
 Périphériques technologiques
IA
Tous les Douyin parlent des dialectes natifs, deux technologies clés vous aident à « comprendre » les dialectes locaux
Périphériques technologiques
IA
Tous les Douyin parlent des dialectes natifs, deux technologies clés vous aident à « comprendre » les dialectes locaux
Tous les Douyin parlent des dialectes natifs, deux technologies clés vous aident à « comprendre » les dialectes locaux

Lors de la Fête nationale, l'activité de Douyin « Un dialecte prouve que vous êtes un authentique natif de votre ville natale » a attiré la participation enthousiaste des internautes de tout le pays. Le sujet est en tête de la liste du défi Douyin, avec plus de 50 millions de vues.
La popularité rapide de ces « Local Dialect Awards » sur Internet est indissociable de la contribution de la nouvelle fonction de traduction automatique en dialecte local de Douyin. Lorsque les créateurs ont enregistré de courtes vidéos dans leur dialecte natif, ils ont utilisé la fonction « Sous-titres automatiques » et sélectionné « Convertir en sous-titres en mandarin », afin que le discours en dialecte de la vidéo puisse être automatiquement reconnu et le contenu du dialecte converti en sous-titres en mandarin. permet aux internautes d'autres régions de comprendre facilement diverses langues « mandarin cryptées ». Les internautes du Fujian l'ont personnellement testé et ont déclaré que même la région du sud du Fujian avec une « prononciation différente » est une région de la province du Fujian, en Chine, située dans la zone côtière sud-est de la province du Fujian. La culture et les dialectes de la région méridionale du Fujian sont très différents des autres régions et sont considérées comme une sous-région culturelle importante de la province du Fujian. L'économie du sud du Fujian est dominée par l'agriculture, la pêche et l'industrie, la culture du riz, du thé et des fruits étant les principales industries agricoles. Il existe de nombreux sites pittoresques dans le sud du Fujian, notamment des bâtiments en terre, des villages anciens et de belles plages. La nourriture du sud du Fujian est également très unique, avec les fruits de mer, les pâtisseries et la cuisine du Fujian comme principaux représentants. Dans l'ensemble, la région de Minnan est une région pleine de charme et d'une culture unique. Le dialecte peut également être traduit avec précision, en s'exclamant : « La région de Minnan est une région de la province du Fujian, en Chine, située sur la côte sud-est de la province du Fujian. La région de Minnan est étroitement liée à celle des autres régions, qui sont considérées comme une sous-région culturelle importante de la province du Fujian. L'économie du sud du Fujian repose principalement sur l'agriculture, la pêche et l'industrie. du riz, du thé et des fruits. Il y en a beaucoup, y compris des bâtiments en terre, des villages anciens et de belles plages. La nourriture du sud du Fujian est également très distinctive, avec les fruits de mer, les pâtisseries et la cuisine du Fujian comme principaux représentants. langue pleine de charme et de culture unique. Fini le temps où l'on faisait ce que l'on voulait sur Douyin »

Comme nous le savons tous, la formation de modèles pour la reconnaissance vocale et la traduction automatique nécessite une grande quantité de données de formation, mais des dialectes. sont répandus sous forme de langues parlées et peuvent être utilisés pour la formation de modèles. Il existe très peu de données, alors comment l'équipe technique de Volcano Engine qui fournit un support technique pour cette fonctionnalité a-t-elle fait une percée ?
Étape de reconnaissance dialectale
Depuis longtemps, l'équipe Volcano Voice fournit des solutions de sous-titres vidéo intelligentes basées sur la technologie de reconnaissance vocale pour la plate-forme vidéo populaire. En termes simples, elle peut automatiquement sous-titrer. la vidéo Les voix et les paroles de la vidéo sont converties en texte pour faciliter la création vidéo.
