
 Périphériques technologiques
IA
Pratique et réflexion sur la plateforme multimodale de grands modèles Jiuzhang Yunji DataCanvas
Périphériques technologiques
IA
Pratique et réflexion sur la plateforme multimodale de grands modèles Jiuzhang Yunji DataCanvas
Pratique et réflexion sur la plateforme multimodale de grands modèles Jiuzhang Yunji DataCanvas


1. Le développement historique des grands modèles multimodaux

La photo ci-dessus est le premier atelier sur l'intelligence artificielle organisé au Dartmouth College aux États-Unis en 1956. Cette conférence est également considérée comme Ce sera le début de l'intelligence artificielle, et les participants sont principalement des pionniers de la logique symbolique (à l'exception du neurobiologiste Peter Milner au milieu du premier rang).
Cependant, cette théorie de la logique symbolique n'a pas pu être réalisée avant longtemps, et même la première période hivernale de l'IA a eu lieu dans les années 1980 et 1990. Ce n'est que grâce à la récente mise en œuvre de grands modèles de langage que nous avons découvert que les réseaux de neurones portent réellement cette pensée logique. Les travaux du neurobiologiste Peter Milner ont inspiré le développement ultérieur des réseaux de neurones artificiels, et c'est pour cette raison qu'il a été invité à y participer. lors de cette réunion académique.

En 2012, Andrew, directeur des véhicules autonomes de Tesla, a publié la photo ci-dessus sur son blog, montrant le président américain de l'époque, Obama, en train de plaisanter avec ses subordonnés. Pour que l'intelligence artificielle comprenne cette image, il ne s'agit pas seulement d'une tâche de perception visuelle, car en plus d'identifier les objets, elle doit également comprendre la relation entre eux. Ce n'est qu'en connaissant les principes physiques de l'échelle que nous pouvons connaître l'histoire décrite dans ; la photo : Obama marche dessus L'homme sur la balance a pris du poids, ce qui lui a valu cette expression étrange tandis que d'autres riaient. Une telle pensée logique a évidemment dépassé le cadre de la perception visuelle pure.Par conséquent, la cognition visuelle et la pensée logique doivent être combinées pour se débarrasser de l'embarras du « retard mental artificiel ». L'importance et la difficulté des grands modèles multimodaux se reflètent également ici. c'est.
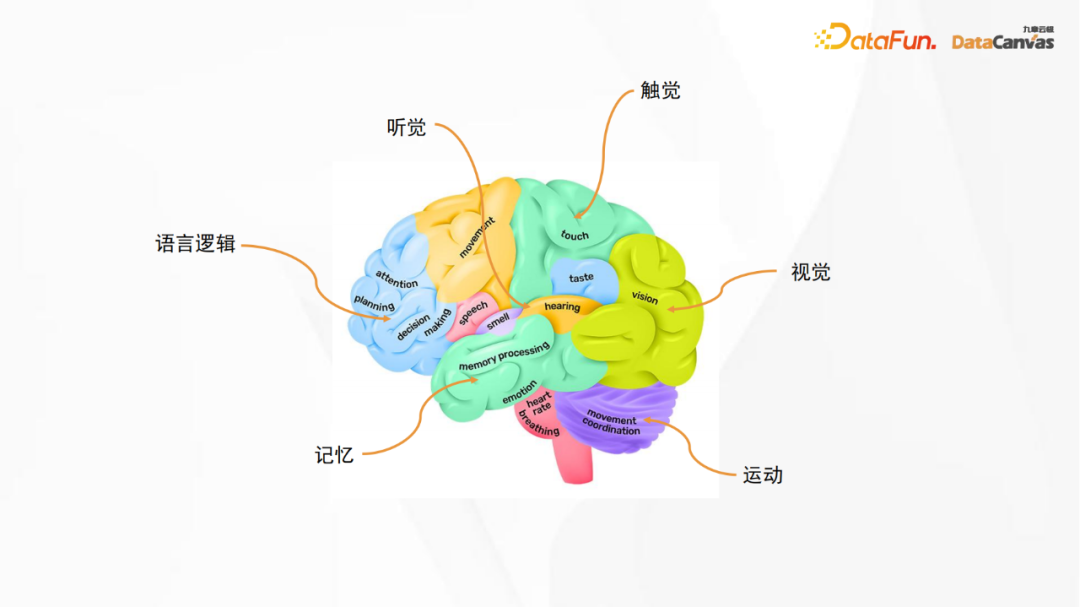
L'image ci-dessus est un diagramme de structure anatomique du cerveau humain. La zone logique du langage sur l'image correspond au grand modèle de langage, tandis que d'autres zones correspondent à différents sens, notamment la vision, l'ouïe, le toucher et mouvement, mémoire, etc. Bien que le réseau de neurones artificiels ne soit pas un réseau de neurones cérébraux au sens propre du terme, nous pouvons toujours nous en inspirer, c'est-à-dire que lors de la construction d'un grand modèle, différentes fonctions peuvent être combinées entre elles. construction de modèles multimodaux.
1. Que peuvent faire les grands modèles multimodaux ?
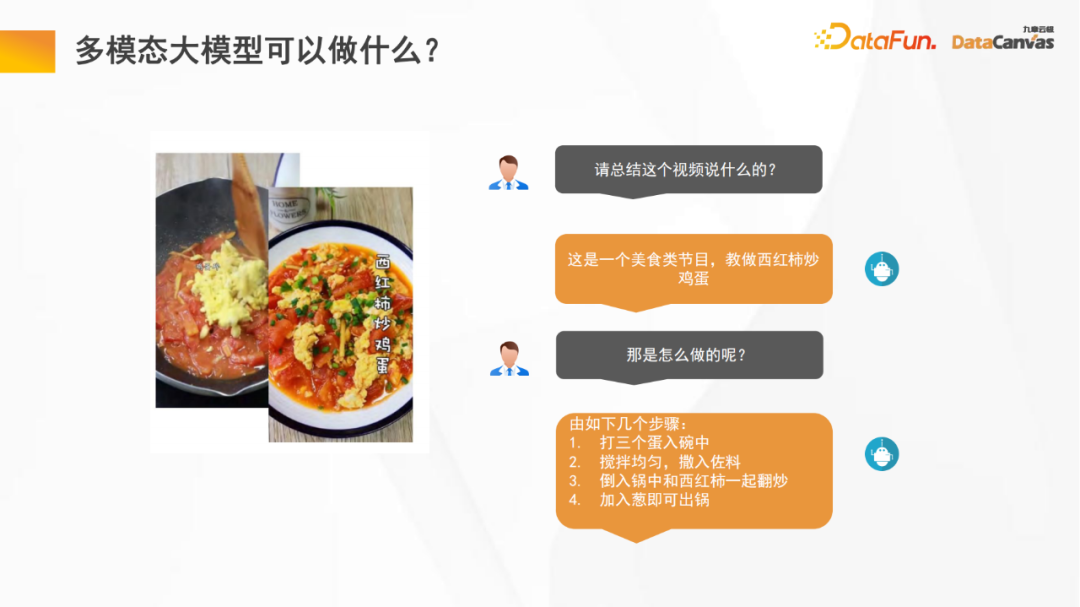
Les grands modèles multimodaux peuvent faire beaucoup de choses pour nous, comme la compréhension de la vidéo. peut également nous aider Effectuer une post-analyse de vidéos, telle que la classification des programmes, les statistiques d'évaluation des programmes, etc. De plus, les graphiques vincentiens sont également un domaine d'application important des grands modèles multimodaux.
