
 Périphériques technologiques
IA
GPT-4 a amélioré sa précision de 13,7 % grâce à la formation DeepMind, obtenant ainsi de meilleures capacités d'induction et de déduction.
Périphériques technologiques
IA
GPT-4 a amélioré sa précision de 13,7 % grâce à la formation DeepMind, obtenant ainsi de meilleures capacités d'induction et de déduction.
GPT-4 a amélioré sa précision de 13,7 % grâce à la formation DeepMind, obtenant ainsi de meilleures capacités d'induction et de déduction.

Actuellement, les grands modèles linguistiques (LLM) démontrent des capacités étonnantes sur les tâches d'inférence, en particulier lorsque des exemples et des étapes intermédiaires sont fournis. Cependant, les méthodes rapides reposent généralement sur des connaissances implicites dans le LLM, et lorsque les connaissances implicites sont fausses ou incompatibles avec la tâche, le LLM peut donner de mauvaises réponses

Maintenant, de Google, de l'Institut Mila, etc. Chercheurs de la recherche Les institutions ont exploré conjointement une nouvelle méthode - permettant au LLM d'apprendre les règles d'inférence et ont proposé un nouveau cadre appelé Hypothèses en Théories (HtT). Cette nouvelle méthode améliore non seulement le raisonnement en plusieurs étapes, mais présente également les avantages de l'interprétabilité et de la transférabilité

Adresse papier : https://arxiv.org/abs/2310.07064
selon Experimental les résultats sur les problèmes de raisonnement numérique et de raisonnement relationnel montrent que la méthode HtT améliore la méthode d'incitation existante et augmente la précision de 11 à 27 %. Dans le même temps, les règles apprises peuvent également être transférées à différents modèles ou différentes formes du même problème
Introduction à la méthode
En général, le cadre HtT contient deux étapes - l'étape inductive et l'étape déductive Étape similaire à la formation et aux tests dans l’apprentissage automatique traditionnel.
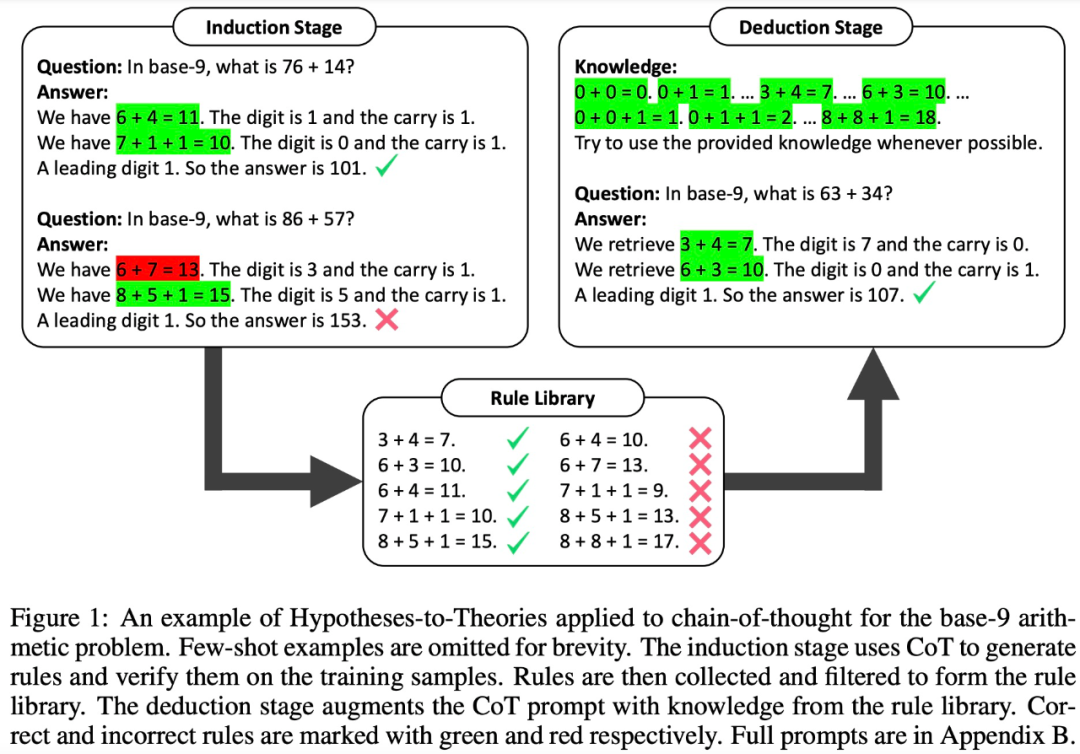
Dans la phase d'intégration, LLM doit d'abord générer et vérifier un ensemble de règles pour des exemples de formation. Cette étude utilise CoT pour déclarer des règles et en dériver des réponses, évaluer la fréquence et l'exactitude des règles, collecter les règles qui apparaissent fréquemment et conduire à des réponses correctes, et former une base de règles
Avec une bonne base de règles, la prochaine étape consiste à déterminer comment pour appliquer cette recherche Ces règles résolvent le problème. À cette fin, dans la phase de déduction, cette étude ajoute une base de règles dans l'invite et demande à LLM de récupérer les règles de la base de règles pour effectuer la déduction, convertissant le raisonnement implicite en raisonnement explicite.
