
 Périphériques technologiques
IA
Pensée inversée : le nouveau modèle de langage de raisonnement mathématique MetaMath entraîne de grands modèles
Périphériques technologiques
IA
Pensée inversée : le nouveau modèle de langage de raisonnement mathématique MetaMath entraîne de grands modèles
Pensée inversée : le nouveau modèle de langage de raisonnement mathématique MetaMath entraîne de grands modèles

Le raisonnement mathématique complexe est un indicateur important pour évaluer les capacités de raisonnement des grands modèles de langage. Actuellement, les ensembles de données de raisonnement mathématique couramment utilisés ont des tailles d'échantillon limitées et une diversité de problèmes insuffisante, ce qui entraîne le phénomène de « renversement de la malédiction » en général. modèles de langage, c'est-à-dire un modèle formé sur « A ». Le modèle de langage de « est B » ne peut pas être généralisé à « B est A » [1]. La forme spécifique de ce phénomène dans les tâches de raisonnement mathématique est la suivante : étant donné un problème mathématique, le modèle de langage est efficace pour utiliser le raisonnement direct pour résoudre le problème, mais n'a pas la capacité de résoudre le problème avec un raisonnement inverse. Le raisonnement inversé est très courant dans les problèmes mathématiques, comme le montrent les 2 exemples suivants.
1. Question classique - Poulet et lapin dans la même cage
- Raisonnement avancé : Il y a 23 poules et 12 lapins dans la cage. Combien de têtes et combien de pieds y a-t-il dans la cage ?
- Raisonnement inverse : Il y a plusieurs poules et lapins dans la même cage. En comptant du haut, il y a 35 têtes, et en comptant du bas, il y a 94 pattes. Combien y a-t-il de poules et de lapins dans la cage ?
2. Problème GSM8K
- Raisonnement direct : James achète 5 paquets de bœuf de 4 livres chacun. Le prix du bœuf est de 5,50 $ la livre ?
- Raisonnement inversé. : James achète x paquets de bœuf de 4 livres chacun. Le prix du bœuf est de 5,50 $ par livre. Si nous savons que la réponse à la question ci-dessus est 110, quelle est la valeur de la variable inconnue x ?