Si le grand modèle est combiné avec le mouvement de personnes ou de robots, une intelligence incarnée sera générée, tout comme les personnes, la méthode de planification du meilleur chemin basée sur l'expérience passée sera appliquée au nouveau Dans le scénario, résolvez certains problèmes qui n'ont jamais été rencontrés auparavant tout en évitant les risques ; vous pouvez même modifier le plan original pendant le processus d'exécution jusqu'à ce que vous obteniez enfin le succès. Il s’agit également d’un scénario d’application offrant de larges perspectives.
2. Grand modèle multimodal
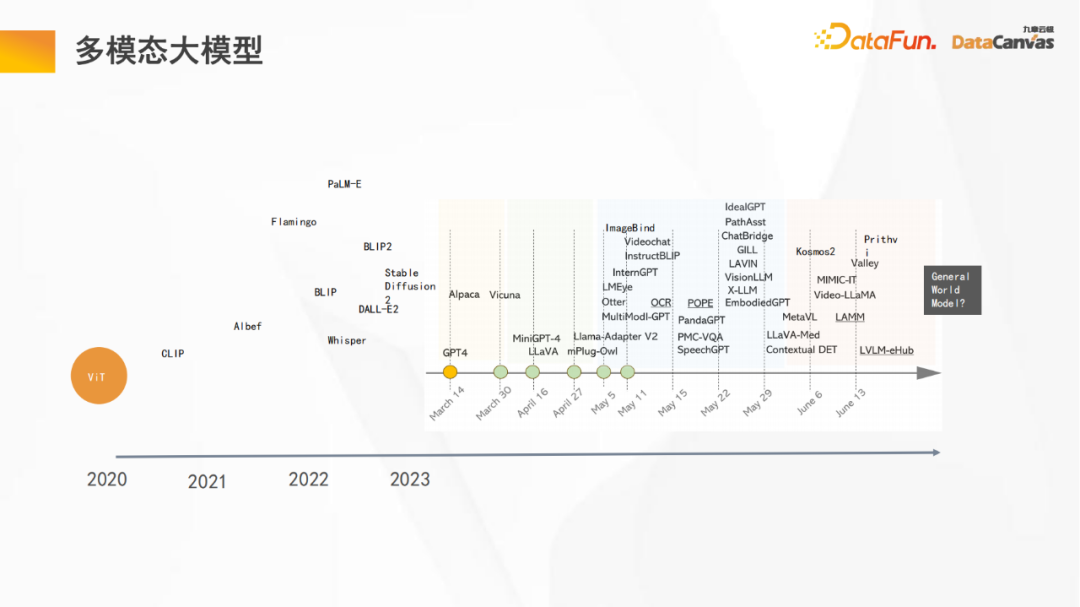
L'image ci-dessus montre quelques nœuds importants dans le processus de développement du grand modèle multimodal :
- Le modèle ViT 2020 (Vision Transformer) est le début d'un grand modèle. Pour la première fois, l'architecture Transformer est utilisée pour d'autres types de données (données visuelles) en plus du langage et du traitement logique, et cela se voit. bonnes capacités de généralisation ;
- Puis grâce au modèle open source CLIP d'OpenAI, il a été une fois de plus prouvé que grâce à l'utilisation de ViT et de grands modèles de langage, les tâches visuelles atteignent de fortes capacités de généralisation à longue traîne, c'est-à-dire de déduction des catégories inédites grâce au bon sens
- D'ici 2023, divers grands modèles multimodaux émergeront progressivement, de PaLM-E (robot), à murmurer (reconnaissance vocale), à ImageBind (alignement d'images), à Sam ( segmentation sémantique) ), et enfin aux images géographiques incluant également l'architecture multimodale unifiée Kosmos2 de Microsoft, les grands modèles multimodaux se développent rapidement.
- Tesla a également proposé la vision d'un modèle mondial universel au CVPR en juin.
Comme vous pouvez le voir sur l'image ci-dessus, en seulement six mois, de nombreux changements ont eu lieu dans le grand modèle, et sa vitesse d'itération est très rapide.
3. Architecture d'alignement modal
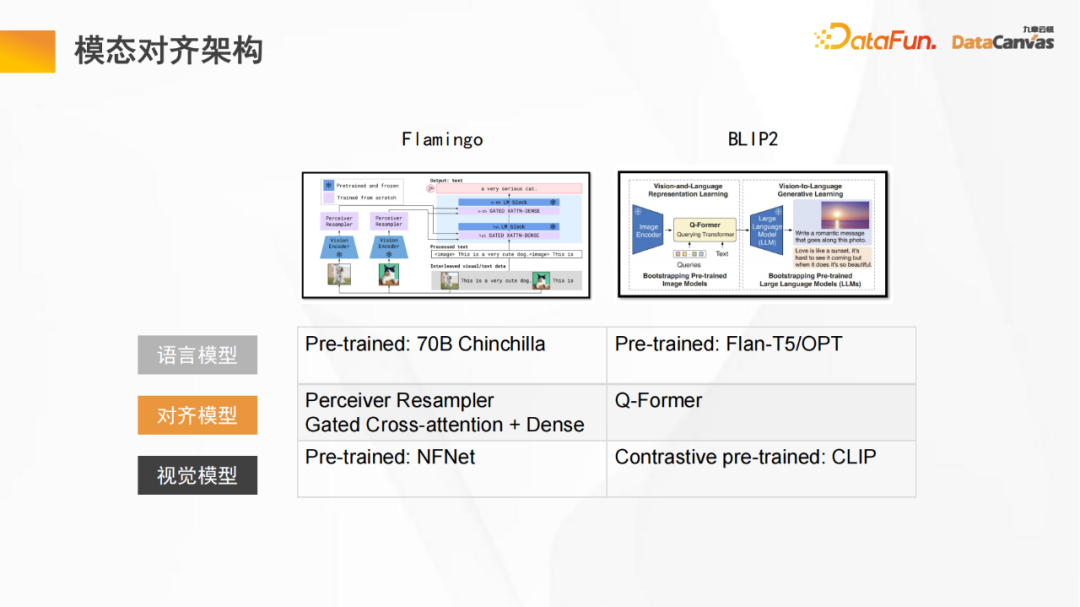
L'image ci-dessus est un schéma d'architecture générale d'un grand modèle multimodal, comprenant un modèle de langage et un modèle visuel, à travers un modèle de langage fixe et un modèle visuel fixe. Apprenez à aligner le modèle ; l'alignement consiste à combiner l'espace vectoriel du modèle visuel et l'espace vectoriel du modèle de langage, puis à compléter la compréhension de la relation logique interne entre les deux dans un espace vectoriel unifié.
