
 Périphériques technologiques
IA
Des bases à la pratique, passez en revue l'historique du développement de la récupération de vecteurs Elasticsearch.
Périphériques technologiques
IA
Des bases à la pratique, passez en revue l'historique du développement de la récupération de vecteurs Elasticsearch.
Des bases à la pratique, passez en revue l'historique du développement de la récupération de vecteurs Elasticsearch.


1. Introduction
La récupération de vecteurs est devenue un élément essentiel des systèmes de recherche et de recommandation modernes.
Il permet une correspondance de requêtes et des recommandations efficaces en convertissant des objets complexes (tels que du texte, des images ou des sons) en vecteurs numériques et en effectuant des recherches de similarité dans un espace multidimensionnel.
 Des bases à la pratique, passez en revue l'historique de développement d'Elasticsearch vector retrieval_elasticsearch
Des bases à la pratique, passez en revue l'historique de développement d'Elasticsearch vector retrieval_elasticsearch
Elasticsearch est un moteur de recherche open source populaire, et son développement dans la récupération de vecteurs a toujours attiré beaucoup d'attention. Cet article passera en revue l'historique du développement de la récupération de vecteurs Elasticsearch, en se concentrant sur les caractéristiques et la progression de chaque étape. Prendre l’historique comme guide aidera chacun à comprendre pleinement la récupération de vecteurs Elasticsearch.
2. Tentative initiale : l'introduction de la récupération vectorielle simple
Elasticsearch n'a pas été initialement conçu spécifiquement pour la récupération vectorielle. Cependant, avec l’essor de l’apprentissage automatique et de l’intelligence artificielle, la demande d’interrogation d’espaces vectoriels de grande dimension a progressivement augmenté.
Dans la version 5.x d'Elasticsearch, les passionnés d'Elastic ont commencé à essayer d'implémenter des fonctions simples de récupération de vecteurs via des plug-ins et des opérations mathématiques de base. Par exemple : certains premiers plug-ins tels que elasticsearch-vector-scoring et fast-elasticsearch-vector-scoring sont conçus pour répondre à de tels besoins.
https://www.php.cn/link/7a677bb4477ae2dd371add568dd19e23
https://www.php.cn/link/7684e5225ab986f6b32ed950eec5621d
Vecteurs à ce stade, la récupération est principalement utilisée pour les requêtes de similarité de base, telles que comme calcul de similarité de texte. Bien que les fonctions soient relativement limitées, cela pose les bases d’un développement ultérieur.
Explication étendue : Concernant la fonction de machine learning, si vous êtes intéressé par le changement de version d'Elasticsearch, je me souviens que la version 6.X a été lancée à cette époque, ce qui était très excitant. Cependant, en raison des fonctions non open source, le véritable public national est encore relativement restreint.
3. Prise en charge officielle : développement ultérieur
Dans la version 7.0 d'Elasticsearch, la prise en charge des champs vectoriels a été officiellement ajoutée, par exemple via le type dense_vector. Cela marque qu'Elasticsearch entre officiellement dans le domaine de la récupération de vecteurs et ne s'appuie plus uniquement sur des plug-ins.
dense_vector Heure de lancement la plus précoce : 13 décembre 2018, la version 7.6 est marquée GA.
https://www.php.cn/link/648f4baa45889f9c5f4f7add35862841
https://www.php.cn/link/ac10ff1941c540cd87c107330996f4f6
Concernant l'utilisation du type dense_vector, lecture recommandée : Vecteur de grande dimension search : Exploration pratique de l'utilisation de dense_vector dans Elasticsearch 8.X.
Le principal défi à ce stade est de savoir comment prendre en charge efficacement la récupération de vecteurs dans la structure d'index inversé traditionnelle. Combiné aux fonctionnalités de recherche en texte intégral existantes, Elasticsearch fournit une solution flexible et puissante.
Des plug-ins initiaux et opérations de base jusqu'au support et à l'intégration officiels ultérieurs, cette étape a jeté une base solide pour l'innovation et l'optimisation ultérieures d'Elasticsearch en matière de récupération de vecteurs.
4. Optimisation spécialisée : calcul de similarité amélioré
Avec la croissance de la demande, l'équipe Elasticsearch a commencé à mener des recherches approfondies et à optimiser les performances de récupération de vecteurs. Cela implique l'introduction de méthodes de calcul de similarité plus complexes, telles que la similarité cosinus, la distance euclidienne, etc., ainsi que l'optimisation de l'exécution des requêtes.
À partir de la version 7.3 d'Elasticsearch, une méthode de calcul de similarité plus complexe a été officiellement introduite. En particulier, les améliorations apportées à la requête script_score permettent aux utilisateurs de personnaliser des calculs de similarité plus riches via des scripts Painless.
