
 Périphériques technologiques
IA
LeCun a encore une fois dénigré le LLM autorégressif : la capacité de raisonnement de GPT-4 est très limitée, comme en témoignent deux articles
Périphériques technologiques
IA
LeCun a encore une fois dénigré le LLM autorégressif : la capacité de raisonnement de GPT-4 est très limitée, comme en témoignent deux articles
LeCun a encore une fois dénigré le LLM autorégressif : la capacité de raisonnement de GPT-4 est très limitée, comme en témoignent deux articles

"Quiconque pense que le LLM auto-régressif est déjà proche de l'IA au niveau humain, ou qu'il a juste besoin d'évoluer pour atteindre l'IA au niveau humain, doit lire ceci. L'AR-LLM a des capacités de raisonnement et de planification très limitées. Pour résoudre cela, le problème ne peut pas être résolu en les agrandissant et en s'entraînant avec plus de données. "
Yann LeCun, lauréat du prix Turing, est depuis longtemps un "questionnaire" du LLM, et le modèle autorégressif l'est. Le paradigme d'apprentissage sur lequel repose le modèle LLM de la série GPT. Il a exprimé publiquement ses critiques à l'égard de l'autorégression et du LLM à plusieurs reprises, et a produit de nombreuses phrases en or, telles que :
"Personne sensé n'utilisera des modèles autorégressifs dans 5 ans." "Les modèles génératifs auto-régressifs sont nuls!" LLM peut-il vraiment autocritique (et améliorer de manière itérative) ses solutions comme le suggère la littérature. Deux nouveaux articles de notre groupe sont le raisonnement (https : //arxiv.org/abs/2310.12397) et la planification (https://arxiv.org/) abs/2310.08118) Ces affirmations ont été étudiées (et remises en question)"
Il semble que ces deux-là. Le thème de cet article, qui étudie les capacités de vérification et d'autocritique de GPT-4, résonne auprès de nombreuses personnes.
Les auteurs de l'article ont déclaré qu'ils pensaient également que le LLM est un excellent « générateur d'idées » (que ce soit sous forme de langage ou de code), mais ils ne peuvent pas garantir leurs propres capacités de planification/raisonnement. Par conséquent, il est préférable de les utiliser dans un environnement LLM-Modulo (avec un raisonneur fiable ou un expert humain dans la boucle). L'autocritique nécessite une vérification, et la vérification est une forme de raisonnement (soyez donc surpris par toutes les affirmations sur la capacité de LLM à s'autocritique).
Dans le même temps, des voix du doute s'élèvent également : « Les capacités de raisonnement des réseaux convolutifs sont plus limitées, mais cela n'empêche pas les travaux d'AlphaZero d'émerger. RL). Je pense que les capacités du modèle permettent un raisonnement extrêmement approfondi (comme les mathématiques au niveau de la recherche). "

À cet égard, les pensées de LeCun sont les suivantes : "AlphaZero" exécute "le plan". Cela se fait via une recherche arborescente de Monte Carlo, en utilisant un réseau convolutif pour proposer de bonnes actions et un autre réseau convolutif pour évaluer la position. Le temps passé à explorer l'arbre pourrait être infini, c'est tout un raisonnement et une planification. "
À l'avenir, la question de savoir si le LLM autorégressif a des capacités de raisonnement et de planification pourrait ne pas être finalisée.
Ensuite, nous pouvons jeter un œil à ce dont parlent ces deux nouveaux articles.
Article 1 : GPT-4 ne sait pas que c'est faux : une analyse des incitations itératives pour les problèmes de raisonnement
Le premier article a amené les chercheurs à remettre en question la capacité d'autocritique de l'état de l'art. art LLM, y compris GPT-4.
Adresse de l'article : https://arxiv.org/pdf/2310.12397.pdf
Jetons ensuite un coup d'œil à l'introduction de l'article.
Il y a toujours eu un désaccord considérable sur les capacités d'inférence des grands modèles de langage (LLM). Au départ, les chercheurs étaient optimistes sur le fait que les capacités d'inférence des LLM apparaîtraient automatiquement à mesure que l'échelle du modèle augmentait. Dans de nombreux cas, les attentes des gens ne sont plus aussi fortes. Par la suite, les chercheurs ont généralement cru que le LLM avait la capacité d’autocritique et d’améliorer les solutions LLM de manière itérative, et ce point de vue a été largement diffusé.
Mais est-ce vraiment le cas ?