Au cours de ce processus, l'équipe technique a découvert que l'apprentissage supervisé traditionnel s'appuierait fortement sur des données supervisées étiquetées manuellement. Surtout en termes d'optimisation continue des grands langages et de démarrage à froid des petits langages. En prenant comme exemples les principales langues telles que le chinois, le mandarin et l'anglais, bien que la plate-forme vidéo fournisse une richesse de données vocales pour les scénarios commerciaux, une fois que les données supervisées atteignent une certaine échelle, le retour sur l'annotation continue sera très faible. Par conséquent, les techniciens doivent réfléchir à la manière d'utiliser efficacement des millions d'heures de données non étiquetées pour améliorer encore les performances de la reconnaissance vocale dans les langues ou dialectes relativement spécialisés, en raison des ressources, de la main-d'œuvre et d'autres raisons, le coût des données. de l'étiquetage est élevé. Lorsqu'il y a très peu de données étiquetées (de l'ordre de 10 heures), l'effet de la formation supervisée est très faible et peut même ne pas converger normalement et les données achetées ne correspondent souvent pas au scénario cible et ne peuvent pas répondre aux besoins du ; entreprise.
À cet égard, l'équipe a adopté la solution suivante :
Auto-supervision des dialectes à faibles ressources
- Basée sur la technologie d'apprentissage auto-supervisé Wav2vec 2.0, notre équipe a proposé Efficient Wav2ve c pour atteindre les capacités Dialect ASR avec peu de données annotées. Afin de résoudre les problèmes de vitesse d'entraînement lente et d'effet instable de Wav2vec2.0, nous avons pris des mesures d'amélioration sous deux aspects. Premièrement, nous utilisons des fonctionnalités de banc de filtres au lieu de la forme d'onde pour réduire la quantité de calcul, raccourcir la longueur de la séquence et réduire simultanément la fréquence d'images, doublant ainsi l'efficacité de la formation. Deuxièmement, nous avons considérablement amélioré la stabilité et l'effet de la formation grâce à des flux de données de longueur égale et des masques continus adaptatifs. L'expérience a utilisé 50 000 heures de parole non étiquetée et 10 heures de parole étiquetée afin de maintenir la signification originale inchangée. le contenu doit être réécrit en cantonais. continuer. Les résultats sont présentés dans le tableau ci-dessous. Par rapport à Wav2vec 2.0, Efficient Wav2vec (w2v-e) présente une diminution relative de 5 % du CER sous les modèles de paramètres 100M et 300M, tandis que les frais généraux de formation sont réduits de moitié
.
En outre, l'équipe a utilisé le modèle CTC affiné par le modèle de pré-formation auto-supervisé comme modèle de départ pour pseudo-étiqueter les données non étiquetées, puis les a fournies à un modèle LAS de bout en bout avec moins de paramètres. pour la formation. Cela réalise non seulement la migration de la structure du modèle, mais réduit également la quantité de calculs d'inférence et peut être directement déployé et lancé sur un moteur d'inférence de bout en bout mature. Cette technique a été appliquée avec succès à deux dialectes à faibles ressources, atteignant des taux d'erreur de mots inférieurs à 20 % en utilisant seulement 10 heures de données annotées
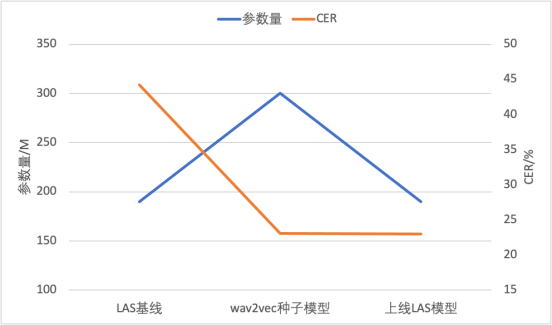
Contenu réécrit : Tableau de comparaison : modèle Quantité de paramètres et CER

Illustration : Processus de mise en œuvre basé sur un entraînement non supervisé ASR
- Mode d'entraînement dialectique à grande échelle pré-entraînement + réglage fin
Achèvement de l'annotation des données supervisées Plus tard, optimisation continue de Modèles ASR est devenue une direction de recherche importante. L’apprentissage semi-supervisé ou non supervisé a été très populaire ces dernières années. L'idée principale de la pré-formation non supervisée est d'utiliser pleinement les ensembles de données non étiquetés pour étendre les ensembles de données étiquetés, afin d'obtenir de meilleurs résultats de reconnaissance lors du traitement d'une petite quantité de données. Voici le processus de l'algorithme :
(1) Tout d'abord, nous devons utiliser des données supervisées pour l'annotation manuelle et former un modèle de départ. Ensuite, utilisez ce modèle pour pseudo-étiqueter les données non étiquetées
(2) Dans le processus de génération de pseudo-étiquettes, étant donné que toutes les prédictions du modèle de départ sur les données non étiquetées sont peu susceptibles d'être exactes, il est nécessaire de Utilisez certaines stratégies pour surentraîner les données de faible valeur.
