
 Périphériques technologiques
IA
Avec GPT-4, le robot a appris à faire tourner des stylos et à plaquer des noix.
Périphériques technologiques
IA
Avec GPT-4, le robot a appris à faire tourner des stylos et à plaquer des noix.
Avec GPT-4, le robot a appris à faire tourner des stylos et à plaquer des noix.

En termes d'apprentissage, GPT-4 est un excellent élève. Après avoir digéré une grande quantité de données humaines, il a maîtrisé diverses connaissances et peut même inspirer le mathématicien Terence Tao lors de discussions.
En même temps, il est également devenu un excellent professeur, enseignant non seulement la connaissance des livres, mais aussi apprenant au robot à tourner les stylos.

Le robot s'appelle Eureka et est le résultat de recherches menées par NVIDIA, l'Université de Pennsylvanie, le California Institute of Technology et l'Université du Texas à Austin. Cette recherche combine recherche sur de grands modèles de langage et apprentissage par renforcement : GPT-4 est utilisé pour affiner la fonction de récompense, et l'apprentissage par renforcement est utilisé pour former les contrôleurs de robots.
Avec la capacité d'écrire du code en GPT-4, Eureka possède d'excellentes capacités de conception de fonctions de récompense. Ses récompenses générées indépendamment sont meilleures que celles des experts humains dans 83 % des tâches. Cette capacité permet aux robots d'accomplir de nombreuses tâches qui n'étaient pas faciles à accomplir auparavant, telles que tourner des stylos, ouvrir des tiroirs et des armoires, lancer et attraper des balles, dribbler et utiliser des ciseaux. Cependant, tout cela se fait pour le moment dans un environnement virtuel.



De plus, Eureka met en œuvre un nouveau type de RLHF en contexte qui est capable d'incorporer les commentaires en langage naturel des opérateurs humains pour guider et aligner les fonctions de récompense. Il peut fournir de puissantes fonctions auxiliaires aux ingénieurs robotiques et les aider à concevoir des comportements de mouvement complexes. Jim Fan, scientifique principal en IA chez Nvidia et l'un des auteurs de l'article, a comparé cette recherche à "Voyager (la sonde spatiale de la galaxie extérieure développée et construite par les États-Unis) dans l'espace API d'un simulateur physique".

Il est à noter que cette recherche est entièrement open source, l'adresse open source est la suivante :

- Lien papier : https://arxiv.org/pdf/2310.12931 .pdf
- Lien du projet : https://eureka-research.github.io/
- Lien du code : https://github.com/eureka-research/Eureka
Présentation de l'article
Les grands modèles de langage (LLM) excellent dans la planification sémantique de haut niveau pour les tâches robotiques (par exemple le robot SayCan, RT-2 de Google), mais peuvent-ils être utilisés pour apprendre des tâches complexes de manipulation de bas niveau, telles que tourner la plume, c'est toujours une question ouverte. Les tentatives existantes nécessitent une expertise approfondie du domaine pour créer des invites de tâches ou acquérir uniquement des compétences simples, ce qui est bien loin de la flexibilité au niveau humain.

Le robot RT-2 de Google.
D’un autre côté, l’apprentissage par renforcement (RL) a obtenu des résultats impressionnants en termes de flexibilité et de nombreux autres aspects (comme la main du robot jouant au Rubik’s Cube d’OpenAI), mais nécessite que les concepteurs humains construisent soigneusement la fonction de récompense avec précision. Codifie et fournit signaux d’apprentissage pour le comportement souhaité. Étant donné que de nombreuses tâches d’apprentissage par renforcement du monde réel ne fournissent que des récompenses rares et difficiles à utiliser pour l’apprentissage, la mise en forme des récompenses est nécessaire dans la pratique pour fournir des signaux d’apprentissage progressifs. Malgré son importance, la fonction de récompense est notoirement difficile à concevoir. Une enquête récente a révélé que 92 % des chercheurs et praticiens de l'apprentissage par renforcement interrogés ont déclaré qu'ils effectuaient des essais et des erreurs manuels lors de la conception des récompenses, et 89 % ont déclaré que les récompenses qu'ils avaient conçues étaient sous-optimales et entraînaient des conséquences inattendues.
