
 Périphériques technologiques
IA
Le cerveau humain connaît le chiffre « 4 », mais pas le chiffre « 5 » ! Les preuves scientifiques soutiennent que les quatre rois célestes F4 sont tous « 4 » (doge)|Nature
Périphériques technologiques
IA
Le cerveau humain connaît le chiffre « 4 », mais pas le chiffre « 5 » ! Les preuves scientifiques soutiennent que les quatre rois célestes F4 sont tous « 4 » (doge)|Nature
Le cerveau humain connaît le chiffre « 4 », mais pas le chiffre « 5 » ! Les preuves scientifiques soutiennent que les quatre rois célestes F4 sont tous « 4 » (doge)|Nature

Veuillez répondre dans une demi-seconde. Combien y a-t-il de pommes dans l'image ci-dessous :

Pouvez-vous dire d'un coup d'œil qu'il y en a quatre à gauche, et qu'à droite... il y en a beaucoup ? Pourquoi ne pouvons-nous pas déterminer instantanément lequel est à droite ?
En plus de ce phénomène, il existe des exemples similaires, tels que "Four" Heavenly King, F "4", "Four" Xiao Hua Dan, etc. Pourquoi tout cela a-t-il à voir avec le chiffre « 4 » ?
Le dernier rapport de la nature fournit des preuves directes pour expliquer ce phénomène - Le cerveau reconnaît le "4" mais pas le "5".
Des chercheurs du centre médical universitaire de Bonn, en Allemagne, ont observé l'activité de neurones uniques et ont découvert que le cerveau utilise différents systèmes pour reconnaître les nombres « 1-4 » et « 5-9 », et que la limite est "4".
Plus précisément, lorsque les neurones traitent les nombres 1 à 4, des neurones spécifiques sont utilisés ; tandis que lors du traitement de 5 à 9, la réponse n'est pas spécifique et sera interférée par les nombres adjacents.
Par exemple : un neurone qui préfère le chiffre 3 ne répondra qu'au 3, tandis qu'un neurone qui préfère le chiffre 8 répondra au 8, mais aussi aux chiffres 7 et 9
Cette découverte est d'une grande importance pour la compréhension la nature de la pensée humaine. Lisa Feigenson, psychologue à l'Université Johns Hopkins, a déclaré :
Fondamentalement, cette question concerne la structure de l'esprit : qu'est-ce qui constitue la base de l'esprit humain ?
Le cerveau humain reconnaît-il le « 4 » ou non le « 5 » ?
Dans un article publié dans le magazine « Nature » en 1871, l'économiste et logicien William Stanley Jevons a étudié la capacité des humains à compter et est arrivé à la conclusion suivante :
Certaines personnes ne peuvent pas juger de la taille du chiffre "5"
Certains chercheurs ont analysé plus tard que c'est parce que le cerveau n'utilise un système de comptage que pour les nombres plus grands, la précision du système est moindre
Certaines personnes émettent également l'hypothèse que la différence vient du fait d'avoir deux systèmes nerveux indépendants pour compter, puis d'utiliser l'EEG, l'imagerie par résonance magnétique fonctionnelle et d'autres technologies pour approfondir les études, mais les résultats sont incohérents, je ne peux pas décider quel mode est correct.
Jusqu'à récemment, une équipe de recherche de l'Université de Bonn en Allemagne utilisait une nouvelle technologie pour enregistrer l'activité de neurones uniques dans le cerveau humain et a finalement découvert la différence de codage neuronal entre les petits nombres et les grands nombres.

801 neurones uniques. Ces neurones proviennent de quatre zones du cerveau : l'amygdale, l'hippocampe, le lobe temporal ventromédian et le lobe temporal ventrolatéral. Pendant le processus d'enregistrement, les patients doivent effectuer une tâche de jugement quantitatif :
Des images « matricielles » non symbolisées dans la plage de 0 à 9 seront affichées à l'écran et chaque image durera une demi-seconde. Les participants doivent appuyer sur les touches gauche et droite pour indiquer si le nombre sur l'image est pair ou impair.
