
 Périphériques technologiques
IA
L'Université de Fudan et Huawei Noah proposent le cadre VidRD pour réaliser une génération vidéo itérative de haute qualité
Périphériques technologiques
IA
L'Université de Fudan et Huawei Noah proposent le cadre VidRD pour réaliser une génération vidéo itérative de haute qualité
L'Université de Fudan et Huawei Noah proposent le cadre VidRD pour réaliser une génération vidéo itérative de haute qualité

Des chercheurs de l'Université de Fudan et du laboratoire Noah's Ark de Huawei ont proposé une solution itérative pour générer des vidéos de haute qualité basée sur le modèle de diffusion d'images (LDM) - VidRD (Reuse and Diffuse). Cette solution vise à réaliser des percées dans la qualité et la longueur des séquences des vidéos générées, et à parvenir à une génération vidéo contrôlable de haute qualité de longues séquences. Il réduit efficacement le problème de gigue entre les images vidéo générées, a une grande valeur de recherche et pratique et contribue à la communauté AIGC actuelle.
Latent Diffusion Model (LDM) est un modèle génératif basé sur Denoising Autoencoder, qui peut générer des échantillons de haute qualité à partir de données initialisées de manière aléatoire en supprimant progressivement le bruit. Cependant, en raison des limitations de calcul et de mémoire lors de la formation et de l'inférence du modèle, un seul LDM ne peut généralement générer qu'un nombre très limité d'images vidéo. Bien que les travaux existants tentent d'utiliser un modèle de prédiction distinct pour générer davantage d'images vidéo, cela entraîne également des coûts de formation supplémentaires et produit une gigue au niveau des images.
Dans cet article, inspiré par le succès remarquable des modèles de diffusion latente (MLD) en synthèse d'images, un cadre appelé "Réutilisation et diffusion", ou VidRD en abrégé, est proposé. Ce cadre peut générer davantage d'images vidéo après le petit nombre d'images vidéo déjà générées par LDM, générant ainsi de manière itérative un contenu vidéo plus long, de meilleure qualité et diversifié. VidRD charge un modèle LDM d'image pré-entraîné pour une formation efficace et utilise un réseau U-Net avec des informations temporelles supplémentaires pour la suppression du bruit.

- Titre de l'article : Réutilisation et diffusion : débruitage itératif pour la génération de texte en vidéo
- Adresse de l'article : https://arxiv.org/abs/2309.03549
- Projet Page d'accueil : https://anonymous0x233.github.io/ReuseAndDiffuse/
Les principales contributions de cet article sont les suivantes :
- Afin de générer des vidéos plus fluides, cet article propose une méthode itérative basée sur la méthode de génération de « texte en vidéo » de modèle LDM sensible au timing. Cette méthode peut générer de manière itérative davantage d'images vidéo en réutilisant les caractéristiques de l'espace latent des images vidéo déjà générées et en suivant à chaque fois le processus de diffusion précédent.
- Cet article conçoit un ensemble de méthodes de traitement de données pour générer des ensembles de données « texte-vidéo » de haute qualité. Pour l'ensemble de données de reconnaissance d'action existant, cet article utilise un grand modèle de langage multimodal pour donner des descriptions textuelles aux vidéos. Pour les données d'image, cet article utilise des méthodes de mise à l'échelle et de traduction aléatoires pour générer davantage d'échantillons de formation vidéo.
- Sur l'ensemble de données UCF-101, cet article a vérifié les deux indicateurs d'évaluation FVD et IS ainsi que les résultats de visualisation. Les résultats quantitatifs et qualitatifs montrent que par rapport aux méthodes existantes, le modèle VidRD a obtenu de meilleurs résultats.