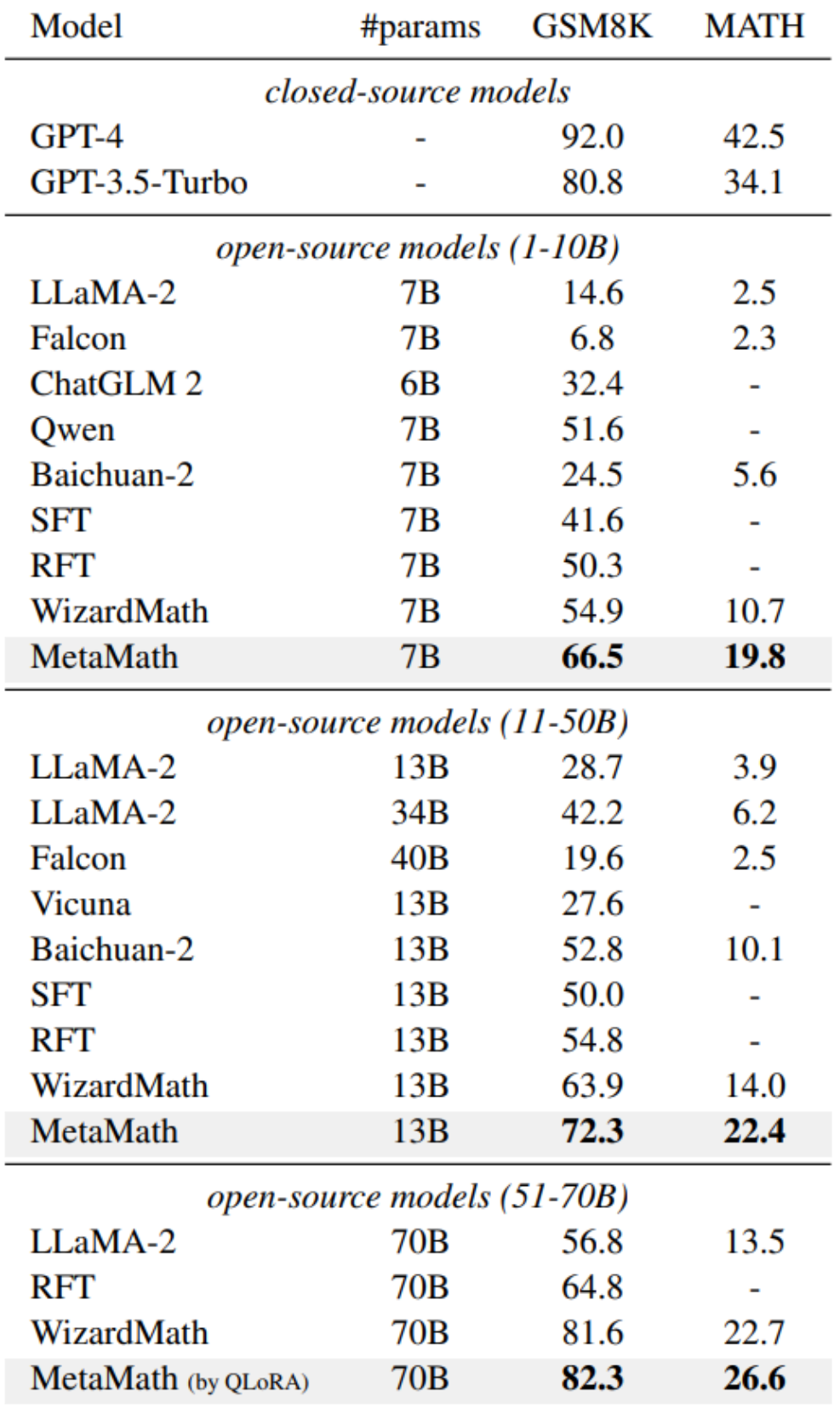
Afin d'améliorer les capacités de raisonnement avant et arrière du modèle, des chercheurs de Cambridge, de l'Université des sciences et technologies de Hong Kong et de Huawei ont proposé l'ensemble de données MetaMathQA basé sur deux ensembles de données mathématiques couramment utilisés (GSM8K et MATH) : un avec une large couverture et un ensemble de données de raisonnement mathématique de haute qualité. MetaMathQA se compose de 395 000 paires de questions-réponses mathématiques avant-inverse générées par un grand modèle de langage. Ils ont affiné LLaMA-2 sur l'ensemble de données MetaMathQA pour obtenir MetaMath, un grand modèle de langage axé sur le raisonnement mathématique (vers l'avant et l'inverse), qui a atteint SOTA sur l'ensemble de données de raisonnement mathématique. L'ensemble de données MetaMathQA et les modèles MetaMath à différentes échelles ont été open source pour être utilisés par les chercheurs.

- Adresse du projet : https://meta-math.github.io/
- Adresse papier : https://arxiv.org/abs/2309.12284
- Adresse des données : https : //huggingface.co/datasets/meta-math/MetaMathQA
- Adresse du modèle : https://huggingface.co/meta-math
- Adresse du code : https://github.com/meta-math/ MetaMath
Dans l'ensemble de données GSM8K-Backward, nous avons construit une expérience d'inférence inverse. Les résultats expérimentaux montrent que par rapport aux méthodes telles que SFT, RFT et WizardMath, la méthode actuelle est peu performante sur les problèmes d'inférence inverse. En revanche, le modèle MetaMath atteint d'excellentes performances en inférence directe et inverse. 1. Augmentation des réponses :
Face à une question, une chaîne de réflexion capable d'obtenir le résultat correct est générée via un grand modèle de langage en tant qu'augmentation des données.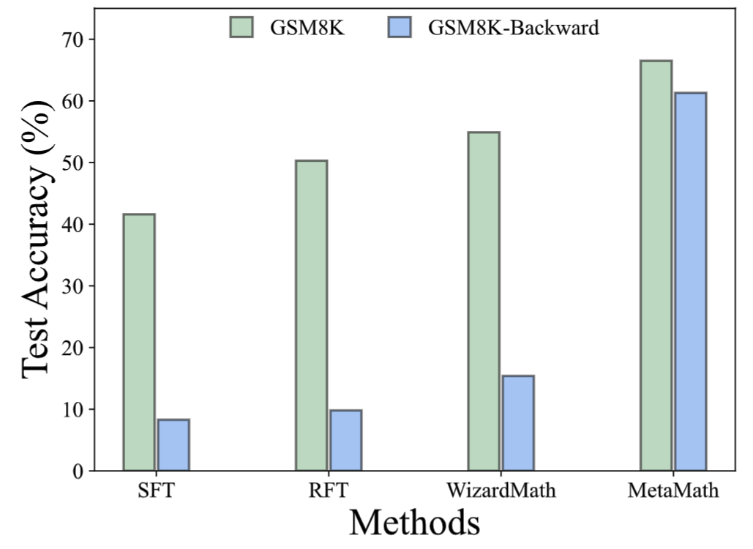
Question : James achète 5 paquets de bœuf de 4 livres chacun Le prix du bœuf est de 5,50 $ la livre ?