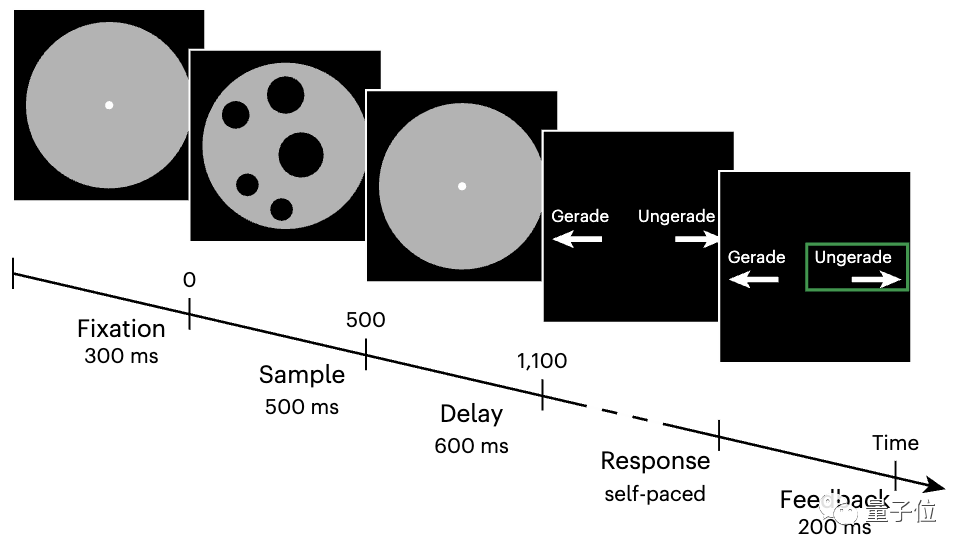 La matrice de points est présentée au format standard et au format de contrôle. Voici trois dispositions de matrice de points :
La matrice de points est présentée au format standard et au format de contrôle. Voici trois dispositions de matrice de points :
.
 △ (à gauche) Disposition standard, la taille et la position des points sont variables ; (au milieu) la disposition des contrôles, égalisant la surface totale et la densité des points (à droite) les points présentent une disposition linéaire
△ (à gauche) Disposition standard, la taille et la position des points sont variables ; (au milieu) la disposition des contrôles, égalisant la surface totale et la densité des points (à droite) les points présentent une disposition linéaire
 △ (à gauche) Disposition standard, la taille et la position des points sont variables ; (au milieu) la disposition des contrôles, égalisant la surface totale et la densité des points (à droite) les points présentent une disposition linéaire
△ (à gauche) Disposition standard, la taille et la position des points sont variables ; (au milieu) la disposition des contrôles, égalisant la surface totale et la densité des points (à droite) les points présentent une disposition linéaireDans les tests comportementaux, les patients étaient significativement plus précis pour juger de petites quantités et répondre. Le temps est plus court, montrant les caractéristiques de la
"subisation".
(La subisation, terme dans le domaine de la psychologie et des sciences cognitives, fait référence à la capacité humaine à estimer rapidement de petites quantités d'objets.)Lorsque le nombre est supérieur à 4, le jugement ralentit et le taux d'erreur augmente , reflétant le processus
"estimation de quantité". Les chercheurs ont calculé respectivement le taux d'erreur et le temps de réaction, et ont finalement déterminé que la limite supérieure de la plage de subisation était en moyenne de 3,7 (taux d'erreur) et 3,6 (temps de réaction).