Introduction à la méthode
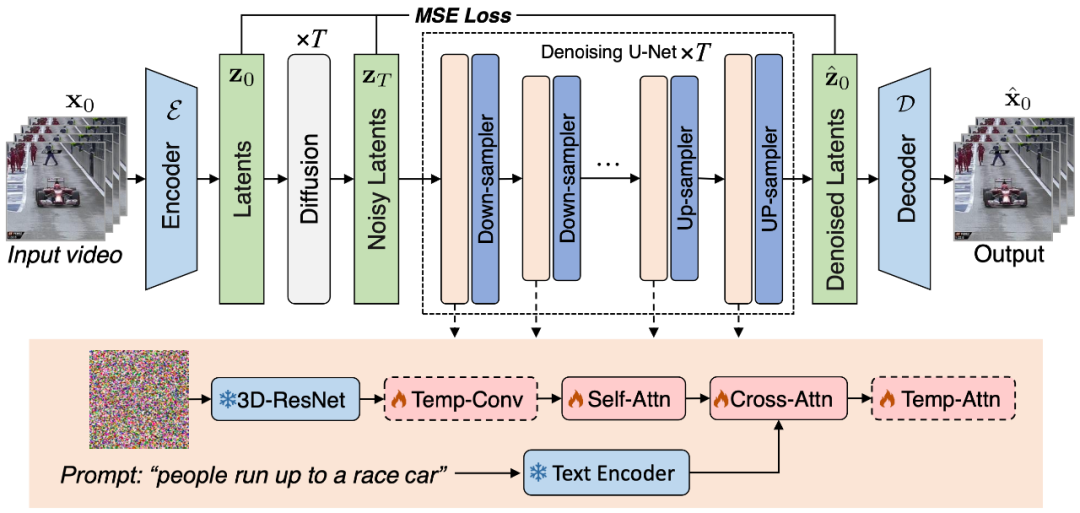
Figure 1. Diagramme schématique du cadre de génération vidéo VidRD proposé dans cet article
Cet article estime que l'utilisation d'images LDM pré-entraînées comme point de départ pour la formation LDM pour une synthèse vidéo de haute qualité, c'est un moyen efficace et choisissez judicieusement. Dans le même temps, ce point de vue est étayé par des travaux de recherche tels que [1, 2]. Dans ce contexte, le modèle soigneusement conçu dans cet article est construit sur la base du modèle de diffusion stable pré-entraîné, apprenant pleinement et héritant de ses excellentes caractéristiques. Ceux-ci incluent un auto-encodeur variationnel (VAE) pour une représentation latente précise et un puissant réseau de débruitage U-Net. La figure 1 montre l'architecture globale du modèle de manière claire et intuitive.
Dans la conception du modèle de cet article, une caractéristique notable est l'utilisation complète des poids de modèle pré-entraînés. Plus précisément, la plupart des couches réseau, y compris les composants de VAE et les couches de suréchantillonnage et de sous-échantillonnage d'U-Net, sont initialisées à l'aide de poids pré-entraînés du modèle de diffusion stable. Cette stratégie accélère non seulement considérablement le processus de formation du modèle, mais garantit également que le modèle présente une bonne stabilité et fiabilité dès le début. Notre modèle peut générer de manière itérative des images supplémentaires à partir d'un clip vidéo initial contenant un petit nombre d'images en réutilisant les caractéristiques latentes d'origine et en imitant le processus de diffusion précédent. De plus, pour l'auto-encodeur utilisé pour convertir entre l'espace de pixels et l'espace latent, nous injectons des couches de réseau liées au timing dans son décodeur et affinons ces couches pour améliorer la cohérence temporelle.
Afin d'assurer la continuité entre les images vidéo, cet article ajoute les couches 3D Temp-conv et Temp-attn au modèle. La couche Temp-conv suit le 3D ResNet, qui implémente des opérations de convolution 3D pour capturer les corrélations spatiales et temporelles afin de comprendre la dynamique et la continuité de l'agrégation de séquences vidéo. La structure Temp-Attn est similaire à Self-attention et est utilisée pour analyser et comprendre la relation entre les images de la séquence vidéo, permettant au modèle de synchroniser avec précision les informations en cours d'exécution entre les images. Ces paramètres sont initialisés de manière aléatoire pendant la formation et sont conçus pour fournir au modèle une compréhension et un codage de la structure temporelle. De plus, afin de s'adapter à la structure du modèle, la saisie des données a également été adaptée et ajustée en conséquence.