Des chercheurs de l'Arizona State University ont testé les capacités de raisonnement du LLM dans une nouvelle étude. Plus précisément, ils se sont concentrés sur l’efficacité des incitations itératives dans le problème de coloration des graphiques, l’un des problèmes NP-complets les plus connus.
Cette étude montre que (i) LLM n'est pas bon pour résoudre les instances de coloration de graphiques (ii) LLM n'est pas bon pour valider les solutions et est donc inefficace en mode itératif. Les résultats de cet article soulèvent donc des questions sur les capacités autocritiques des LLM de pointe.
L'article donne quelques résultats expérimentaux, par exemple, en mode direct, LLM est très mauvais pour résoudre les instances de coloration de graphiques. De plus, l'étude a également révélé que LLM n'est pas bon pour vérifier la solution. Pire encore, le système ne parvient pas à reconnaître la bonne couleur et se retrouve avec la mauvaise couleur.
La figure ci-dessous est une évaluation du problème de colorisation des graphiques. Dans ce contexte, GPT-4 peut deviner les couleurs de manière indépendante et autocritique. En dehors de la boucle autocritique, il existe un validateur vocal externe.
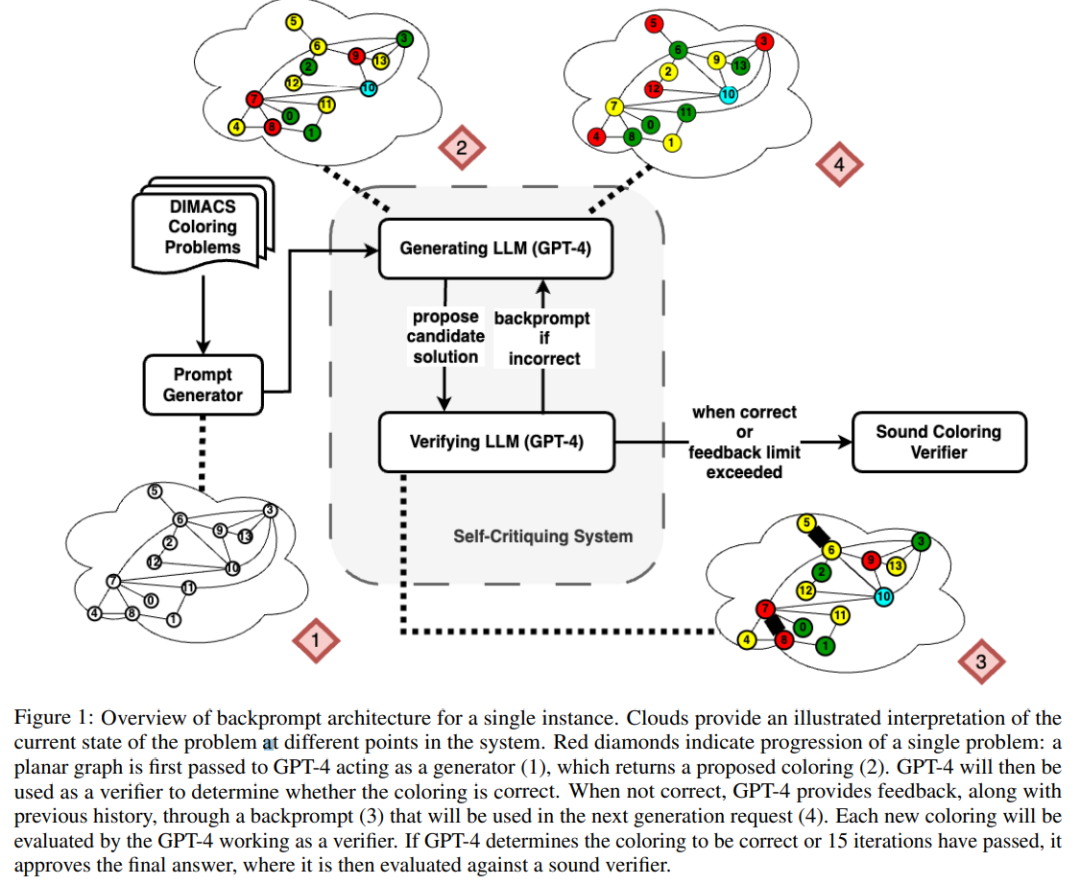
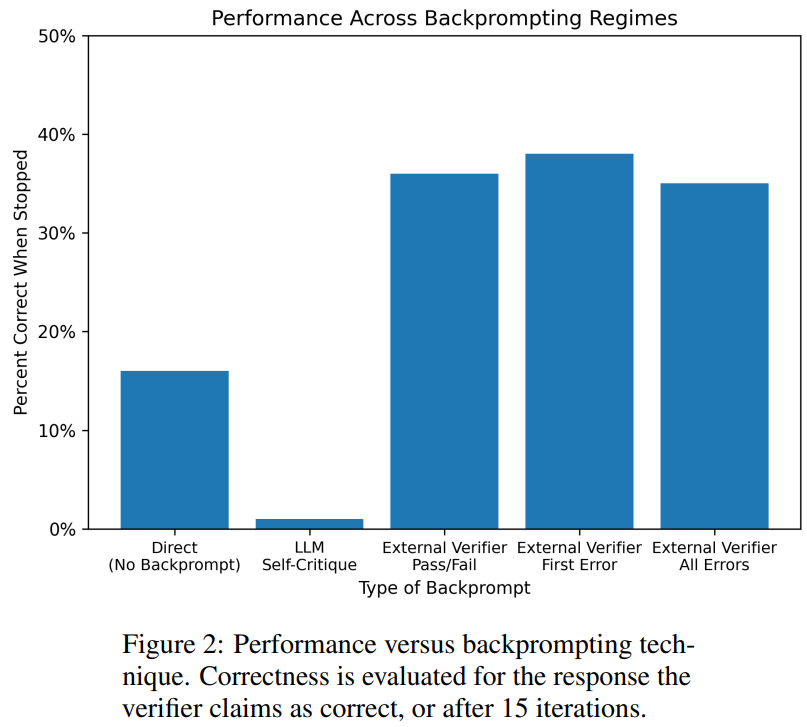