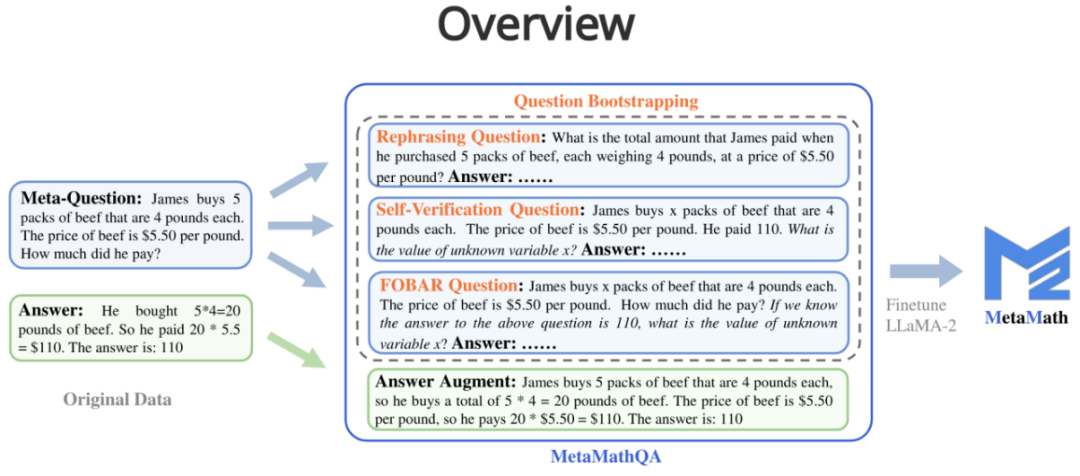 Réponse : James achète 5 paquets de bœuf de 4 livres. chacun, donc il achète un total de 5 * 4 = 20 livres de bœuf. Le prix du bœuf est de 5,50 $ la livre, donc il paie 20 * 5,50 $ = 110 $. La réponse est : 110.
Réponse : James achète 5 paquets de bœuf de 4 livres. chacun, donc il achète un total de 5 * 4 = 20 livres de bœuf. Le prix du bœuf est de 5,50 $ la livre, donc il paie 20 * 5,50 $ = 110 $. La réponse est : 110.
2. Question (amélioration de la réécriture des questions) :
À partir d'une méta-question, réécrivez la question à travers un grand modèle de langage et générez une chaîne de réflexion qui obtient le résultat correct en tant qu'augmentation des données. 3. Question FOBAR (amélioration de la question inverse FOBAR) : Étant donné une méta-question, le nombre dans la condition de masque est x, étant donné la réponse originale et l'inverse de x pour générer une question inverse, et basé sur Ce problème inverse génère la chaîne de pensée correcte pour effectuer une augmentation des données (exemple d'inversion : « Si nous savons que la réponse à la question ci-dessus est 110, quelle est la valeur de la variable inconnue x ? »). 4. Question d'auto-vérification (amélioration de la question inverse d'auto-vérification) : Basée sur FOBAR, l'augmentation des données est effectuée en réécrivant la partie de la question inverse en déclarations énoncées via un grand modèle de langage (exemple réécrit : "Combien a fait il paie ? » (avec la réponse 110) a été réécrit comme « Il a payé 110 »).