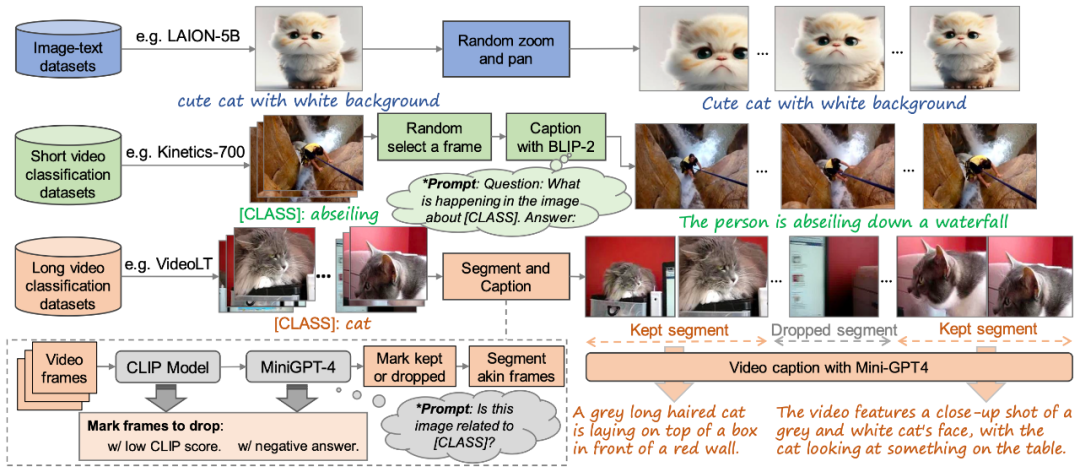
Figure 2. La méthode de construction de l'ensemble de données d'entraînement "texte-vidéo" de haute qualité proposée dans cet article
Afin d'entraîner le modèle VidRD, cet article propose une méthode pour construire un grand- Ensemble de données de formation à l'échelle « texte-vidéo » La méthode, comme le montre la figure 2, peut gérer des données « texte-image » et des données « texte-vidéo » sans description. De plus, afin d'obtenir une génération vidéo de haute qualité, cet article tente également de supprimer les filigranes sur les données d'entraînement.
Bien que les ensembles de données de description vidéo de haute qualité soient relativement rares sur le marché actuel, il existe un grand nombre d'ensembles de données de classification vidéo. Ces ensembles de données ont un contenu vidéo riche et chaque vidéo est accompagnée d'une étiquette de classification. Par exemple, Moments-In-Time, Kinetics-700 et VideoLT sont trois ensembles de données représentatifs de classification vidéo à grande échelle. Kinetics-700 couvre 700 catégories d'actions humaines et contient plus de 600 000 clips vidéo. Moments-In-Time comprend 339 catégories d'action, avec un total de plus d'un million de clips vidéo. VideoLT, quant à lui, contient 1 004 catégories et 250 000 vidéos longues non éditées.
Afin d'utiliser pleinement les données vidéo existantes, cet article tente d'annoter automatiquement ces vidéos plus en détail. Cet article utilise de grands modèles de langage multimodaux tels que BLIP-2 et MiniGPT4. En ciblant les images clés de la vidéo et en combinant leurs étiquettes de classification d'origine, cet article conçoit de nombreuses invites pour générer des annotations via un modèle de questions et réponses. Cette méthode améliore non seulement les informations vocales des données vidéo, mais apporte également des descriptions vidéo plus complètes et détaillées aux vidéos existantes qui n'ont pas de descriptions détaillées, permettant ainsi une génération de balises vidéo plus riches pour aider le modèle VidRD à apporter un meilleur effet de formation.
De plus, pour les données d'image très riches existantes, cet article a également conçu une méthode détaillée pour convertir les données d'image au format vidéo pour la formation. L'opération spécifique consiste à effectuer un panoramique et un zoom sur différentes positions de l'image à différentes vitesses, donnant ainsi à chaque image une forme de présentation dynamique unique et simulant l'effet du déplacement d'une caméra pour capturer des objets fixes dans la vie réelle. Grâce à cette méthode, les données d'images existantes peuvent être utilisées efficacement pour la formation vidéo.
Affichage de l'effet
Les textes de description sont : "Timelapse sur un pays enneigé avec une aurore dans le ciel.", "Une bougie brûle.", "Une tornade épique attaquant au-dessus d'une ville lumineuse la nuit." , et "Vue aérienne d'une plage de sable blanc au bord d'une mer magnifique." D’autres visualisations peuvent être trouvées sur la page d’accueil du projet.

Figure 3. Comparaison visuelle de l'effet de génération avec les méthodes existantes
Enfin, comme le montre la figure 3, les résultats de génération de cet article sont comparés aux méthodes existantes Make-A-Video [3 ] et La comparaison visuelle d'Imagen Video [4] montre l'effet de génération de meilleure qualité du modèle dans cet article.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Utilisez ddrescue pour récupérer des données sous Linux
Mar 20, 2024 pm 01:37 PM
Utilisez ddrescue pour récupérer des données sous Linux
Mar 20, 2024 pm 01:37 PM
DDREASE est un outil permettant de récupérer des données à partir de périphériques de fichiers ou de blocs tels que des disques durs, des SSD, des disques RAM, des CD, des DVD et des périphériques de stockage USB. Il copie les données d'un périphérique bloc à un autre, laissant derrière lui les blocs corrompus et ne déplaçant que les bons blocs. ddreasue est un puissant outil de récupération entièrement automatisé car il ne nécessite aucune interruption pendant les opérations de récupération. De plus, grâce au fichier map ddasue, il peut être arrêté et repris à tout moment. Les autres fonctionnalités clés de DDREASE sont les suivantes : Il n'écrase pas les données récupérées mais comble les lacunes en cas de récupération itérative. Cependant, il peut être tronqué si l'outil est invité à le faire explicitement. Récupérer les données de plusieurs fichiers ou blocs en un seul
 Open source! Au-delà de ZoeDepth ! DepthFM : estimation rapide et précise de la profondeur monoculaire !