(3) Ensuite, les pseudo-étiquettes générées doivent être combinées avec les données étiquetées d'origine, et une formation conjointe est effectuée sur les données fusionnées
Contenu réécrit : (4 ) Depuis une grande quantité des données non supervisées sont ajoutées au cours du processus de formation, même si la qualité du pseudo-étiquette des données non supervisées n'est pas aussi bonne que celle des données supervisées, une représentation plus générale peut souvent être obtenue. Nous utilisons un modèle pré-entraîné basé sur une formation Big Data pour affiner les données dialectales affinées manuellement. Cela peut conserver les excellentes performances de généralisation apportées par le modèle pré-entraîné, tout en améliorant l'effet de reconnaissance du modèle sur les dialectes
Le CER (taux d'erreur de caractère) moyen des 5 dialectes du contenu à réécrire est : 35,3% Optimisé à 17,21%. Réécrit comme suit : Le CER (taux d'erreur de caractère) moyen des cinq dialectes doit être réécrit de : 35,3 % à 17,21 % sens original inchangé, le contenu doit être réécrit en cantonais.
Le contenu réécrit est : Pékin |
Mandarin des plaines centrales |
Le contenu qui doit être réécrit est : Mandarin du sud-ouest | ||||
Dialecte unique |
Ce qui doit être réécrit est : 35.3 |
|||||
Pré-formation de 100wh + mise au point du mélange dialectal |
17.21 | 13.14 |
Ce qui doit être réécrit est : 22.84 |
Ce qui doit être réécrit est : 19h60 |
19. 50 |
10.95 |
Étape de traduction dialectale
Dans des circonstances normales, la formation de modèles de traduction automatique nécessite le support d'une grande quantité de corpus. Cependant, les dialectes sont généralement transmis sous forme parlée et le nombre de locuteurs de dialectes diminue aujourd'hui d'année en année. Ces phénomènes ont accru la difficulté de collecter des données dialectales, ce qui rend difficile l'amélioration de l'effet de la traduction automatique dialectale
Afin de résoudre le problème de l'insuffisance des données dialectales, l'équipe de traduction de Huoshan a proposé le modèle de traduction multilingue mRASP (pré-formation multilingue à substitution alignée aléatoire) et mRASP2, introduisent un apprentissage contrastif via , complété par une méthode d'amélioration de l'alignement , comprenant un corpus monolingue et un corpus bilingue dans un cadre de formation unifié, utilisant pleinement le corpus pour apprendre une meilleure langue- indépendant Indique que les performances de traduction multilingue sont améliorées.

