
 Périphériques technologiques
IA
Le travail innovant de l'équipe de Chen Danqi : Obtention de SOTA à 5% de coût, déclenchant un engouement pour la « tonte d'alpaga »
Périphériques technologiques
IA
Le travail innovant de l'équipe de Chen Danqi : Obtention de SOTA à 5% de coût, déclenchant un engouement pour la « tonte d'alpaga »
Le travail innovant de l'équipe de Chen Danqi : Obtention de SOTA à 5% de coût, déclenchant un engouement pour la « tonte d'alpaga »

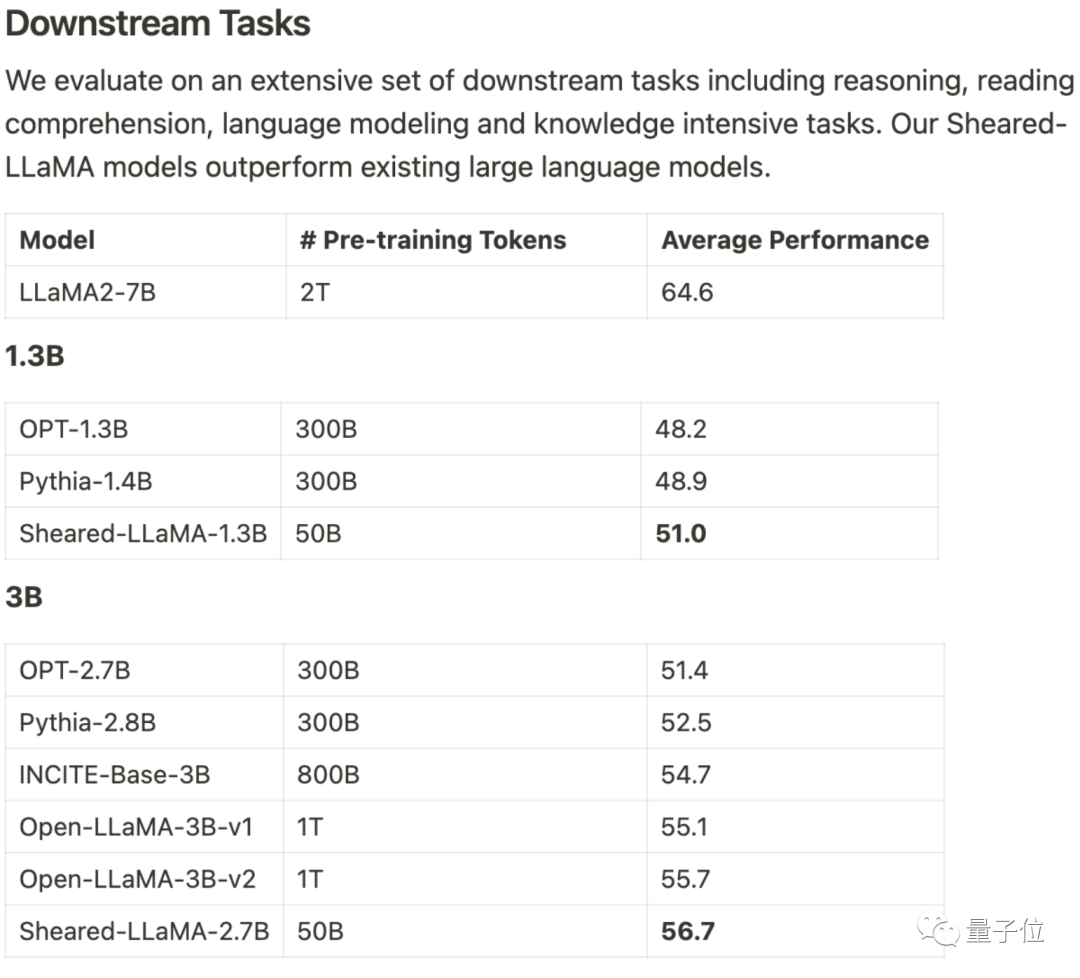
Il n'utilise que 3% du montant du calcul et 5% du coût pour obtenir SOTA, dominant les grands modèles open source à l'échelle 1B-3B.
Ce résultat vient de l'équipe de Princeton Chen Danqi, et s'appelle LLM-ShearingMéthode d'élagage grand modèle.