/guide/en/elasticsearch/reference/7.3/query-dsl-script-score-query.html#vector-functions
La fonction principale est de permettre le calcul de la similarité via l'angle entre les vecteurs, en utilisant k voisins les plus proches ( k-NN) pour prendre en charge les moteurs de recherche de similarité. Il est largement utilisé dans les systèmes d’analyse de texte et de recommandation.
Principalement utilisé pour résoudre : des exigences de similarité complexes, offrant des options de calcul de similarité plus flexibles et plus puissantes pour répondre à davantage de besoins commerciaux.
Les scénarios d'application sont reflétés dans :
(1)个性化推荐:通过余弦相似度分析用户的行为和兴趣,提供更个性化的推荐内容;(2)图像识别和搜索:使用欧几里得距离快速检索与给定图像相似的图像;(3)声音分析:在声音文件之间寻找相似模式,用于语音识别和分析。
Il convient de mentionner que : initialement, les dimensions prises en charge par la récupération vectorielle étaient : 1024, jusqu'à la version 8.8 d'Elasticsearch, les dimensions prises en charge ont été modifiées en : 2048 (c'est une demande très populaire) .
https://www.php.cn/link/1bda7493c968ded9800b3a754fc07e5c
/t/vector-knn-search-with-more-than-1024-dimensions/332819