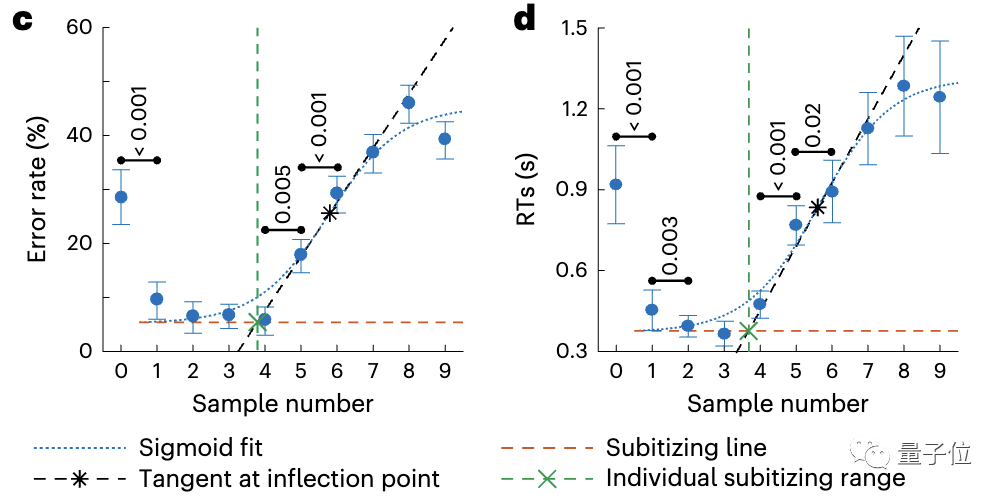
L'analyse des réponses neuronales a en outre confirmé l'exactitude des résultats comportementaux
Système de quantification décimale et système d'estimation de grands nombres
Au niveau d'un seul neurone, les chercheurs ont également observé des modèles de codage similaires
Ils ont répondu sélectivement aux neurones non Des nombres symbolisés ont été trouvés dans les quatre zones cérébrales enregistrées, et ces neurones sélectifs couvraient la gamme complète de nombres de 0 à 9.
La proportion de neurones sélectifs dans différentes zones du cerveau est d'environ 15,1%, ce qui est nettement plus élevé que les niveaux aléatoires.
Après avoir analysé les caractéristiques et les corrélations de la courbe de réglage des neurones, les chercheurs ont découvert :
Pour les petites quantités 1 à 4, les neurones sont hautement sélectifs pour la quantité préférée et suppriment la réponse à la quantité non préférée, améliorant ainsi l'effet de reconnaissance.
Pour un neurone sensible aux changements de quantité, il produira la réponse maximale à un nombre spécifique. Le nombre qui provoque la réponse maximale est le « nombre préféré » du neurone
Lorsque le nombre est supérieur à. 4 Lorsque , la courbe de réglage du neurone deviendra plus large, la sélectivité diminuera également et reviendra au niveau de base à mesure que le nombre augmente, ce qui est cohérent avec les caractéristiques de l'estimation du nombre
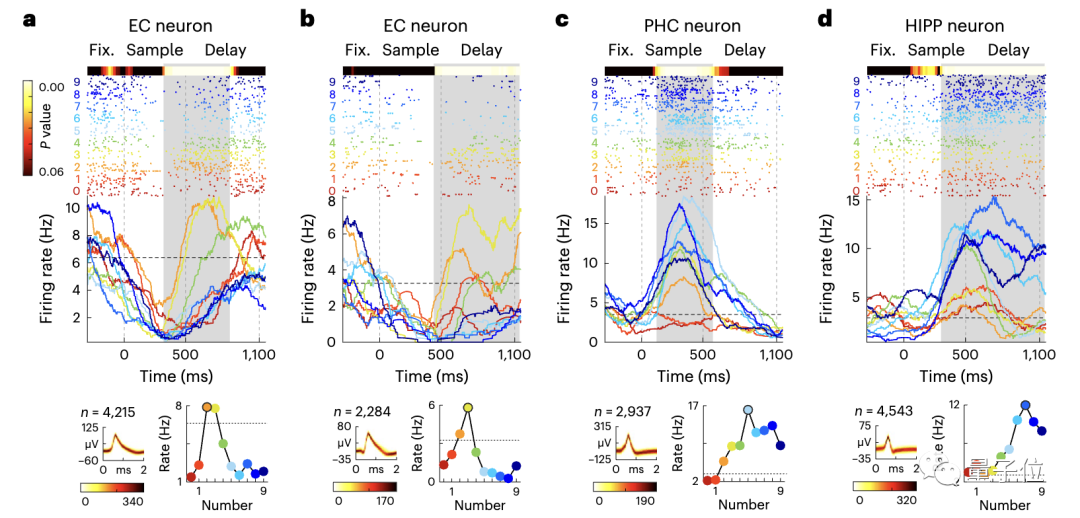
Ensuite, les chercheurs ont utilisé Les SVM pour sélectionner les neurones sexuels ont été décodés, une analyse de l'espace d'état et une analyse de regroupement ont été effectuées, et des tests statistiques ont été effectués sur des groupes de neurones Il a également été constaté qu'il existe une limite de classification pour le jugement quantitatif, et que la différence la plus significative se situe entre la quantité. 4 et 5.