Les résultats montrent que GPT4 est précis à moins de 20 % pour deviner les couleurs, et plus surprenant, le mode d'autocritique (deuxième colonne de la figure ci-dessous) a la précision la plus faible. Cet article examine également la question connexe de savoir si GPT-4 améliorerait sa solution si un vérificateur vocal externe fournissait des critiques prouvées correctes sur les couleurs qu'il devine. Dans ce cas, les indications inversées peuvent réellement améliorer les performances.
Même si GPT-4 devine accidentellement une couleur valide, son autocritique peut lui faire halluciner qu'il n'y a pas de violation.
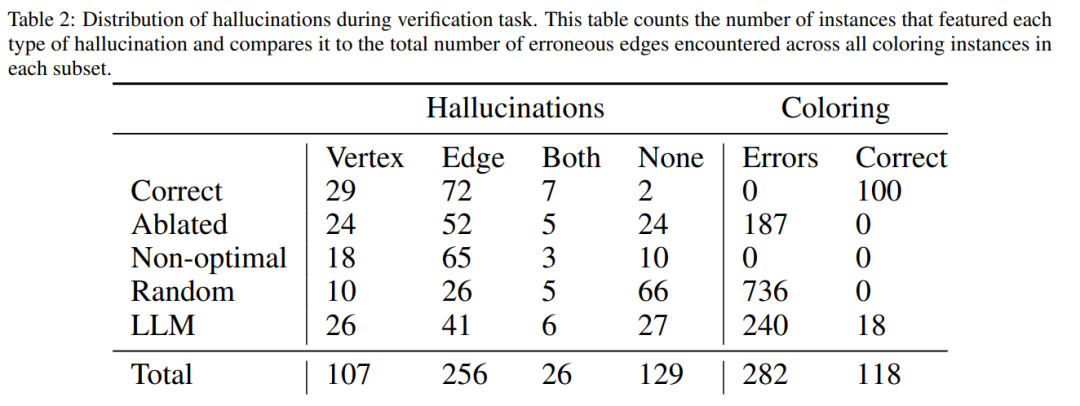
Enfin, l'auteur donne un résumé concernant le problème de coloration des graphiques :
- L'autocritique nuira en fait aux performances de LLM, car GPT-4 est terrible en vérification ; Les commentaires extérieurs du vérificateur peuvent en effet améliorer les performances du LLM.
- Article 2 : Les grands modèles linguistiques peuvent-ils vraiment s'améliorer en autocritiqueant leurs propres plans ?
Dans l'article "Les grands modèles linguistiques peuvent-ils vraiment s'améliorer en autocritiqueant leurs propres plans ?", la recherche équipe La capacité du LLM à s'auto-vérifier/critiquer dans des situations de planification a été explorée.