Apr 03, 2024 pm 12:04 PM
Open source! Au-delà de ZoeDepth ! DepthFM : estimation rapide et précise de la profondeur monoculaire !
Apr 03, 2024 pm 12:04 PM
0. À quoi sert cet article ? Nous proposons DepthFM : un modèle d'estimation de profondeur monoculaire génératif de pointe, polyvalent et rapide. En plus des tâches traditionnelles d'estimation de la profondeur, DepthFM démontre également des capacités de pointe dans les tâches en aval telles que l'inpainting en profondeur. DepthFM est efficace et peut synthétiser des cartes de profondeur en quelques étapes d'inférence. Lisons ce travail ensemble ~ 1. Titre des informations sur l'article : DepthFM : FastMonocularDepthEstimationwithFlowMatching Auteur : MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas entre officiellement dans l’ère des robots électriques ! Hier, l'Atlas hydraulique s'est retiré "en larmes" de la scène de l'histoire. Aujourd'hui, Boston Dynamics a annoncé que l'Atlas électrique était au travail. Il semble que dans le domaine des robots humanoïdes commerciaux, Boston Dynamics soit déterminé à concurrencer Tesla. Après la sortie de la nouvelle vidéo, elle a déjà été visionnée par plus d’un million de personnes en seulement dix heures. Les personnes âgées partent et de nouveaux rôles apparaissent. C'est une nécessité historique. Il ne fait aucun doute que cette année est l’année explosive des robots humanoïdes. Les internautes ont commenté : Les progrès des robots ont fait ressembler la cérémonie d'ouverture de cette année à des êtres humains, et le degré de liberté est bien plus grand que celui des humains. Mais n'est-ce vraiment pas un film d'horreur ? Au début de la vidéo, Atlas est allongé calmement sur le sol, apparemment sur le dos. Ce qui suit est à couper le souffle
 Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Les performances de JAX, promu par Google, ont dépassé celles de Pytorch et TensorFlow lors de récents tests de référence, se classant au premier rang sur 7 indicateurs. Et le test n’a pas été fait sur le TPU présentant les meilleures performances JAX. Bien que parmi les développeurs, Pytorch soit toujours plus populaire que Tensorflow. Mais à l’avenir, des modèles plus volumineux seront peut-être formés et exécutés sur la base de la plate-forme JAX. Modèles Récemment, l'équipe Keras a comparé trois backends (TensorFlow, JAX, PyTorch) avec l'implémentation native de PyTorch et Keras2 avec TensorFlow. Premièrement, ils sélectionnent un ensemble de
 La vitalité de la super intelligence s'éveille ! Mais avec l'arrivée de l'IA qui se met à jour automatiquement, les mères n'ont plus à se soucier des goulots d'étranglement des données.
Apr 29, 2024 pm 06:55 PM
La vitalité de la super intelligence s'éveille ! Mais avec l'arrivée de l'IA qui se met à jour automatiquement, les mères n'ont plus à se soucier des goulots d'étranglement des données.
Apr 29, 2024 pm 06:55 PM
Je pleure à mort. Le monde construit à la folie de grands modèles. Les données sur Internet ne suffisent pas du tout. Le modèle de formation ressemble à « The Hunger Games », et les chercheurs en IA du monde entier se demandent comment nourrir ces personnes avides de données. Ce problème est particulièrement important dans les tâches multimodales. À une époque où rien ne pouvait être fait, une équipe de start-up du département de l'Université Renmin de Chine a utilisé son propre nouveau modèle pour devenir la première en Chine à faire de « l'auto-alimentation des données générées par le modèle » une réalité. De plus, il s’agit d’une approche à deux volets, du côté compréhension et du côté génération, les deux côtés peuvent générer de nouvelles données multimodales de haute qualité et fournir un retour de données au modèle lui-même. Qu'est-ce qu'un modèle ? Awaker 1.0, un grand modèle multimodal qui vient d'apparaître sur le Forum Zhongguancun. Qui est l'équipe ? Moteur Sophon. Fondé par Gao Yizhao, doctorant à la Hillhouse School of Artificial Intelligence de l’Université Renmin.