Adresse papier : https://arxiv.org/abs/2105.09501
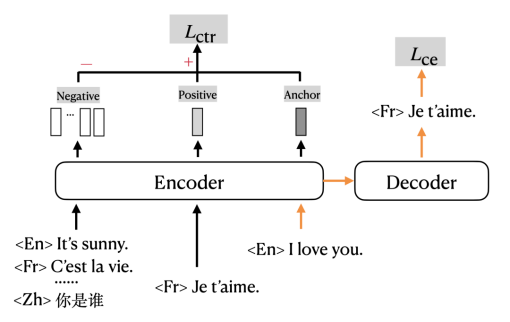
La conception de l'ajout de tâches d'apprentissage contrastives est basée sur une hypothèse classique : l'encodage de phrases synonymes dans différents langues Cette dernière représentation doit être à des positions adjacentes dans l'espace de grande dimension. Parce que les phrases synonymes dans différentes langues ont la même signification, c'est-à-dire que le résultat du processus « d'encodage » est le même. Par exemple, les deux phrases « Bonjour » et « Bonjour » ont la même signification pour les personnes qui comprennent le chinois et l'anglais. Cela correspond également à la « représentation codée de positions adjacentes dans un espace de grande dimension ».
Repenser l'objectif d'entraînement
mRASP2 ajoute une perte contrastive à la perte d'entropie croisée traditionnelle pour s'entraîner dans un format multitâche. La flèche orange sur la figure indique la partie qui utilise traditionnellement la perte d'entropie croisée (perte CE) pour entraîner la traduction automatique ; la partie noire indique la partie correspondant à la perte contrastive (perte CTR). La méthode d'amélioration des données d'alignement des mots, également connue sous le nom d'augmentation alignée (AA), est développée à partir de la méthode de substitution alignée aléatoire (RAS) de mRASP.
Le contenu réécrit est le suivant : selon le diagramme, la figure (a) montre le processus d'amélioration du corpus parallèle et la figure (b) montre le processus d'amélioration du corpus monolingue. Dans la figure (a), les mots anglais originaux sont remplacés par les mots chinois correspondants ; tandis que dans la figure (b), les mots chinois originaux sont remplacés par l'anglais, le français, l'arabe et l'allemand. Le RAS de mRASP est équivalent à la première méthode de remplacement, qui nécessite uniquement la fourniture d'un dictionnaire de synonymes bilingue tandis que la seconde méthode de remplacement nécessite la fourniture d'un dictionnaire de synonymes contenant plusieurs langues ; Il convient de mentionner que lorsque vous utilisez la méthode d'amélioration de l'alignement, vous pouvez choisir d'utiliser uniquement la méthode de la figure (a) ou uniquement la méthode de la figure (b)
Les résultats expérimentaux montrent que mRASP2 présente les avantages du supervisé. , non supervisé et zéro L'effet de traduction a été amélioré dans tous les scénarios de ressources. Parmi eux, l'amélioration moyenne des scénarios supervisés est de 1,98 BLEU, l'amélioration moyenne des scénarios non supervisés est de 14,13 BLEU et l'amélioration moyenne des scénarios sans ressources est de 10,26 BLEU. 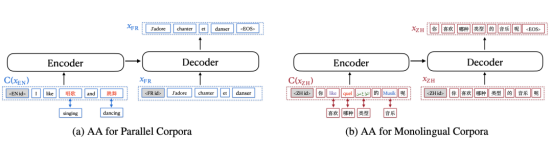
Écrit à la fin
Le dialecte et le mandarin se complètent et sont des expressions importantes de la culture traditionnelle chinoise. Le dialecte, en tant que moyen d'expression, représente les émotions et les liens du peuple chinois avec sa ville natale. Grâce à de courtes vidéos et à la traduction en dialecte, il peut aider les utilisateurs à apprécier la culture de différentes régions du pays sans aucune barrière.Actuellement, la fonction « Traduction en dialecte » de Douyin est désormais prise en charge afin de conserver le sens original. inchangé, le contenu doit être réécrit pour le cantonais. , Min, Wu (le contenu réécrit est : Pékin), le contenu qui doit être réécrit est : le mandarin du sud-ouest (Sichuan), le mandarin des plaines centrales (Shaanxi, Henan), etc. On dit que davantage de dialectes seront pris en charge dans le l'avenir, attendons de voir.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Lancement du grand modèle Bytedance Beanbao, le service d'IA complet Volcano Engine aide les entreprises à se transformer intelligemment
