
 Périphériques technologiques
IA
Comment implémenter avec élégance la reconnaissance de position radar FMCW (IROS2023)
Périphériques technologiques
IA
Comment implémenter avec élégance la reconnaissance de position radar FMCW (IROS2023)
Comment implémenter avec élégance la reconnaissance de position radar FMCW (IROS2023)

Bonjour à tous, je m'appelle Yuan Jianhao et je suis très heureux de venir sur la plateforme Heart of Autonomous Driving pour partager nos travaux sur la reconnaissance de position radar à l'IROS2023.
Le positionnement à l'aide d'un radar à ondes continues modulées en fréquence (FMCW) suscite de plus en plus d'attention en raison de sa résistance inhérente aux environnements difficiles. Cependant, les artefacts complexes du processus de mesure radar nécessitent des estimations d’incertitude appropriées pour garantir une application sûre et fiable de cette modalité de capteur prometteuse. Dans ce travail, nous proposons un système de gestion de cartes multi-sessions qui construit une carte « optimale » basée sur les propriétés de variance apprises dans l'espace d'intégration pour une localisation ultérieure. En utilisant la même propriété de variance, nous proposons également une nouvelle méthode pour rejeter de manière introspective les requêtes de positionnement qui pourraient être incorrectes. À cette fin, nous appliquons un apprentissage métrique robuste tenant compte du bruit qui exploite à la fois les variations à court terme des données radar le long du trajet (pour l'augmentation des données) et prédit les incertitudes en aval dans l'identification de position métrique basée sur l'espace. Nous démontrons l'efficacité de notre approche grâce à des tests approfondis de validation croisée sur les ensembles de données Oxford Radar RobotCar et MulRan. Ici, nous dépassons l'état de l'art actuel en matière d'identification de position radar et d'autres méthodes tenant compte de l'incertitude en utilisant une seule requête du voisin le plus proche. Nous montrons également une augmentation des performances dans un environnement de test difficile lors du rejet de requêtes basées sur l'incertitude, ce que nous n'avons pas observé avec les systèmes concurrents de reconnaissance de localisation prenant en compte l'incertitude.
Le point de départ du radar
La reconnaissance de position et la localisation sont des tâches importantes dans le domaine de la robotique et des systèmes autonomes, car elles permettent aux systèmes de comprendre et de naviguer dans leur environnement. Les méthodes traditionnelles de reconnaissance de localisation basées sur la vision sont souvent sensibles aux changements des conditions environnementales, telles que l'éclairage, la météo et l'occlusion, ce qui entraîne une dégradation des performances. Pour résoudre ce problème, l’utilisation du radar FMCW comme alternative de capteur robuste dans cet environnement conflictuel suscite un intérêt croissant.
Les travaux existants ont démontré l'efficacité des méthodes d'extraction de caractéristiques artisanales et basées sur l'apprentissage pour la reconnaissance de position radar FMCW. Malgré le succès des travaux existants, le déploiement de ces méthodes dans des applications critiques pour la sécurité telles que la conduite autonome est encore limitée par les estimations de l'incertitude d'étalonnage. Dans ce domaine, les points suivants doivent être pris en compte :
- La sécurité nécessite que les estimations d'incertitude soient bien calibrées avec des taux de faux positifs afin de permettre un rejet introspectif.
- Le déploiement en direct nécessite une capacité d'inférence rapide basée sur l'incertitude ; Les parcours répétés d'itinéraires en autonomie à long terme nécessitent une maintenance cartographique continue en ligne.
Présentation du processus système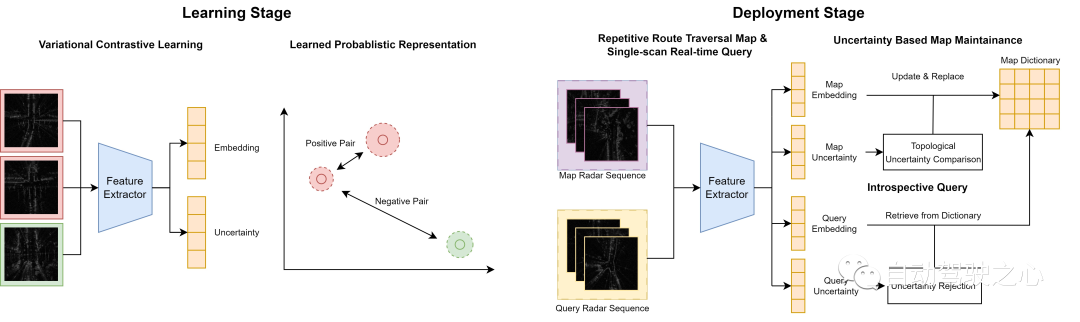
Introduction à la méthode Off the Radar
Cet article présente un cadre d'apprentissage variationnel contrastif pour l'identification de position radar afin de décrire l'incertitude dans l'identification de position. Les principales contributions comprennent :- Cadre d'apprentissage contrastif prenant en compte l'incertitude.