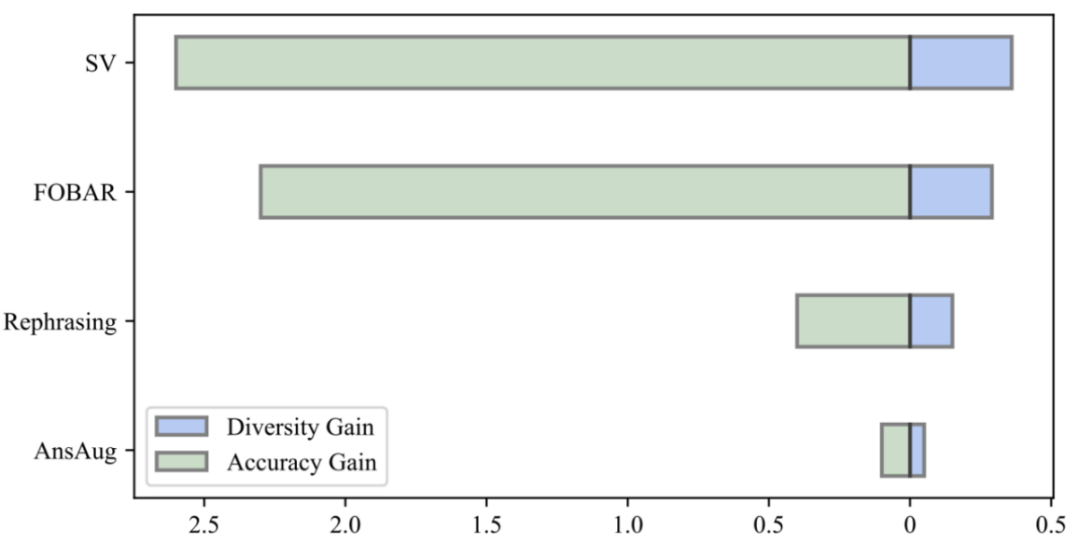
Comme le montre la figure ci-dessus, les chercheurs ont calculé le modèle LLaMA-2-7B dans chaque partie des données de réponse uniquement, GSM8K CoT et les données MetaMathQA définissent le niveau de confusion. La perplexité de l'ensemble de données MetaMathQA est nettement inférieure à celle des deux autres ensembles de données, ce qui indique qu'il a une plus grande capacité d'apprentissage et peut être plus utile pour révéler la connaissance latente du modèle Pourquoi MetaMathQA est-il utile ? Augmentation de la diversité des données de la chaîne de pensée En comparant le gain de diversité des données et le gain de précision du modèle, les chercheurs ont constaté que l'introduction de la même quantité de données augmentées par reformulation, FOBAR et SV entraînait des gains de diversité évidents et une amélioration significative du modèle. précision. En revanche, l’utilisation seule de l’augmentation des réponses a entraîné une saturation significative de la précision. Une fois que la précision atteint la saturation, l'ajout de données AnsAug n'apportera qu'une amélioration limitée des performances
Selon « l'hypothèse d'alignement de surface » [2], la capacité des grands modèles de langage vient de pré- formation, tandis que les données des tâches en aval activent les capacités inhérentes du modèle de langage appris lors de la pré-formation. Par conséquent, cela soulève deux questions importantes : (i) quel type de données active le plus efficacement les connaissances latentes, et (ii) pourquoi un ensemble de données est-il meilleur qu’un autre pour une telle activation ?