Étant donné que la conception des récompenses est si importante, nous ne pouvons nous empêcher de nous demander : est-il possible de développer un algorithme général de programmation de récompenses en utilisant un codage LLM de pointe (tel que GPT-4) ? Ces LLM ont d'excellentes performances en matière d'écriture de code, de génération zéro et d'apprentissage en contexte, et ont considérablement amélioré les performances des agents de programmation. Idéalement, de tels algorithmes de conception de récompenses devraient avoir des capacités de génération de récompenses au niveau humain, être évolutifs pour un large éventail de tâches, automatiser le processus fastidieux d'essais et d'erreurs sans supervision humaine, tout en étant compatibles avec la supervision humaine pour garantir la sécurité et la cohérence. .
Cet article propose un algorithme de conception de récompense EUREKA (le nom complet est Evolution-driven Universal REward Kit for Agent) piloté par LLM. L'algorithme a atteint les réalisations suivantes :
1. Les performances de conception des récompenses ont atteint le niveau humain dans 29 environnements RL open source différents, dont 10 formes de robots différentes (robots quadrupèdes, robots quadricoptères, robots bipèdes, manipulateurs et plusieurs mains adroites, voir Figure 1. Sans invites ni modèles de récompense spécifiques à une tâche, les récompenses générées de manière autonome par EUREKA ont surpassé les récompenses des experts humains dans 83 % des tâches et ont atteint une amélioration normalisée moyenne de 52 %

2. les tâches d'opération adroites qui étaient auparavant impossibles à réaliser grâce à l'ingénierie de récompense manuelle. Prenons l'exemple du problème de rotation du stylo. Dans ce cas, une main avec cinq doigts doit faire pivoter rapidement le stylo selon la configuration de rotation prédéfinie. autant de cycles que possible. En combinant EUREKA avec l'apprentissage de cours, les chercheurs ont démontré pour la première fois le fonctionnement de la rotation rapide du stylo sur la « Main de l'Ombre » anthropomorphe (Voir le bas de la figure 1
3). Fournit une nouvelle méthode d'apprentissage contextuel sans gradient pour l'apprentissage par renforcement basé sur la rétroaction humaine (RLHF), qui peut générer des images plus efficaces et alignées sur l'humain sur la base de diverses formes d'entrée humaine. L'article montre qu'EUREKA. peuvent bénéficier et améliorer les fonctions de récompense humaines existantes. De même, les chercheurs démontrent également la capacité d'EUREKA à utiliser la rétroaction textuelle humaine pour aider à la conception de fonctions de récompense. , EUREKA n'a pas d'invites de tâches spécifiques, de modèles de récompense et un petit nombre d'exemples. Dans l'expérience, EUREKA a obtenu des résultats nettement meilleurs que L2R. Bénéficiant de sa capacité à générer et à affiner des programmes de récompense expressifs de forme libre,
EUREKA. la polyvalence bénéficie de trois choix clés de conception d'algorithme : l'environnement comme contexte, la recherche évolutive et la réflexion sur les récompenses.
Premièrement, EUREKA peut générer une fonction de récompense exécutable à partir de zéro échantillon dans le LLM de codage du squelette (GPT-4). code source de l'environnement comme contexte. Ensuite, EUREKA propose de manière itérative un lot de candidats à la récompense en effectuant une recherche évolutive, et affine les récompenses les plus prometteuses dans la fenêtre de contexte LLM, améliorant ainsi considérablement la qualité des récompenses. la réflexion sur les récompenses, qui est un résumé textuel de la qualité des récompenses basé sur les statistiques de formation aux politiques, est possible. processus d'optimisation. Pour garantir qu'EUREKA puisse étendre sa recherche de récompenses à son potentiel maximum, EUREKA est implémenté dans IsaacGym. L'apprentissage par renforcement distribué accéléré par GPU est utilisé pour évaluer les récompenses intermédiaires, ce qui permet d'améliorer jusqu'à trois ordres de grandeur la vitesse d'apprentissage des politiques. faisant d'EUREKA un algorithme large qui évolue naturellement à mesure que la quantité de calcul augmente.