- Mécanisme de requête introspectif basé sur les estimations de l'incertitude d'étalonnage.
- Maintenance récursive de cartes en ligne pour des environnements changeants.
Apprentissage contrastif variationnel
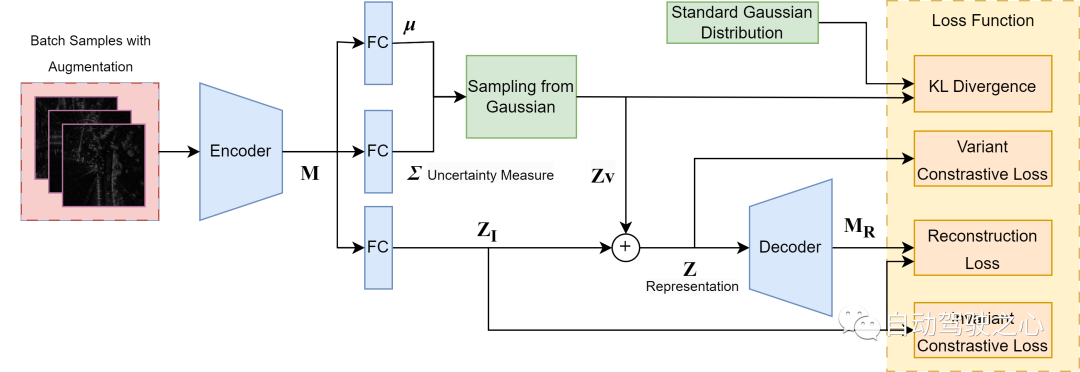
Les travaux de cette section sont à la fois un élément clé de notre contribution principale et une nouvelle intégration de l'apprentissage métrique variationnel profond avec la reconnaissance de position radar, ainsi qu'une nouvelle façon de caractériser l'incertitude dans la reconnaissance de position. Comme le montre la figure, nous adoptons une structure pour décomposer le balayage radar en une partie variable induite par le bruit, qui capture la variance des sources d'incertitude sans rapport avec la prédiction, et une partie sémantiquement invariante pour la représentation de la scène. La partie variable est ensuite échantillonnée à partir d'une distribution gaussienne carrée égale multivariée préalable et ajoutée à la partie d'invariance pour former la représentation globale. La sortie variable est utilisée directement comme mesure d’incertitude. Nous supposons que nous considérons uniquement les incertitudes aléatoires dans les prédictions du modèle, causées par le flou et le caractère aléatoire inhérents aux données, comme principale source d'incertitude. Surtout pour les analyses radar, cela peut être dû au bruit de chatoiement, à la saturation et aux occlusions temporaires. Les méthodes d'apprentissage métriques standard, quelle que soit la fonction de perte choisie, ont tendance à forcer des plongements identiques entre des paires d'exemples positifs tout en ignorant la variance potentielle entre eux. Cependant, cela peut rendre le modèle insensible aux petites fonctionnalités et surajuster la distribution de formation. Par conséquent, pour modéliser la variance du bruit, nous utilisons la variance probabiliste supplémentaire obtenue dans la structure pour estimer l'incertitude aléatoire. Pour construire une telle représentation radar sensible au bruit, nous utilisons quatre fonctions de perte pour guider la formation globale.
1) Perte de contraste invariante sur la représentation déterministe (Z_I) pour séparer le bruit non pertinent pour la tâche de la sémantique radar afin que l'intégration invariante contienne suffisamment d'informations causales et
2) Perte de contraste variable Sur la représentation globale (Z ; ), établir un espace métrique significatif. Les deux pertes de contraste prennent la forme suivante.
L'un des lots se compose de m échantillons et d'une augmentation de trame de rotation synthétique approchée temporellement en utilisant la stratégie de « rotation », qui est simplement une augmentation de rotation, pour l'invariance de rotation. Notre objectif est de maximiser la probabilité qu'un échantillon augmenté soit reconnu comme l'instance d'origine, tout en minimisant la probabilité d'un cas d'inversion.
où l'intégration ( Z ) est ( Z_I ) ou ( Z ) comme décrit dans les équations 1) et 2).