 Pourquoi MetaMathQA est-il utile ? Amélioration de la qualité (perplexité) des données de la chaîne de réflexion
Pourquoi MetaMathQA est-il utile ? Amélioration de la qualité (perplexité) des données de la chaîne de réflexion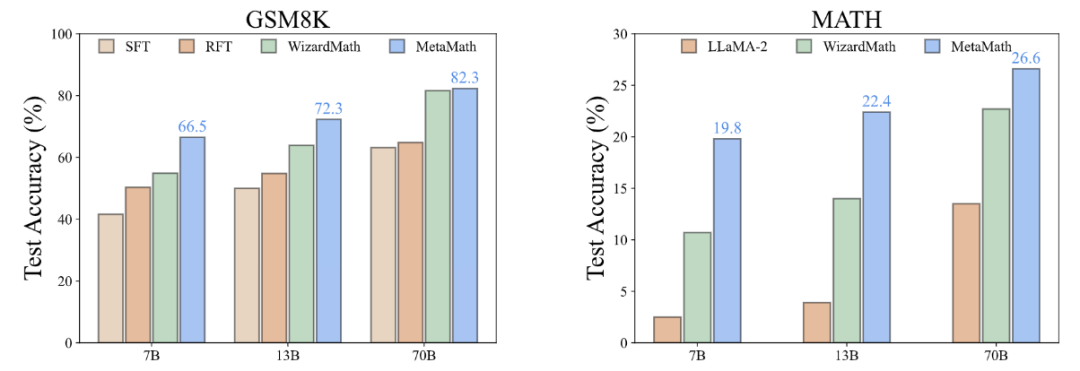
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment implémenter le tri des fichiers par Debian Readdir
Apr 13, 2025 am 09:06 AM
Comment implémenter le tri des fichiers par Debian Readdir
Apr 13, 2025 am 09:06 AM
Dans Debian Systems, la fonction ReadDir est utilisée pour lire le contenu du répertoire, mais l'ordre dans lequel il revient n'est pas prédéfini. Pour trier les fichiers dans un répertoire, vous devez d'abord lire tous les fichiers, puis les trier à l'aide de la fonction QSORT. Le code suivant montre comment trier les fichiers de répertoire à l'aide de ReadDir et QSort dans Debian System: # include # include # include # include # include // Fonction de comparaison personnalisée, utilisée pour qsortintCompare (constvoid * a, constvoid * b) {returnstrcmp (* (
 Comment optimiser les performances de Debian Readdir
Apr 13, 2025 am 08:48 AM
Comment optimiser les performances de Debian Readdir
Apr 13, 2025 am 08:48 AM
Dans Debian Systems, les appels du système ReadDir sont utilisés pour lire le contenu des répertoires. Si ses performances ne sont pas bonnes, essayez la stratégie d'optimisation suivante: simplifiez le nombre de fichiers d'annuaire: divisez les grands répertoires en plusieurs petits répertoires autant que possible, en réduisant le nombre d'éléments traités par appel ReadDir. Activer la mise en cache de contenu du répertoire: construire un mécanisme de cache, mettre à jour le cache régulièrement ou lorsque le contenu du répertoire change et réduire les appels fréquents à Readdir. Les caches de mémoire (telles que Memcached ou Redis) ou les caches locales (telles que les fichiers ou les bases de données) peuvent être prises en compte. Adoptez une structure de données efficace: si vous implémentez vous-même la traversée du répertoire, sélectionnez des structures de données plus efficaces (telles que les tables de hachage au lieu de la recherche linéaire) pour stocker et accéder aux informations du répertoire
 Comment Debian Readdir s'intègre à d'autres outils
Apr 13, 2025 am 09:42 AM
Comment Debian Readdir s'intègre à d'autres outils
Apr 13, 2025 am 09:42 AM
La fonction ReadDir dans le système Debian est un appel système utilisé pour lire le contenu des répertoires et est souvent utilisé dans la programmation C. Cet article expliquera comment intégrer ReadDir avec d'autres outils pour améliorer sa fonctionnalité. Méthode 1: combinant d'abord le programme de langue C et le pipeline, écrivez un programme C pour appeler la fonction readdir et sortir le résultat: # include # include # include # includeIntmain (intargc, char * argv []) {dir * dir; structDirent * entrée; if (argc! = 2) {
 Conseils de configuration du pare-feu Debian Mail Server
Apr 13, 2025 am 11:42 AM
Conseils de configuration du pare-feu Debian Mail Server
Apr 13, 2025 am 11:42 AM
La configuration du pare-feu d'un serveur de courrier Debian est une étape importante pour assurer la sécurité du serveur. Voici plusieurs méthodes de configuration de pare-feu couramment utilisées, y compris l'utilisation d'iptables et de pare-feu. Utilisez les iptables pour configurer le pare-feu pour installer iptables (sinon déjà installé): Sudoapt-getUpDaSuDoapt-getinstalliptableView Règles actuelles iptables: Sudoiptable-L Configuration