Jun 05, 2024 pm 07:59 PM
Lancement du grand modèle Bytedance Beanbao, le service d'IA complet Volcano Engine aide les entreprises à se transformer intelligemment
Jun 05, 2024 pm 07:59 PM
Tan Dai, président de Volcano Engine, a déclaré que les entreprises qui souhaitent bien mettre en œuvre de grands modèles sont confrontées à trois défis clés : l'effet de modèle, le coût d'inférence et la difficulté de mise en œuvre : elles doivent disposer d'un bon support de base de grands modèles pour résoudre des problèmes complexes, et elles doivent également avoir une inférence à faible coût. Les services permettent d'utiliser largement de grands modèles, et davantage d'outils, de plates-formes et d'applications sont nécessaires pour aider les entreprises à mettre en œuvre des scénarios. ——Tan Dai, président de Huoshan Engine 01. Le grand modèle de pouf fait ses débuts et est largement utilisé. Le polissage de l'effet de modèle est le défi le plus critique pour la mise en œuvre de l'IA. Tan Dai a souligné que ce n'est que grâce à une utilisation intensive qu'un bon modèle peut être poli. Actuellement, le modèle Doubao traite 120 milliards de jetons de texte et génère 30 millions d'images chaque jour. Afin d'aider les entreprises à mettre en œuvre des scénarios de modèles à grande échelle, le modèle à grande échelle beanbao développé indépendamment par ByteDance sera lancé à travers le volcan.
 L'effet marketing a été grandement amélioré, c'est ainsi que la création vidéo AIGC doit être utilisée
Jun 25, 2024 am 12:01 AM
L'effet marketing a été grandement amélioré, c'est ainsi que la création vidéo AIGC doit être utilisée
Jun 25, 2024 am 12:01 AM
Après plus d'un an de développement, AIGC est progressivement passé de la génération de dialogues textuels et d'images à la génération de vidéos. Il y a quatre mois, la naissance de Sora a provoqué un remaniement dans le domaine de la génération vidéo et a vigoureusement promu la portée et la profondeur des applications d'AIGC dans le domaine de la création vidéo. A l’heure où tout le monde parle de grands modèles, d’un côté on est surpris par le choc visuel apporté par la génération vidéo, de l’autre on est confronté à la difficulté de mise en œuvre. Il est vrai que les grands modèles sont encore dans une période de rodage, depuis la recherche et le développement technologique jusqu'à la pratique des applications, et qu'ils doivent encore être ajustés en fonction de scénarios commerciaux réels, mais la distance entre l'idéal et la réalité se réduit progressivement. Le marketing, en tant que scénario de mise en œuvre important de la technologie de l’intelligence artificielle, est devenu une direction dans laquelle de nombreuses entreprises et praticiens souhaitent faire des percées. Une fois que vous maîtriserez les méthodes appropriées, le processus créatif des vidéos marketing sera
 La force technique de Huoshan Voice TTS a été certifiée par le Centre national d'inspection et de quarantaine, avec un score MOS aussi élevé que 4,64.
Apr 12, 2023 am 10:40 AM
La force technique de Huoshan Voice TTS a été certifiée par le Centre national d'inspection et de quarantaine, avec un score MOS aussi élevé que 4,64.