Le modèle Flamingo et le modèle BLIP2 présentés sur la photo adoptent une structure similaire (le modèle Flamingo utilise l'architecture Perceiver, tandis que le modèle BLIP2 utilise une version améliorée de l'architecture Transformer) ; grâce à une variété de méthodes d'apprentissage contrastées. Un grand nombre de jetons sont utilisés pour une grande quantité d'apprentissage afin d'obtenir de meilleurs effets d'alignement, enfin, le modèle est affiné en fonction de tâches spécifiques ;
2. Plateforme multimodale de grands modèles de Jiuzhang Yunji DataCanvas
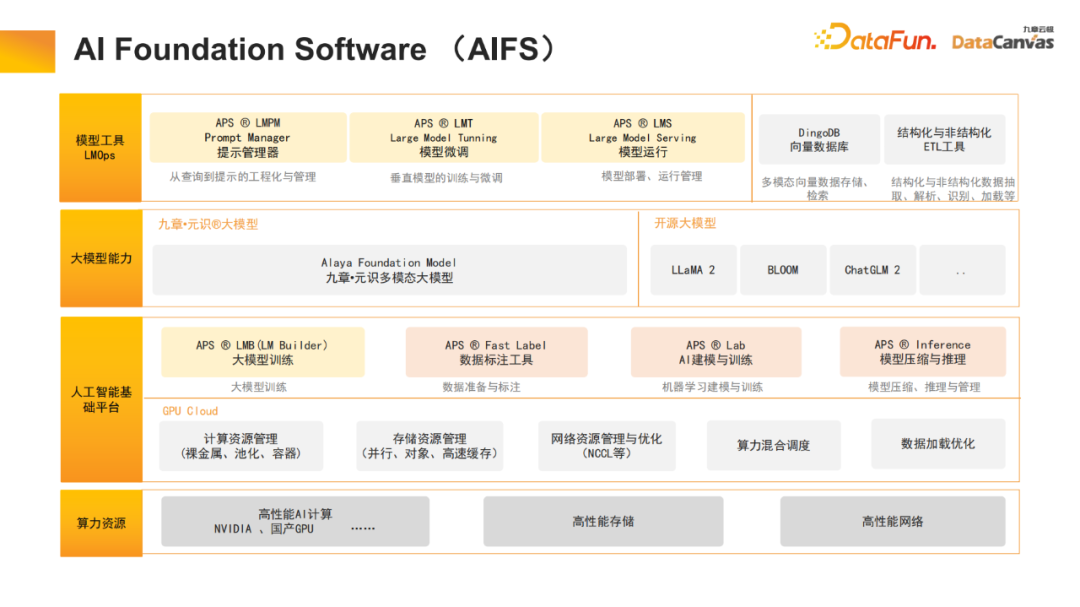
1. AI Foundation Software (AIFS)
Jiuzhang Yunji DataCanvas est un fournisseur de logiciels de base d'intelligence artificielle et fournit également des ressources humaines informatiques (y compris Clusters GPU) sont utilisés pour effectuer un stockage haute performance et une optimisation du réseau sur cette base, de grands outils de formation de modèles sont fournis, notamment des bacs à sable expérimentaux de modélisation d'annotation de données, etc. Jiuzhang Yunji DataCanvas prend non seulement en charge les grands modèles open source courants sur le marché, mais développe également de manière indépendante les grands modèles multimodaux Yuanshi. Au niveau de la couche application, des outils sont fournis pour gérer les mots d'invite, affiner le modèle et fournir un mécanisme d'exploitation et de maintenance du modèle. Parallèlement, une base de données vectorielles multimodale a été open source pour enrichir l'architecture logicielle de base.
2. L'outil de modèle LMOPS
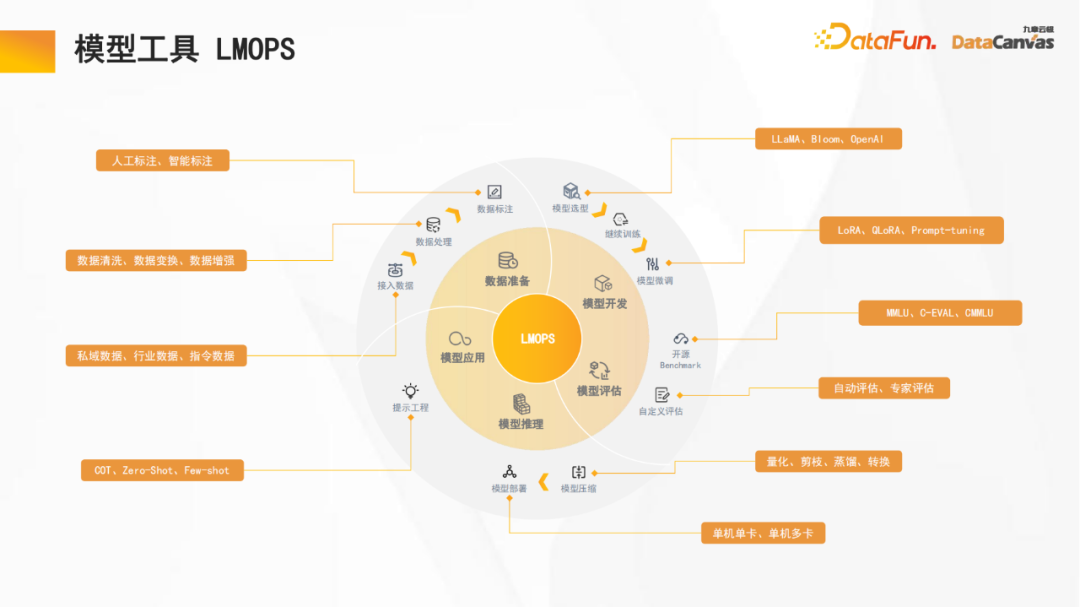
Jiuzhang Yunji DataCanvas se concentre sur l'optimisation du développement du cycle de vie complet, y compris la préparation des données (l'annotation des données prend en charge l'annotation manuelle et l'annotation intelligente), le développement du modèle, le modèle évaluation (y compris l'évaluation horizontale et l'évaluation verticale), le raisonnement sur modèle (supportant la quantification du modèle, la distillation des connaissances et autres mécanismes de raisonnement accéléré), l'application du modèle, etc.
3. LMB – Large Model Builder

Lors de la construction du modèle, de nombreux travaux d'optimisation distribués et efficaces ont été effectués, notamment le parallélisme des données, le parallélisme tenseur, le parallélisme des pipelines, etc. Ces tâches d'optimisation distribuées sont effectuées en un seul clic et prennent en charge le contrôle visuel, ce qui peut réduire considérablement les coûts de main-d'œuvre et améliorer l'efficacité du développement.