Elasticsearch 7.x 版本的增强相似度计算功能标志着向量检索能力的显著进展。通过引入更复杂的相似度计算方法和查询优化,Elasticsearch 不仅增强了其在传统搜索场景中的功能,还为新兴的机器学习和 AI 应用打开了新的可能性。
但,这个时候你会发现,如果要实现复杂的向量搜索功能,自己实现的还很多。如果把后面马上提到的深度学习的集成和大模型的出现比作:飞行的汽车,当前的阶段还是 “拉驴车”,功能是有的,但用起来很费劲。
 从基础到实践,回顾Elasticsearch 向量检索发展史_Elastic_02
从基础到实践,回顾Elasticsearch 向量检索发展史_Elastic_02
5.深度学习集成与未来展望
大模型时代,向量检索和多模态搜索成为 “兵家” 必争之地。
多模态检索是一种综合各种数据模态(如文本、图像、音频、视频等)的检索技术。换句话说,它不仅仅是根据文字进行搜索,还可以根据图像、声音或其他模态的输入来搜索相关内容。
为了更通俗地理解多模态检索,我们可以通过以下比喻和示例来加深认识:想象你走进一个巨大的图书馆,这里不仅有书籍,还有各种图片、录音和视频。你可以向图书馆员展示一张照片,她会为你找到与这张照片相关的所有书籍、音频和视频。或者,你可以哼一段旋律,图书馆员能找到相关的资料,或者提供类似的歌曲或视频。这就是多模态检索的魔力!
随着深度学习技术的不断发展和应用,Elasticsearch 已开始探索将深度学习模型直接集成到向量检索过程中。这不仅允许更复杂、更准确的相似度计算,还开辟了新的应用领域,例如基于图像或声音的搜索。尤其在 Elasticsearch 的 8.x 版本,这一方向得到了显著的推进。
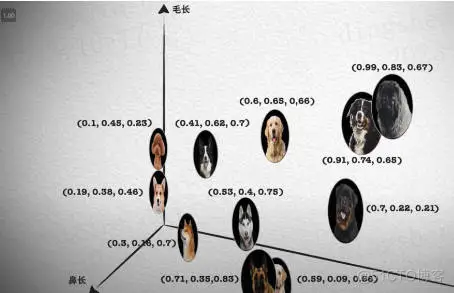
5.1 向量化是前提
如下图所示,先从左往右看是写入,图像、文档、音频转化为向量特征表示,在 Elasticsearch 中通过 dense_vector 类型存储。
从右往左看是检索,先将检索语句转化为向量特征表示,然后借助 K 近邻检索算法(在 Elasticsearch 中借助 Knn search 实现),获取相似的结果。
看中间,Results 部分就是向量检索的结果。
综上,向量检索打破了传统倒排索引仅支持文本检索的缺陷,可以扩展支持文本、语音、图像、视频多种模态。
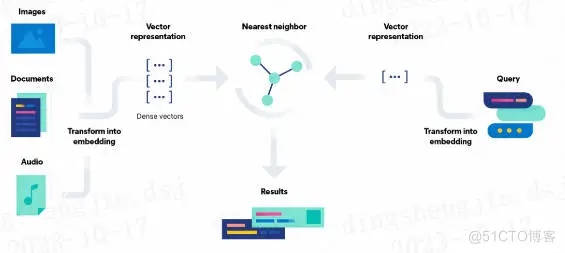 图片来自:Elasticsearch 官方文档
图片来自:Elasticsearch 官方文档
相信你到这里,应该理解了向量检索和多模态。没有向量化的这个过程,多模态检索无从谈起。
5.2 模型是核心
深度学习模型集成总共可分为三步:
