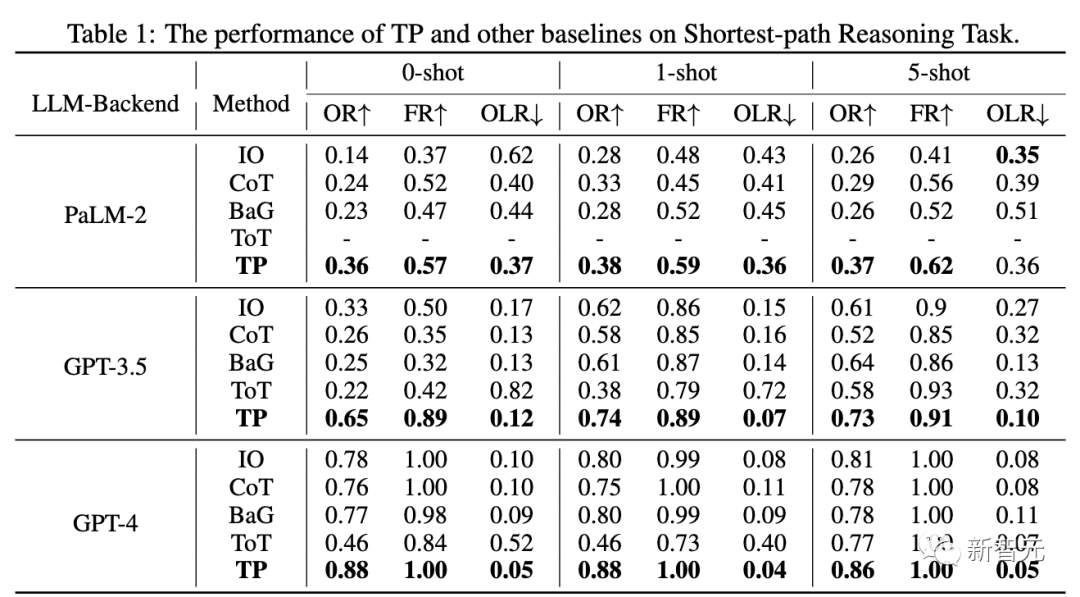
Dans différents paramètres, le coût du jeton du TP de couche 1 est similaire à celui du ToT. Cependant, le TP de couche 1 a atteint des performances très compétitives dans la recherche du chemin le plus court optimal.
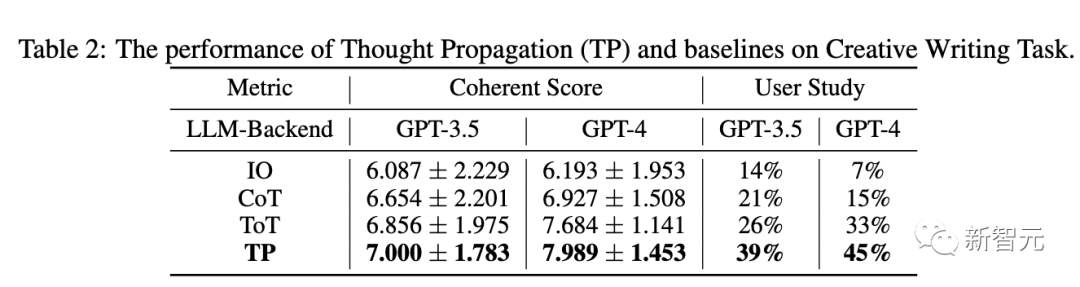
De plus, par rapport à la couche 0 TP (IO), le gain de performances de la couche 1 TP est également très significatif. La figure 5(a) montre l'augmentation du coût du jeton pour le TP de couche 2. Le tableau 2 ci-dessous montre les performances du TP et des lignes de base dans GPT-3.5 et GPT-4. En termes de cohérence, TP dépasse la référence. De plus, dans des études d'utilisateurs, TP a augmenté de 13 % la préférence humaine pour l'écriture créative. Dans la troisième évaluation de tâche, les chercheurs ont utilisé la suite de jeux ALFWorld pour instancier la tâche de planification d'agent LLM dans 134 environnements. TP augmente le taux d'achèvement des tâches de 15 % dans la planification des agents LLM. Cela démontre la supériorité du TP réflexif pour une planification réussie lors de l'exécution de tâches similaires. Selon les résultats expérimentaux ci-dessus, il est démontré que la « propagation de la pensée » peut être appliquée à une variété de tâches de raisonnement différentes et fonctionne bien dans toutes ces tâches "Penser Le modèle de "propagation" fournit une nouvelle technologie pour l'inférence LLM complexe. La pensée analogique est un signe de la capacité humaine à résoudre des problèmes. Elle peut apporter une série d'avantages systématiques, tels qu'une recherche et une correction d'erreurs plus efficaces. Dans des situations similaires, le LLM peut également inciter la pensée analogique à mieux surmonter. leurs propres faiblesses, telles que le manque de connaissances réutilisables et les erreurs locales en cascade, etc. Cependant, ces résultats ont certaines limites Générez des questions d'analogie utiles et gardez le chemin de raisonnement simple et pas facile. De plus, les chemins de raisonnement analogiques enchaînés plus longs peuvent devenir longs et difficiles à suivre. Dans le même temps, contrôler et coordonner des chaînes de raisonnement à plusieurs étapes est également une tâche assez difficile Cependant, la « propagation de la pensée » nous offre toujours une méthode intéressante en résolvant de manière créative les défauts de raisonnement du LLM. Avec un développement ultérieur, la pensée analogique pourrait rendre la capacité de raisonnement de LLM encore plus puissante. Cela indique également la voie à suivre pour atteindre l'objectif d'un raisonnement humain plus étroit dans de grands modèles de langage Il est un chercheur national en reconnaissance de formes à l'Institut d'automatisation de l'Académie chinoise des sciences. Professeur en laboratoire et à l'Université de l'Académie chinoise des sciences, il est également membre de l'IAPR et membre senior de l'IEEE Il a auparavant obtenu son baccalauréat et sa maîtrise de l'Université de Dalian. de technologie et son doctorat de l'Institut d'automatisation de l'Académie chinoise des sciences en 2009 Ses axes de recherche sont les algorithmes biométriques (reconnaissance