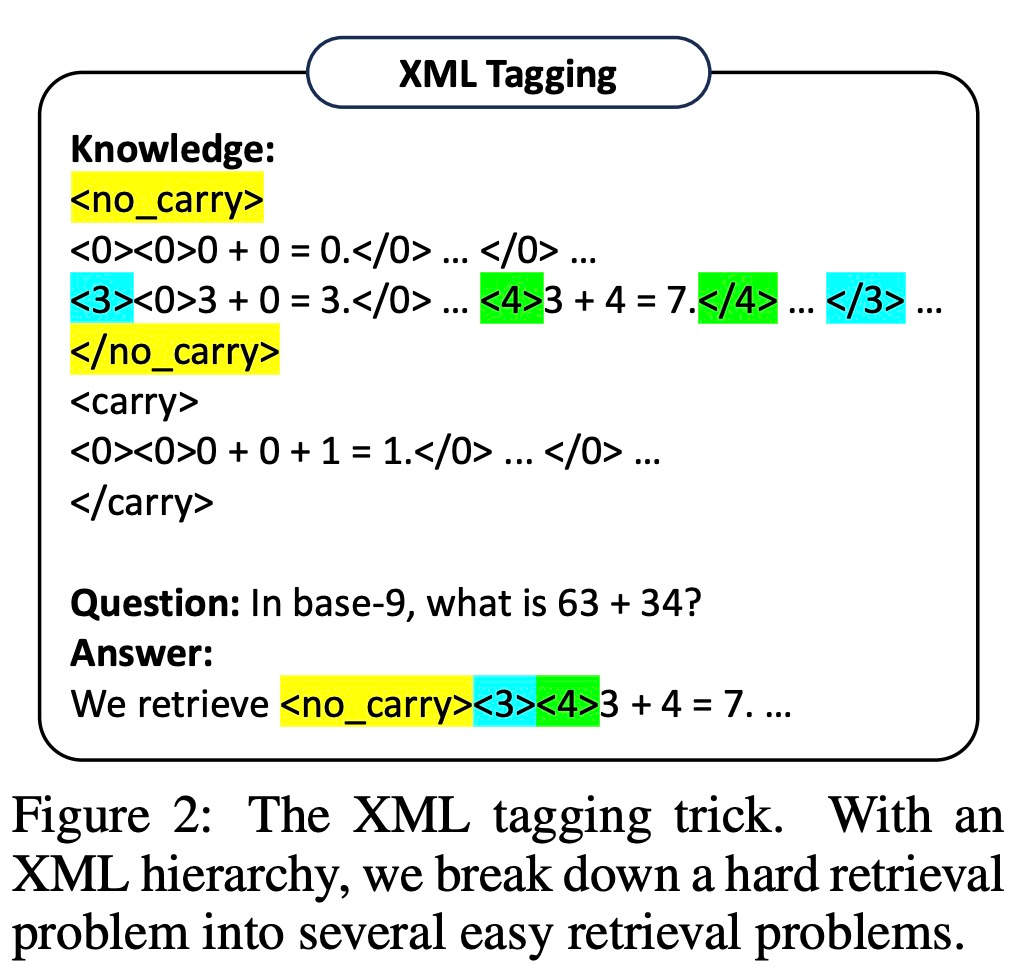
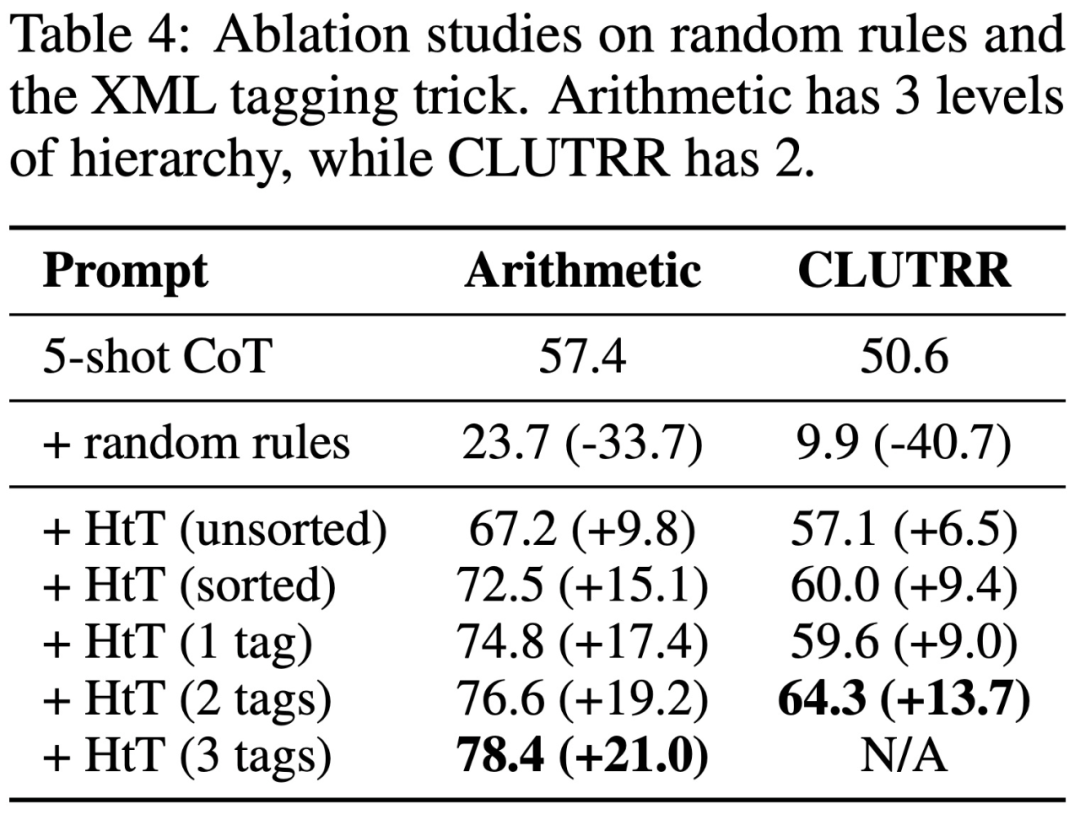
Cependant, des études ont montré que même les LLM très puissants (tels que GPT-4) ont du mal à récupérer les bonnes règles à chaque étape. Par conséquent, cette étude développe des techniques de balisage XML pour améliorer les capacités de récupération de contexte de LLM
Résultats expérimentaux
Pour évaluer HtT, cette étude a effectué des benchmarks sur deux problèmes de raisonnement en plusieurs étapes. Les résultats expérimentaux montrent que HtT améliore la méthode d'invite à quelques échantillons. Les auteurs ont également réalisé des études approfondies sur l’ablation pour fournir une compréhension plus complète du HtT.