Comme le montre la figure 2. Les chercheurs se sont engagés à rendre open source toutes les invites, environnements et fonctions de récompense générées pour faciliter la poursuite des recherches sur la conception des récompenses basées sur le LLM.

Introduction à la méthode
 EUREKA peut écrire indépendamment l'algorithme de récompense. Voyons comment l'implémenter.
EUREKA peut écrire indépendamment l'algorithme de récompense. Voyons comment l'implémenter.
EUREKA se compose de trois composants algorithmiques : 1) l'environnement comme contexte, prenant ainsi en charge la génération zéro de récompenses exécutables ; 2) la recherche évolutive, proposant et améliorant de manière itérative les candidats aux récompenses 3) la réflexion sur les récompenses, prenant en charge des améliorations fines des récompenses ; .
L'environnement comme contexte
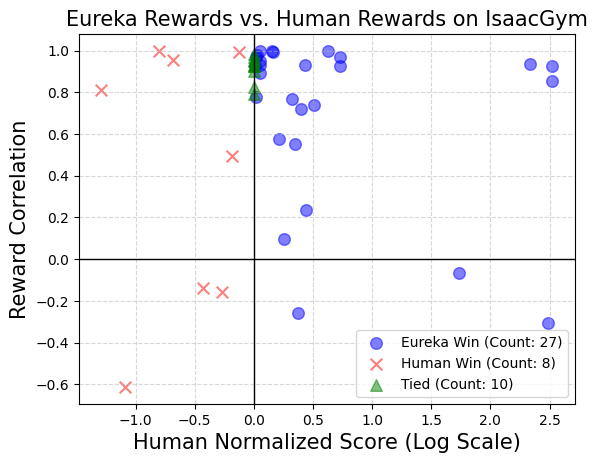
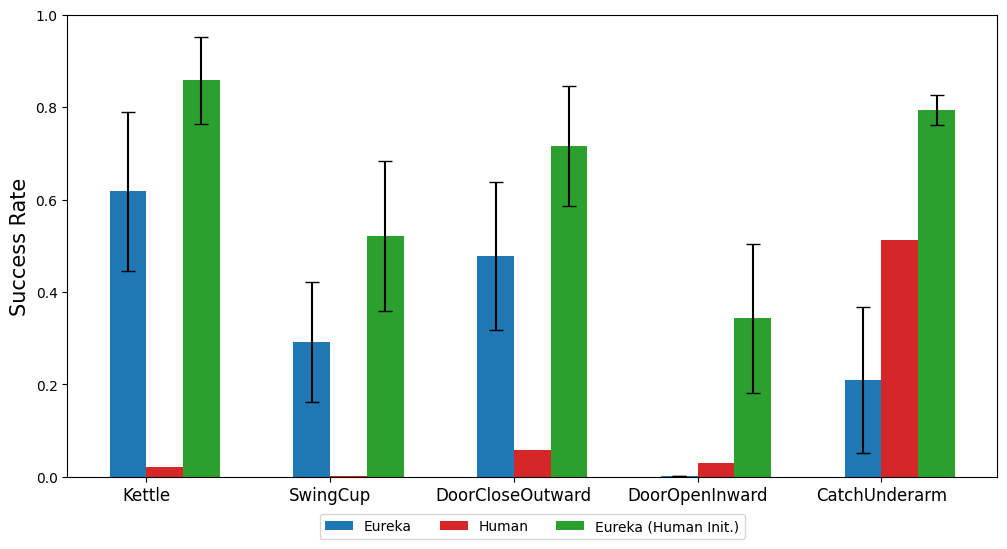
Cet article recommande de fournir directement le code de l'environnement d'origine comme contexte. Avec seulement un minimum d'instructions, EUREKA peut générer des récompenses dans différents environnements avec zéro échantillon. Un exemple de sortie EUREKA est présenté à la figure 3. EUREKA combine de manière experte les variables d'observation existantes (par exemple, la position du bout du doigt) dans le code d'environnement fourni et produit un code de récompense valide - le tout sans aucune ingénierie d'indices ou modèle de récompense spécifique à l'environnement. Cependant, la récompense générée peut ne pas toujours être exécutable du premier coup, et même si elle est exécutable, elle peut être sous-optimale. Cela soulève une question : comment surmonter efficacement le caractère sous-optimal de la génération de récompenses à partir d’un seul échantillon ? Recherche évolutive Ensuite, l'article présente comment la recherche évolutive peut résoudre les problèmes de solutions sous-optimales mentionnés ci-dessus. Ils sont affinés de telle manière qu'à chaque itération, EUREKA échantillonne plusieurs sorties indépendantes du LLM (ligne 5 de l'algorithme 1). Étant donné que chaque itération (générations) est distribuée indépendamment et de manière identique, à mesure que le nombre d'échantillons augmente, la probabilité d'erreurs dans toutes les fonctions de récompense au cours de l'itération diminue de façon exponentielle. Réflexion sur les récompenses Pour fournir une analyse des récompenses plus complexe et ciblée, cet article propose de créer un feedback automatisé pour résumer la dynamique de formation aux politiques dans le texte. Plus précisément, étant donné que la fonction de récompense EUREKA nécessite des composants individuels dans le programme de récompense (tels que les composants de récompense de la figure 3), nous suivons les valeurs scalaires de tous les composants de récompense à des points de contrôle politiques intermédiaires tout au long du processus de formation. Bien qu'il soit très simple de construire ce type de processus de réflexion sur les récompenses, en raison des dépendances de l'algorithme d'optimisation des récompenses, cette façon de le construire est très importante. Autrement dit, l'efficacité de la fonction de récompense est affectée par le choix spécifique de l'algorithme RL, et la même récompense peut se comporter très différemment même sous le même optimiseur, en fonction