
 Périphériques technologiques
IA
La longueur du contexte LLaMA2 monte en flèche jusqu'à 1 million de jetons, avec un seul hyperparamètre à ajuster.
Périphériques technologiques
IA
La longueur du contexte LLaMA2 monte en flèche jusqu'à 1 million de jetons, avec un seul hyperparamètre à ajuster.
La longueur du contexte LLaMA2 monte en flèche jusqu'à 1 million de jetons, avec un seul hyperparamètre à ajuster.

Avec seulement quelques ajustements, la taille du contexte de support des grands modèles peut être étendue de 16 000 jetons à 1 million ? !
Toujours sur LLaMA 2 qui ne possède que 7 milliards de paramètres.
Vous devez savoir que même les Claude 2 et GPT-4 actuellement populaires prennent en charge des longueurs de contexte de seulement 100 000 et 32 000. Au-delà de cette plage, les grands modèles commenceront à dire des bêtises et seront incapables de se souvenir des choses.
Maintenant, une nouvelle étude de l'Université de Fudan et du Laboratoire d'intelligence artificielle de Shanghai a non seulement trouvé un moyen d'augmenter la longueur de la fenêtre contextuelle pour une série de grands modèles, mais a également découvert les règles.

Selon cette règle, il suffit d'ajuster 1 hyperparamètre, peut garantir l'effet de sortie tout en améliorant de manière stable les performances d'extrapolation des grands modèles.
L'extrapolation fait référence à la modification des performances de sortie lorsque la longueur d'entrée du grand modèle dépasse la longueur du texte pré-entraîné. Si la capacité d'extrapolation n'est pas bonne, une fois que la longueur d'entrée dépasse la longueur du texte pré-entraîné, le grand modèle « dira des bêtises ».
Alors, qu'est-ce que cela peut exactement améliorer les capacités d'extrapolation des grands modèles, et comment fait-il ?
"Mécanisme" pour améliorer les capacités d'extrapolation de grands modèles
Cette méthode d'amélioration des capacités d'extrapolation de grands modèles est liée au module appelé Positional Encoding dans l'architecture Transformer.
En fait, le module de mécanisme d'attention simple (Attention) ne peut pas distinguer les jetons dans différentes positions. Par exemple, « Je mange des pommes » et « Les pommes me mangent » n'ont aucune différence à ses yeux.
Par conséquent, un codage positionnel doit être ajouté pour lui permettre de comprendre les informations sur l'ordre des mots et de vraiment comprendre le sens d'une phrase.
Les méthodes actuelles d'encodage de position du Transformer incluent l'encodage de position absolue (intégration des informations de position dans l'entrée), l'encodage de position relative (écriture des informations de position dans le calcul du score d'attention) et l'encodage de position de rotation. Parmi eux, le plus populaire est l’encodage de position de rotation, qui est RoPE.
RoPE obtient l'effet de codage de position relative grâce à un codage de position absolue, mais par rapport au codage de position relative, il peut mieux améliorer le potentiel d'extrapolation des grands modèles.
Comment stimuler davantage les capacités d'extrapolation des grands modèles à l'aide du codage de position RoPE est également devenu une nouvelle direction dans de nombreuses études récentes.
Ces études sont principalement divisées en deux grandes écoles : limitation de l'attention et ajustement de l'angle de rotation.
Les recherches représentatives sur la limitation de l'attention incluent ALiBi, xPos, BCA, etc. Le StreamingLLM récemment proposé par le MIT peut permettre aux grands modèles d'atteindre une longueur d'entrée infinie (mais n'augmente pas la longueur de la fenêtre contextuelle), ce qui appartient au type de recherche dans cette direction.
