

众所周知,对 GPT-3.5 进行微调是非常昂贵的。本文通过实验来验证手动微调模型是否可以接近 GPT-3.5 的性能,而成本只是 GPT-3.5 的一小部分。有趣的是,本文确实做到了。
在 SQL 任务和 functional representation 任务上的结果对比,本文发现:
本实验的结论之一是微调 GPT-3.5 适用于初始验证工作,但在那之后,像 Llama 2 这样的模型可能是最佳选择,简单总结一下:
接下来我们看看,本文是如何实现的。
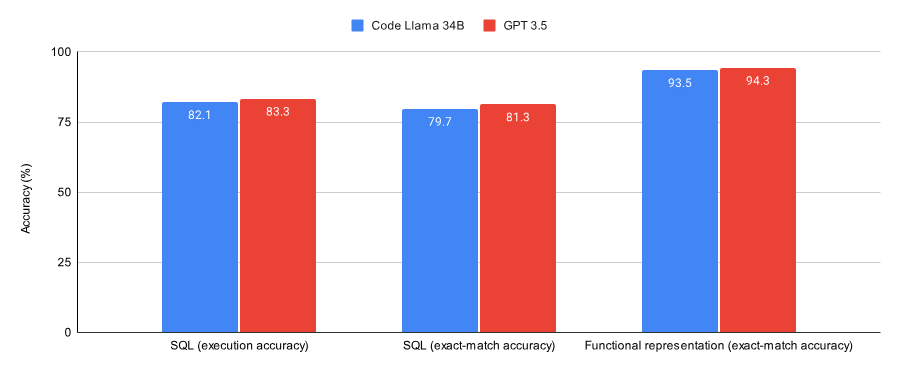
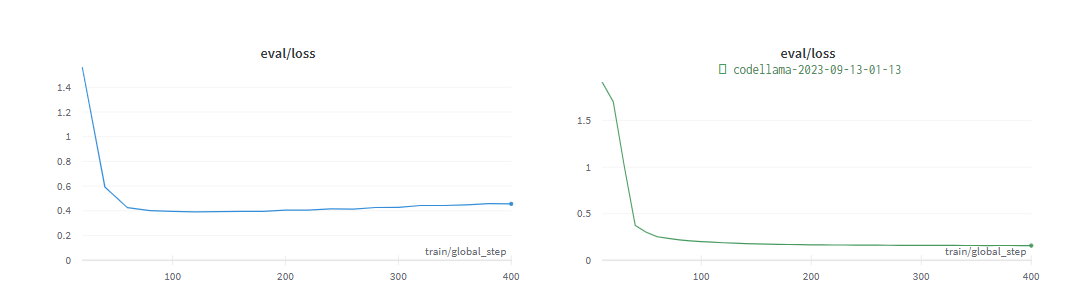
下图为 Code Llama 34B 和 GPT-3.5 在 SQL 任务和 functional representation 任务上训练至收敛的性能。结果表明,GPT-3.5 在这两个任务上都取得了更好的准确率。
在硬件使用上,实验使用的是 A40 GPU,每小时约 0.475 美元。
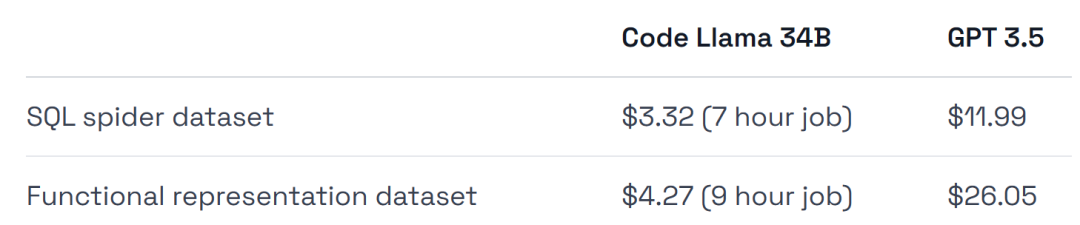
此外,实验选取了两个非常适合进行微调的数据集,Spider 数据集的子集以及 Viggo functional representation 数据集。
为了与 GPT-3.5 模型进行公平的比较,实验对 Llama 进行了最少超参数微调。
本文实验的两个关键选择是使用 Code Llama 34B 和 Lora 微调,而不是全参数微调。
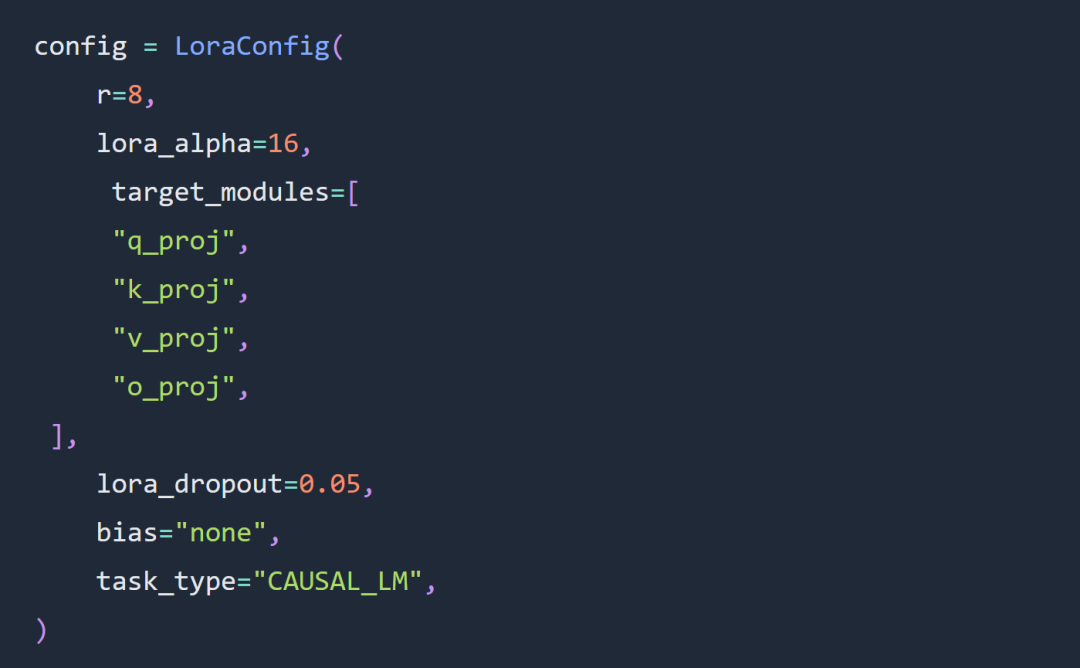
实验在很大程度上遵循了有关 Lora 超参数微调的规则,Lora 适配器配置如下:
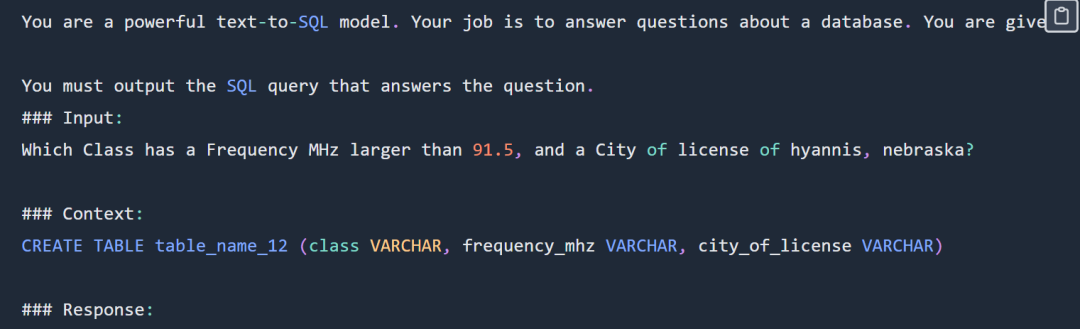
SQL 提示示例如下:
SQL 提示部分展示,完整提示请查看原博客
实验没有使用完整的 Spider 数据集,具体形式如下
department : Department_ID [ INT ] primary_key Name [ TEXT ] Creation [ TEXT ] Ranking [ INT ] Budget_in_Billions [ INT ] Num_Employees [ INT ] head : head_ID [ INT ] primary_key name [ TEXT ] born_state [ TEXT ] age [ INT ] management : department_ID [ INT ] primary_key management.department_ID = department.Department_ID head_ID [ INT ] management.head_ID = head.head_ID temporary_acting [ TEXT ]
实验选择使用 sql-create-context 数据集和 Spider 数据集的交集。为模型提供的上下文是一个 SQL 创建命令,如下所示:
CREATE TABLE table_name_12 (class VARCHAR, frequency_mhz VARCHAR, city_of_license VARCHAR)
SQL 任务的代码和数据地址:https://github.com/samlhuillier/spider-sql-finetune
functional representation 提示的示例如下所示:
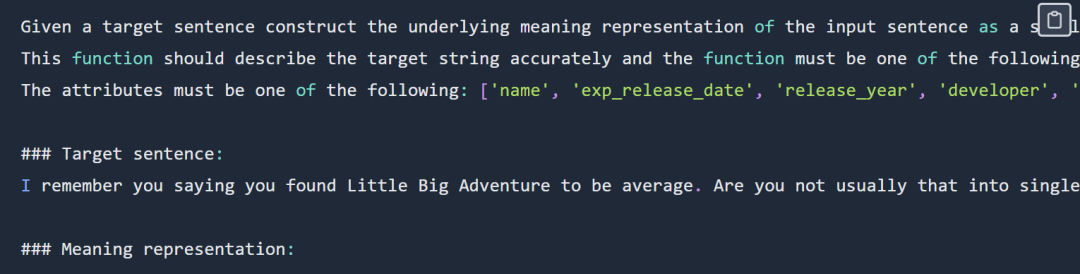
functional representation 提示部分展示,完整提示请查看原博客
输出如下所示:
verify_attribute(name[Little Big Adventure], rating[average], has_multiplayer[no], platforms[PlayStation])
评估阶段,两个实验很快就收敛了:
functional representation 任务代码和数据地址:https://github.com/samlhuillier/viggo-finetune
了解更多内容,请查看原博客。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment lier des données dans une liste déroulante
Comment lier des données dans une liste déroulante
 Comment modifier par lots les noms de fichiers
Comment modifier par lots les noms de fichiers
 Téléchargement du logiciel de trading Yiou
Téléchargement du logiciel de trading Yiou
 Encyclopédie ChatGPT nationale gratuite
Encyclopédie ChatGPT nationale gratuite
 Comment illuminer le moment des amis proches de Douyin
Comment illuminer le moment des amis proches de Douyin
 La différence entre vivox100s et x100
La différence entre vivox100s et x100
 API de Google Maps
API de Google Maps
 utilisation de la fonction setproperty
utilisation de la fonction setproperty








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