4、LMB – Constructeur de grands modèles
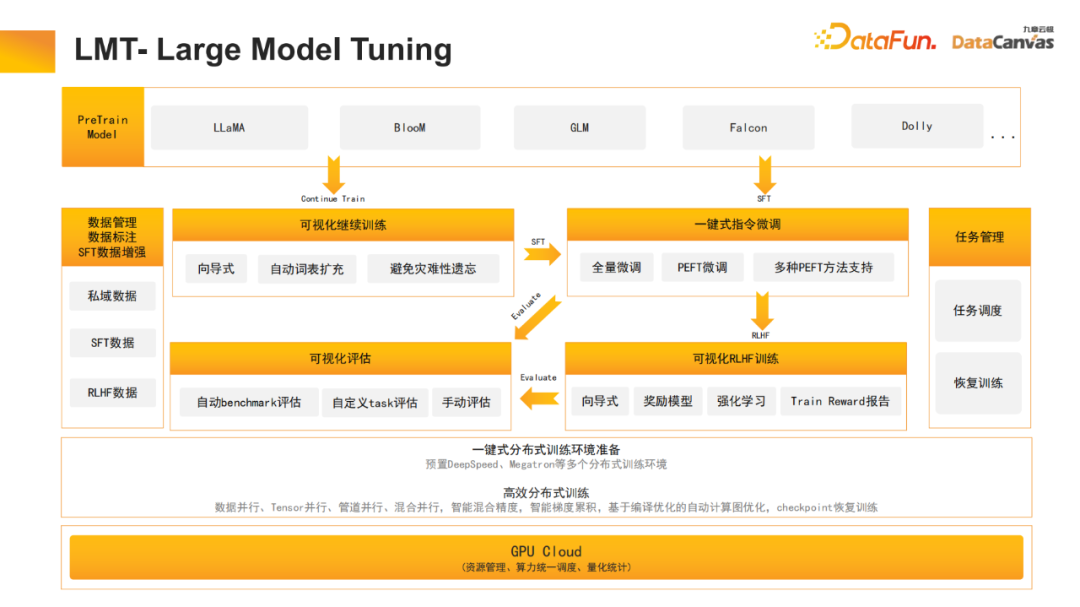
Le réglage des grands modèles a également été optimisé, y compris la formation continue commune, le réglage de la supervision et le retour humain dans l'apprentissage par renforcement. De plus, de nombreuses optimisations ont été apportées pour le chinois, comme l'expansion automatique du vocabulaire chinois. Étant donné que de nombreux mots chinois ne sont pas inclus dans les grands modèles open source, ces mots peuvent être divisés en plusieurs jetons ; l'expansion automatique de ces mots peut permettre au modèle de mieux utiliser ces mots.
5. LMS – Large Model Serving
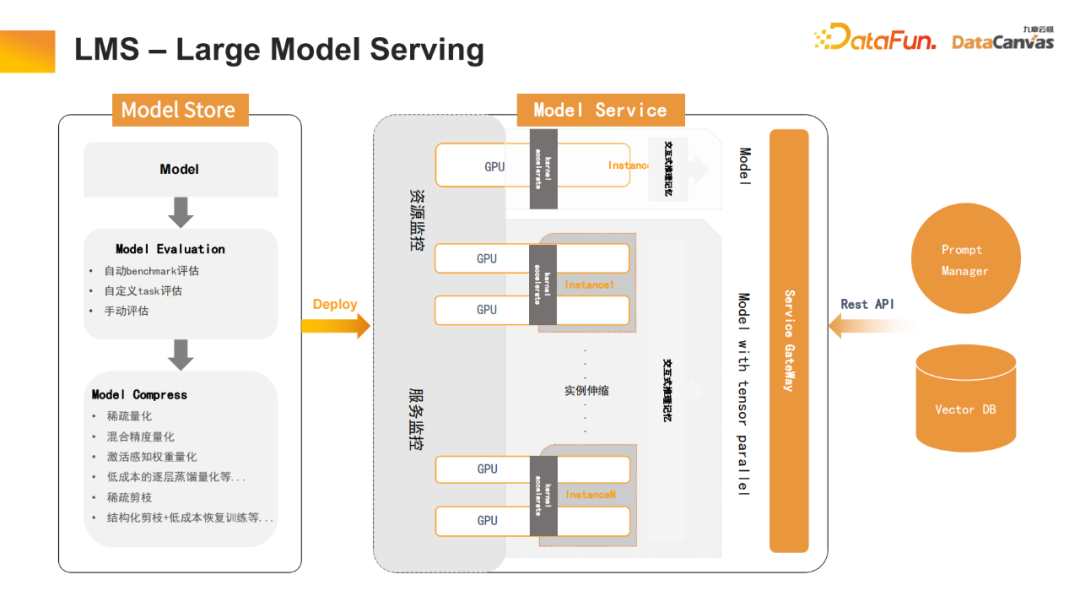
Le service de grands modèles est également un élément très important La plateforme a également apporté de nombreuses optimisations dans la quantification des modèles, la distillation des connaissances et d'autres aspects, ce qui réduit considérablement le temps de calcul et accélère le transformateur grâce à la distillation des connaissances couche par couche pour réduire sa quantité de calcul. Dans le même temps, de nombreux travaux d'élagage ont été effectués (y compris l'élagage structuré, l'élagage clairsemé, etc.), ce qui a considérablement amélioré la vitesse d'inférence des grands modèles.
De plus, le processus de dialogue interactif a également été optimisé. Par exemple, dans un transformateur de dialogue multi-tours, la clé et la valeur de chaque tenseur peuvent être mémorisées sans calculs répétés. Par conséquent, il peut être stocké dans Vector DB pour réaliser la fonction de mémoire de l'historique des conversations et améliorer l'expérience utilisateur pendant le processus d'interaction.
6. Prompt Manager
Prompt Manager, un outil de conception et de construction de mots d'invite de grands modèles, aide les utilisateurs à concevoir de meilleurs mots d'invite et guide les grands modèles pour générer un contenu de sortie plus précis, fiable et attendu. Cet outil peut non seulement fournir un mode de développement de boîte à outils de développement pour le personnel technique, mais également fournir un mode de fonctionnement d'interaction homme-machine pour le personnel non technique, répondant aux besoins de différents groupes de personnes pour l'utilisation de grands modèles.
Ses principales fonctions comprennent : la gestion de modèles d'IA, la gestion de scènes, la gestion de modèles de mots rapides, le développement de mots rapides et l'application de mots rapides, etc.

La plate-forme fournit des outils de gestion de mots d'invite couramment utilisés pour réaliser le contrôle de version, et fournit des modèles couramment utilisés pour accélérer la mise en œuvre des mots d'invite.
3. La pratique du grand modèle multimodal Jiuzhang Yunji DataCanvas
1. Grand modèle multimodal - avec mémoire
Après avoir présenté les fonctions de la plateforme, je partagerai ensuite le modèle multimodal. Pratiques de développement de grands modèles.