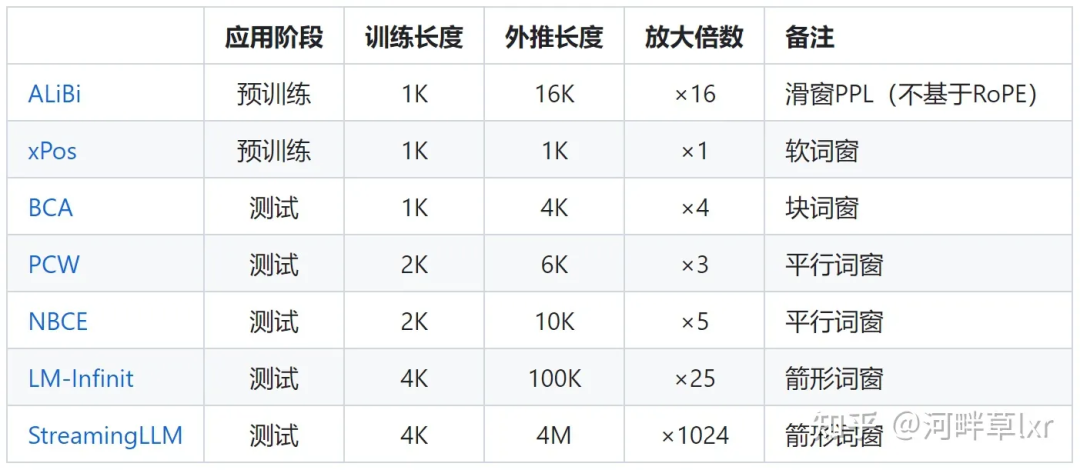
△L'auteur de la source de l'image
a encore du travail à faire pour ajuster l'angle de rotation. Les représentants typiques tels que l'interpolation linéaire, Giraffe, Code LLaMA, LLaMA2 Long, etc. appartiennent tous à ce type de recherche.
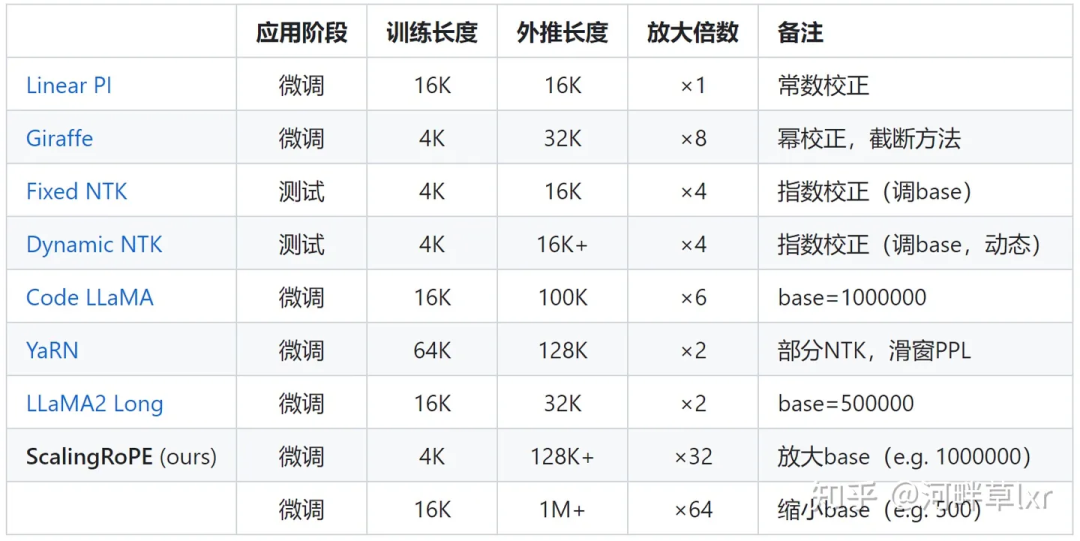
△Auteur de la source de l'image
Prenant comme exemple la recherche récemment populaire LLaMA2 Long de Meta, il a proposé une méthode appelée RoPE ABF, qui a réussi à étendre la longueur du contexte des grands modèles en modifiant un hyperparamètre à 32 000 jetons. .