Cet article propose une étude systématique de la capacité des LLM à critiquer leurs propres résultats, en particulier dans le contexte de problèmes de planification classiques. Alors que des recherches récentes se montrent optimistes quant au potentiel autocritique des LLM, en particulier dans des contextes itératifs, cette étude suggère une perspective différente.
Adresse papier : https://arxiv.org/abs/2310.08118
Étonnamment, les résultats de la recherche montrent que l'autocritique peut réduire les performances de génération de plans, en particulier avec le vérificateur de validation externe et le LLM. systèmes de vérification. LLM peut produire un grand nombre de messages d'erreur, compromettant ainsi la fiabilité du système.
L'évaluation empirique des chercheurs sur le domaine classique de planification de l'IA Blocksworld souligne que la fonction d'autocritique de LLM n'est pas efficace pour planifier les problèmes. Le validateur peut générer un grand nombre d'erreurs, ce qui nuit à la fiabilité de l'ensemble du système, en particulier dans les domaines où l'exactitude de la planification est critique.
Fait intéressant, la nature du feedback (feedback binaire ou détaillé) n'a pas d'impact significatif sur les performances de génération du plan, ce qui suggère que le problème principal réside dans les capacités de vérification binaire de LLM plutôt que dans la granularité du feedback.
Comme le montre la figure ci-dessous, l'architecture d'évaluation de cette étude comprend 2 LLM - générateur LLM + vérificateur LLM. Pour une instance donnée, le générateur LLM est chargé de générer les plans candidats, tandis que le vérificateur LLM détermine leur exactitude. Si le plan s'avère incorrect, le validateur fournit un retour d'information indiquant la raison de son erreur. Ce retour d'information est ensuite transféré au générateur LLM, qui invite le générateur LLM à générer de nouveaux plans candidats. Toutes les expériences de cette étude ont utilisé GPT-4 comme LLM par défaut.
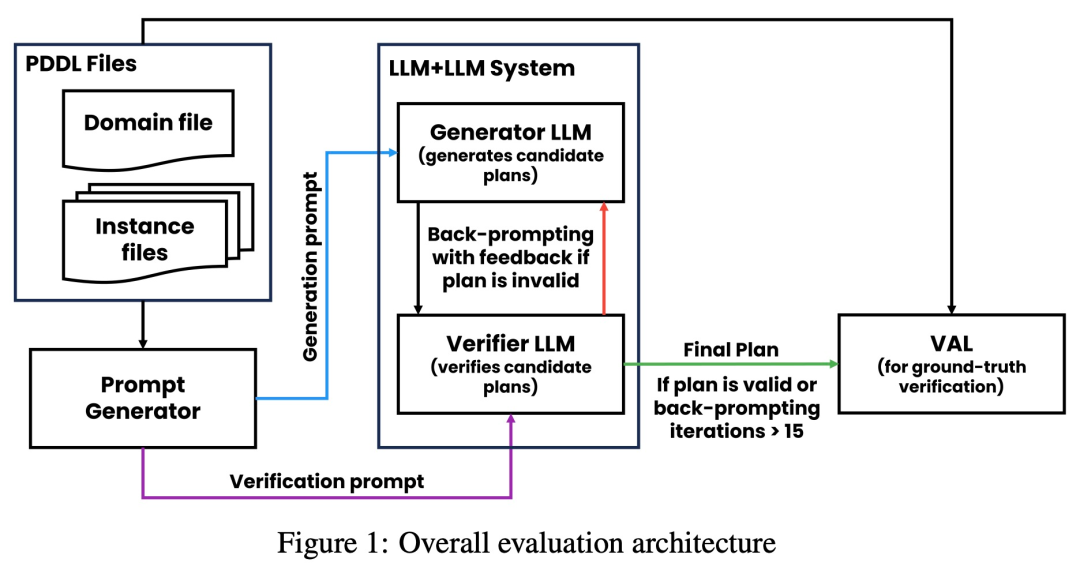
Cette étude expérimente et compare plusieurs méthodes de génération de plans sur Blocksworld. Plus précisément, l’étude a généré 100 instances aléatoires pour évaluer diverses méthodes. Pour fournir une évaluation réaliste de l'exactitude de la planification finale du LLM, l'étude utilise un validateur externe VAL.
Comme le montre le tableau 1, la méthode avec invite arrière LLM+LLM est légèrement meilleure que la méthode sans invite arrière en termes de précision.