et synthèse des visages, reconnaissance de l'iris, ré-identification des personnes), l'apprentissage des représentations (en utilisant les faibles/auto-identifications). apprentissage supervisé ou par transfert réseaux pré-entraînés), apprentissage génératif (modèles génératifs, génération d'images, traduction d'images). Il a publié plus de 200 articles dans des revues et conférences internationales, y compris des revues internationales bien connues telles que IEEE TPAMI, IEEE TIP, IEEE TIFS, IEEE TNN, IEEE TCSVT et des revues internationales de premier plan telles que CVPR, ICCV, ECCV, NeurIPS, etc. Conférence Il est membre du comité de rédaction de IEEE TIP, IEEE TBIOM et Pattern Recognition, et a également été président régional de conférences internationales telles que CVPR, ECCV, NeurIPS, ICML, CIPR et IJCAI Yu Junchi est un doctorant de quatrième année à l'Institut d'automatisation de l'Académie chinoise des sciences. Son superviseur est le professeur Heran. Il a précédemment effectué un stage au Laboratoire d'intelligence artificielle de Tencent, en collaboration avec le Dr Tingyang Xu, le Dr Yu. Rong, le Dr Yatao Bian et le professeur Huang de Junzhou ont travaillé ensemble. Aujourd'hui, il est étudiant en échange au département d'informatique de l'université de Yale, étudiant sous la direction du professeur Rex Ying . Son objectif est de développer une méthode d'apprentissage de graphes fiable (TwGL) avec une bonne interprétabilité et portabilité, et d'explorer son application dans. le domaine de la biochimie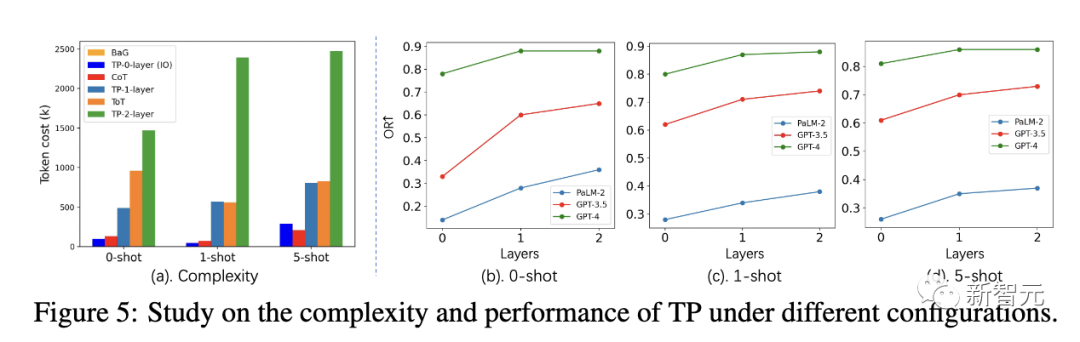
Creative Writing
Planification d'agent LLM

La clé pour améliorer le raisonnement LLM
Introduction à l'auteur
Ran He (然)

Junchi Yu (俞junchi)

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Imaginez un modèle d'intelligence artificielle qui non seulement a la capacité de surpasser l'informatique traditionnelle, mais qui permet également d'obtenir des performances plus efficaces à moindre coût. Ce n'est pas de la science-fiction, DeepSeek-V2[1], le modèle MoE open source le plus puissant au monde est ici. DeepSeek-V2 est un puissant mélange de modèle de langage d'experts (MoE) présentant les caractéristiques d'une formation économique et d'une inférence efficace. Il est constitué de 236B paramètres, dont 21B servent à activer chaque marqueur. Par rapport à DeepSeek67B, DeepSeek-V2 offre des performances plus élevées, tout en économisant 42,5 % des coûts de formation, en réduisant le cache KV de 93,3 % et en augmentant le débit de génération maximal à 5,76 fois. DeepSeek est une entreprise explorant l'intelligence artificielle générale
 L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L’IA change effectivement les mathématiques. Récemment, Tao Zhexuan, qui a prêté une attention particulière à cette question, a transmis le dernier numéro du « Bulletin de l'American Mathematical Society » (Bulletin de l'American Mathematical Society). En se concentrant sur le thème « Les machines changeront-elles les mathématiques ? », de nombreux mathématiciens ont exprimé leurs opinions. L'ensemble du processus a été plein d'étincelles, intense et passionnant. L'auteur dispose d'une équipe solide, comprenant Akshay Venkatesh, lauréat de la médaille Fields, le mathématicien chinois Zheng Lejun, l'informaticien de l'Université de New York Ernest Davis et de nombreux autres universitaires bien connus du secteur. Le monde de l’IA a radicalement changé. Vous savez, bon nombre de ces articles ont été soumis il y a un an.
 KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
Plus tôt ce mois-ci, des chercheurs du MIT et d'autres institutions ont proposé une alternative très prometteuse au MLP – KAN. KAN surpasse MLP en termes de précision et d’interprétabilité. Et il peut surpasser le MLP fonctionnant avec un plus grand nombre de paramètres avec un très petit nombre de paramètres. Par exemple, les auteurs ont déclaré avoir utilisé KAN pour reproduire les résultats de DeepMind avec un réseau plus petit et un degré d'automatisation plus élevé. Plus précisément, le MLP de DeepMind compte environ 300 000 paramètres, tandis que le KAN n'en compte qu'environ 200. KAN a une base mathématique solide comme MLP est basé sur le théorème d'approximation universelle, tandis que KAN est basé sur le théorème de représentation de Kolmogorov-Arnold. Comme le montre la figure ci-dessous, KAN a
 Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas entre officiellement dans l’ère des robots électriques ! Hier, l'Atlas hydraulique s'est retiré "en larmes" de la scène de l'histoire. Aujourd'hui, Boston Dynamics a annoncé que l'Atlas électrique était au travail. Il semble que dans le domaine des robots humanoïdes commerciaux, Boston Dynamics soit déterminé à concurrencer Tesla. Après la sortie de la nouvelle vidéo, elle a déjà été visionnée par plus d’un million de personnes en seulement dix heures. Les personnes âgées partent et de nouveaux rôles apparaissent. C'est une nécessité historique. Il ne fait aucun doute que cette année est l’année explosive des robots humanoïdes. Les internautes ont commenté : Les progrès des robots ont fait ressembler la cérémonie d'ouverture de cette année à des êtres humains, et le degré de liberté est bien plus grand que celui des humains. Mais n'est-ce vraiment pas un film d'horreur ? Au début de la vidéo, Atlas est allongé calmement sur le sol, apparemment sur le dos. Ce qui suit est à couper le souffle
 Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Les performances de JAX, promu par Google, ont dépassé celles de Pytorch et TensorFlow lors de récents tests de référence, se classant au premier rang sur 7 indicateurs. Et le test n’a pas été fait sur le TPU présentant les meilleures performances JAX. Bien que parmi les développeurs, Pytorch soit toujours plus populaire que Tensorflow. Mais à l’avenir, des modèles plus volumineux seront peut-être formés et exécutés sur la base de la plate-forme JAX. Modèles Récemment, l'équipe Keras a comparé trois backends (TensorFlow, JAX, PyTorch) avec l'implémentation native de PyTorch et Keras2 avec TensorFlow. Premièrement, ils sélectionnent un ensemble de
 Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