Cet hyperparamètre est exactement le "switch" découvert par des études telles que Code LLaMA et LLaMA2 Long -
la base de l'angle de rotation (base).
Ajustez-le simplement pour garantir de meilleures performances d'extrapolation des grands modèles.
Mais qu'il s'agisse de Code LLaMA ou de LLaMA2 Long, ils ne sont affinés que sur une base précise et une durée d'entraînement continue pour renforcer leurs capacités d'extrapolation.
Pouvons-nous trouver une règle garantissant que tous les grands modèles utilisant le codage de position RoPE puissent améliorer de manière stable les performances d'extrapolation ?
Maîtrisez cette règle, le contexte est facile 100w+
Des chercheurs de l'Université de Fudan et de l'Institut de recherche sur l'IA de Shanghai ont mené des expériences sur ce problème.
Ils ont d'abord analysé plusieurs paramètres qui affectent les capacités d'extrapolation RoPE et ont proposé un concept appelé Dimension critique (Dimension critique). Ensuite, sur la base de ce concept, ils ont résumé un ensemble de Loi de mise à l'échelle de l'extrapolation RoPE de l'extrapolation basée sur RoPE.
Appliquez simplement cetteloi pour garantir que tout grand modèle basé sur le codage positionnel RoPE peut améliorer les capacités d'extrapolation.