Basés sur Alpaca LLaMA 2 7B, les modèles Sheared-LLama taillés 1,3B et 3B sont obtenus grâce à une taille structurée directionnelle.

Pour surpasser le modèle précédent de la même échelle dans l'évaluation des tâches en aval, il doit être réécrit
Xia Mengzhou, le premier auteur, a déclaré : « C'est beaucoup plus rentable que la pré-formation à partir de zéro."

L'article donne également un exemple de sortie élaguée de Sheared-LLaMA, indiquant que malgré la taille de seulement 1,3B et 2,7B, elle peut déjà générer des réponses cohérentes et riches.
Pour la même tâche de « jouer le rôle d'un analyste de l'industrie des semi-conducteurs », la structure de réponse de la version 2.7B est encore plus claire.

L'équipe a déclaré que bien qu'actuellement seule la version Llama 2 7B ait été utilisée pour les expériences d'élagage, la méthode peut être étendue à d'autres architectures de modèles et peut également être étendue à n'importe quelle échelle .
Un avantage supplémentaire après l'élagage est que vous pouvez choisir des ensembles de données de haute qualité pour un pré-entraînement continu

Certains développeurs ont déclaré qu'il y a à peine 6 mois, presque tout le monde pensait que les modèles inférieurs à 65B n'avaient aucune utilisation pratique
À ce rythme, je parie que les modèles 1B-3B seront également d’une grande valeur, sinon maintenant, du moins bientôt.