3) Divergence Kullback – Leibler (KL) Entre la distribution gaussienne apprise et la distribution gaussienne multivariée isotrope standard, c'est notre hypothèse a priori de bruit de données. Cela garantit la même répartition du bruit sur tous les échantillons et fournit une référence statique pour la valeur absolue de la sortie variable.
4) La perte de reconstruction se situe entre la carte de caractéristiques extraite (M) et la sortie du décodeur (M_R), ce qui oblige la représentation globale (Z) à contenir suffisamment d'informations du balayage radar d'origine pour être reconstruite. Cependant, nous reconstruisons uniquement une carte de caractéristiques de dimension inférieure au lieu d'une reconstruction par balayage radar au niveau des pixels afin de réduire le coût de calcul dans le processus de décodage.
Bien que la structure VAE ordinaire pilotée uniquement par la divergence KL et la perte de reconstruction fournisse également une variance latente, elle est considérée comme peu fiable pour l'estimation de l'incertitude en raison de ses problèmes bien connus d'effondrement postérieur et de disparition de la variance. Cette inefficacité est principalement due au déséquilibre des deux pertes lors de l'entraînement : lorsque la divergence KL domine, l'espace latent postérieur est forcé d'égaler l'a priori, tandis que lorsque la perte de reconstruction domine, la variance latente est poussée à zéro. Cependant, dans notre approche, nous obtenons une formation plus stable en introduisant une perte contrastive variable comme régularisateur supplémentaire, où la variance est pilotée pour maintenir des limites robustes entre les centres de cluster dans l'espace métrique. En conséquence, nous obtenons une variance spatiale sous-jacente plus fiable qui reflète l’incertitude aléatoire sous-jacente dans la perception radar. Nous choisissons de démontrer les avantages de notre approche spécifique de l’apprentissage de l’incertitude dans un contexte de perte croissante de fonctionnalités. Dans ce domaine, les techniques de pointe pour la reconnaissance de position radar utilisent déjà des pertes avec de nombreux (c'est-à-dire plus de 2) échantillons négatifs, nous élargissons donc cette base.
Maintenance continue de la carte
La maintenance continue de la carte est une caractéristique importante des systèmes en ligne, car nous visons à utiliser pleinement les données numérisées obtenues lors du fonctionnement des véhicules autonomes et à améliorer la carte de manière récursive. Le processus de fusion de nouveaux scans radar dans une carte parent composée de scans précédemment parcourus est le suivant. Chaque balayage radar est représenté par une représentation cachée et une métrique d'incertitude. Au cours du processus de fusion, nous recherchons des échantillons positifs correspondants pour chaque nouvelle analyse avec une distance topologique inférieure à un seuil. Si le nouveau scan présente une incertitude plus faible, il est intégré à la carte parent et remplace le scan correspondant, sinon il est rejeté.
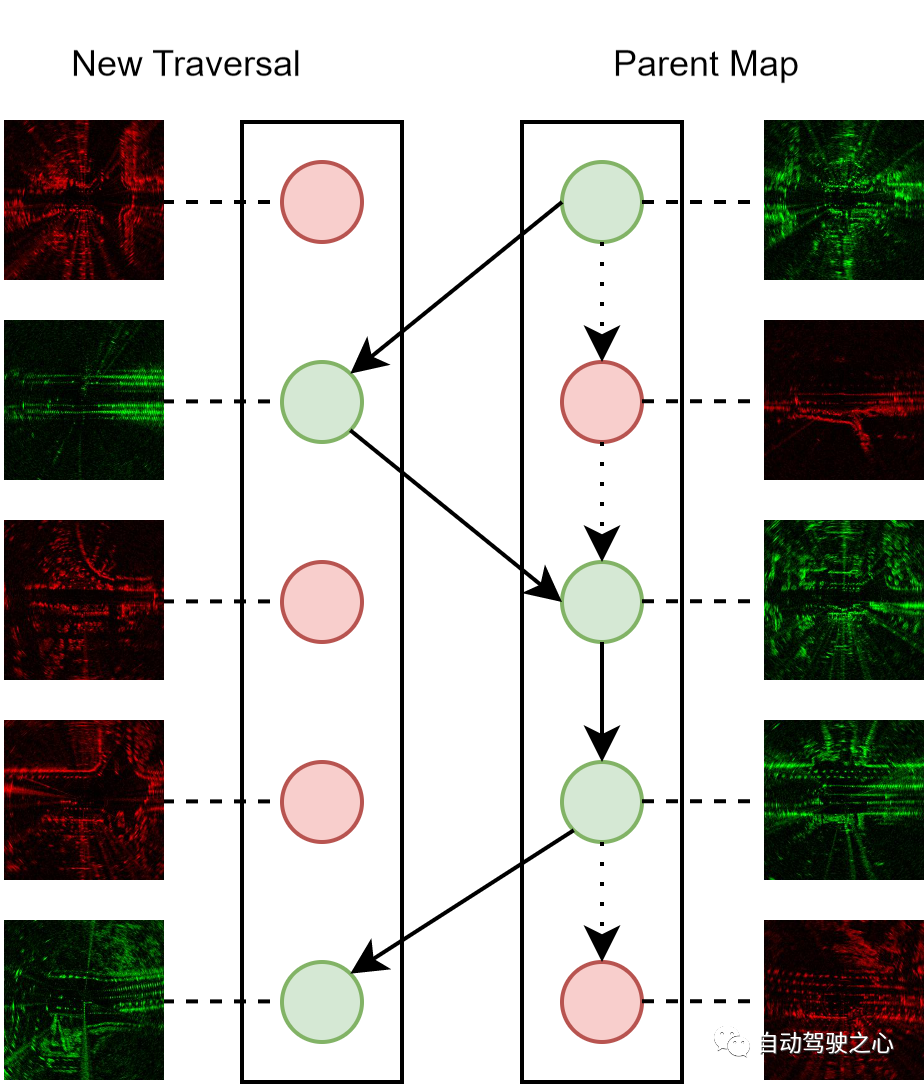