Voyons d’abord quelle est la dimension critique.D'après la définition, il est lié à la longueur du texte de pré-entraînement Ttrain, au nombre de dimensions de la tête d'auto-attention d et à d'autres paramètres. La méthode de calcul spécifique est la suivante : .

Parmi eux, 10000 est la "valeur initiale" de l'hyperparamètre et de la base de l'angle de rotation.
L'auteur a découvert que, que la base soit agrandie ou réduite, la capacité d'extrapolation du grand modèle basé sur RoPE peut finalement être améliorée. En revanche, lorsque la base de l'angle de rotation est de 10 000, la capacité d'extrapolation du grand modèle est. le pire.
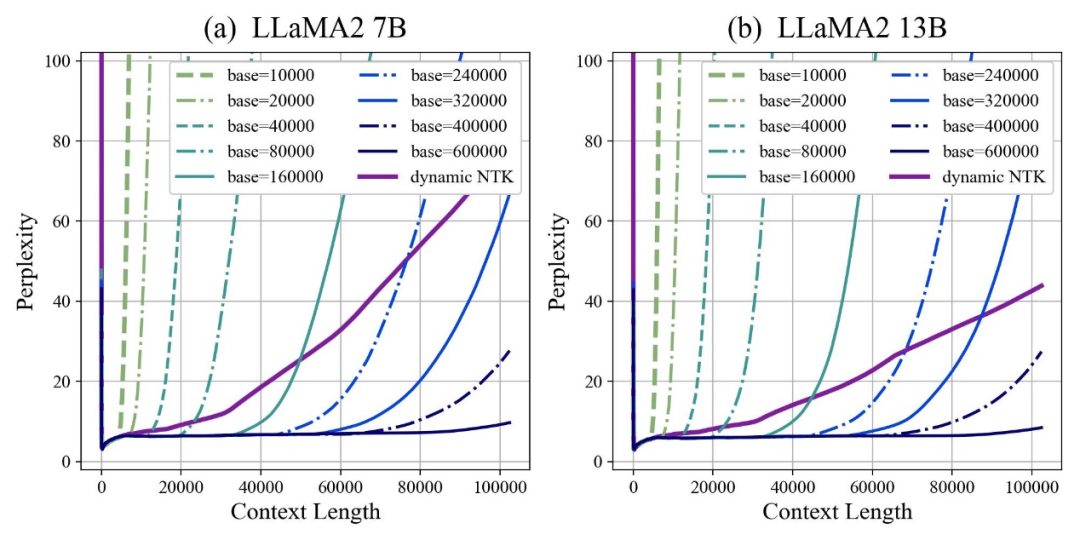
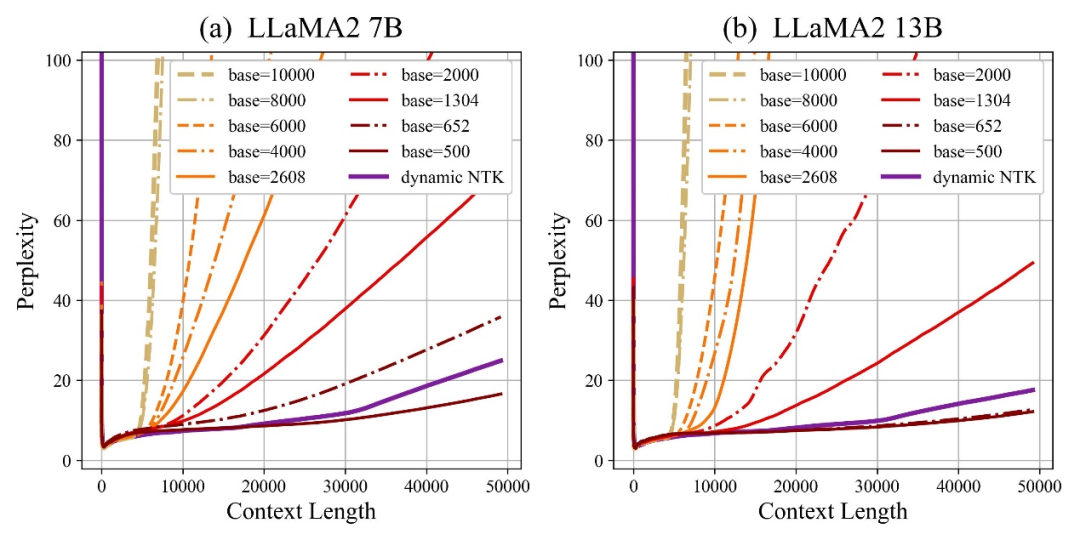
Cet article estime qu'une base d'angle de rotation plus petite peut permettre aux informations de position d'être perçues dans plus de dimensions, et qu'une base d'angle de rotation plus grande peut exprimer des informations de position plus longues.
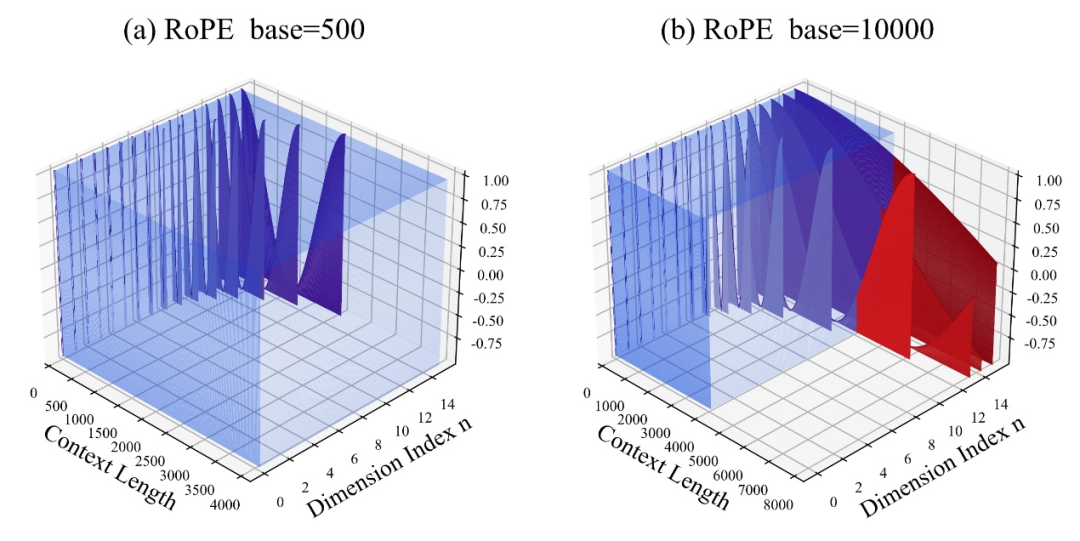
Dans ce cas, face à des corpus d'entraînement continu de différentes longueurs, de combien de base d'angle de rotation faut-il réduire et agrandir pour garantir que la capacité d'extrapolation des grands modèles est maximisée ?