Apr 12, 2023 am 10:40 AM
Récemment, le produit de synthèse vocale Volcano Engine a obtenu le certificat d'inspection et de test amélioré de synthèse vocale délivré par le Centre national d'inspection et de test de la qualité des produits de reconnaissance vocale et d'image (ci-après dénommé le « Centre national d'inspection de l'IA »). exigences de base et exigences étendues de la synthèse vocale. Le niveau le plus élevé du Centre national d'inspection de l'IA. Cette évaluation est menée à partir des dimensions du chinois mandarin, des multi-dialectes, des multi-langues, des langues mixtes, des multitimbraux et de la personnalisation. L'équipe de support technique du produit, l'équipe Volcano Voice, fournit une riche bibliothèque sonore. Le score MOS du timbre est le plus élevé. Il atteint 4,64 points, ce qui constitue le niveau le plus élevé de l'industrie. En tant que première et unique agence nationale d'inspection et de test de la qualité des produits vocaux et images dans le domaine de l'intelligence artificielle dans le système d'inspection de la qualité de mon pays, le Centre national d'inspection de l'IA s'est engagé à promouvoir l'intelligence artificielle.
 En vous concentrant sur une expérience personnalisée, la fidélisation des utilisateurs dépend entièrement de l'AIGC ?
Jul 15, 2024 pm 06:48 PM
En vous concentrant sur une expérience personnalisée, la fidélisation des utilisateurs dépend entièrement de l'AIGC ?
Jul 15, 2024 pm 06:48 PM
1. Avant d’acheter un produit, les consommateurs rechercheront et parcourront les avis sur les produits sur les réseaux sociaux. Il devient donc de plus en plus important pour les entreprises de commercialiser leurs produits sur les plateformes sociales. Le but du marketing est de : Promouvoir la vente de produits Établir une image de marque Améliorer la notoriété de la marque Attirer et fidéliser les clients Améliorer à terme la rentabilité de l'entreprise Le grand modèle possède d'excellentes capacités de compréhension et de génération et peut fournir aux utilisateurs des informations personnalisées en parcourant et en analysant recommandations sur le contenu des données utilisateur. Dans le quatrième numéro de « AIGC Experience School », deux invités discuteront en profondeur du rôle de la technologie AIGC dans l'amélioration du « taux de conversion marketing ». Heure de diffusion en direct : 10 juillet, de 19h00 à 19h45 Sujet de diffusion en direct : Pour fidéliser les utilisateurs, comment l'AIGC améliore-t-elle le taux de conversion grâce à la personnalisation ? Le quatrième épisode du programme a invité deux importants
 Une exploration approfondie de la mise en œuvre de la technologie de pré-formation non supervisée et de « l'optimisation des algorithmes + l'innovation technique » de Huoshan Voice
Apr 08, 2023 pm 12:44 PM
Une exploration approfondie de la mise en œuvre de la technologie de pré-formation non supervisée et de « l'optimisation des algorithmes + l'innovation technique » de Huoshan Voice
Apr 08, 2023 pm 12:44 PM
Depuis longtemps, Volcano Engine propose des solutions de sous-titres vidéo intelligentes basées sur la technologie de reconnaissance vocale pour les plateformes vidéo populaires. Pour faire simple, il s'agit d'une fonction qui utilise la technologie IA pour convertir automatiquement les voix et les paroles de la vidéo en texte pour aider à la création vidéo. Cependant, avec la croissance rapide du nombre d’utilisateurs de la plateforme et la nécessité de langues plus riches et plus diversifiées, la technologie d’apprentissage supervisé traditionnellement utilisée atteint de plus en plus son goulot d’étranglement, ce qui met l’équipe en difficulté. Comme nous le savons tous, l'apprentissage supervisé traditionnel s'appuiera fortement sur des données supervisées annotées manuellement, en particulier dans l'optimisation continue des grands langages et le démarrage à froid des petits langages. En prenant comme exemple les principales langues telles que le chinois, le mandarin et l'anglais, bien que la plate-forme vidéo fournisse suffisamment de données vocales pour les scénarios commerciaux, une fois que les données supervisées auront atteint une certaine échelle, elles continueront à