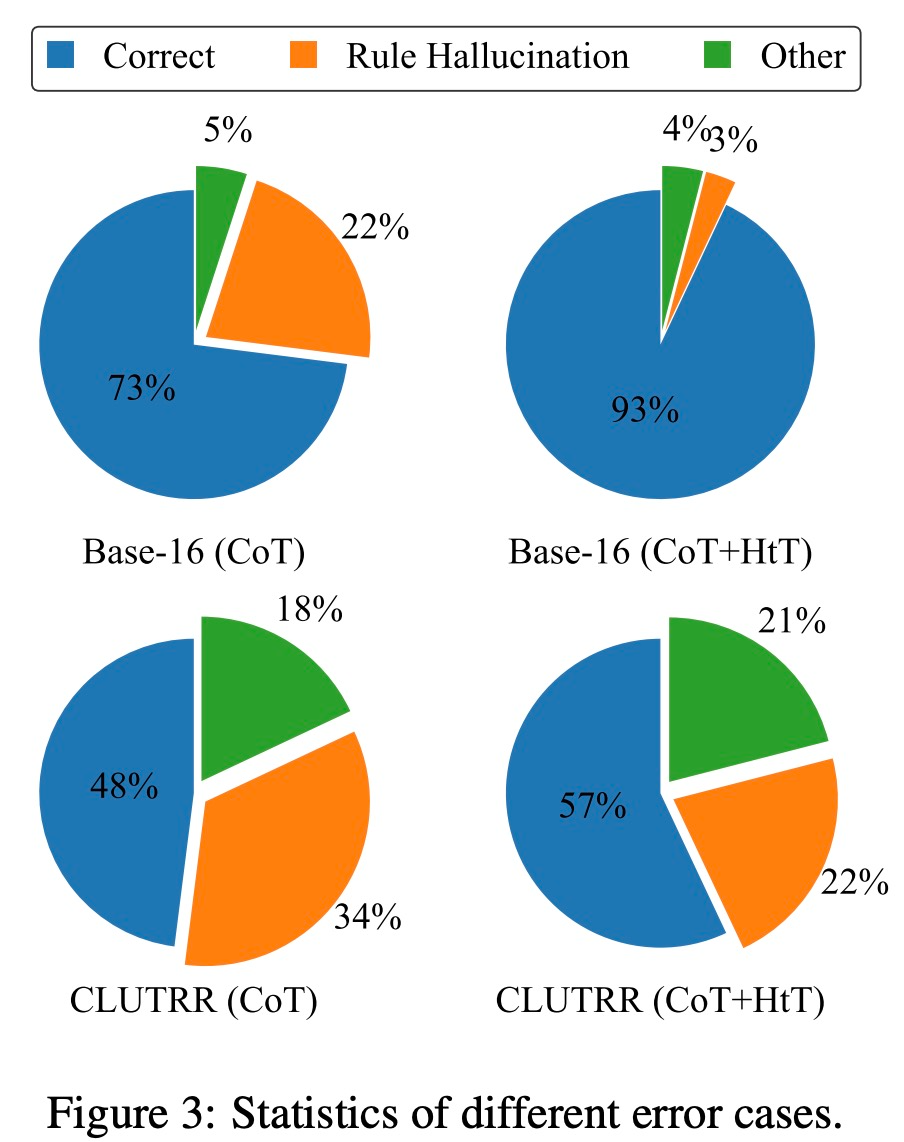
Ils évaluent de nouvelles méthodes sur des problèmes de raisonnement numérique et de raisonnement relationnel. En inférence numérique, ils ont observé une amélioration de 21,0 % de la précision du GPT-4. En raisonnement relationnel, GPT-4 a obtenu une amélioration de la précision de 13,7 %, et GPT-3.5 en a bénéficié encore plus, doublant les performances. Le gain de performance vient principalement de la réduction de l’illusion des règles.