第一步:模型导入和管理:Elasticsearch 8.x 支持导入预训练的深度学习模型,并提供相应的模型管理工具,方便模型的部署和更新。第二步:向量表示与转换:通过深度学习模型,可以将非结构化数据如图像和声音转换为向量表示,从而进行有效的检索。第三步:自定义相似度计算:8.x 版本提供了基于深度学习模型的自定义相似度计算接口,允许用户根据实际需求开发和部署专门的相似度计算方法。
关于深度学习,可以是自训练模型,也可以是第三方模型库中的模型,举例:咱们图搜图案例中就是用的 HuggingFace 里的:clip-ViT-B-32-multilingual-v1 模型。
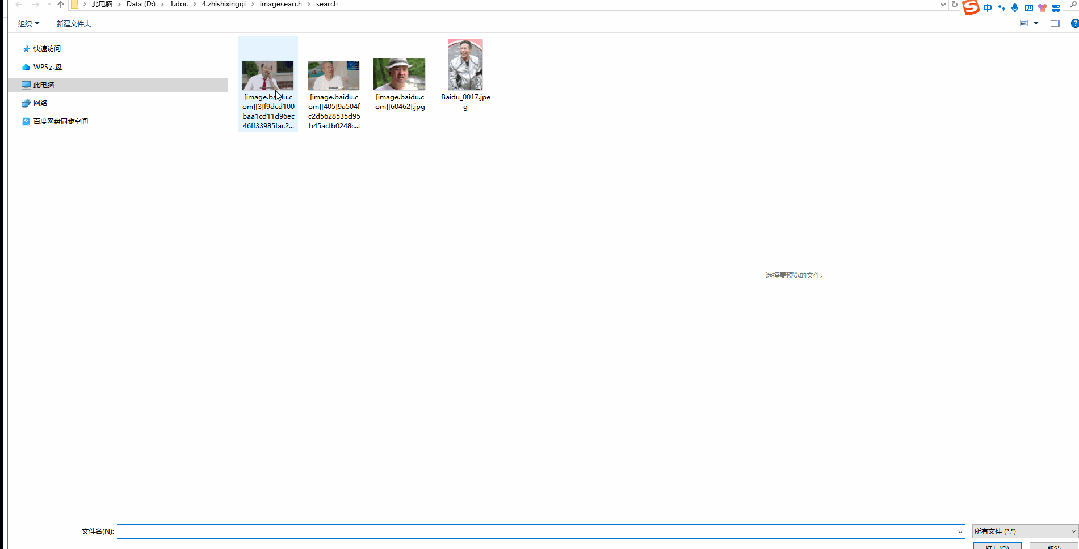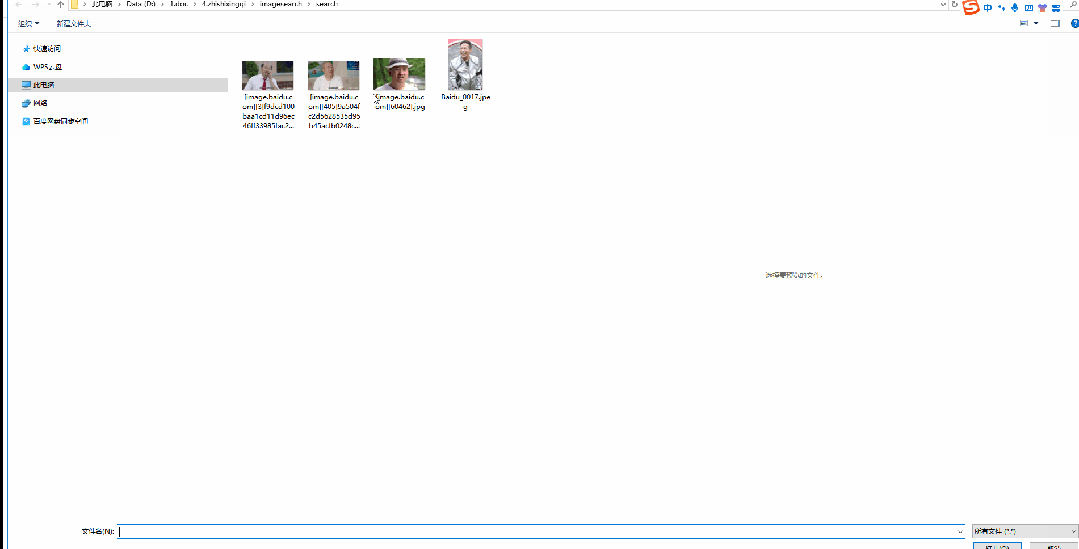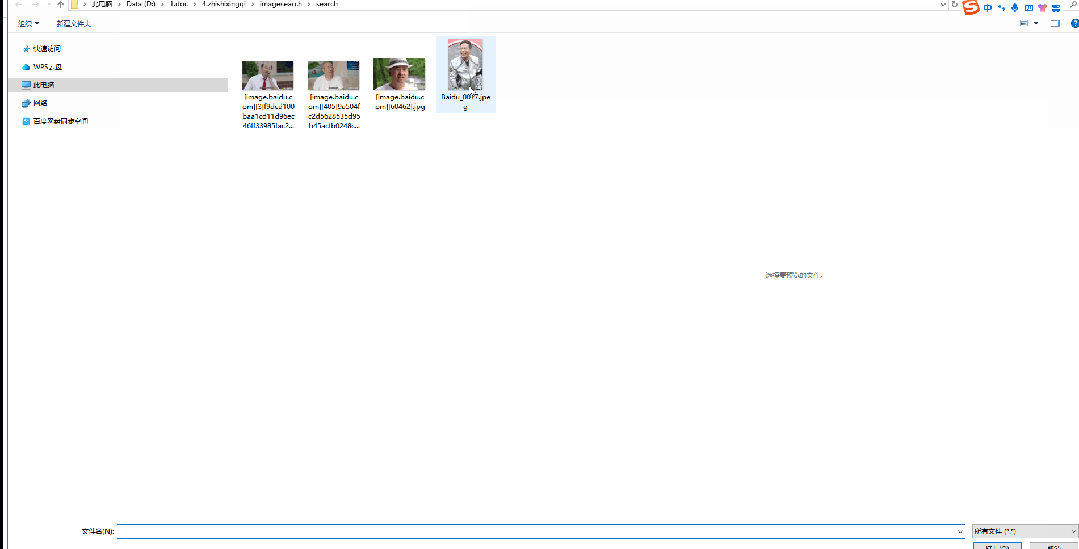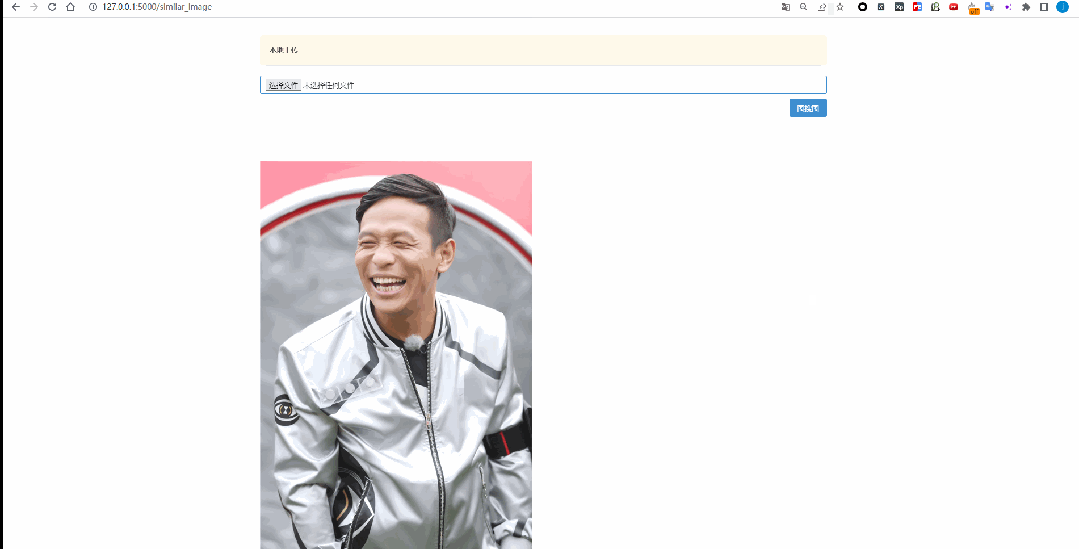 从基础到实践,回顾Elasticsearch 向量检索发展史_Elastic_04
从基础到实践,回顾Elasticsearch 向量检索发展史_Elastic_04
Elasticsearch 支持的第三方模型列表:
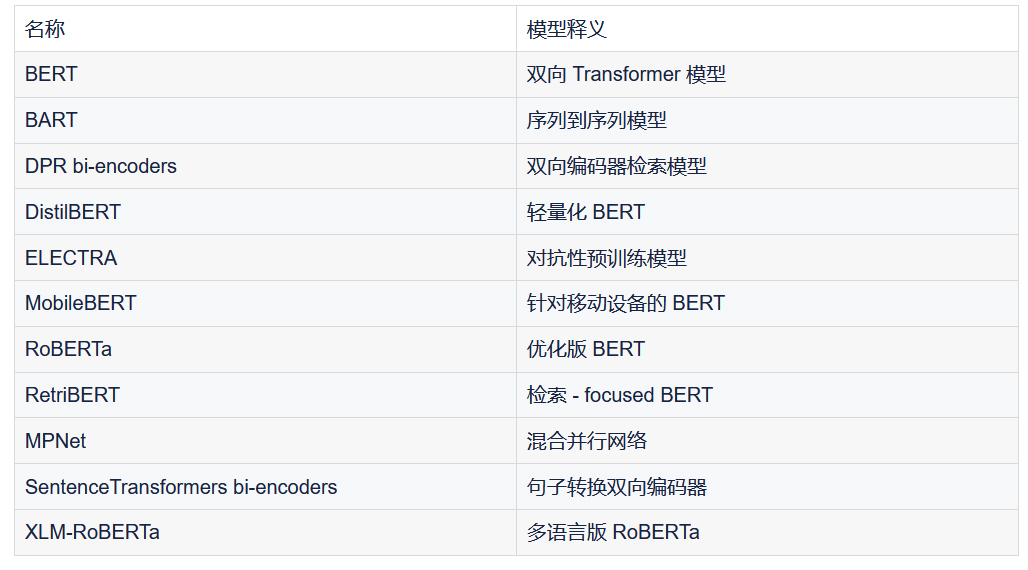
包括如下的 Hugging Face 模型库也都是支持的。
 从基础到实践,回顾Elasticsearch 向量检索发展史_elasticsearch_05
从基础到实践,回顾Elasticsearch 向量检索发展史_elasticsearch_05
模型是 Elasticsearch 与深度学习集成的核心,它能将复杂的数据转化为 “指纹” 向量,使搜索更高效和智能。借助模型,Elasticsearch 可以理解和匹配各种非结构化数据,如图像和声音,提供更为准确和个性化的搜索结果,同时适应不断变化的数据和需求。“没有了模型,我们还需要黑暗中摸索很久”。
第三方模型官网介绍:/guide/en/machine-learning/8.9/ml-nlp-model-ref.html#ml-nlp-model-ref-text-embedding
值得一提的是:Elasticsearch 导入大模型需要专属 Python 客户端工具 Eland。
Eland 是一个 Python Elasticsearch 客户端,让用户能用类似 Pandas 的 API 来探索和分析 Elasticsearch 中的数据,还支持从常见机器学习库上传训练好的模型到 Elasticsearch。
