

Auteur : Ye Xiaofei
Lien : https://www.zhihu.com/question/269707221/answer/2281374258
Quand j'ai atterri chez Mercedes-Benz en Amérique du Nord, il fut un temps afin de tester différentes structures et paramètres, peut former plus d'une centaine de modèles différents en une semaine Pour cette raison, j'ai combiné les pratiques des prédécesseurs de l'entreprise et mes propres réflexions pour résumer un ensemble de méthodes efficaces de gestion des expériences de code, qui a aidé à mettre en œuvre le projet avec succès. Maintenant, je le partage ici avec tout le monde.
Je sais que de nombreux dépôts open source aiment utiliser l'argparse d'entrée pour transmettre de nombreux paramètres de formation et liés au modèle, ce qui est en fait très inefficace. D'une part, il sera gênant de saisir manuellement un grand nombre de paramètres à chaque fois que vous vous entraînez. Si vous modifiez directement les valeurs par défaut puis accédez au code pour les modifier, cela vous fera perdre beaucoup de temps. Ici, je vous recommande d'utiliser directement un fichier Yaml pour contrôler tous les paramètres liés au modèle et à la formation, et de lier le nom du Yaml au nom du modèle et à l'horodatage. C'est ce que fait la célèbre bibliothèque de détection de nuages de points 3D OpenPCDet, comme illustré ci-dessous. ce lien. github.com/open-mmlab/OpenPCDet/blob/master/tools/cfgs/kitti_models/pointrcnn.yaml
J'ai coupé une partie du fichier yaml du lien donné ci-dessus, comme le montre la figure ci-dessous, cette configuration couvertures de fichiers Il comprend comment prétraiter les nuages de points, les types de classification, divers paramètres du squelette et la sélection de l'optimiseur et de la perte (non illustré dans la figure, veuillez consulter le lien ci-dessus pour plus de détails). En d'autres termes,
Fondamentalement, tous les facteurs qui peuvent affecter votre modèle sont inclus dans ce fichier, et dans le code, il vous suffit d'utiliser un simple yaml.load() pour lire tous ces paramètres dans un dict. Plus important encore, Ce fichier de configuration peut être enregistré dans le même dossier que votre point de contrôle, vous pouvez donc l'utiliser directement pour la formation des points d'arrêt, le réglage fin ou les tests directs. Il est également très pratique à utiliser pour tester les résultats. les paramètres correspondants.
 La modularisation du code est très importante
La modularisation du code est très importante
Tensorboard, tqdm
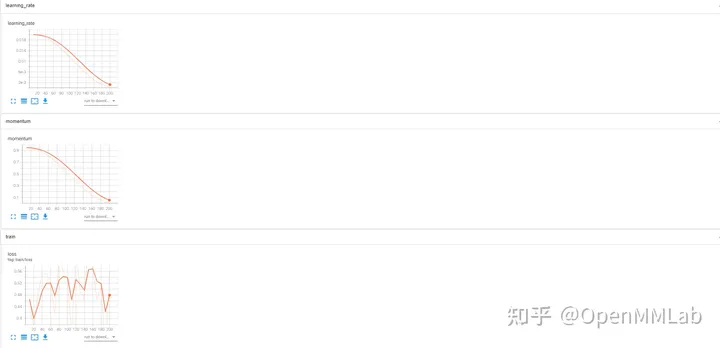
J'utilise ces deux bibliothèques pratiquement à chaque fois. Tensorboard peut très bien suivre les changements dans la courbe de perte de votre entraînement, ce qui vous permet de juger plus facilement si le modèle est toujours convergent et surajusté. Si vous effectuez un travail lié à l'image, vous pouvez également y mettre des résultats de visualisation. Souvent, il vous suffit de regarder l'état de convergence du tensorboard pour savoir comment fonctionne votre modèle. Est-il nécessaire de passer du temps à tester et à affiner séparément. Tqdm peut vous aider à suivre intuitivement la progression de votre entraînement, ce qui vous facilite la tâche ? arrêt anticipé .Utilisez pleinement GithubQue vous co-développiez avec plusieurs personnes ou que vous travailliez sur un projet solo, je vous recommande fortement d'utiliser Github (la société peut utiliser bitbucket, plus ou moins) pour enregistrer votre code. Pour plus de détails, veuillez vous référer à ma réponse : En tant qu'étudiant diplômé, quels outils de recherche scientifique vous semblent utiles ?https://www.zhihu.com/question/484596211/answer/2163122684
Enregistrer les résultats expérimentaux
Réponse 2
Le code de gestion Git n'a rien à voir avec l'apprentissage profond ou la recherche scientifique. L'écriture de code est obligatoire. be Utiliser des outils de gestion de versions. Personnellement, je pense que c'est une question de choix d'utiliser ou non GitHub. Après tout, il est impossible que tout le code de l'entreprise soit lié à un Git externe.