Traitez l'élagage comme une optimisation contrainte
LLM-Shearing, plus précisément une sorte de élagage structuré directionnel, qui taille un grand modèle selon une structure cible spécifiée.
Les méthodes d'élagage précédentes peuvent entraîner une dégradation des performances du modèle car certaines structures seront supprimées, affectant sa capacité d'expression
Nous proposons une nouvelle méthode en traitant l'élagage comme un problème d'optimisation contraint. Nous recherchons des sous-réseaux qui correspondent à la structure spécifiée en apprenant la matrice du masque d'élagage et visons à maximiser les performances
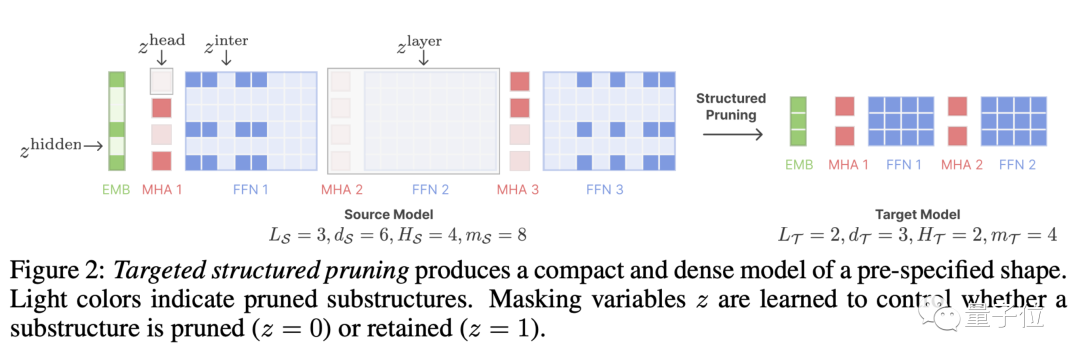
Ensuite, nous continuons à pré-entraîner le modèle élagué et à restaurer dans une certaine mesure la perte de performances causée par l'élagage.
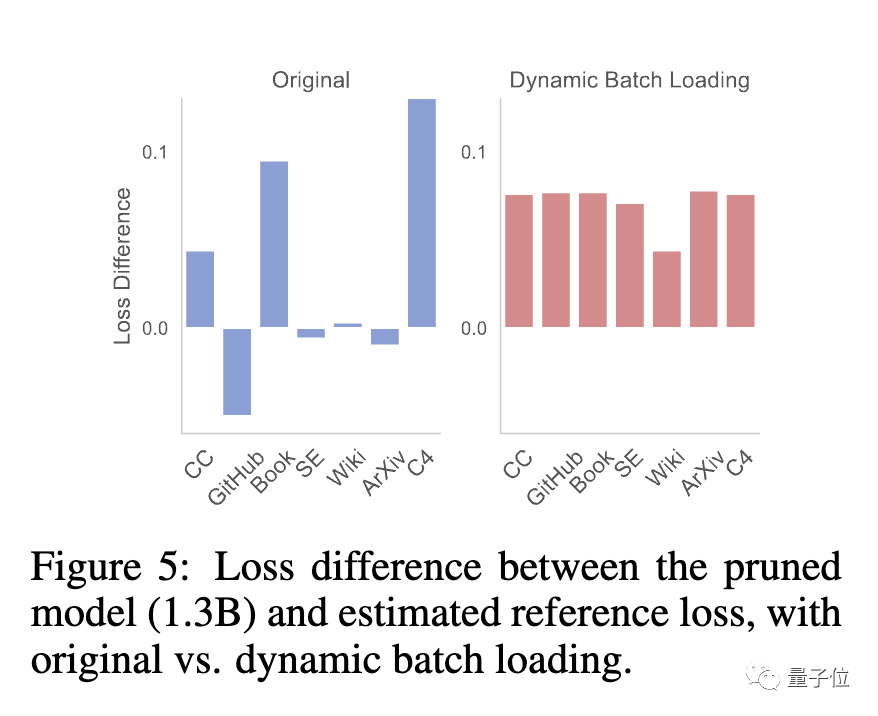
À ce stade, l'équipe a constaté que le modèle élagué et le modèle formé à partir de zéro présentaient des taux de réduction des pertes différents pour différents ensembles de données, ce qui entraînait le problème d'une faible efficacité d'utilisation des données.
À cette fin, l'équipe a proposé Dynamic Batch Loading (Dynamic Batch Loading), qui ajuste dynamiquement la proportion de données dans chaque domaine en fonction du taux de réduction des pertes du modèle sur différentes données de domaine, améliorant ainsi l'efficacité de l'utilisation des données.
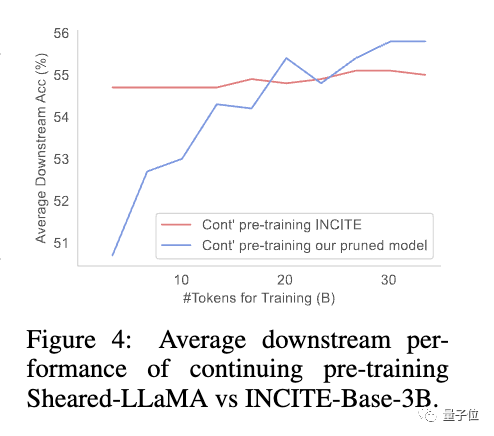
L'étude a révélé que même si les modèles élagués ont des performances initiales médiocres par rapport aux modèles de taille équivalente formés à partir de zéro, ils peuvent rapidement s'améliorer avec un pré-entraînement continu et éventuellement surpasser
Cela montre que l'élagage à partir d'une base solide des branches du modèle , ce qui peut offrir de meilleures conditions d’initialisation pour poursuivre la pré-formation.
continuera à être mis à jour, venez couper un par un
Les auteurs de l'article sont des doctorants de Princeton Xia Mengzhou, Gao Tianyu, Tsinghua Zhiyuan Zeng, Princeton professeur adjoint Chen Dan琦 .
Xia Mengzhou est diplômée de l'Université de Fudan avec un baccalauréat et de la CMU avec une maîtrise.
Gao Tianyu est un étudiant de premier cycle diplômé de l'Université Tsinghua. Il a remporté le prix spécial Tsinghua en 2019
Tous deux sont étudiants de Chen Danqi, et Chen Danqi est actuellement professeur adjoint à l'Université de Princeton et membre du Princeton Natural. Language Processing Group La co-responsable de
Récemment, sur sa page d'accueil personnelle, Chen Danqi a mis à jour son orientation de recherche.
"Cette période est principalement axée sur le développement de modèles à grande échelle, et les sujets de recherche incluent : "
- Comment la récupération peut jouer un rôle important dans les modèles de nouvelle génération, en améliorant le réalisme, l'adaptabilité, l'interprétabilité et la crédibilité.
- Formation et déploiement à faible coût de grands modèles, méthodes de formation améliorées, gestion des données, compression des modèles et optimisation de l'adaptation des tâches en aval.
- Également intéressé par les travaux qui améliorent véritablement la compréhension des capacités et des limites des grands modèles actuels, tant sur le plan empirique que théorique.

