

Cet article est réimprimé avec l'autorisation d'AI New Media Qubit (ID de compte public : QbitAI). Veuillez contacter la source pour la réimpression.
Sous beaucoup d'attention, GPT4 a enfin lancé aujourd'hui des fonctions liées à la vision.
J'ai rapidement testé les capacités de perception d'image de GPT avec mes amis cet après-midi. Même si nous avions des attentes, nous avons quand même été très choqués.
Point de vue principal :
Je pense que les problèmes liés à la sémantique dans la conduite autonome auraient dû être bien résolus par les grands modèles, mais la crédibilité et les capacités de perception spatiale des grands modèles ne sont toujours pas satisfaisantes.
Cela devrait être plus que suffisant pour résoudre certains cas dits d'angle liés à l'efficacité, mais il est encore très loin de s'appuyer entièrement sur de gros modèles pour terminer la conduite de manière autonome et assurer la sécurité.


△Description GPT4
Partie précise : 3 camions ont été détectés, le numéro de plaque d'immatriculation du véhicule qui précède est fondamentalement correct (ignorez s'il y a des chinois caractères), météo correcte avec l'environnement, a identifié avec précision les obstacles inconnus à venir sans invite .
Pièces inexactes : la position du troisième camion est impossible à distinguer de gauche à droite, et le texte au-dessus de la tête du deuxième camion est une supposition aléatoire (en raison d'une résolution insuffisante ?).
Cela ne suffit pas, continuons à donner un petit indice et demandons ce qu'est cet objet et s'il peut être pressé.
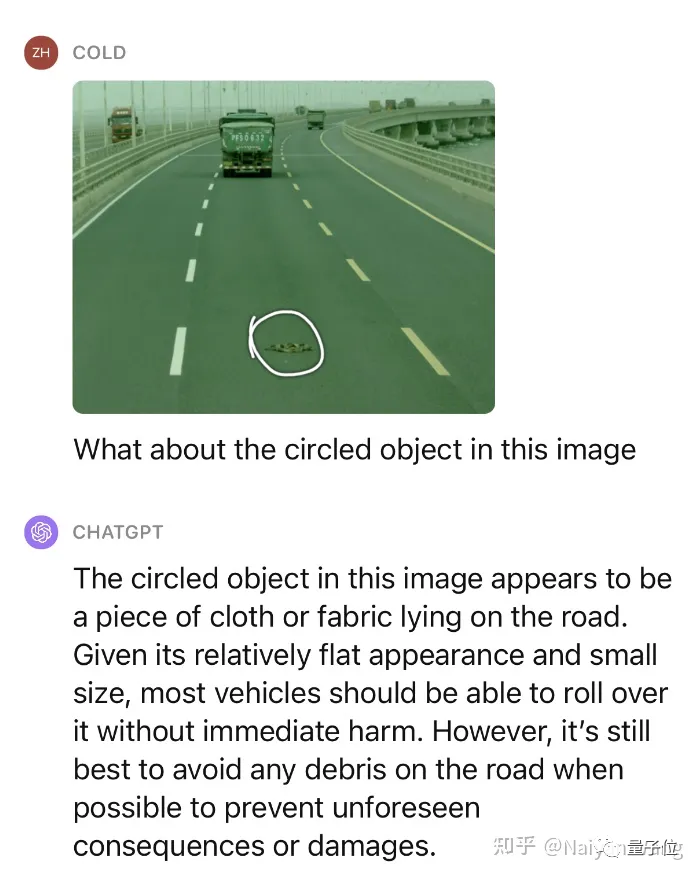
Impressionnant ! Nous avons testé plusieurs scénarios similaires, et les performances sur des obstacles inconnus peuvent être considérées comme très étonnantes.
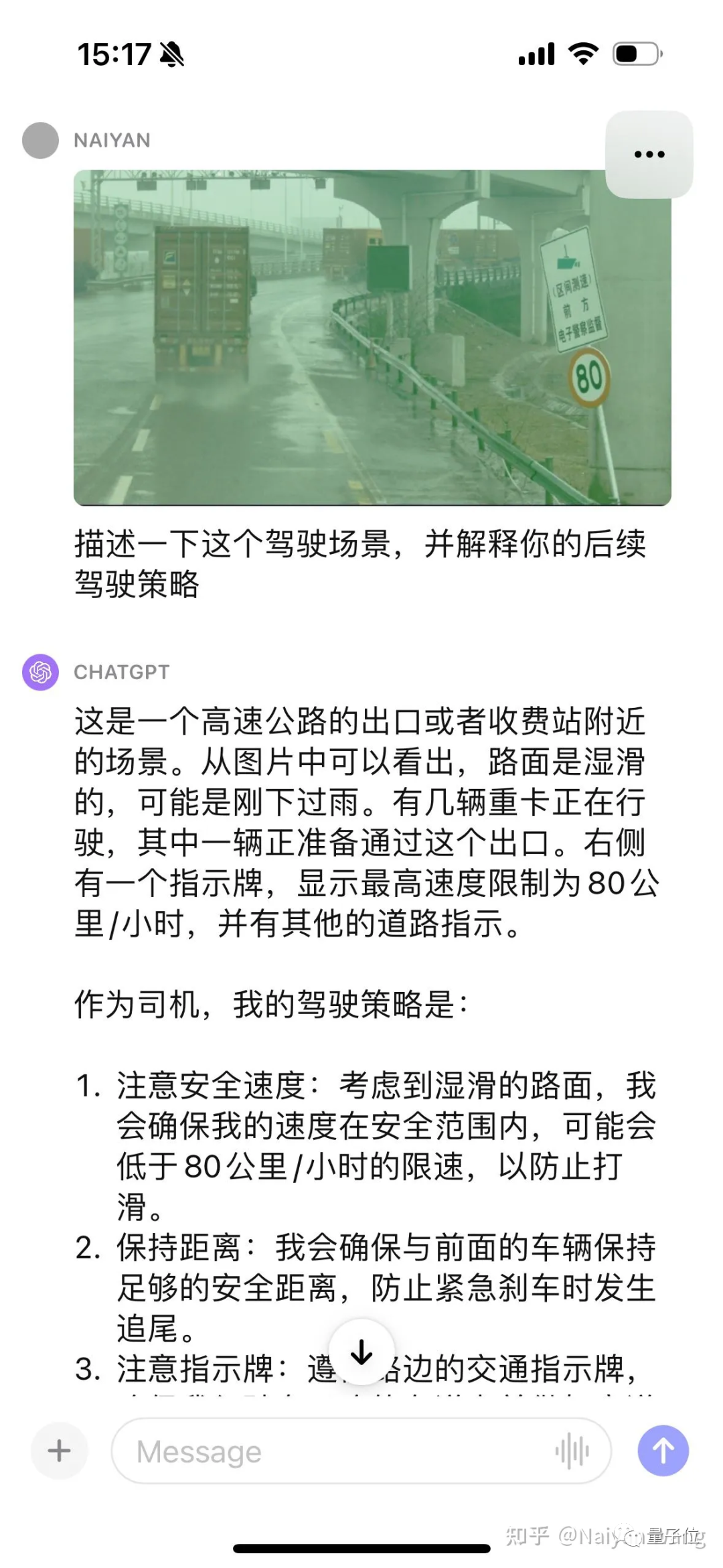
Il n'y a pas d'invite pour reconnaître automatiquement le panneau. Cela devrait être basique, continuons à donner quelques indices.