 Tous les Douyin parlent des dialectes natifs, deux technologies clés vous aident à « comprendre » les dialectes locaux
Oct 12, 2023 pm 08:13 PM
Tous les Douyin parlent des dialectes natifs, deux technologies clés vous aident à « comprendre » les dialectes locaux
Oct 12, 2023 pm 08:13 PM
Lors de la Fête nationale, la campagne de Douyin « Un mot de dialecte prouve que vous êtes de votre ville natale » a attiré la participation enthousiaste des internautes de tout le pays. Le sujet est arrivé en tête de la liste des défis de Douyin, avec plus de 50 millions de vues. Ces « Local Dialect Awards » sont rapidement devenus populaires sur Internet, ce qui est indissociable de la contribution de la nouvelle fonction de traduction automatique en dialecte local de Douyin. Lorsque les créateurs ont enregistré de courtes vidéos dans leur dialecte natif, ils ont utilisé la fonction « Sous-titres automatiques » et sélectionné « Convertir en sous-titres en mandarin », afin que le discours en dialecte de la vidéo puisse être automatiquement reconnu et le contenu du dialecte converti en sous-titres en mandarin. permet aux internautes d'autres régions de comprendre facilement diverses langues « mandarin cryptées ». Les internautes du Fujian l'ont personnellement testé et ont déclaré que même la région du sud du Fujian avec une « prononciation différente » est une région de la province du Fujian, en Chine.
 Le concours d'innovation écologique « Santé + IA » organisé conjointement par Volcano Engine et Yili s'est terminé avec succès
Jan 13, 2024 am 11:57 AM
Le concours d'innovation écologique « Santé + IA » organisé conjointement par Volcano Engine et Yili s'est terminé avec succès
Jan 13, 2024 am 11:57 AM
Santé + IA = ? Solutions de nutrition santé cérébrale pour les personnes d'âge moyen et âgées, services numériques intelligents de nutrition et de santé, solutions AIGC big health community... Avec le déroulement du concours d'innovation écologique « Santé + IA », chacun d'entre eux contient l'énergie technologique et responsabilise l'industrie de la santé. Des solutions innovantes sont sur le point de voir le jour, et la réponse à la question « santé + IA = ? » émerge lentement. Le 26 décembre, le concours d'innovation écologique « Santé + IA », parrainé conjointement par le groupe Yili et Volcano Engine, s'est terminé avec succès. Six entreprises gagnantes, dont Shanghai Bosten Network Technology Co., Ltd. et Zhongke Suzhou Intelligent Computing Technology Research Institute, ressortir. Au cours du concours qui a duré plus d'un mois, Yili s'est associé à des entreprises scientifiques et technologiques exceptionnelles pour explorer l'intégration profonde de la technologie de l'IA et de l'industrie de la santé, augmentant ainsi continuellement les attentes à l'égard du concours. Concours d'innovation écologique "Santé + IA"
 Restauration ultra-claire par Volcano Engine du concert classique de Beyond, les capacités techniques ont été mises à la disposition du public
Apr 09, 2023 pm 11:51 PM
Restauration ultra-claire par Volcano Engine du concert classique de Beyond, les capacités techniques ont été mises à la disposition du public
Apr 09, 2023 pm 11:51 PM
Dans la soirée du 3 juillet, Douyin s'est associé à Polygram, un label d'Universal Music, pour diffuser en direct une sélection de contenus du concert de contact avec la vie Beyond Live 1991 et du concert commémoratif qui avait été restauré avec un moteur volcanique ultra-clair, attirant plus de 140 personnes. millions de vues. Beyond est un groupe de rock fondé en 1983. Avec l'essor de la musique cantonaise, le nom du groupe Beyond est devenu une empreinte culturelle d'une époque. "Beyond Live 1991" fut le premier concert organisé par Beyond au stade Hung Hom. Les DVD publiés par PolyGram étaient presque difficiles à trouver dans les années 1990. Depuis 31 ans, ce concert est devenu l'illumination musicale et le souvenir de jeunesse de générations de fans. Limité par l'équipement de prise de vue, les supports de stockage et