L'article donne une règle de mise à l'échelle pour l'extrapolation RoPE étendue, qui est liée à des paramètres tels que les dimensions critiques, la longueur du texte d'entraînement continu et la longueur du texte de pré-entraînement des grands modèles :

Sur la base de cette règle, différents pré- une formation peut être effectuée et une formation continue sur la longueur du texte pour calculer directement les performances d'extrapolation du grand modèle, en d'autres termes, prédire la longueur du contexte prise en charge par le grand modèle.
À l'inverse, en utilisant cette règle, vous pouvez rapidement déduire comment ajuster au mieux la base de l'angle de rotation, améliorant ainsi les performances d'extrapolation des grands modèles.
L'auteur a testé cette série de tâches et a découvert qu'à titre expérimental, la saisie actuelle d'une longueur de 100 000, 500 000 ou même 1 million de jetons peut garantir que l'extrapolation peut être réalisée sans restrictions d'attention supplémentaires.
Dans le même temps, les travaux visant à améliorer les capacités d'extrapolation des grands modèles, notamment Code LLaMA et LLaMA2 Long, ont prouvé que cette règle est effectivement raisonnable et efficace.
De cette façon, il vous suffit « d'ajuster un paramètre » selon cette règle, et vous pouvez facilement étendre la longueur de la fenêtre contextuelle du grand modèle basé sur RoPE et améliorer la capacité d'extrapolation.
Liu Xiaoran, le premier auteur de l'article, a déclaré que cette recherche améliore actuellement les effets des tâches en aval en améliorant le corpus de formation continue. Une fois terminé, le code et le modèle seront open source. ~
Adresse papier :
https://arxiv.org/abs/2310.05209
Dépôt Github :
https://github.com/OpenLMLab/scaling-rope
Analyse papier blog :
https:// zhuanlan.zhihu.com/p/660073229
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Utilisez ddrescue pour récupérer des données sous Linux
Mar 20, 2024 pm 01:37 PM
Utilisez ddrescue pour récupérer des données sous Linux
Mar 20, 2024 pm 01:37 PM
DDREASE est un outil permettant de récupérer des données à partir de périphériques de fichiers ou de blocs tels que des disques durs, des SSD, des disques RAM, des CD, des DVD et des périphériques de stockage USB. Il copie les données d'un périphérique bloc à un autre, laissant derrière lui les blocs corrompus et ne déplaçant que les bons blocs. ddreasue est un puissant outil de récupération entièrement automatisé car il ne nécessite aucune interruption pendant les opérations de récupération. De plus, grâce au fichier map ddasue, il peut être arrêté et repris à tout moment. Les autres fonctionnalités clés de DDREASE sont les suivantes : Il n'écrase pas les données récupérées mais comble les lacunes en cas de récupération itérative. Cependant, il peut être tronqué si l'outil est invité à le faire explicitement. Récupérer les données de plusieurs fichiers ou blocs en un seul
 Open source! Au-delà de ZoeDepth ! DepthFM : estimation rapide et précise de la profondeur monoculaire !
Apr 03, 2024 pm 12:04 PM
Open source! Au-delà de ZoeDepth ! DepthFM : estimation rapide et précise de la profondeur monoculaire !