Cette frontière est très cohérente avec le jugement intuitif humain
Cette étude fournit la preuve directe que le système «subitisant» pour les petits nombres et le système «d'estimation» pour les grands nombres peuvent coexister
Le système «subitisant» peut être lié à l'attention et mémoire de travail De manière pertinente, cela explique notre jugement pointu sur de petites quantités d'informations, alors que le cerveau s'appuie sur un traitement plus lent et systématique de l'information pour les entrées qui dépassent sa capacité.
Cependant, les chercheurs ont également mentionné que les mécanismes de réseau plus complexes doivent être explorés plus en détail, par exemple s'il existe des différences de codage similaires dans d'autres zones du cerveau, si ce phénomène peut également être observé dans des tâches cognitives plus complexes et si la boucle d'inhibition effet de temps, etc.
Lien papier : https://www.nature.com/articles/d41586-023-03136-w
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Navicat se connecte au code et à la solution d'erreur de base de données
Apr 08, 2025 pm 11:06 PM
Navicat se connecte au code et à la solution d'erreur de base de données
Apr 08, 2025 pm 11:06 PM
Erreurs et solutions courantes Lors de la connexion aux bases de données: nom d'utilisateur ou mot de passe (erreur 1045) Blocs de pare-feu Connexion (erreur 2003) Délai de connexion (erreur 10060) Impossible d'utiliser la connexion à socket (erreur 1042) Erreur de connexion SSL (erreur 10055) Trop de connexions Résultat de l'hôte étant bloqué (erreur 1129)
 Comment rédiger le dernier tutoriel sur la déclaration d'insertion SQL
Apr 09, 2025 pm 01:48 PM
Comment rédiger le dernier tutoriel sur la déclaration d'insertion SQL
Apr 09, 2025 pm 01:48 PM
L'instruction INSERT SQL est utilisée pour ajouter de nouvelles lignes à une table de base de données, et sa syntaxe est: Insérer dans Table_Name (Column1, Column2, ..., Columnn) VALEUR (VALEUR1, Value2, ..., Valuen);. Cette instruction prend en charge l'insertion de plusieurs valeurs et permet d'insérer des valeurs nulles dans des colonnes, mais il est nécessaire de s'assurer que les valeurs insérées sont compatibles avec le type de données de la colonne pour éviter de violer les contraintes d'unicité.