 Vitesse Internet lente des données cellulaires sur iPhone : correctifs
May 03, 2024 pm 09:01 PM
Vitesse Internet lente des données cellulaires sur iPhone : correctifs
May 03, 2024 pm 09:01 PM
Vous êtes confronté à un décalage et à une connexion de données mobile lente sur iPhone ? En règle générale, la puissance de l'Internet cellulaire sur votre téléphone dépend de plusieurs facteurs tels que la région, le type de réseau cellulaire, le type d'itinérance, etc. Vous pouvez prendre certaines mesures pour obtenir une connexion Internet cellulaire plus rapide et plus fiable. Correctif 1 – Forcer le redémarrage de l'iPhone Parfois, le redémarrage forcé de votre appareil réinitialise simplement beaucoup de choses, y compris la connexion cellulaire. Étape 1 – Appuyez simplement une fois sur la touche d’augmentation du volume et relâchez-la. Ensuite, appuyez sur la touche de réduction du volume et relâchez-la à nouveau. Étape 2 – La partie suivante du processus consiste à maintenir le bouton sur le côté droit. Laissez l'iPhone finir de redémarrer. Activez les données cellulaires et vérifiez la vitesse du réseau. Vérifiez à nouveau Correctif 2 – Changer le mode de données Bien que la 5G offre de meilleures vitesses de réseau, elle fonctionne mieux lorsque le signal est plus faible
 La version Kuaishou de Sora 'Ke Ling' est ouverte aux tests : génère plus de 120 s de vidéo, comprend mieux la physique et peut modéliser avec précision des mouvements complexes
Jun 11, 2024 am 09:51 AM
La version Kuaishou de Sora 'Ke Ling' est ouverte aux tests : génère plus de 120 s de vidéo, comprend mieux la physique et peut modéliser avec précision des mouvements complexes
Jun 11, 2024 am 09:51 AM
Quoi? Zootopie est-elle concrétisée par l’IA domestique ? Avec la vidéo est exposé un nouveau modèle de génération vidéo domestique à grande échelle appelé « Keling ». Sora utilise une voie technique similaire et combine un certain nombre d'innovations technologiques auto-développées pour produire des vidéos qui comportent non seulement des mouvements larges et raisonnables, mais qui simulent également les caractéristiques du monde physique et possèdent de fortes capacités de combinaison conceptuelle et d'imagination. Selon les données, Keling prend en charge la génération de vidéos ultra-longues allant jusqu'à 2 minutes à 30 ips, avec des résolutions allant jusqu'à 1080p, et prend en charge plusieurs formats d'image. Un autre point important est que Keling n'est pas une démo ou une démonstration de résultats vidéo publiée par le laboratoire, mais une application au niveau produit lancée par Kuaishou, un acteur leader dans le domaine de la vidéo courte. De plus, l'objectif principal est d'être pragmatique, de ne pas faire de chèques en blanc et de se mettre en ligne dès sa sortie. Le grand modèle de Ke Ling est déjà sorti à Kuaiying.
 L'US Air Force présente son premier avion de combat IA de grande envergure ! Le ministre a personnellement effectué l'essai routier sans intervenir pendant tout le processus, et 100 000 lignes de code ont été testées 21 fois.
May 07, 2024 pm 05:00 PM
L'US Air Force présente son premier avion de combat IA de grande envergure ! Le ministre a personnellement effectué l'essai routier sans intervenir pendant tout le processus, et 100 000 lignes de code ont été testées 21 fois.
May 07, 2024 pm 05:00 PM
Récemment, le milieu militaire a été submergé par la nouvelle : les avions de combat militaires américains peuvent désormais mener des combats aériens entièrement automatiques grâce à l'IA. Oui, tout récemment, l’avion de combat IA de l’armée américaine a été rendu public pour la première fois, dévoilant ainsi son mystère. Le nom complet de ce chasseur est Variable Stability Simulator Test Aircraft (VISTA). Il a été personnellement piloté par le secrétaire de l'US Air Force pour simuler une bataille aérienne en tête-à-tête. Le 2 mai, le secrétaire de l'US Air Force, Frank Kendall, a décollé à bord d'un X-62AVISTA à la base aérienne d'Edwards. Notez que pendant le vol d'une heure, toutes les actions de vol ont été effectuées de manière autonome par l'IA ! Kendall a déclaré : "Au cours des dernières décennies, nous avons réfléchi au potentiel illimité du combat air-air autonome, mais cela a toujours semblé hors de portée." Mais maintenant,