Eland 是为了与 Elasticsearch 协同工作而开发的库。它不是 Elasticsearch 的一个特定版本产物,而是作为一个独立的项目来帮助 Python 开发者更方便地在 Elasticsearch 中进行数据探索和机器学习任务。
Eland 更多参见:
/guide/en/elasticsearch/client/eland/current/index.html
https://www.php.cn/link/47e57c4836ae0c44f774f9d8497e0b4f
5.3 ESRE 是 Elastic 的未来
前一段时间在分别给两位阿里云、腾讯云大佬聊天的时候,都提到了 Elasticsearch Relevance Engine (ESRE) 才是 Elastic 未来。
ESRE 官方介绍如下:——Elasticsearch Relevance Engine 将 AI 的最佳实践与 Elastic 的文本搜索进行了结合。ESRE 为开发人员提供了一整套成熟的检索算法,并能够与大型语言模型 (LLM) 集成。借助 ESRE,我们可以应用具有卓越相关性的开箱即用型语义搜索,与外部大型语言模型集成,实现混合搜索,并使用第三方或我们自己的模型。
ESRE 集成了高级相关性排序如 BM25f、强大的矢量数据库、自然语言处理技术、与第三方模型如 GPT-3 和 GPT-4 的集成,并支持开发者自定义模型与应用。其特点在于提供深度的语义搜索,与专业领域的数据整合,以及无缝的生成式 AI 整合,让开发者能够构建更吸引人、更准确的搜索体验。
在 Elasticsearch 8.9 版本上新了:Semantic search 语义检索功能,对官方文档熟悉的同学,你会发现如下截图内容,早期版本是没有的。
语义搜索不是根据搜索词进行字面匹配,而是根据搜索查询的意图和上下文含义来检索结果。
更进一步讲:语义搜索不仅仅是匹配你输入的关键字,而是试图理解你的真正意图,给你带来更准确、更有上下文的搜索结果。简单来说,如果你在英国搜索 “football”,系统知道你可能想要搜橄榄球,而不是足球(在美国 football 是足球)。
这种智能搜索方式,得益于强大的文本向量化等技术背景,使我们的在线搜索体验更加直观、方便和满意。
在文本里检索 connection speed requirement, 这点属于早期的倒排索引检索方式,或者叫全文检索中的短语 match_phrase 检索匹配 或者分词 match 检索匹配。这种可以得到结果。但是,中后半段视频显示,要是咱们要检索:“How fast should my internet be” 怎么办?