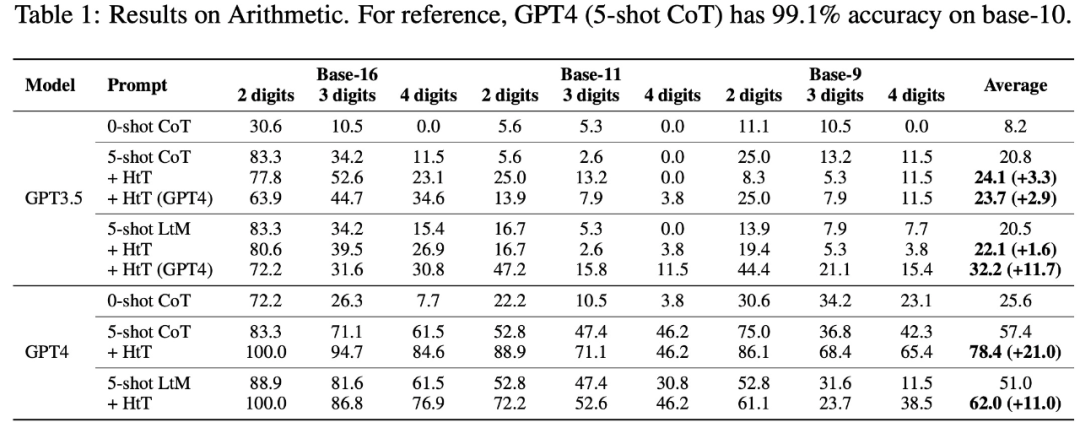
Plus précisément, le tableau 1 ci-dessous montre les résultats sur les ensembles de données arithmétiques en base 16, base 11 et base 9. Parmi tous les systèmes de base, le CoT 0-shot présente les pires performances dans les deux LLM.
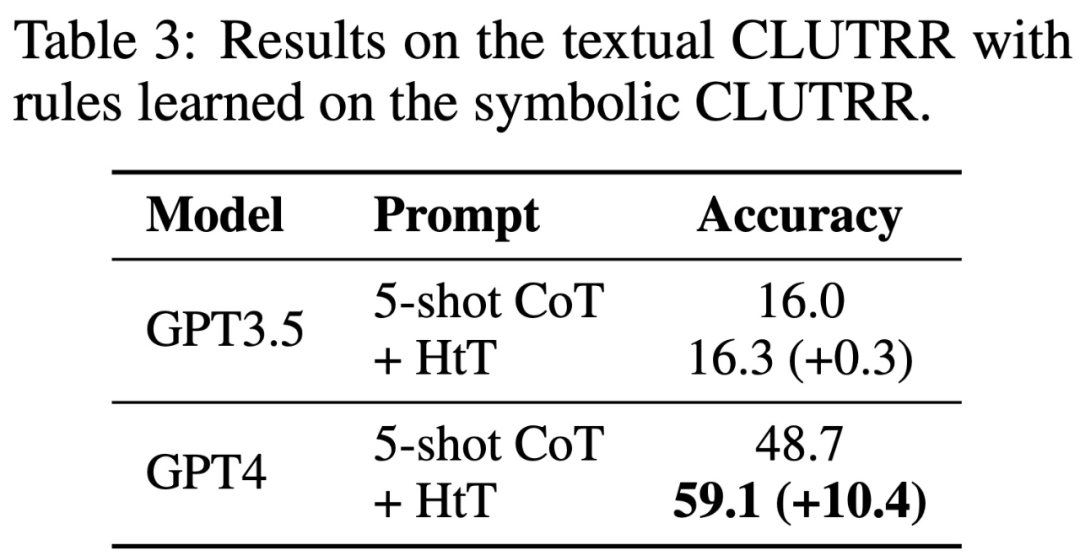
Le tableau 2 présente les résultats comparant différentes méthodes sur CLUTRR. On peut observer que le CoT 0-shot a les pires performances en GPT3.5 et GPT4. Pour la méthode d'invite en quelques tirs, CoT et LtM fonctionnent de la même manière. En termes de précision moyenne, HtT surpasse systématiquement les méthodes d'indication pour les deux modèles de 11,1 à 27,2 %. Il convient de noter que GPT3.5 n'est pas mauvais pour récupérer les règles CLUTRR et bénéficie davantage de HtT que GPT4, probablement parce qu'il y a moins de règles en CLUTRR qu'en arithmétique.