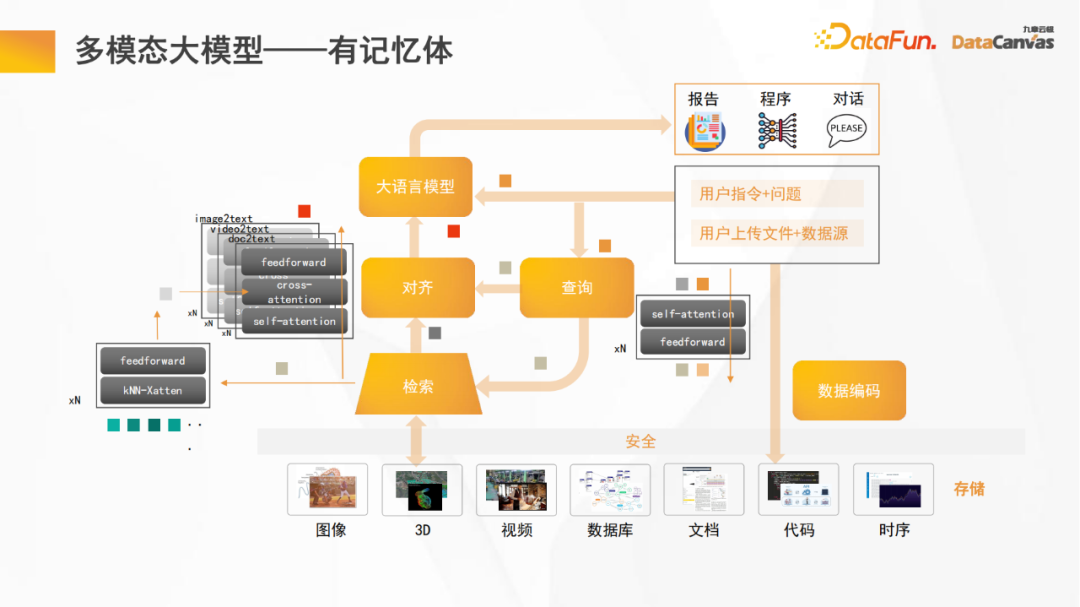
L'image ci-dessus est le cadre de base du grand modèle multimodal Jiuzhang Yunji DataCanvas. La différence par rapport aux autres grands modèles multimodaux est qu'elle contient de la mémoire, ce qui peut améliorer le grand modèle open source. Capacités de raisonnement.
Généralement, le nombre de paramètres des grands modèles open source est relativement faible. Si une partie des paramètres est utilisée pour la mémoire, sa capacité de raisonnement sera considérablement réduite. Si de la mémoire est ajoutée à un grand modèle open source, les capacités de raisonnement et de mémoire seront améliorées en même temps.
De plus, comme la plupart des modèles, le grand modèle multimodal corrigera également le grand modèle de langage et le codage des données fixe, et effectuera une formation modulaire séparée pour la fonction d'alignement, par conséquent, toutes les différentes modalités de données seront alignées sur ; le texte La partie logique ; dans le processus de raisonnement, la langue est d'abord traduite, puis fusionnée, et enfin le travail de raisonnement est effectué.
2. Pipeline ETL de données non structurées
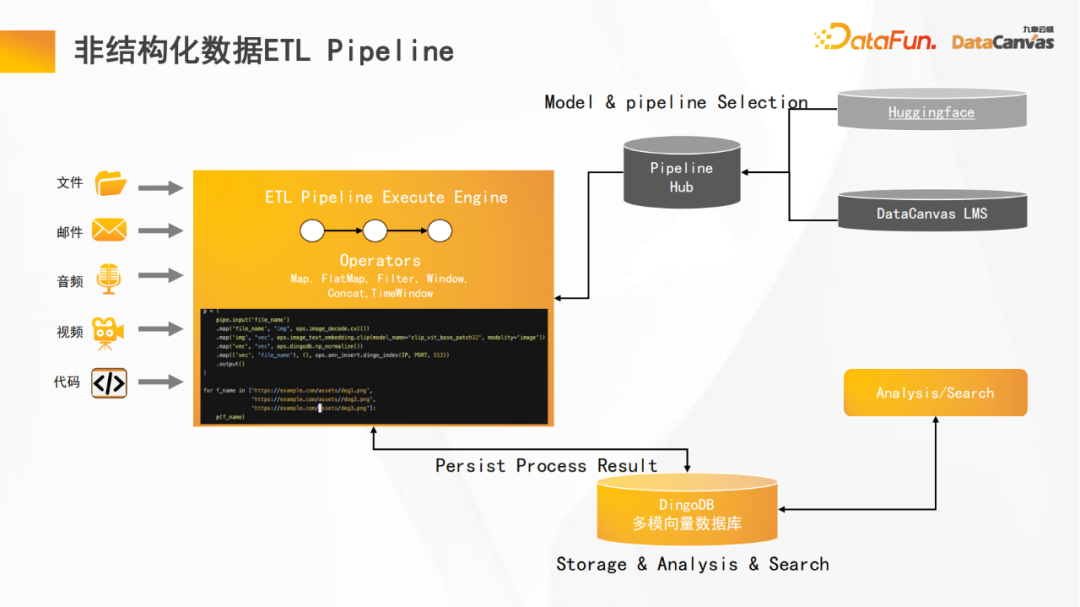
Parce que notre base de données vectorielle multimodale DingoDB combine des fonctions multimodales et ETL, elle peut fournir de bonnes capacités de gestion de données non structurées. La plate-forme fournit des fonctions ETL de pipeline et a effectué de nombreuses optimisations, notamment la compilation d'opérateurs, le traitement parallèle et l'optimisation du cache.
De plus, la plateforme fournit un Hub où les pipelines peuvent être réutilisés pour obtenir l'expérience de développement la plus efficace. Dans le même temps, il prend en charge de nombreux encodeurs sur Huggingface, qui peuvent réaliser un encodage optimal de différentes données modales.
3. Méthode de construction de grands modèles multimodaux
Jiuzhang Yunji DataCanvas utilise le grand modèle multimodal Yuanshi comme base pour aider les utilisateurs à choisir d'autres grands modèles open source et également à utiliser leur propre modal. données Organiser une formation.
La construction d'un grand modèle multimodal est grossièrement divisée en trois étapes :
- La première étape : un grand modèle de langage fixe et un alignement et une requête de formation de l'encodeur modal ; Facultatif, prend en charge la recherche multimodale) : Modèle de langage large fixe, encodeur modal, module d'alignement et de requête, module de récupération de formation
- La troisième étape (facultatif, pour des tâches spécifiques) : Instructions pour affiner le grand modèle de langage ; Modèle de langage.