Apr 03, 2024 pm 12:04 PM
0. À quoi sert cet article ? Nous proposons DepthFM : un modèle d'estimation de profondeur monoculaire génératif de pointe, polyvalent et rapide. En plus des tâches traditionnelles d'estimation de la profondeur, DepthFM démontre également des capacités de pointe dans les tâches en aval telles que l'inpainting en profondeur. DepthFM est efficace et peut synthétiser des cartes de profondeur en quelques étapes d'inférence. Lisons ce travail ensemble ~ 1. Titre des informations sur l'article : DepthFM : FastMonocularDepthEstimationwithFlowMatching Auteur : MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Comment utiliser la fonction de filtre Excel avec plusieurs conditions
Feb 26, 2024 am 10:19 AM
Comment utiliser la fonction de filtre Excel avec plusieurs conditions
Feb 26, 2024 am 10:19 AM
Si vous avez besoin de savoir comment utiliser le filtrage avec plusieurs critères dans Excel, le didacticiel suivant vous guidera à travers les étapes pour vous assurer que vous pouvez filtrer et trier efficacement vos données. La fonction de filtrage d'Excel est très puissante et peut vous aider à extraire les informations dont vous avez besoin à partir de grandes quantités de données. Cette fonction peut filtrer les données en fonction des conditions que vous définissez et afficher uniquement les pièces qui remplissent les conditions, rendant la gestion des données plus efficace. En utilisant la fonction de filtre, vous pouvez trouver rapidement des données cibles, ce qui vous fait gagner du temps dans la recherche et l'organisation des données. Cette fonction peut non seulement être appliquée à de simples listes de données, mais peut également être filtrée en fonction de plusieurs conditions pour vous aider à localiser plus précisément les informations dont vous avez besoin. Dans l’ensemble, la fonction de filtrage d’Excel est très utile
 Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Les performances de JAX, promu par Google, ont dépassé celles de Pytorch et TensorFlow lors de récents tests de référence, se classant au premier rang sur 7 indicateurs. Et le test n’a pas été fait sur le TPU présentant les meilleures performances JAX. Bien que parmi les développeurs, Pytorch soit toujours plus populaire que Tensorflow. Mais à l’avenir, des modèles plus volumineux seront peut-être formés et exécutés sur la base de la plate-forme JAX. Modèles Récemment, l'équipe Keras a comparé trois backends (TensorFlow, JAX, PyTorch) avec l'implémentation native de PyTorch et Keras2 avec TensorFlow. Premièrement, ils sélectionnent un ensemble de
 Vitesse Internet lente des données cellulaires sur iPhone : correctifs
May 03, 2024 pm 09:01 PM
Vitesse Internet lente des données cellulaires sur iPhone : correctifs
May 03, 2024 pm 09:01 PM
Vous êtes confronté à un décalage et à une connexion de données mobile lente sur iPhone ? En règle générale, la puissance de l'Internet cellulaire sur votre téléphone dépend de plusieurs facteurs tels que la région, le type de réseau cellulaire, le type d'itinérance, etc. Vous pouvez prendre certaines mesures pour obtenir une connexion Internet cellulaire plus rapide et plus fiable. Correctif 1 – Forcer le redémarrage de l'iPhone Parfois, le redémarrage forcé de votre appareil réinitialise simplement beaucoup de choses, y compris la connexion cellulaire. Étape 1 – Appuyez simplement une fois sur la touche d’augmentation du volume et relâchez-la. Ensuite, appuyez sur la touche de réduction du volume et relâchez-la à nouveau. Étape 2 – La partie suivante du processus consiste à maintenir le bouton sur le côté droit. Laissez l'iPhone finir de redémarrer. Activez les données cellulaires et vérifiez la vitesse du réseau. Vérifiez à nouveau Correctif 2 – Changer le mode de données Bien que la 5G offre de meilleures vitesses de réseau, elle fonctionne mieux lorsque le signal est plus faible
 La vitalité de la super intelligence s'éveille ! Mais avec l'arrivée de l'IA qui se met à jour automatiquement, les mères n'ont plus à se soucier des goulots d'étranglement des données.