Il convient de mentionner qu'en utilisant les règles de GPT4, les performances CoT sur GPT3.5 sont améliorées de 27,2%, soit plus de deux fois les performances CoT et proches des performances CoT sur GPT4. Par conséquent, les auteurs pensent que HtT peut servir de nouvelle forme de distillation des connaissances d’un LLM fort à un LLM faible.
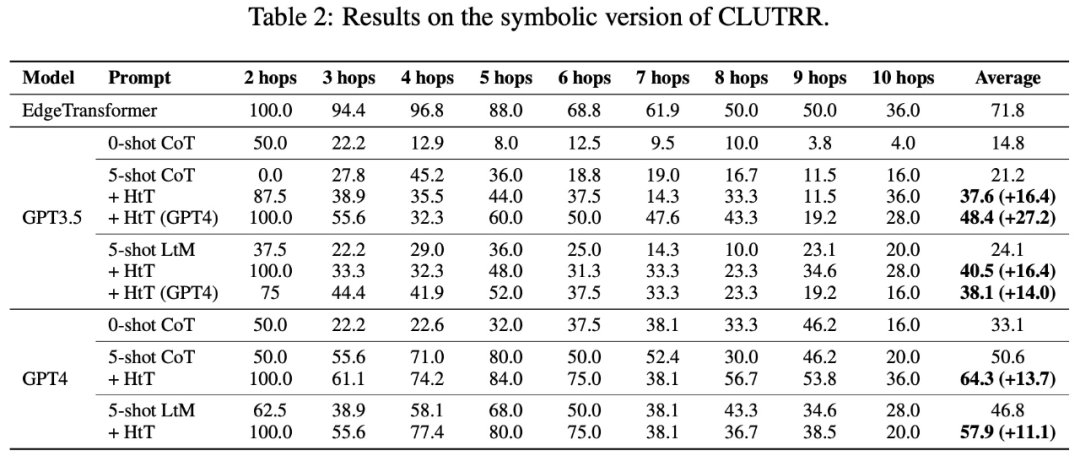
Le tableau 3 montre que HtT améliore considérablement les performances de GPT-4 (version texte). Cette amélioration n'est pas significative pour GPT3.5, car elle produit souvent des erreurs autres que l'illusion de règles lors du traitement de la saisie de texte.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 L'application de grands modèles Tencent Yuanbao est en ligne ! Hunyuan est mis à niveau pour créer un assistant IA complet pouvant être transporté n'importe où
Jun 09, 2024 pm 10:38 PM
L'application de grands modèles Tencent Yuanbao est en ligne ! Hunyuan est mis à niveau pour créer un assistant IA complet pouvant être transporté n'importe où
Jun 09, 2024 pm 10:38 PM
Le 30 mai, Tencent a annoncé une mise à niveau complète de son modèle Hunyuan. L'application « Tencent Yuanbao » basée sur le modèle Hunyuan a été officiellement lancée et peut être téléchargée sur les magasins d'applications Apple et Android. Par rapport à la version de l'applet Hunyuan lors de la phase de test précédente, Tencent Yuanbao fournit des fonctionnalités de base telles que la recherche IA, le résumé IA et l'écriture IA pour les scénarios d'efficacité du travail ; pour les scénarios de la vie quotidienne, le gameplay de Yuanbao est également plus riche et fournit de multiples fonctionnalités d'application IA. , et de nouvelles méthodes de jeu telles que la création d'agents personnels sont ajoutées. « Tencent ne s'efforcera pas d'être le premier à créer un grand modèle. » Liu Yuhong, vice-président de Tencent Cloud et responsable du grand modèle Tencent Hunyuan, a déclaré : « Au cours de l'année écoulée, nous avons continué à promouvoir les capacités de Tencent. Grand modèle Tencent Hunyuan. Dans la technologie polonaise riche et massive dans des scénarios commerciaux tout en obtenant un aperçu des besoins réels des utilisateurs.