其实这里转换为向量检索,fast 和 speed 语义相近,should be 和 required、needs 语义相近,internet 和 connection、wifi 语义相近。所以依然能召回结果。
这突破了传统同义词的限制,体现了语义检索的妙处!
更进一步,我们给出语义检索和传统分词检索的区别,以期望大家更好的理解语义搜索。
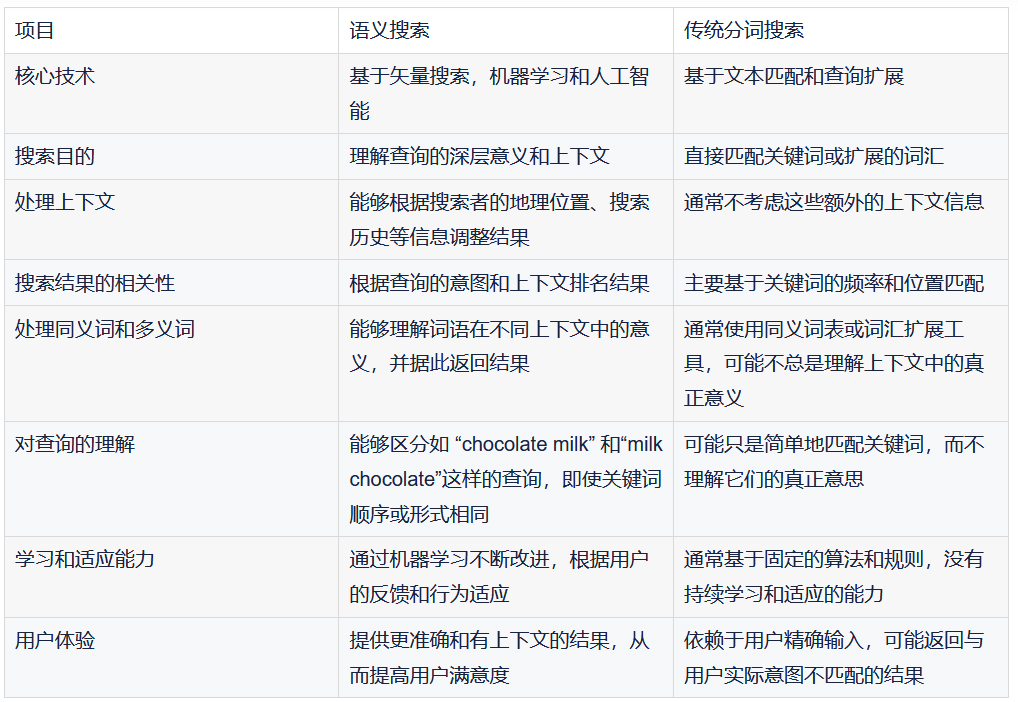
总体而言,深度学习集成已经成为 Elasticsearch 向量检索能力的有力补充,促使它在搜索和分析领域的地位更加牢固,同时也为未来的发展提供了广阔的空间。
6.小结
Elasticsearch 的向量检索从最初的简单实现发展到现在的高效、多功能解决方案,反映了现代搜索和推荐系统的需求和挑战。随着技术的不断演进,我们可以期待 Elasticsearch 在向量检索方面将继续推动创新和卓越。
说一下最近的感触,向量检索、大模型等新技术的出现有种感觉 “学不完,根本学不完”,并且很容易限于 “皮毛论”(我自创的词)——所有技术都了解一点点,但经不起提问;浅了说,貌似啥都懂,深了说,一问三不知。
这种情况怎么办?我目前的方法是:以实践为目的去深入理解理论,必要时理解算法,然后不定期将所看、所思、所想梳理成文,以备忘和知识体系化。这个过程很慢、很累,但我相信时间越长、价值越大。
欢迎大家就向量检索等问题进行留言讨论交流,你的问题很可能就是下一次文章的主题哦!