des différences d'hyperparamètres. En détaillant comment les algorithmes RL optimisent les composants de récompense individuels, la réflexion sur les récompenses permet à EUREKA de produire des modifications de récompense plus ciblées et de synthétiser des fonctions de récompense qui fonctionnent mieux en synergie avec les algorithmes RL fixes. La partie expérimentale effectue une évaluation complète d'Eureka, y compris sa capacité à générer des fonctions de récompense, sa capacité à résoudre de nouvelles tâches et sa capacité à intégrer diverses entrées humaines. L'environnement expérimental comprend 10 robots différents et 29 tâches, parmi lesquelles ces 29 tâches sont implémentées par le simulateur IsaacGym. Les expériences ont été menées en utilisant 9 environnements originaux d'IsaacGym (Isaac), couvrant une variété de morphologies de robots : quadrupèdes, bipèdes, quadricoptères, manipulateurs et mains adroites de robots. En plus de cela, le document garantit la profondeur de l'évaluation en incluant 20 tâches du référentiel de dextérité. Eureka peut générer des fonctions de récompense de niveau surhumain. Sur 29 tâches, la fonction de récompense donnée par Eureka a obtenu de meilleurs résultats que la récompense écrite par les experts sur 83 % des tâches, avec une amélioration moyenne de 52 %. En particulier, Eureka réalise des gains plus importants dans l’environnement de référence de haute dimension de la dextérité. Eureka est capable de faire évoluer les recherches de récompenses afin que les récompenses continuent de s'améliorer au fil du temps. En combinant une recherche de récompenses à grande échelle et des retours détaillés sur la réflexion des récompenses, Eureka produit progressivement de meilleures récompenses, dépassant finalement les performances humaines. Eureka génère également de nouvelles récompenses. Cet article évalue la nouveauté des récompenses Eureka en calculant la corrélation entre les récompenses Eureka et les récompenses humaines sur toutes les tâches Isaac. Comme le montre la figure, Eureka génère principalement des fonctions de récompense faiblement corrélées, qui surpassent les fonctions de récompense humaines. De plus, nous observons que plus la tâche est difficile, moins la récompense Eurêka est pertinente. Dans certains cas, les récompenses Eureka étaient même négativement corrélées aux récompenses humaines, tout en les surpassant largement. Si vous voulez réaliser que la main adroite du robot peut continuer à tourner le stylo, le programme d'exploitation doit avoir autant de cycles que possible. Cet article aborde cette tâche en (1) demandant à Eureka de générer une fonction de récompense utilisée pour rediriger les stylos vers des configurations cibles aléatoires, puis (2) en utilisant les récompenses Eureka pour affiner cette politique pré-entraînée afin d'obtenir la séquence de rotation de stylo souhaitée. configuration. Comme le montre la figure, la roulette Eureka s'est rapidement adaptée à la stratégie et a tourné avec succès pendant plusieurs cycles successifs. En revanche, ni les politiques de pré-formation ni celles apprises de toutes pièces ne peuvent réaliser un seul cycle de rotations. Cet article examine également s'il est bénéfique pour Eureka de commencer par une initialisation de fonction de récompense humaine. Comme démontré, Eureka s'améliore et bénéficie des récompenses