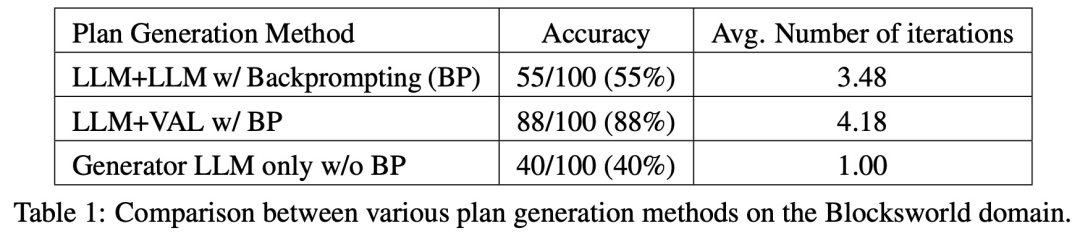
Sur 100 cas, le validateur en a identifié avec précision 61 (61%).
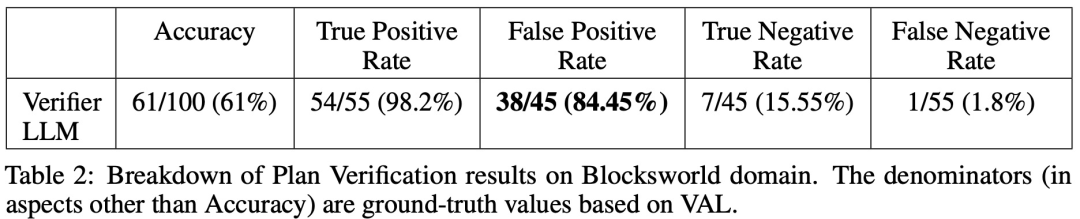
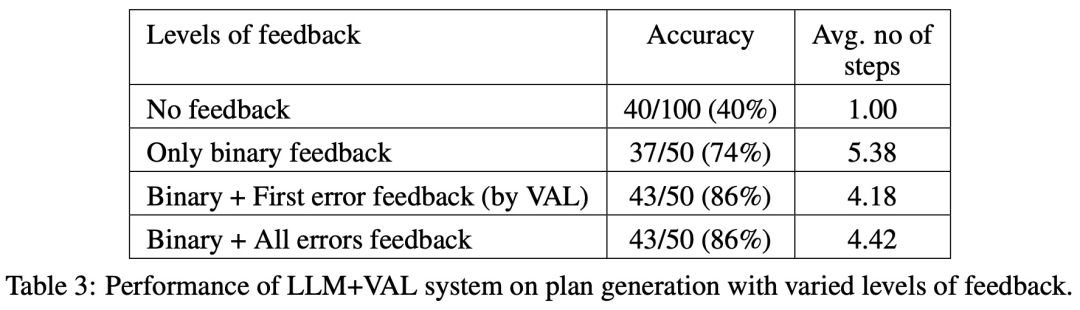
Le tableau ci-dessous montre les performances du LLM lors de la réception de différents niveaux de commentaires (y compris l'absence de commentaires).
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1359
1359
 52
52

 Comment utiliser les plumes PS pour créer des effets transparents?
Apr 06, 2025 pm 07:03 PM
Comment utiliser les plumes PS pour créer des effets transparents?
Apr 06, 2025 pm 07:03 PM
Méthode de production d'effet transparent: Utilisez l'outil de sélection et les plumes pour coopérer: sélectionnez les zones transparentes et les plumes pour adoucir les bords; Modifiez le mode de mélange de couche et l'opacité pour contrôler la transparence. Utilisez des masques et des plumes: Sélectionnez et des zones de plumes; Ajouter les masques de couche et la transparence de contrôle du gradient de niveaux de gris.
 Comment est la compatibilité du centrage d'images bootstrap
Apr 07, 2025 am 07:51 AM
Comment est la compatibilité du centrage d'images bootstrap
Apr 07, 2025 am 07:51 AM
Bootstrap Image Centering fait face à des problèmes de compatibilité. La solution est la suivante: Utilisez MX-Auto pour centrer l'image horizontalement pour l'affichage: Block. Le centrage vertical utilise des dispositions Flexbox ou Grid pour garantir que l'élément parent est centré verticalement pour aligner les éléments enfants. Pour la compatibilité du navigateur IE, utilisez des outils tels que AutoPrefixer pour ajouter automatiquement les préfixes du navigateur. Optimiser la taille de l'image, le format et l'ordre de chargement pour améliorer les performances de la page.