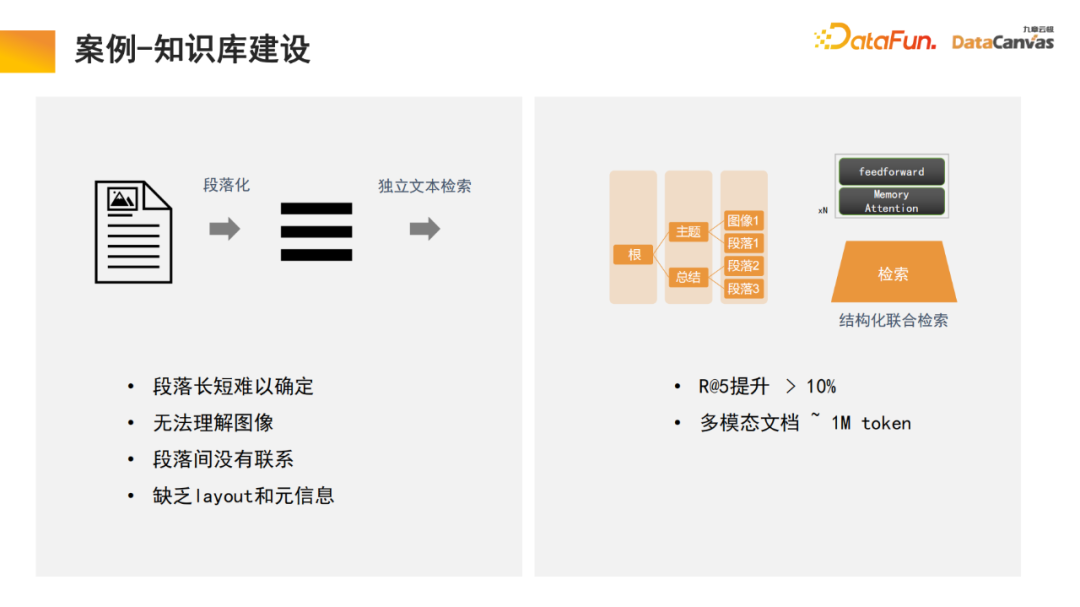
- 4. Cas - Construction d'une base de connaissances
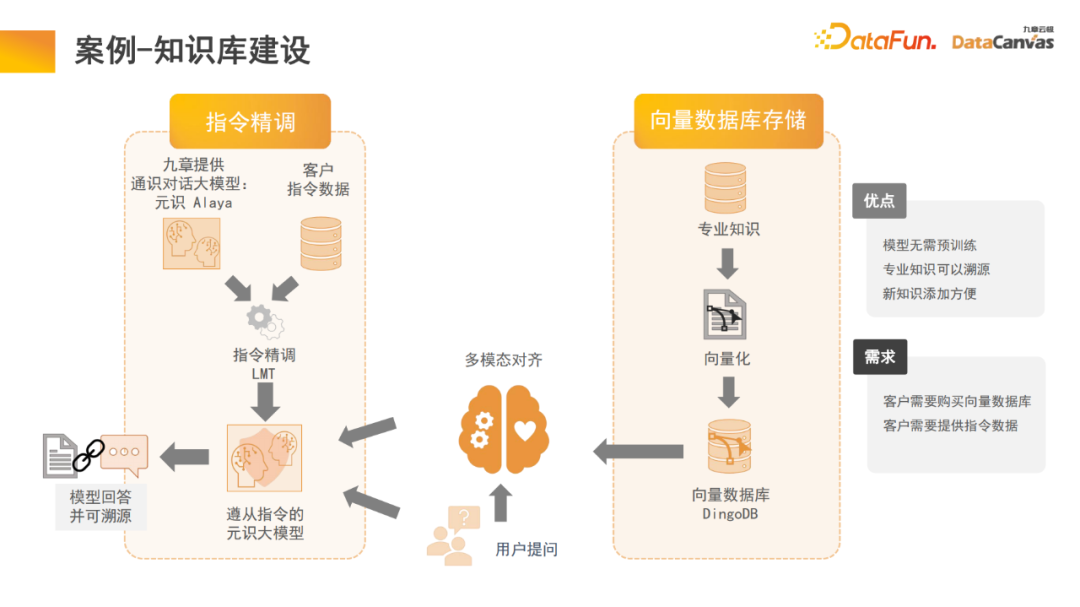 L'architecture de mémoire dans le grand modèle peut nous aider à réaliser la construction d'une base de connaissances multimodale, qui est en fait une application modèle. Zhihu est un module d'application de base de connaissances multimodale typique, et ses connaissances professionnelles peuvent être retracées.
L'architecture de mémoire dans le grand modèle peut nous aider à réaliser la construction d'une base de connaissances multimodale, qui est en fait une application modèle. Zhihu est un module d'application de base de connaissances multimodale typique, et ses connaissances professionnelles peuvent être retracées.
Plus précisément, les connaissances professionnelles sont utilisées pour faire différents choix de codage via l'encodeur, et en même temps, une évaluation unifiée est effectuée sur la base de différentes méthodes d'évaluation, et la sélection de l'encodeur est réalisée par une évaluation en un clic. Enfin, la vectorisation de l'encodeur est appliquée et stockée dans la base de données vectorielles multimodale DingoDB, puis les informations pertinentes sont extraites via le module multimodal du grand modèle et le raisonnement est effectué via le modèle de langage.
La dernière partie du modèle nécessite souvent un ajustement précis des instructions. Étant donné que les besoins des différents utilisateurs sont différents, l'ensemble du grand modèle multimodal doit être affiné. En raison des avantages particuliers des bases de connaissances multimodales dans l'organisation de l'information, le modèle a la capacité d'apprendre et de récupérer. C'est également une innovation que nous avons apportée au processus de rédaction de paragraphes de texte.
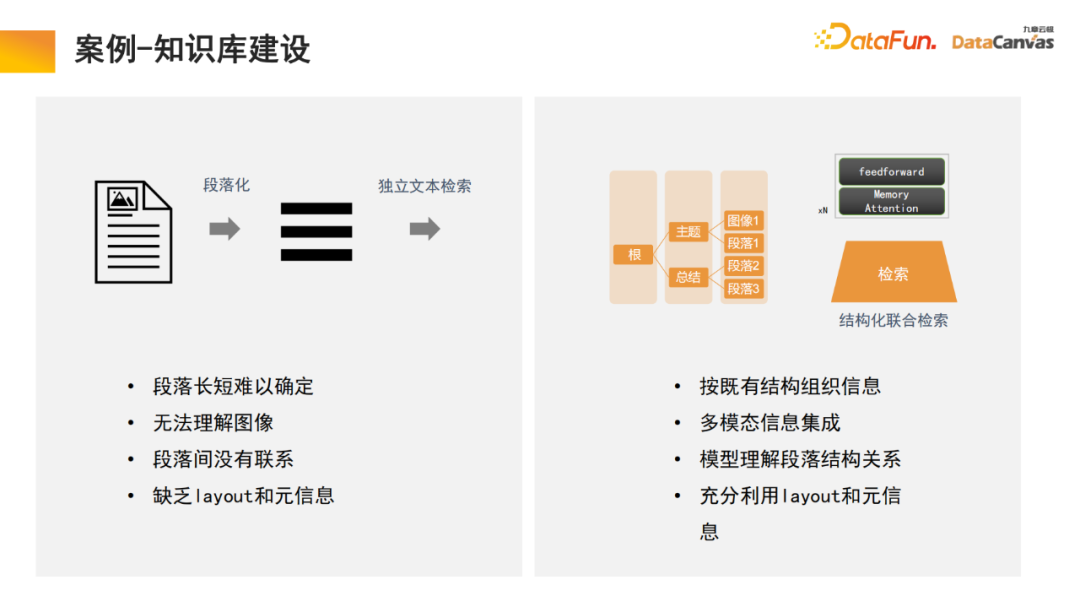
La base de connaissances générales consiste à diviser le document en paragraphes, puis à déverrouiller chaque paragraphe indépendamment. Cette méthode est facilement perturbée par le bruit et, pour de nombreux documents volumineux, il est difficile de déterminer la norme de division des paragraphes.