Diagramme schématique de la maintenance de la carte : les nœuds rouges et verts représentent des balayages radar avec respectivement des incertitudes supérieures et inférieures. Nous conservons toujours une carte parent comme référence de positionnement pour chaque emplacement, composée uniquement de scans avec la plus faible incertitude. Notez que les bords en pointillés représentent l'état initial de la carte parent et que les bords pleins représentent les versions mises à jour de la carte parent.
En effectuant de manière itérative le processus de maintenance, nous pouvons progressivement améliorer la qualité de la carte parent intégrée. Par conséquent, l'algorithme de maintenance peut servir de stratégie de déploiement en ligne efficace car il exploite en permanence plusieurs expériences du même parcours d'itinéraire pour améliorer les performances de reconnaissance tout en maintenant une taille de carte parent constante, ce qui entraîne des coûts de calcul et de stockage budgétisés.
Requête introspective
En raison de l'incertitude du modèle avec les mesures de la distribution gaussienne standard, la variance estimée dans toutes les dimensions est proche de 1. Par conséquent, nous pouvons définir entièrement l’échelle et la résolution du rejet de l’incertitude à l’aide de deux hyperparamètres, Delta et N. Le seuil résultant T est défini comme suit :
Étant donné une analyse avec une variance latente à m dimensions, nous faisons une moyenne sur toutes les dimensions, ce qui donne une mesure d'incertitude scalaire
Rejet de prédiction
Au moment de l'inférence, nous effectuons une introspection Rejet de requête , les analyses de requête dont la variance est supérieure à un seuil défini seront rejetées pour identification. Les méthodes existantes, telles que STUN et MC Dropout, divisent dynamiquement la plage d'incertitude d'un lot d'échantillons en niveaux seuils. Cependant, cela nécessite plusieurs échantillons lors de l'inférence et peut conduire à des performances de rejet instables, en particulier lorsqu'il n'y a qu'un petit nombre d'échantillons. En revanche, notre stratégie de seuillage statique fournit des niveaux de seuil indépendants de l’échantillon et fournit une estimation et un rejet cohérents de l’incertitude et du rejet en une seule analyse. Cette fonctionnalité est essentielle pour le déploiement en temps réel des systèmes de reconnaissance de localisation, puisque les balayages radar sont acquis image par image pendant la conduite.
Détails expérimentaux
Cet article utilise deux ensembles de données : 1) Oxford Radar RobotCar et 2) MulRan. Les deux ensembles de données utilisent le radar à balayage CTS350-X Navtech FMCW. Le système radar fonctionne dans la plage de 76 à 77 GHz et peut générer jusqu'à 3 768 lectures de plage avec une résolution de 4,38 cm. Les performances de reconnaissance du
benchmark se font en comparant avec plusieurs méthodes existantes, dont le VAE original, la méthode d'identification de site radar de pointe proposée par Gaddet al appelée BCRadar) , et la méthode RingKey sans apprentissage (qui fait partie de ScanContext, sans raffinement de rotation). De plus, les performances sont comparées à celles de MC Dropout et STUN, qui servent de référence pour la reconnaissance de lieux tenant compte de l'incertitude.