humaines quelle que soit leur qualité. Eureka implémente également RLHF, qui peut combiner les commentaires humains pour modifier les récompenses, guidant ainsi progressivement l'agent vers des comportements plus sûrs et plus humains. L'exemple montre comment Eureka apprend à un robot humanoïde à courir debout avec des commentaires humains qui remplacent la réflexion de récompense automatique précédente. Un robot humanoïde apprend la démarche de course grâce à Eureka. Pour plus d'informations, veuillez vous référer au document original. 



Expérience





Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Ligne de commande de l'arrêt CentOS
Apr 14, 2025 pm 09:12 PM
Ligne de commande de l'arrêt CentOS
Apr 14, 2025 pm 09:12 PM
La commande de fermeture CENTOS est arrêtée et la syntaxe est la fermeture de [options] le temps [informations]. Les options incluent: -H Arrêtez immédiatement le système; -P éteignez l'alimentation après l'arrêt; -r redémarrer; -t temps d'attente. Les temps peuvent être spécifiés comme immédiats (maintenant), minutes (minutes) ou une heure spécifique (HH: mm). Des informations supplémentaires peuvent être affichées dans les messages système.
 Quelles sont les méthodes de sauvegarde pour Gitlab sur Centos
Apr 14, 2025 pm 05:33 PM
Quelles sont les méthodes de sauvegarde pour Gitlab sur Centos
Apr 14, 2025 pm 05:33 PM
La politique de sauvegarde et de récupération de GitLab dans le système CentOS afin d'assurer la sécurité et la récupérabilité des données, Gitlab on CentOS fournit une variété de méthodes de sauvegarde. Cet article introduira plusieurs méthodes de sauvegarde courantes, paramètres de configuration et processus de récupération en détail pour vous aider à établir une stratégie complète de sauvegarde et de récupération de GitLab. 1. MANUEL BACKUP Utilisez le Gitlab-RakegitLab: Backup: Créer la commande pour exécuter la sauvegarde manuelle. Cette commande sauvegarde des informations clés telles que le référentiel Gitlab, la base de données, les utilisateurs, les groupes d'utilisateurs, les clés et les autorisations. Le fichier de sauvegarde par défaut est stocké dans le répertoire / var / opt / gitlab / backups. Vous pouvez modifier / etc / gitlab
 Comment vérifier la configuration de CentOS HDFS
Apr 14, 2025 pm 07:21 PM
Comment vérifier la configuration de CentOS HDFS
Apr 14, 2025 pm 07:21 PM
Guide complet pour vérifier la configuration HDFS dans les systèmes CentOS Cet article vous guidera comment vérifier efficacement la configuration et l'état de l'exécution des HDF sur les systèmes CentOS. Les étapes suivantes vous aideront à bien comprendre la configuration et le fonctionnement des HDF. Vérifiez la variable d'environnement Hadoop: Tout d'abord, assurez-vous que la variable d'environnement Hadoop est correctement définie. Dans le terminal, exécutez la commande suivante pour vérifier que Hadoop est installé et configuré correctement: HadoopVersion Check HDFS Fichier de configuration: Le fichier de configuration de base de HDFS est situé dans le répertoire / etc / hadoop / conf / le répertoire, où Core-site.xml et hdfs-site.xml sont cruciaux. utiliser
 Comment est la prise en charge du GPU pour Pytorch sur Centos
Apr 14, 2025 pm 06:48 PM
Comment est la prise en charge du GPU pour Pytorch sur Centos
Apr 14, 2025 pm 06:48 PM