Dans notre modèle, le module de récupération effectue un apprentissage et le modèle trouve automatiquement l'organisation des informations structurées appropriée. Pour un produit spécifique, commencez par le manuel du produit, localisez d'abord le grand paragraphe du catalogue, puis localisez le paragraphe spécifique. Dans le même temps, comme il s'agit d'une intégration d'informations multimodale, en plus du texte, elle contient souvent également des images, des tableaux, etc., qui peuvent également être vectorisés et combinés avec des méta-informations pour réaliser une récupération conjointe, améliorant ainsi l'efficacité de la récupération. .
Il convient de mentionner que le module de récupération utilise un mécanisme d'attention mémoire, qui peut augmenter le taux de rappel de 10 % par rapport à des algorithmes similaires. En même temps, le mécanisme d'attention mémoire peut être utilisé pour le traitement de documents multimodaux ; , ce qui est également un aspect très avantageux de.
 4. Réflexions et perspectives d'avenir
4. Réflexions et perspectives d'avenir
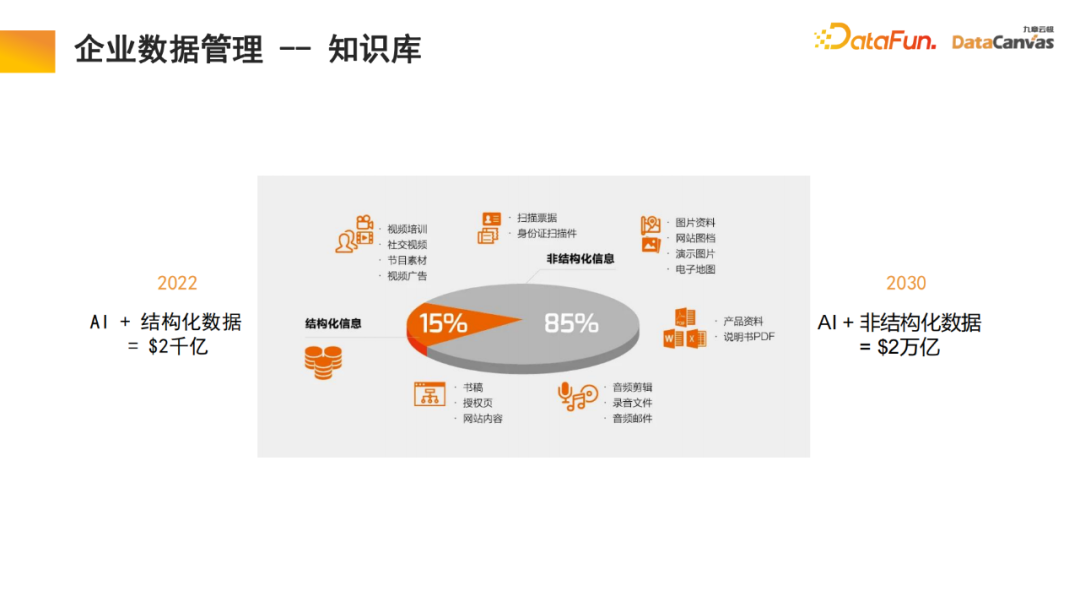
85% des données de l'entreprise sont des données non structurées. Seulement 15 % sont des données structurées. Au cours des 20 dernières années, l’intelligence artificielle s’est principalement concentrée sur les données structurées. Les données non structurées sont très difficiles à utiliser et nécessitent beaucoup d’énergie et de coûts pour les convertir en données structurées. Avec l'aide de grands modèles multimodaux et de bases de connaissances multimodales, et grâce au nouveau paradigme de l'intelligence artificielle, l'utilisation des données non structurées dans la gestion interne des entreprises peut être considérablement améliorée, ce qui pourrait multiplier par 10 valeur dans le futur.
La base de connaissances multimodale sert de base à l'agent, avec en plus l'agent R&D, l'agent du service client, l'agent commercial, l'agent juridique et les ressources humaines. tels que les agents de ressources et les agents d'exploitation et de maintenance d'entreprise peuvent tous être exploités via la base de connaissances.
Prenons l'exemple de l'agent commercial. Une architecture commune comprend deux agents existant en même temps, dont l'un est responsable de la prise de décision et l'autre est responsable de l'analyse de l'étape de vente. Les deux modules peuvent rechercher des informations pertinentes via des bases de connaissances multimodales, notamment des informations sur les produits, des statistiques de ventes historiques, des portraits de clients, des expériences de vente passées, etc. Ces informations sont intégrées pour aider ces deux agents à faire le travail le meilleur et le plus correct. Ces décisions dans à leur tour, ils aident les utilisateurs à obtenir les meilleures informations sur les ventes, qui sont ensuite enregistrées dans une base de données multimodale. Ce cycle continue d'améliorer les performances des ventes.
Nous pensons que les entreprises les plus précieuses de demain seront celles qui mettront l’intelligence en pratique. J'espère que Jiuzhang Yunji DataCanvas pourra vous accompagner jusqu'au bout et vous entraider.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 CLIP-BEVFormer : superviser explicitement la structure BEVFormer pour améliorer les performances de détection à longue traîne
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer : superviser explicitement la structure BEVFormer pour améliorer les performances de détection à longue traîne
Mar 26, 2024 pm 12:41 PM
Écrit ci-dessus et compréhension personnelle de l'auteur : À l'heure actuelle, dans l'ensemble du système de conduite autonome, le module de perception joue un rôle essentiel. Le véhicule autonome roulant sur la route ne peut obtenir des résultats de perception précis que via le module de perception en aval. dans le système de conduite autonome, prend des jugements et des décisions comportementales opportuns et corrects. Actuellement, les voitures dotées de fonctions de conduite autonome sont généralement équipées d'une variété de capteurs d'informations de données, notamment des capteurs de caméra à vision panoramique, des capteurs lidar et des capteurs radar à ondes millimétriques pour collecter des informations selon différentes modalités afin d'accomplir des tâches de perception précises. L'algorithme de perception BEV basé sur la vision pure est privilégié par l'industrie en raison de son faible coût matériel et de sa facilité de déploiement, et ses résultats peuvent être facilement appliqués à diverses tâches en aval.
 Implémentation d'algorithmes d'apprentissage automatique en C++ : défis et solutions courants
Jun 03, 2024 pm 01:25 PM
Implémentation d'algorithmes d'apprentissage automatique en C++ : défis et solutions courants
Jun 03, 2024 pm 01:25 PM
Les défis courants rencontrés par les algorithmes d'apprentissage automatique en C++ incluent la gestion de la mémoire, le multithread, l'optimisation des performances et la maintenabilité. Les solutions incluent l'utilisation de pointeurs intelligents, de bibliothèques de threads modernes, d'instructions SIMD et de bibliothèques tierces, ainsi que le respect des directives de style de codage et l'utilisation d'outils d'automatisation. Des cas pratiques montrent comment utiliser la bibliothèque Eigen pour implémenter des algorithmes de régression linéaire, gérer efficacement la mémoire et utiliser des opérations matricielles hautes performances.