J'ai encore été choqué. . . Il pouvait automatiquement reconnaître le brouillard derrière le camion et a également mentionné la flaque d'eau, mais a encore une fois indiqué que la direction était à gauche. . . Je pense qu'une ingénierie rapide peut être nécessaire ici pour mieux permettre à GPT d'afficher la position et la direction.

La première image a été saisie Parce qu'il n'y avait aucune information de chronométrage, le camion de droite a simplement été considéré comme garé. Alors voici une autre image :

Je peux déjà le dire automatiquement. Cette voiture a percuté le garde-corps et a plané sur le bord de la route. . . Mais au lieu de cela, les panneaux routiers qui semblaient plus faciles étaient faux. . . Tout ce que je peux dire, c'est que c'est un modèle énorme. Il vous choquera toujours et vous ne savez jamais quand il vous fera pleurer. . . Une autre image :

Cette fois, elle parle directement des débris sur la route, et je l'admire à nouveau. . . Mais une fois, j'ai mal nommé la flèche sur la route. . . D'une manière générale, les informations qui nécessitent une attention particulière dans cette scène sont couvertes. Pour des problèmes tels que la signalisation routière, les défauts ne sont pas masqués.

On peut seulement dire que c'est très précis par rapport aux cas auparavant difficiles comme « quelqu'un vous a fait signe », c'est comme un jeu d'enfant et peut être résolu avec des cas d'angle sémantiques.
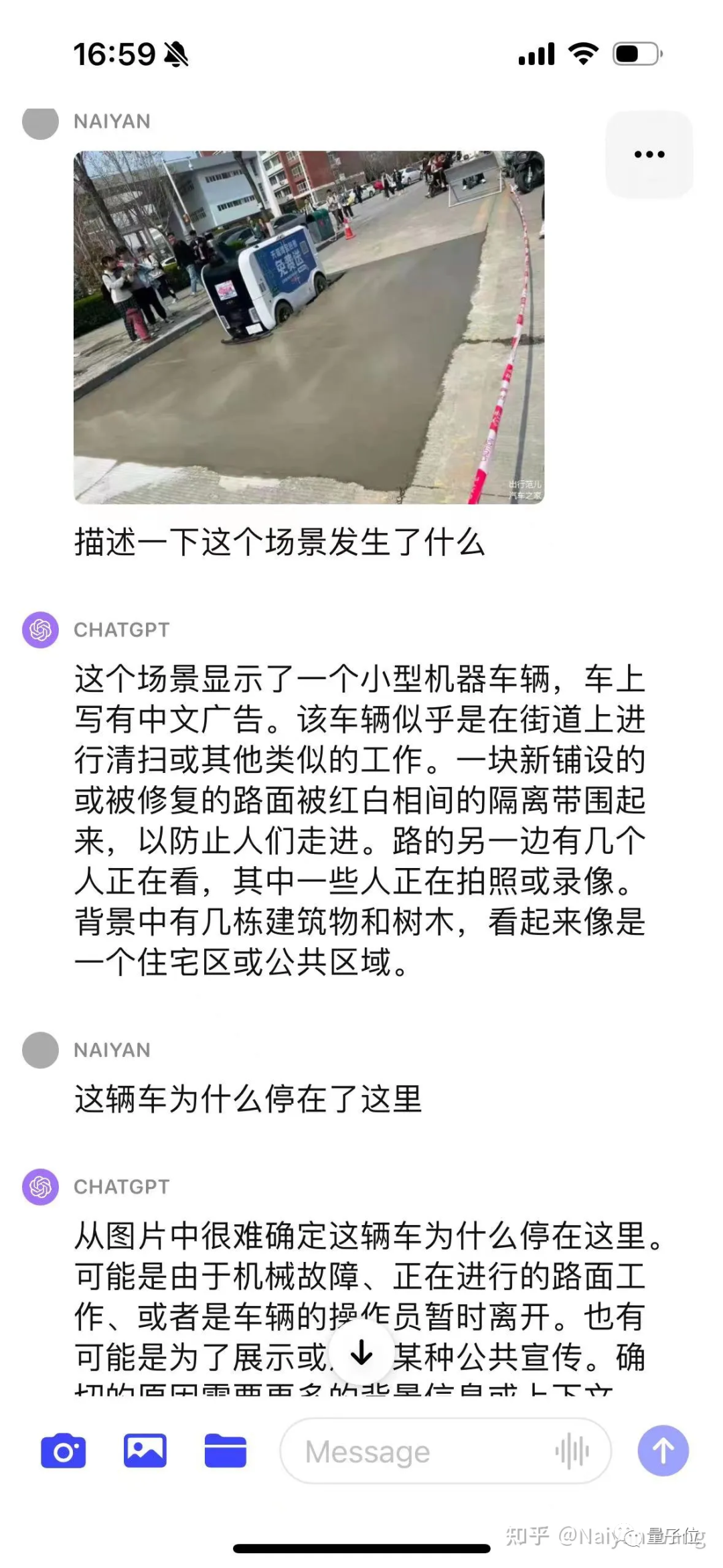



J'étais relativement conservateur au début et je n'ai pas deviné directement la cause. Cela est conforme à. les objectifs de l’alignement.
Après avoir utilisé CoT, il a été découvert que le problème était que la voiture n'était pas considérée comme un véhicule autonome, donc donner ces informations via une invite peut donner des informations plus précises.
Enfin, grâce à de nombreuses invites, je peux conclure que l'asphalte nouvellement posé n'est pas adapté à la conduite. Le résultat final est toujours correct, mais le processus est plus tortueux et nécessite une ingénierie plus rapide et une conception plus soignée.
Cette raison peut aussi être due au fait que l'image n'est pas du premier point de vue et ne peut être déduite qu'à partir du troisième point de vue. Cet exemple n'est donc pas très précis.
Certaines tentatives rapides ont pleinement prouvé la puissance et les performances de généralisation de GPT4V. Des invites appropriées devraient pouvoir utiliser pleinement la force de GPT4V.
Il devrait être très prometteur de résoudre le cas du coin sémantique, mais le problème de l'illusion continuera de tourmenter certaines applications dans des scénarios liés à la sécurité.
Très excitant. Je pense personnellement que l'utilisation rationnelle de modèles aussi grands peut considérablement accélérer le développement de la conduite autonome L4 et même L5. Cependant, LLM doit-il conduire directement ? La conduite de bout en bout, en particulier, reste une question discutable.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Quelles compétences sont nécessaires pour travailler dans l'industrie PHP ?
Quelles compétences sont nécessaires pour travailler dans l'industrie PHP ?
 Quelles sont les technologies de collecte de données ?
Quelles sont les technologies de collecte de données ?
 Tutoriel sur la fabrication de pièces inscrites
Tutoriel sur la fabrication de pièces inscrites
 Comment exprimer des espaces dans des expressions régulières
Comment exprimer des espaces dans des expressions régulières
 Comment gérer les téléchargements de fichiers bloqués dans Windows 10
Comment gérer les téléchargements de fichiers bloqués dans Windows 10
 Introduction au middleware Laravel
Introduction au middleware Laravel
 Site officiel d'OuYi Exchange
Site officiel d'OuYi Exchange
 Comment ouvrir l'Explorateur Windows 7
Comment ouvrir l'Explorateur Windows 7
 Quels sont les moteurs de workflow Java ?
Quels sont les moteurs de workflow Java ?








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