7.参考
1、/cn/blog/text-similarity-search-with-vectors-in-elasticsearch
2、/guide/en/elasticsearch/reference/7.3/query-dsl-script-score-query.html#vector-functions-cosine
3、https://www.php.cn/link/8b0bb3eff8c1e5bf7f206125959921d7
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1359
1359
 52
52

 Méthodes et étapes d'utilisation de BERT pour l'analyse des sentiments en Python
Jan 22, 2024 pm 04:24 PM
Méthodes et étapes d'utilisation de BERT pour l'analyse des sentiments en Python
Jan 22, 2024 pm 04:24 PM
BERT est un modèle de langage d'apprentissage profond pré-entraîné proposé par Google en 2018. Le nom complet est BidirectionnelEncoderRepresentationsfromTransformers, qui est basé sur l'architecture Transformer et présente les caractéristiques d'un codage bidirectionnel. Par rapport aux modèles de codage unidirectionnels traditionnels, BERT peut prendre en compte les informations contextuelles en même temps lors du traitement du texte, de sorte qu'il fonctionne bien dans les tâches de traitement du langage naturel. Sa bidirectionnalité permet à BERT de mieux comprendre les relations sémantiques dans les phrases, améliorant ainsi la capacité expressive du modèle. Grâce à des méthodes de pré-formation et de réglage fin, BERT peut être utilisé pour diverses tâches de traitement du langage naturel, telles que l'analyse des sentiments, la dénomination
 Analyse des fonctions d'activation de l'IA couramment utilisées : pratique d'apprentissage en profondeur de Sigmoid, Tanh, ReLU et Softmax
Dec 28, 2023 pm 11:35 PM
Analyse des fonctions d'activation de l'IA couramment utilisées : pratique d'apprentissage en profondeur de Sigmoid, Tanh, ReLU et Softmax
Dec 28, 2023 pm 11:35 PM
Les fonctions d'activation jouent un rôle crucial dans l'apprentissage profond. Elles peuvent introduire des caractéristiques non linéaires dans les réseaux neuronaux, permettant ainsi au réseau de mieux apprendre et simuler des relations entrées-sorties complexes. La sélection et l'utilisation correctes des fonctions d'activation ont un impact important sur les performances et les résultats de formation des réseaux de neurones. Cet article présentera quatre fonctions d'activation couramment utilisées : Sigmoid, Tanh, ReLU et Softmax, à partir de l'introduction, des scénarios d'utilisation, des avantages, Les inconvénients et les solutions d'optimisation sont abordés pour vous fournir une compréhension complète des fonctions d'activation. 1. Fonction sigmoïde Introduction à la formule de la fonction SIgmoïde : La fonction sigmoïde est une fonction non linéaire couramment utilisée qui peut mapper n'importe quel nombre réel entre 0 et 1. Il est généralement utilisé pour unifier le
 Au-delà d'ORB-SLAM3 ! SL-SLAM : les scènes de faible luminosité, de gigue importante et de texture faible sont toutes gérées
May 30, 2024 am 09:35 AM
Au-delà d'ORB-SLAM3 ! SL-SLAM : les scènes de faible luminosité, de gigue importante et de texture faible sont toutes gérées
May 30, 2024 am 09:35 AM
Écrit précédemment, nous discutons aujourd'hui de la manière dont la technologie d'apprentissage profond peut améliorer les performances du SLAM (localisation et cartographie simultanées) basé sur la vision dans des environnements complexes. En combinant des méthodes d'extraction de caractéristiques approfondies et de correspondance de profondeur, nous introduisons ici un système SLAM visuel hybride polyvalent conçu pour améliorer l'adaptation dans des scénarios difficiles tels que des conditions de faible luminosité, un éclairage dynamique, des zones faiblement texturées et une gigue importante. Notre système prend en charge plusieurs modes, notamment les configurations étendues monoculaire, stéréo, monoculaire-inertielle et stéréo-inertielle. En outre, il analyse également comment combiner le SLAM visuel avec des méthodes d’apprentissage profond pour inspirer d’autres recherches. Grâce à des expériences approfondies sur des ensembles de données publiques et des données auto-échantillonnées, nous démontrons la supériorité du SL-SLAM en termes de précision de positionnement et de robustesse du suivi.