Sheared-Llama est déjà disponible sur Hugging Face
L'équipe a déclaré qu'elle continuerait à mettre à jour la bibliothèque open source
Lorsque de plus grands modèles seront publiés, coupez-les un par un et continuez à sortir des petits modèles performants.

One More Thing
Je dois dire que les grands modèles sont vraiment trop bouclés maintenant.
Mengzhou Xia vient de publier une correction, déclarant que la technologie SOTA a été utilisée lors de la rédaction de l'article, mais qu'une fois l'article terminé, elle a été dépassée par la dernière technologie Stable-LM-3B
Adresse du papier : https : / /arxiv.org/abs/2310.06694
Hugging Face : https://huggingface.co/princeton-nlp
Lien vers la page d'accueil du projet : https://xiamengzhou.github.io/sheared-llama/
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment optimiser les performances de Debian Readdir
Apr 13, 2025 am 08:48 AM
Comment optimiser les performances de Debian Readdir
Apr 13, 2025 am 08:48 AM
Dans Debian Systems, les appels du système ReadDir sont utilisés pour lire le contenu des répertoires. Si ses performances ne sont pas bonnes, essayez la stratégie d'optimisation suivante: simplifiez le nombre de fichiers d'annuaire: divisez les grands répertoires en plusieurs petits répertoires autant que possible, en réduisant le nombre d'éléments traités par appel ReadDir. Activer la mise en cache de contenu du répertoire: construire un mécanisme de cache, mettre à jour le cache régulièrement ou lorsque le contenu du répertoire change et réduire les appels fréquents à Readdir. Les caches de mémoire (telles que Memcached ou Redis) ou les caches locales (telles que les fichiers ou les bases de données) peuvent être prises en compte. Adoptez une structure de données efficace: si vous implémentez vous-même la traversée du répertoire, sélectionnez des structures de données plus efficaces (telles que les tables de hachage au lieu de la recherche linéaire) pour stocker et accéder aux informations du répertoire
 Conseils de configuration du pare-feu Debian Mail Server
Apr 13, 2025 am 11:42 AM
Conseils de configuration du pare-feu Debian Mail Server
Apr 13, 2025 am 11:42 AM
La configuration du pare-feu d'un serveur de courrier Debian est une étape importante pour assurer la sécurité du serveur. Voici plusieurs méthodes de configuration de pare-feu couramment utilisées, y compris l'utilisation d'iptables et de pare-feu. Utilisez les iptables pour configurer le pare-feu pour installer iptables (sinon déjà installé): Sudoapt-getUpDaSuDoapt-getinstalliptableView Règles actuelles iptables: Sudoiptable-L Configuration
 Comment implémenter le tri des fichiers par Debian Readdir
Apr 13, 2025 am 09:06 AM
Comment implémenter le tri des fichiers par Debian Readdir
Apr 13, 2025 am 09:06 AM
Dans Debian Systems, la fonction ReadDir est utilisée pour lire le contenu du répertoire, mais l'ordre dans lequel il revient n'est pas prédéfini. Pour trier les fichiers dans un répertoire, vous devez d'abord lire tous les fichiers, puis les trier à l'aide de la fonction QSORT. Le code suivant montre comment trier les fichiers de répertoire à l'aide de ReadDir et QSort dans Debian System: # include # include # include # include # include // Fonction de comparaison personnalisée, utilisée pour qsortintCompare (constvoid * a, constvoid * b) {returnstrcmp (* (
 Comment définir le niveau de journal Debian Apache
Apr 13, 2025 am 08:33 AM
Comment définir le niveau de journal Debian Apache
Apr 13, 2025 am 08:33 AM