 Lancement du grand modèle Bytedance Beanbao, le service d'IA complet Volcano Engine aide les entreprises à se transformer intelligemment
Jun 05, 2024 pm 07:59 PM
Lancement du grand modèle Bytedance Beanbao, le service d'IA complet Volcano Engine aide les entreprises à se transformer intelligemment
Jun 05, 2024 pm 07:59 PM
Tan Dai, président de Volcano Engine, a déclaré que les entreprises qui souhaitent bien mettre en œuvre de grands modèles sont confrontées à trois défis clés : l'effet de modèle, le coût d'inférence et la difficulté de mise en œuvre : elles doivent disposer d'un bon support de base de grands modèles pour résoudre des problèmes complexes, et elles doivent également avoir une inférence à faible coût. Les services permettent d'utiliser largement de grands modèles, et davantage d'outils, de plates-formes et d'applications sont nécessaires pour aider les entreprises à mettre en œuvre des scénarios. ——Tan Dai, président de Huoshan Engine 01. Le grand modèle de pouf fait ses débuts et est largement utilisé. Le polissage de l'effet de modèle est le défi le plus critique pour la mise en œuvre de l'IA. Tan Dai a souligné que ce n'est que grâce à une utilisation intensive qu'un bon modèle peut être poli. Actuellement, le modèle Doubao traite 120 milliards de jetons de texte et génère 30 millions d'images chaque jour. Afin d'aider les entreprises à mettre en œuvre des scénarios de modèles à grande échelle, le modèle à grande échelle beanbao développé indépendamment par ByteDance sera lancé à travers le volcan.
 Cet article vous amènera à comprendre SHAP : explication du modèle pour l'apprentissage automatique
Jun 01, 2024 am 10:58 AM
Cet article vous amènera à comprendre SHAP : explication du modèle pour l'apprentissage automatique
Jun 01, 2024 am 10:58 AM
Dans les domaines de l’apprentissage automatique et de la science des données, l’interprétabilité des modèles a toujours été au centre des préoccupations des chercheurs et des praticiens. Avec l'application généralisée de modèles complexes tels que l'apprentissage profond et les méthodes d'ensemble, la compréhension du processus décisionnel du modèle est devenue particulièrement importante. Explainable AI|XAI contribue à renforcer la confiance dans les modèles d'apprentissage automatique en augmentant la transparence du modèle. L'amélioration de la transparence des modèles peut être obtenue grâce à des méthodes telles que l'utilisation généralisée de plusieurs modèles complexes, ainsi que les processus décisionnels utilisés pour expliquer les modèles. Ces méthodes incluent l'analyse de l'importance des caractéristiques, l'estimation de l'intervalle de prédiction du modèle, les algorithmes d'interprétabilité locale, etc. L'analyse de l'importance des fonctionnalités peut expliquer le processus de prise de décision du modèle en évaluant le degré d'influence du modèle sur les fonctionnalités d'entrée. Estimation de l’intervalle de prédiction du modèle
 Implémentation d'algorithmes d'apprentissage automatique en C++ : défis et solutions courants
Jun 03, 2024 pm 01:25 PM
Implémentation d'algorithmes d'apprentissage automatique en C++ : défis et solutions courants
Jun 03, 2024 pm 01:25 PM
Les défis courants rencontrés par les algorithmes d'apprentissage automatique en C++ incluent la gestion de la mémoire, le multithread, l'optimisation des performances et la maintenabilité. Les solutions incluent l'utilisation de pointeurs intelligents, de bibliothèques de threads modernes, d'instructions SIMD et de bibliothèques tierces, ainsi que le respect des directives de style de codage et l'utilisation d'outils d'automatisation. Des cas pratiques montrent comment utiliser la bibliothèque Eigen pour implémenter des algorithmes de régression linéaire, gérer efficacement la mémoire et utiliser des opérations matricielles hautes performances.