 Intégration d'espace latent : explication et démonstration
Jan 22, 2024 pm 05:30 PM
Intégration d'espace latent : explication et démonstration
Jan 22, 2024 pm 05:30 PM
L'intégration d'espace latent (LatentSpaceEmbedding) est le processus de mappage de données de grande dimension vers un espace de faible dimension. Dans le domaine de l'apprentissage automatique et de l'apprentissage profond, l'intégration d'espace latent est généralement un modèle de réseau neuronal qui mappe les données d'entrée de grande dimension dans un ensemble de représentations vectorielles de basse dimension. Cet ensemble de vecteurs est souvent appelé « vecteurs latents » ou « latents ». encodages". Le but de l’intégration de l’espace latent est de capturer les caractéristiques importantes des données et de les représenter sous une forme plus concise et compréhensible. Grâce à l'intégration de l'espace latent, nous pouvons effectuer des opérations telles que la visualisation, la classification et le regroupement de données dans un espace de faible dimension pour mieux comprendre et utiliser les données. L'intégration d'espace latent a de nombreuses applications dans de nombreux domaines, tels que la génération d'images, l'extraction de caractéristiques, la réduction de dimensionnalité, etc. L'intégration de l'espace latent est le principal
 Comprendre en un seul article : les liens et les différences entre l'IA, le machine learning et le deep learning
Mar 02, 2024 am 11:19 AM
Comprendre en un seul article : les liens et les différences entre l'IA, le machine learning et le deep learning
Mar 02, 2024 am 11:19 AM
Dans la vague actuelle de changements technologiques rapides, l'intelligence artificielle (IA), l'apprentissage automatique (ML) et l'apprentissage profond (DL) sont comme des étoiles brillantes, à la tête de la nouvelle vague des technologies de l'information. Ces trois mots apparaissent fréquemment dans diverses discussions de pointe et applications pratiques, mais pour de nombreux explorateurs novices dans ce domaine, leurs significations spécifiques et leurs connexions internes peuvent encore être entourées de mystère. Alors regardons d'abord cette photo. On constate qu’il existe une corrélation étroite et une relation progressive entre l’apprentissage profond, l’apprentissage automatique et l’intelligence artificielle. Le deep learning est un domaine spécifique du machine learning, et le machine learning
 Super fort! Top 10 des algorithmes de deep learning !
Mar 15, 2024 pm 03:46 PM
Super fort! Top 10 des algorithmes de deep learning !
Mar 15, 2024 pm 03:46 PM
Près de 20 ans se sont écoulés depuis que le concept d'apprentissage profond a été proposé en 2006. L'apprentissage profond, en tant que révolution dans le domaine de l'intelligence artificielle, a donné naissance à de nombreux algorithmes influents. Alors, selon vous, quels sont les 10 meilleurs algorithmes pour l’apprentissage profond ? Voici les meilleurs algorithmes d’apprentissage profond, à mon avis. Ils occupent tous une position importante en termes d’innovation, de valeur d’application et d’influence. 1. Contexte du réseau neuronal profond (DNN) : Le réseau neuronal profond (DNN), également appelé perceptron multicouche, est l'algorithme d'apprentissage profond le plus courant lorsqu'il a été inventé pour la première fois, jusqu'à récemment en raison du goulot d'étranglement de la puissance de calcul. années, puissance de calcul, La percée est venue avec l'explosion des données. DNN est un modèle de réseau neuronal qui contient plusieurs couches cachées. Dans ce modèle, chaque couche transmet l'entrée à la couche suivante et
 Comment utiliser les modèles hybrides CNN et Transformer pour améliorer les performances
Jan 24, 2024 am 10:33 AM
Comment utiliser les modèles hybrides CNN et Transformer pour améliorer les performances
Jan 24, 2024 am 10:33 AM
Convolutional Neural Network (CNN) et Transformer sont deux modèles d'apprentissage en profondeur différents qui ont montré d'excellentes performances sur différentes tâches. CNN est principalement utilisé pour les tâches de vision par ordinateur telles que la classification d'images, la détection de cibles et la segmentation d'images. Il extrait les caractéristiques locales de l'image via des opérations de convolution et effectue une réduction de dimensionnalité des caractéristiques et une invariance spatiale via des opérations de pooling. En revanche, Transformer est principalement utilisé pour les tâches de traitement du langage naturel (NLP) telles que la traduction automatique, la classification de texte et la reconnaissance vocale. Il utilise un mécanisme d'auto-attention pour modéliser les dépendances dans des séquences, évitant ainsi le calcul séquentiel dans les réseaux neuronaux récurrents traditionnels. Bien que ces deux modèles soient utilisés pour des tâches différentes, ils présentent des similitudes dans la modélisation des séquences.
 Algorithme RMSprop amélioré
Jan 22, 2024 pm 05:18 PM
Algorithme RMSprop amélioré
Jan 22, 2024 pm 05:18 PM
RMSprop est un optimiseur largement utilisé pour mettre à jour les poids des réseaux de neurones. Il a été proposé par Geoffrey Hinton et al. en 2012 et est le prédécesseur de l'optimiseur Adam. L'émergence de l'optimiseur RMSprop vise principalement à résoudre certains problèmes rencontrés dans l'algorithme de descente de gradient SGD, tels que la disparition de gradient et l'explosion de gradient. En utilisant l'optimiseur RMSprop, le taux d'apprentissage peut être ajusté efficacement et les pondérations mises à jour de manière adaptative, améliorant ainsi l'effet de formation du modèle d'apprentissage en profondeur. L'idée principale de l'optimiseur RMSprop est d'effectuer une moyenne pondérée des gradients afin que les gradients à différents pas de temps aient des effets différents sur les mises à jour de poids. Plus précisément, RMSprop calcule le carré de chaque paramètre