Cet article décrit comment ajuster le niveau de journalisation du serveur Apacheweb dans le système Debian. En modifiant le fichier de configuration, vous pouvez contrôler le niveau verbeux des informations de journal enregistrées par Apache. Méthode 1: Modifiez le fichier de configuration principal pour localiser le fichier de configuration: le fichier de configuration d'Apache2.x est généralement situé dans le répertoire / etc / apache2 /. Le nom de fichier peut être apache2.conf ou httpd.conf, selon votre méthode d'installation. Modifier le fichier de configuration: Ouvrez le fichier de configuration avec les autorisations racine à l'aide d'un éditeur de texte (comme Nano): Sutonano / etc / apache2 / apache2.conf
 Comment Debian OpenSSL empêche les attaques de l'homme au milieu
Apr 13, 2025 am 10:30 AM
Comment Debian OpenSSL empêche les attaques de l'homme au milieu
Apr 13, 2025 am 10:30 AM
Dans Debian Systems, OpenSSL est une bibliothèque importante pour le chiffrement, le décryptage et la gestion des certificats. Pour empêcher une attaque d'homme dans le milieu (MITM), les mesures suivantes peuvent être prises: utilisez HTTPS: assurez-vous que toutes les demandes de réseau utilisent le protocole HTTPS au lieu de HTTP. HTTPS utilise TLS (Protocole de sécurité de la couche de transport) pour chiffrer les données de communication pour garantir que les données ne sont pas volées ou falsifiées pendant la transmission. Vérifiez le certificat de serveur: vérifiez manuellement le certificat de serveur sur le client pour vous assurer qu'il est digne de confiance. Le serveur peut être vérifié manuellement via la méthode du délégué d'URLSession
 Méthode d'installation du certificat de Debian Mail Server SSL
Apr 13, 2025 am 11:39 AM
Méthode d'installation du certificat de Debian Mail Server SSL
Apr 13, 2025 am 11:39 AM
Les étapes pour installer un certificat SSL sur le serveur de messagerie Debian sont les suivantes: 1. Installez d'abord la boîte à outils OpenSSL, assurez-vous que la boîte à outils OpenSSL est déjà installée sur votre système. Si ce n'est pas installé, vous pouvez utiliser la commande suivante pour installer: Sudoapt-getUpDaSuDoapt-getInstallOpenSSL2. Générer la clé privée et la demande de certificat Suivant, utilisez OpenSSL pour générer une clé privée RSA 2048 bits et une demande de certificat (RSE): OpenSS
 Comment Debian Readdir s'intègre à d'autres outils
Apr 13, 2025 am 09:42 AM
Comment Debian Readdir s'intègre à d'autres outils
Apr 13, 2025 am 09:42 AM
La fonction ReadDir dans le système Debian est un appel système utilisé pour lire le contenu des répertoires et est souvent utilisé dans la programmation C. Cet article expliquera comment intégrer ReadDir avec d'autres outils pour améliorer sa fonctionnalité. Méthode 1: combinant d'abord le programme de langue C et le pipeline, écrivez un programme C pour appeler la fonction readdir et sortir le résultat: # include # include # include # includeIntmain (intargc, char * argv []) {dir * dir; structDirent * entrée; if (argc! = 2) {
 Comment faire Debian Hadoop Log Management
Apr 13, 2025 am 10:45 AM
Comment faire Debian Hadoop Log Management
Apr 13, 2025 am 10:45 AM
Gérer les journaux Hadoop sur Debian, vous pouvez suivre les étapes et les meilleures pratiques suivantes: l'agrégation de journal Activer l'agrégation de journaux: définir yarn.log-aggregation-inable à true dans le fichier yarn-site.xml pour activer l'agrégation de journaux. Configurer la stratégie de rétention du journal: Définissez Yarn.log-agregation.retain-secondes pour définir le temps de rétention du journal, tel que 172800 secondes (2 jours). Spécifiez le chemin de stockage des journaux: via yarn.n