La dernière vidéo du robot Optimus de Tesla est sortie, et il peut déjà fonctionner en usine. À vitesse normale, il trie les batteries (les batteries 4680 de Tesla) comme ceci : Le responsable a également publié à quoi cela ressemble à une vitesse 20 fois supérieure - sur un petit "poste de travail", en sélectionnant et en sélectionnant et en sélectionnant : Cette fois, il est publié L'un des points forts de la vidéo est qu'Optimus réalise ce travail en usine, de manière totalement autonome, sans intervention humaine tout au long du processus. Et du point de vue d'Optimus, il peut également récupérer et placer la batterie tordue, en se concentrant sur la correction automatique des erreurs : concernant la main d'Optimus, le scientifique de NVIDIA Jim Fan a donné une évaluation élevée : la main d'Optimus est l'un des robots à cinq doigts du monde. le plus adroit. Ses mains ne sont pas seulement tactiles
 FisheyeDetNet : le premier algorithme de détection de cible basé sur une caméra fisheye
Apr 26, 2024 am 11:37 AM
FisheyeDetNet : le premier algorithme de détection de cible basé sur une caméra fisheye
Apr 26, 2024 am 11:37 AM
La détection de cibles est un problème relativement mature dans les systèmes de conduite autonome, parmi lesquels la détection des piétons est l'un des premiers algorithmes à être déployés. Des recherches très complètes ont été menées dans la plupart des articles. Cependant, la perception de la distance à l’aide de caméras fisheye pour une vue panoramique est relativement moins étudiée. En raison de la distorsion radiale importante, la représentation standard du cadre de délimitation est difficile à mettre en œuvre dans les caméras fisheye. Pour alléger la description ci-dessus, nous explorons les conceptions étendues de boîtes englobantes, d'ellipses et de polygones généraux dans des représentations polaires/angulaires et définissons une métrique de segmentation d'instance mIOU pour analyser ces représentations. Le modèle fisheyeDetNet proposé avec une forme polygonale surpasse les autres modèles et atteint simultanément 49,5 % de mAP sur l'ensemble de données de la caméra fisheye Valeo pour la conduite autonome.
 DualBEV : dépassant largement BEVFormer et BEVDet4D, ouvrez le livre !
Mar 21, 2024 pm 05:21 PM
DualBEV : dépassant largement BEVFormer et BEVDet4D, ouvrez le livre !
Mar 21, 2024 pm 05:21 PM
Cet article explore le problème de la détection précise d'objets sous différents angles de vue (tels que la perspective et la vue à vol d'oiseau) dans la conduite autonome, en particulier comment transformer efficacement les caractéristiques de l'espace en perspective (PV) en vue à vol d'oiseau (BEV). implémenté via le module Visual Transformation (VT). Les méthodes existantes sont globalement divisées en deux stratégies : la conversion 2D en 3D et la conversion 3D en 2D. Les méthodes 2D vers 3D améliorent les caractéristiques 2D denses en prédisant les probabilités de profondeur, mais l'incertitude inhérente aux prévisions de profondeur, en particulier dans les régions éloignées, peut introduire des inexactitudes. Alors que les méthodes 3D vers 2D utilisent généralement des requêtes 3D pour échantillonner des fonctionnalités 2D et apprendre les poids d'attention de la correspondance entre les fonctionnalités 3D et 2D via un transformateur, ce qui augmente le temps de calcul et de déploiement.