 Comment ajouter des icônes à la liste Bootstrap?
Apr 07, 2025 am 10:42 AM
Comment ajouter des icônes à la liste Bootstrap?
Apr 07, 2025 am 10:42 AM
Comment ajouter des icônes à la liste Bootstrap: fourre directement l'icône dans l'élément de liste & lt; li & gt;, en utilisant le nom de classe fourni par la bibliothèque d'icônes (comme Font Awesome). Utilisez la classe bootstrap pour aligner les icônes et le texte (par exemple, d-flex, justifier-content-between, align-items-center). Utilisez le composant Bootstrap Tag (badge) pour afficher les numéros ou l'état. Ajustez la position de l'icône (Flex-Direction: Row-Reverse;), Contrôlez le style (style CSS). Erreur commune: l'icône ne s'affiche pas (pas
 Comment changer la taille d'une liste de bootstrap?
Apr 07, 2025 am 10:45 AM
Comment changer la taille d'une liste de bootstrap?
Apr 07, 2025 am 10:45 AM
La taille d'une liste d'amorçage dépend de la taille du conteneur qui contient la liste, pas de la liste elle-même. L'utilisation du système de grille de bootstrap ou de Flexbox peut contrôler la taille du conteneur, redimentant ainsi indirectement les éléments de la liste.
 Que dois-je faire si la carte PS est dans l'interface de chargement?
Apr 06, 2025 pm 06:54 PM
Que dois-je faire si la carte PS est dans l'interface de chargement?
Apr 06, 2025 pm 06:54 PM
L'interface de chargement de la carte PS peut être causée par le logiciel lui-même (corruption de fichiers ou conflit de plug-in), l'environnement système (corruption du pilote ou des fichiers système en raison), ou matériel (corruption du disque dur ou défaillance du bâton de mémoire). Vérifiez d'abord si les ressources informatiques sont suffisantes, fermez le programme d'arrière-plan et publiez la mémoire et les ressources CPU. Correction de l'installation de PS ou vérifiez les problèmes de compatibilité pour les plug-ins. Mettre à jour ou tomber la version PS. Vérifiez le pilote de la carte graphique et mettez-le à jour et exécutez la vérification du fichier système. Si vous résumez les problèmes ci-dessus, vous pouvez essayer la détection du disque dur et les tests de mémoire.
 Comment implémenter la nidification des listes de bootstrap?
Apr 07, 2025 am 10:27 AM
Comment implémenter la nidification des listes de bootstrap?
Apr 07, 2025 am 10:27 AM
Les listes imbriquées dans Bootstrap nécessitent l'utilisation du système de grille de bootstrap pour contrôler le style. Tout d'abord, utilisez la couche extérieure & lt; ul & gt; et & lt; li & gt; Pour créer une liste, alors enveloppez la liste des calques intérieure dans & lt; div class = & quot; row & gt; et ajouter & lt; div class = & quot; col-md-6 & quot; & gt; à la liste des calques intérieure pour spécifier que la liste des calques intérieure occupe la moitié de la largeur d'une ligne. De cette façon, la liste intérieure peut avoir la bonne
 Quelle méthode est utilisée pour convertir les chaînes en objets dans vue.js?
Apr 07, 2025 pm 09:39 PM
Quelle méthode est utilisée pour convertir les chaînes en objets dans vue.js?
Apr 07, 2025 pm 09:39 PM
Lors de la conversion des chaînes en objets dans vue.js, JSON.Parse () est préféré pour les chaînes JSON standard. Pour les chaînes JSON non standard, la chaîne peut être traitée en utilisant des expressions régulières et réduisez les méthodes en fonction du format ou du codé décodé par URL. Sélectionnez la méthode appropriée en fonction du format de chaîne et faites attention aux problèmes de sécurité et d'encodage pour éviter les bogues.
 Quelle est la différence entre les plumes et les floues de PS?
Apr 06, 2025 pm 07:18 PM
Quelle est la différence entre les plumes et les floues de PS?
Apr 06, 2025 pm 07:18 PM
Il existe des différences dans les deux principales technologies de traitement d'image: les plumes et le flou. La plume adoucit principalement les bords durs de l'image et crée un effet de gradient naturel en modifiant la transparence ou l'opacité, qui convient aux scènes telles que les découpes et la synthèse. Le flou réduira la netteté globale de l'image et rendra les détails moins évidents. Il est souvent utilisé pour créer une conception artistique floue, brouiller l'arrière-plan ou réduire le bruit de l'image.