 Comment ajouter une nouvelle colonne dans SQL
Apr 09, 2025 pm 02:09 PM
Comment ajouter une nouvelle colonne dans SQL
Apr 09, 2025 pm 02:09 PM
Ajoutez de nouvelles colonnes à une table existante dans SQL en utilisant l'instruction ALTER TABLE. Les étapes spécifiques comprennent: la détermination des informations du nom de la table et de la colonne, rédaction des instructions de la table ALTER et exécution des instructions. Par exemple, ajoutez une colonne de messagerie à la table des clients (VARCHAR (50)): Alter Table Clients Ajouter un e-mail VARCHAR (50);
 Quelle est la syntaxe pour ajouter des colonnes dans SQL
Apr 09, 2025 pm 02:51 PM
Quelle est la syntaxe pour ajouter des colonnes dans SQL
Apr 09, 2025 pm 02:51 PM
La syntaxe pour ajouter des colonnes dans SQL est alter table table_name Ajouter Column_name data_type [pas null] [default default_value]; Lorsque Table_Name est le nom de la table, Column_name est le nouveau nom de colonne, DATA_TYPE est le type de données, et non Null Spécifie si les valeurs NULL sont autorisées, et default default_value spécifie la valeur par défaut.
 La syntaxe de l'ajout de colonnes dans différents systèmes de base de données est-elle la même?
Apr 09, 2025 pm 12:51 PM
La syntaxe de l'ajout de colonnes dans différents systèmes de base de données est-elle la même?
Apr 09, 2025 pm 12:51 PM
La syntaxe pour ajouter des colonnes dans différents systèmes de base de données varie considérablement et varie d'une base de données à la base de données. Par exemple: MySQL: alter les utilisateurs de la table Ajouter un e-mail de colonne Varchar (255); PostgreSQL: Alter Table Users Ajouter la colonne Email Varchar (255) Non Null Unique; Oracle: Alter Table Users Ajouter un e-mail Varchar2 (255); SQL Server: Alter Table Users Ajouter un e-mail Varch
 Comment définir des valeurs par défaut lors de l'ajout de colonnes dans SQL
Apr 09, 2025 pm 02:45 PM
Comment définir des valeurs par défaut lors de l'ajout de colonnes dans SQL
Apr 09, 2025 pm 02:45 PM
Définissez la valeur par défaut des colonnes nouvellement ajoutées, utilisez l'instruction ALTER TABLE: Spécifiez des colonnes Ajouter et définissez la valeur par défaut: alter table table_name Ajouter Column_name data_type default_value; Utilisez la clause CONSTRAINT pour spécifier la valeur par défaut: ALTER TABLE TABLE_NAME ADD COLUMN COLUMN_NAME DATA_TYPE CONSTRAINT DEFAULT_CONSTRAINT DEFAULT_VALUE;
 Tableau Clear SQL: Conseils d'optimisation des performances
Apr 09, 2025 pm 02:54 PM
Tableau Clear SQL: Conseils d'optimisation des performances
Apr 09, 2025 pm 02:54 PM
Conseils pour améliorer les performances de compensation de la table SQL: utilisez une table tronquée au lieu de supprimer, libre d'espace et réinitialiser la colonne d'identité. Désactivez les contraintes de clés étrangères pour éviter la suppression en cascade. Utilisez les opérations d'encapsulation des transactions pour assurer la cohérence des données. Supprimer les mégadonnées et limiter le nombre de lignes via Limit. Reconstruisez l'indice après la compensation pour améliorer l'efficacité de la requête.
 SQL Classic 50 Question Answers
Apr 09, 2025 pm 01:33 PM
SQL Classic 50 Question Answers
Apr 09, 2025 pm 01:33 PM
SQL (Language de requête structuré) est un langage de programmation utilisé pour créer, gérer et interroger les bases de données. Les fonctions principales incluent: la création de bases de données et de tables, d'insertion, de mise à jour et de suppression de données, de tri et de filtrage des résultats, d'agrégation des fonctions, de jonction de tables, de sous-requêtes, d'opérateurs, de fonctions, de mots clés, de manipulation de données / de définition / langage de contrôle, de types de connexion, d'optimisation de requête, de sécurité, d'outils, de ressources, de versions, d'erreurs communes, de techniques de débogage, de meilleurs pratiques, de tristes et de pliées.