 Explorez les principes sous-jacents et la sélection d'algorithmes de la fonction de tri C++
Apr 02, 2024 pm 05:36 PM
Explorez les principes sous-jacents et la sélection d'algorithmes de la fonction de tri C++
Apr 02, 2024 pm 05:36 PM
La couche inférieure de la fonction de tri C++ utilise le tri par fusion, sa complexité est O(nlogn) et propose différents choix d'algorithmes de tri, notamment le tri rapide, le tri par tas et le tri stable.
 L'intelligence artificielle peut-elle prédire la criminalité ? Explorez les capacités de CrimeGPT
Mar 22, 2024 pm 10:10 PM
L'intelligence artificielle peut-elle prédire la criminalité ? Explorez les capacités de CrimeGPT
Mar 22, 2024 pm 10:10 PM
La convergence de l’intelligence artificielle (IA) et des forces de l’ordre ouvre de nouvelles possibilités en matière de prévention et de détection de la criminalité. Les capacités prédictives de l’intelligence artificielle sont largement utilisées dans des systèmes tels que CrimeGPT (Crime Prediction Technology) pour prédire les activités criminelles. Cet article explore le potentiel de l’intelligence artificielle dans la prédiction de la criminalité, ses applications actuelles, les défis auxquels elle est confrontée et les éventuelles implications éthiques de cette technologie. Intelligence artificielle et prédiction de la criminalité : les bases CrimeGPT utilise des algorithmes d'apprentissage automatique pour analyser de grands ensembles de données, identifiant des modèles qui peuvent prédire où et quand les crimes sont susceptibles de se produire. Ces ensembles de données comprennent des statistiques historiques sur la criminalité, des informations démographiques, des indicateurs économiques, des tendances météorologiques, etc. En identifiant les tendances qui pourraient échapper aux analystes humains, l'intelligence artificielle peut donner du pouvoir aux forces de l'ordre.
 Algorithme de détection amélioré : pour la détection de cibles dans des images de télédétection optique haute résolution
Jun 06, 2024 pm 12:33 PM
Algorithme de détection amélioré : pour la détection de cibles dans des images de télédétection optique haute résolution
Jun 06, 2024 pm 12:33 PM
01Aperçu des perspectives Actuellement, il est difficile d'atteindre un équilibre approprié entre efficacité de détection et résultats de détection. Nous avons développé un algorithme YOLOv5 amélioré pour la détection de cibles dans des images de télédétection optique haute résolution, en utilisant des pyramides de caractéristiques multicouches, des stratégies de têtes de détection multiples et des modules d'attention hybrides pour améliorer l'effet du réseau de détection de cibles dans les images de télédétection optique. Selon l'ensemble de données SIMD, le mAP du nouvel algorithme est 2,2 % meilleur que YOLOv5 et 8,48 % meilleur que YOLOX, permettant ainsi d'obtenir un meilleur équilibre entre les résultats de détection et la vitesse. 02 Contexte et motivation Avec le développement rapide de la technologie de télédétection, les images de télédétection optique à haute résolution ont été utilisées pour décrire de nombreux objets à la surface de la Terre, notamment des avions, des voitures, des bâtiments, etc. Détection d'objets dans l'interprétation d'images de télédétection
 Application d'algorithmes dans la construction de 58 plateformes de portraits
May 09, 2024 am 09:01 AM
Application d'algorithmes dans la construction de 58 plateformes de portraits
May 09, 2024 am 09:01 AM
1. Contexte de la construction de la plateforme 58 Portraits Tout d'abord, je voudrais partager avec vous le contexte de la construction de la plateforme 58 Portraits. 1. La pensée traditionnelle de la plate-forme de profilage traditionnelle ne suffit plus. La création d'une plate-forme de profilage des utilisateurs s'appuie sur des capacités de modélisation d'entrepôt de données pour intégrer les données de plusieurs secteurs d'activité afin de créer des portraits d'utilisateurs précis. Elle nécessite également l'exploration de données pour comprendre le comportement et les intérêts des utilisateurs. et besoins, et fournir des capacités côté algorithmes ; enfin, il doit également disposer de capacités de plate-forme de données pour stocker, interroger et partager efficacement les données de profil utilisateur et fournir des services de profil. La principale différence entre une plate-forme de profilage d'entreprise auto-construite et une plate-forme de profilage de middle-office est que la plate-forme de profilage auto-construite dessert un seul secteur d'activité et peut être personnalisée à la demande. La plate-forme de mid-office dessert plusieurs secteurs d'activité et est complexe ; modélisation et offre des fonctionnalités plus générales. 2.58 Portraits d'utilisateurs de l'arrière-plan de la construction du portrait sur la plate-forme médiane 58
 Ajoutez SOTA en temps réel et montez en flèche ! FastOcc : un algorithme Occ plus rapide et convivial pour le déploiement est là !
Mar 14, 2024 pm 11:50 PM
Ajoutez SOTA en temps réel et montez en flèche ! FastOcc : un algorithme Occ plus rapide et convivial pour le déploiement est là !
Mar 14, 2024 pm 11:50 PM
Écrit ci-dessus & La compréhension personnelle de l'auteur est que dans le système de conduite autonome, la tâche de perception est un élément crucial de l'ensemble du système de conduite autonome. L'objectif principal de la tâche de perception est de permettre aux véhicules autonomes de comprendre et de percevoir les éléments environnementaux environnants, tels que les véhicules circulant sur la route, les piétons au bord de la route, les obstacles rencontrés lors de la conduite, les panneaux de signalisation sur la route, etc., aidant ainsi en aval modules Prendre des décisions et des actions correctes et raisonnables. Un véhicule doté de capacités de conduite autonome est généralement équipé de différents types de capteurs de collecte d'informations, tels que des capteurs de caméra à vision panoramique, des capteurs lidar, des capteurs radar à ondes millimétriques, etc., pour garantir que le véhicule autonome peut percevoir et comprendre avec précision l'environnement environnant. éléments , permettant aux véhicules autonomes de prendre les bonnes décisions pendant la conduite autonome. Tête
 Analyse d'algorithme PHP : méthode efficace pour trouver les nombres manquants dans un tableau
Mar 02, 2024 am 08:39 AM
Analyse d'algorithme PHP : méthode efficace pour trouver les nombres manquants dans un tableau
Mar 02, 2024 am 08:39 AM
Analyse d'algorithme PHP : Une méthode efficace pour trouver les nombres manquants dans un tableau. Dans le processus de développement d'applications PHP, nous rencontrons souvent des situations où nous devons trouver des nombres manquants dans un tableau. Cette situation est très courante dans le traitement des données et la conception d'algorithmes, nous devons donc maîtriser des algorithmes de recherche efficaces pour résoudre ce problème. Cet article présentera une méthode efficace pour trouver les nombres manquants dans un tableau et joindra des exemples de code PHP spécifiques. Description du problème Supposons que nous ayons un tableau contenant des nombres entiers compris entre 1 et 100, mais qu'il manque un nombre. Nous devons concevoir un