Par contre, après avoir testé des milliers de versions, je pense que vous ne saurez pas quel modèle a quels paramètres. Les bonnes habitudes sont très efficaces. De plus, essayez de fournir des valeurs par défaut pour les paramètres nouvellement ajoutés afin de faciliter l'appel de l'ancienne version du fichier de configuration.
Dans le même projet, une bonne réutilisabilité est une très bonne habitude de programmation, mais dans le codage DL en développement rapide, on suppose que le projet est axé sur les tâches. Oui, cela peut parfois devenir un obstacle, alors essayez d'extraire certaines fonctions réutilisables. Concernant la structure du modèle, essayez de découpler différents modèles en différents fichiers, ce qui rendra les futures mises à jour plus pratiques. Sinon, certains designs apparemment beaux deviendront inutiles au bout de quelques mois.
Il y a souvent une situation embarrassante Du début à la fin d'un projet, le framework a été mis à jour vers plusieurs versions, et la nouvelle version possède des fonctionnalités alléchantes, mais malheureusement certaines API ont changé. Par conséquent, vous pouvez essayer de maintenir la version du framework stable au sein du projet. Essayez de considérer les avantages et les inconvénients des différentes versions avant de démarrer le projet. Parfois, un apprentissage approprié est nécessaire.
De plus, ayez un cœur tolérant envers les différents cadres.
Auteur : OpenMMLab
Lien : https://www.zhihu.com/question/269707221/answer/2480772257
Source : Zhihu
Le droit d'auteur appartient à l'auteur. Pour une réimpression commerciale, veuillez contacter l'auteur pour obtenir une autorisation. Pour une réimpression non commerciale, veuillez indiquer la source.
Bonjour l'intervenant, la réponse précédente mentionnait l'utilisation de Tensorboard, Weights&Biases, MLFlow, Neptune et d'autres outils pour gérer les données expérimentales. Cependant, à mesure que de plus en plus de roues sont construites pour des outils de gestion expérimentaux, le coût de l'apprentissage de ces outils devient de plus en plus élevé. Comment devrions-nous choisir ?
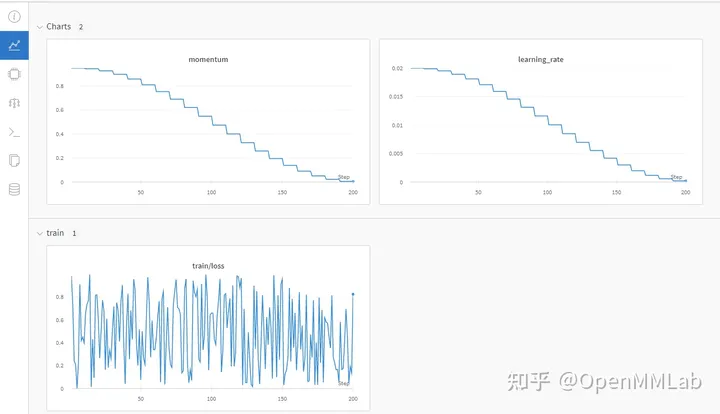
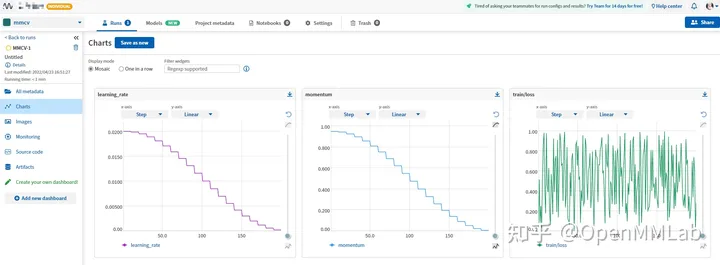
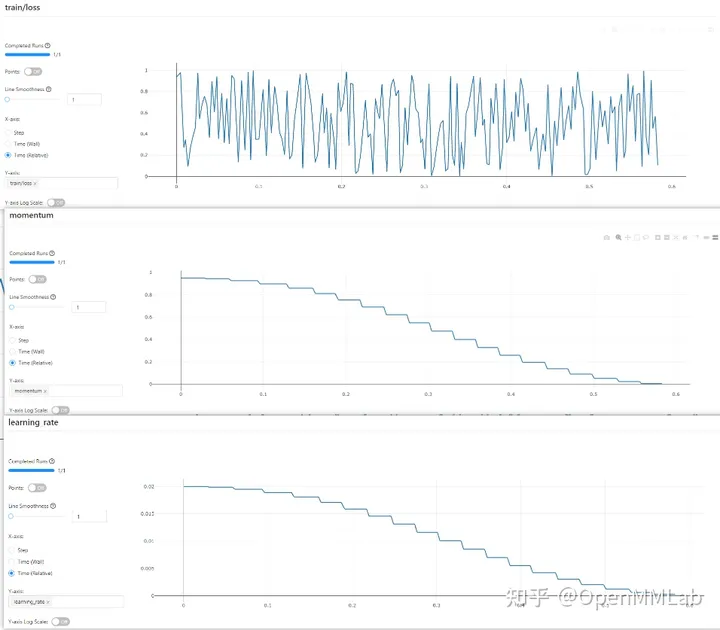
MMCV répond à tous vos fantasmes, et vous pouvez changer d'outil en modifiant le fichier de configuration.