 Comment apprendre Debian Syslog
Apr 13, 2025 am 11:51 AM
Comment apprendre Debian Syslog
Apr 13, 2025 am 11:51 AM
Ce guide vous guidera pour apprendre à utiliser Syslog dans Debian Systems. Syslog est un service clé dans les systèmes Linux pour les messages du système de journalisation et du journal d'application. Il aide les administrateurs à surveiller et à analyser l'activité du système pour identifier et résoudre rapidement les problèmes. 1. Connaissance de base de Syslog Les fonctions principales de Syslog comprennent: la collecte et la gestion des messages journaux de manière centralisée; Prise en charge de plusieurs formats de sortie de journal et des emplacements cibles (tels que les fichiers ou les réseaux); Fournir des fonctions de visualisation et de filtrage des journaux en temps réel. 2. Installer et configurer syslog (en utilisant RSYSLOG) Le système Debian utilise RSYSLOG par défaut. Vous pouvez l'installer avec la commande suivante: SudoaptupDatesud
 Comment configurer les règles de pare-feu pour Debian Syslog
Apr 13, 2025 am 06:51 AM
Comment configurer les règles de pare-feu pour Debian Syslog
Apr 13, 2025 am 06:51 AM
Cet article décrit comment configurer les règles de pare-feu à l'aide d'iptables ou UFW dans Debian Systems et d'utiliser Syslog pour enregistrer les activités de pare-feu. Méthode 1: Utiliser iptableIpTable est un puissant outil de pare-feu de ligne de commande dans Debian System. Afficher les règles existantes: utilisez la commande suivante pour afficher les règles iptables actuelles: Sudoiptables-L-N-V permet un accès IP spécifique: Par exemple, permettez l'adresse IP 192.168.1.100 pour accéder au port 80: Sudoiptables-Ainput-PTCP - DPORT80-S192.16
 Comment définir le niveau de journal Debian Apache
Apr 13, 2025 am 08:33 AM
Comment définir le niveau de journal Debian Apache
Apr 13, 2025 am 08:33 AM
Cet article décrit comment ajuster le niveau de journalisation du serveur Apacheweb dans le système Debian. En modifiant le fichier de configuration, vous pouvez contrôler le niveau verbeux des informations de journal enregistrées par Apache. Méthode 1: Modifiez le fichier de configuration principal pour localiser le fichier de configuration: le fichier de configuration d'Apache2.x est généralement situé dans le répertoire / etc / apache2 /. Le nom de fichier peut être apache2.conf ou httpd.conf, selon votre méthode d'installation. Modifier le fichier de configuration: Ouvrez le fichier de configuration avec les autorisations racine à l'aide d'un éditeur de texte (comme Nano): Sutonano / etc / apache2 / apache2.conf
 Comment Debian OpenSSL empêche les attaques de l'homme au milieu
Apr 13, 2025 am 10:30 AM
Comment Debian OpenSSL empêche les attaques de l'homme au milieu
Apr 13, 2025 am 10:30 AM
Dans Debian Systems, OpenSSL est une bibliothèque importante pour le chiffrement, le décryptage et la gestion des certificats. Pour empêcher une attaque d'homme dans le milieu (MITM), les mesures suivantes peuvent être prises: utilisez HTTPS: assurez-vous que toutes les demandes de réseau utilisent le protocole HTTPS au lieu de HTTP. HTTPS utilise TLS (Protocole de sécurité de la couche de transport) pour chiffrer les données de communication pour garantir que les données ne sont pas volées ou falsifiées pendant la transmission. Vérifiez le certificat de serveur: vérifiez manuellement le certificat de serveur sur le client pour vous assurer qu'il est digne de confiance. Le serveur peut être vérifié manuellement via la méthode du délégué d'URLSession