Activer l'accélération du GPU Pytorch sur le système CentOS nécessite l'installation de versions CUDA, CUDNN et GPU de Pytorch. Les étapes suivantes vous guideront tout au long du processus: CUDA et CUDNN Installation détermineront la compatibilité de la version CUDA: utilisez la commande NVIDIA-SMI pour afficher la version CUDA prise en charge par votre carte graphique NVIDIA. Par exemple, votre carte graphique MX450 peut prendre en charge CUDA11.1 ou plus. Téléchargez et installez Cudatoolkit: visitez le site officiel de Nvidiacudatoolkit et téléchargez et installez la version correspondante selon la version CUDA la plus élevée prise en charge par votre carte graphique. Installez la bibliothèque CUDNN:
 CentOS installe MySQL
Apr 14, 2025 pm 08:09 PM
CentOS installe MySQL
Apr 14, 2025 pm 08:09 PM
L'installation de MySQL sur CENTOS implique les étapes suivantes: Ajout de la source MySQL YUM appropriée. Exécutez la commande YUM Install MySQL-Server pour installer le serveur MySQL. Utilisez la commande mysql_secure_installation pour créer des paramètres de sécurité, tels que la définition du mot de passe de l'utilisateur racine. Personnalisez le fichier de configuration MySQL selon les besoins. Écoutez les paramètres MySQL et optimisez les bases de données pour les performances.
 Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Docker utilise les fonctionnalités du noyau Linux pour fournir un environnement de fonctionnement d'application efficace et isolé. Son principe de travail est le suivant: 1. Le miroir est utilisé comme modèle en lecture seule, qui contient tout ce dont vous avez besoin pour exécuter l'application; 2. Le Système de fichiers Union (UnionFS) empile plusieurs systèmes de fichiers, ne stockant que les différences, l'économie d'espace et l'accélération; 3. Le démon gère les miroirs et les conteneurs, et le client les utilise pour l'interaction; 4. Les espaces de noms et les CGROUP implémentent l'isolement des conteneurs et les limitations de ressources; 5. Modes de réseau multiples prennent en charge l'interconnexion du conteneur. Ce n'est qu'en comprenant ces concepts principaux que vous pouvez mieux utiliser Docker.
 CentOS8 redémarre SSH
Apr 14, 2025 pm 09:00 PM
CentOS8 redémarre SSH
Apr 14, 2025 pm 09:00 PM
La commande pour redémarrer le service SSH est: SystemCTL Redémarrer SSHD. Étapes détaillées: 1. Accédez au terminal et connectez-vous au serveur; 2. Entrez la commande: SystemCTL Restart SSHD; 3. Vérifiez l'état du service: SystemCTL Status Sshd.
 Comment faire fonctionner la formation distribuée de Pytorch sur CentOS
Apr 14, 2025 pm 06:36 PM
Comment faire fonctionner la formation distribuée de Pytorch sur CentOS
Apr 14, 2025 pm 06:36 PM
La formation distribuée par Pytorch sur le système CentOS nécessite les étapes suivantes: Installation de Pytorch: La prémisse est que Python et PIP sont installés dans le système CentOS. Selon votre version CUDA, obtenez la commande d'installation appropriée sur le site officiel de Pytorch. Pour la formation du processeur uniquement, vous pouvez utiliser la commande suivante: pipinstalltorchtorchVisionTorChaudio Si vous avez besoin d'une prise en charge du GPU, assurez-vous que la version correspondante de CUDA et CUDNN est installée et utilise la version Pytorch correspondante pour l'installation. Configuration de l'environnement distribué: la formation distribuée nécessite généralement plusieurs machines ou des GPU multiples uniques. Lieu