github.com/open-mmlab/mmcv
log_config = dict( interval=1, hooks=[ dict(type='TextLoggerHook'), dict(type='TensorboardLoggerHook') ])
log_config = dict( interval=1, hooks=[ dict(type='TextLoggerHook'), dict(type='WandbLoggerHook') ])
(vous devez vous connecter à wandb avec l'API Python à l'avance)
log_config = dict( interval=1, hooks=[ dict(type='TextLoggerHook'), dict(type='NeptuneLoggerHook', init_kwargs=dict(project='Your Neptume account/mmcv')) ])
log_config = dict( interval=1, hooks=[ dict(type='TextLoggerHook'), dict(type='MlflowLoggerHook') ])
log_config = dict( interval=1, hooks=[ dict(type='TextLoggerHook'), dict(type='DvcliveLoggerHook') ])
Ce qui précède utilise uniquement le fonctions les plus élémentaires de divers outils de gestion expérimentale , nous pouvons modifier davantage le profil pour débloquer plus de poses.
Avoir MMCV équivaut à disposer de tous les outils de gestion expérimentaux. Si vous étiez un garçon de TF auparavant, vous pouvez choisir le style nostalgique classique de TensorBoard ; si vous souhaitez enregistrer toutes les données expérimentales et l'environnement expérimental, vous pouvez aussi bien essayer Wandb (Poids et biais) ou Neptume si votre appareil ne peut pas l'être ; connecté à Internet, vous pouvez choisir mlflow pour que les données expérimentales soient enregistrées localement et il y a toujours un outil qui vous convient.
De plus, MMCV dispose également de son propre système de gestion des journaux, qui est TextLoggerHook ! Il enregistrera toutes les informations générées pendant le processus de formation, telles que l'environnement de l'appareil, l'ensemble de données, la méthode d'initialisation du modèle, la perte, les mesures et autres informations générées pendant la formation, dans le fichier xxx.log local. Vous pouvez consulter les données expérimentales précédentes sans utiliser d'outils.
Vous vous demandez toujours quel outil de gestion des expériences utiliser ? Êtes-vous toujours inquiet du coût d’apprentissage de divers outils ? Dépêchez-vous et embarquez à bord de MMCV et découvrez divers outils sans douleur avec seulement quelques lignes de fichiers de configuration.
github.com/open-mmlab/mmcv
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Tutoriel PHP
Tutoriel PHP
 Quelle est la raison pour laquelle l'écran de l'ordinateur est noir mais l'ordinateur est allumé ?
Quelle est la raison pour laquelle l'écran de l'ordinateur est noir mais l'ordinateur est allumé ?
 Comment changer la couleur d'arrière-plan d'un mot en blanc
Comment changer la couleur d'arrière-plan d'un mot en blanc
 Quels sont les quatre outils d'analyse du Big Data ?
Quels sont les quatre outils d'analyse du Big Data ?
 Comment résoudre les problèmes lors de l'analyse des packages
Comment résoudre les problèmes lors de l'analyse des packages
 Tutoriel de récupération des icônes de mon ordinateur Win10
Tutoriel de récupération des icônes de mon ordinateur Win10
 Qu'est-ce que Spring MVC
Qu'est-ce que Spring MVC
 JavaScript : vide 0
JavaScript : vide 0








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