Apr 29, 2024 pm 06:55 PM
La vitalité de la super intelligence s'éveille ! Mais avec l'arrivée de l'IA qui se met à jour automatiquement, les mères n'ont plus à se soucier des goulots d'étranglement des données.
Apr 29, 2024 pm 06:55 PM
Je pleure à mort. Le monde construit à la folie de grands modèles. Les données sur Internet ne suffisent pas du tout. Le modèle de formation ressemble à « The Hunger Games », et les chercheurs en IA du monde entier se demandent comment nourrir ces personnes avides de données. Ce problème est particulièrement important dans les tâches multimodales. À une époque où rien ne pouvait être fait, une équipe de start-up du département de l'Université Renmin de Chine a utilisé son propre nouveau modèle pour devenir la première en Chine à faire de « l'auto-alimentation des données générées par le modèle » une réalité. De plus, il s’agit d’une approche à deux volets, du côté compréhension et du côté génération, les deux côtés peuvent générer de nouvelles données multimodales de haute qualité et fournir un retour de données au modèle lui-même. Qu'est-ce qu'un modèle ? Awaker 1.0, un grand modèle multimodal qui vient d'apparaître sur le Forum Zhongguancun. Qui est l'équipe ? Moteur Sophon. Fondé par Gao Yizhao, doctorant à la Hillhouse School of Artificial Intelligence de l’Université Renmin.
 Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
La dernière vidéo du robot Optimus de Tesla est sortie, et il peut déjà fonctionner en usine. À vitesse normale, il trie les batteries (les batteries 4680 de Tesla) comme ceci : Le responsable a également publié à quoi cela ressemble à une vitesse 20 fois supérieure - sur un petit "poste de travail", en sélectionnant et en sélectionnant et en sélectionnant : Cette fois, il est publié L'un des points forts de la vidéo est qu'Optimus réalise ce travail en usine, de manière totalement autonome, sans intervention humaine tout au long du processus. Et du point de vue d'Optimus, il peut également récupérer et placer la batterie tordue, en se concentrant sur la correction automatique des erreurs : concernant la main d'Optimus, le scientifique de NVIDIA Jim Fan a donné une évaluation élevée : la main d'Optimus est l'un des robots à cinq doigts du monde. le plus adroit. Ses mains ne sont pas seulement tactiles
 Le premier robot capable d'accomplir de manière autonome des tâches humaines apparaît, avec cinq doigts flexibles et rapides, et de grands modèles prennent en charge l'entraînement dans l'espace virtuel
Mar 11, 2024 pm 12:10 PM
Le premier robot capable d'accomplir de manière autonome des tâches humaines apparaît, avec cinq doigts flexibles et rapides, et de grands modèles prennent en charge l'entraînement dans l'espace virtuel
Mar 11, 2024 pm 12:10 PM
Cette semaine, FigureAI, une entreprise de robotique investie par OpenAI, Microsoft, Bezos et Nvidia, a annoncé avoir reçu près de 700 millions de dollars de financement et prévoit de développer un robot humanoïde capable de marcher de manière autonome au cours de la prochaine année. Et l’Optimus Prime de Tesla a reçu à plusieurs reprises de bonnes nouvelles. Personne ne doute que cette année sera celle de l’explosion des robots humanoïdes. SanctuaryAI, une entreprise canadienne de robotique, a récemment lancé un nouveau robot humanoïde, Phoenix. Les responsables affirment qu’il peut accomplir de nombreuses tâches de manière autonome, à la même vitesse que les humains. Pheonix, le premier robot au monde capable d'accomplir des tâches de manière autonome à la vitesse d'un humain, peut saisir, déplacer et placer avec élégance chaque objet sur ses côtés gauche et droit. Il peut identifier des objets de manière autonome