 Pratique avancée du graphe de connaissances industrielles
Jun 13, 2024 am 11:59 AM
Pratique avancée du graphe de connaissances industrielles
Jun 13, 2024 am 11:59 AM
1. Introduction au contexte Tout d’abord, présentons l’historique du développement de la technologie Yunwen. Yunwen Technology Company... 2023 est la période où les grands modèles prédominent. De nombreuses entreprises pensent que l'importance des graphiques a été considérablement réduite après les grands modèles et que les systèmes d'information prédéfinis étudiés précédemment ne sont plus importants. Cependant, avec la promotion du RAG et la prévalence de la gouvernance des données, nous avons constaté qu'une gouvernance des données plus efficace et des données de haute qualité sont des conditions préalables importantes pour améliorer l'efficacité des grands modèles privatisés. Par conséquent, de plus en plus d'entreprises commencent à y prêter attention. au contenu lié à la construction des connaissances. Cela favorise également la construction et le traitement des connaissances à un niveau supérieur, où de nombreuses techniques et méthodes peuvent être explorées. On voit que l'émergence d'une nouvelle technologie ne détruit pas toutes les anciennes technologies, mais peut également intégrer des technologies nouvelles et anciennes.
 Xiaomi Byte unit ses forces ! Un grand modèle de l'accès de Xiao Ai à Doubao : déjà installé sur les téléphones mobiles et SU7
Jun 13, 2024 pm 05:11 PM
Xiaomi Byte unit ses forces ! Un grand modèle de l'accès de Xiao Ai à Doubao : déjà installé sur les téléphones mobiles et SU7
Jun 13, 2024 pm 05:11 PM
Selon les informations du 13 juin, selon le compte public « Volcano Engine » de Byte, l'assistant d'intelligence artificielle de Xiaomi « Xiao Ai » a conclu une coopération avec Volcano Engine. Les deux parties réaliseront une expérience interactive d'IA plus intelligente basée sur le grand modèle beanbao. . Il est rapporté que le modèle beanbao à grande échelle créé par ByteDance peut traiter efficacement jusqu'à 120 milliards de jetons de texte et générer 30 millions de contenus chaque jour. Xiaomi a utilisé le grand modèle Doubao pour améliorer les capacités d'apprentissage et de raisonnement de son propre modèle et créer un nouveau « Xiao Ai Classmate », qui non seulement saisit plus précisément les besoins des utilisateurs, mais offre également une vitesse de réponse plus rapide et des services de contenu plus complets. Par exemple, lorsqu'un utilisateur pose une question sur un concept scientifique complexe, &ldq
 IA explicable : Expliquer les modèles IA/ML complexes
Jun 03, 2024 pm 10:08 PM
IA explicable : Expliquer les modèles IA/ML complexes
Jun 03, 2024 pm 10:08 PM
Traducteur | Revu par Li Rui | Chonglou Les modèles d'intelligence artificielle (IA) et d'apprentissage automatique (ML) deviennent aujourd'hui de plus en plus complexes, et le résultat produit par ces modèles est une boîte noire – impossible à expliquer aux parties prenantes. L'IA explicable (XAI) vise à résoudre ce problème en permettant aux parties prenantes de comprendre comment fonctionnent ces modèles, en s'assurant qu'elles comprennent comment ces modèles prennent réellement des décisions et en garantissant la transparence des systèmes d'IA, la confiance et la responsabilité pour résoudre ce problème. Cet article explore diverses techniques d'intelligence artificielle explicable (XAI) pour illustrer leurs principes sous-jacents. Plusieurs raisons pour lesquelles l’IA explicable est cruciale Confiance et transparence : pour que les systèmes d’IA soient largement acceptés et fiables, les utilisateurs doivent comprendre comment les décisions sont prises
 Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
L'ensemble de données ScienceAI Question Answering (QA) joue un rôle essentiel dans la promotion de la recherche sur le traitement du langage naturel (NLP). Des ensembles de données d'assurance qualité de haute qualité peuvent non seulement être utilisés pour affiner les modèles, mais également évaluer efficacement les capacités des grands modèles linguistiques (LLM), en particulier la capacité à comprendre et à raisonner sur les connaissances scientifiques. Bien qu’il existe actuellement de nombreux ensembles de données scientifiques d’assurance qualité couvrant la médecine, la chimie, la biologie et d’autres domaines, ces ensembles de données présentent encore certaines lacunes. Premièrement, le formulaire de données est relativement simple, et la plupart sont des questions à choix multiples. Elles sont faciles à évaluer, mais limitent la plage de sélection des réponses du modèle et ne peuvent pas tester pleinement la capacité du modèle à répondre aux questions scientifiques. En revanche, les questions et réponses ouvertes