Étude d'ablationPour évaluer l'efficacité de nos modules de requête introspective (Q) et de maintenance de carte (M) proposés, nous avons mené une étude d'ablation en comparant différentes variantes de notre méthode, notées respectivement OURS(O/M) /Q /QM), les détails sont les suivants :
- O : Pas de maintenance de la carte, pas de requête d'introspection
- M : Seule la maintenance de la carte
- Q : Seule la requête d'introspection
- QM : La maintenance de la carte et la requête d'introspection sont spécifiques à , nous avons comparé les performances d'identification entre O et M et les performances d'estimation de l'incertitude entre Q et QM.
Paramètres communsPour garantir une comparaison équitable, nous adoptons une perte contrastive par lots commune pour toutes les méthodes basées sur l'apprentissage contrastif, ce qui entraîne une fonction de perte cohérente entre les tests de référence.
Détails de mise en œuvre
Configuration du scan
Pour toutes les méthodes, nous convertissons les scans radar polaires avec A = 400 relèvements et B = 3768 grilles en scans cartésiens, avec chaque taille de boîte de 4,38 cm, avec W = longueur de côté de 256 et une taille de boîte de 0,5 m.
Hyperparamètres de formation
Nous utilisons VGG-19 [^simonyan2014very^] comme extracteur de caractéristiques d'arrière-plan et utilisons une couche linéaire pour projeter les caractéristiques extraites dans une dimension d'intégration inférieure d=128. Nous avons formé toutes les lignes de base pendant 10 époques dans Oxford Radar RobotCar et 15 itérations dans MulRan avec un taux d'apprentissage de 1e{-5} et une taille de lot de 8.
Métriques d'évaluation
Pour évaluer les performances de reconnaissance de lieu, nous utilisons Recall@N (R@N)Recall@N (R@N) 指标,这是通过确定在 N 个候选者中是否至少有一个候选者接近 GPS/INS 所指示的地面真实值来确定的本地化的准确性。这对于自动驾驶应用中的安全保证尤为重要,因为它反映了系统对假阴性率的校准。我们还使用 Average Precision (AP) 来测量所有召回级别的平均精度。最后,我们使用 F-scores 与 beta=2/1/0.5 来分配召回对精确度的重要性级别,作为评估整体识别性能的综合指标。
此外,为了评估不确定性估计性能。我们使用 Recall@RR,在这里我们执行内省查询拒绝,并在不同的不确定性阈值级别上评估 Recall@N=1 -- 拒绝所有查询的扫描的不确定性大于阈值的。我们因此拒绝了 0-100% 的查询。
结果总结
地点识别性能
如 Oxford Radar RobotCar实验中表格1所示,我们的方法仅使用度量学习模块,在所有指标上都取得了最高的性能。具体来说,在 Recall@1 方面,我们的方法 OURS(O) 展示了通过变分对比学习框架学习的方差解耦表示的有效性,实现了超过 90.46% 的识别性能。这进一步得到了 MulRan 实验结果的支持,如表2所示,我们的方法在 Recall@1、总体 F-scores 和 AP 上均优于其他所有方法。尽管在 MulRan 实验中,VAE 在 Recall@5/10 上优于我们的方法,但我们的方法在两种设置中的最佳 F-1/0.5/2 和 AP Indicateur, qui détermine s'il y a au moins un candidat parmi N candidats. La précision de localisation est déterminée en se rapprochant de la vérité terrain indiquée par GPS/INS. Ceci est particulièrement important pour l'assurance de la sécurité dans les applications de conduite autonome, car cela reflète l'étalonnage du système du taux de faux négatifs. Nous utilisons également
Average Precision (AP) 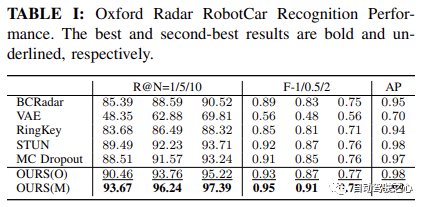 pour mesurer la précision moyenne de tous les niveaux de rappel. Enfin, nous utilisons
pour mesurer la précision moyenne de tous les niveaux de rappel. Enfin, nous utilisons
F-scores et
beta=2/1/0.5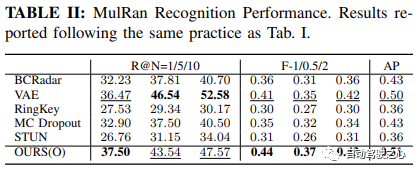
Recall@RR, où nous effectuons un rejet de requête introspectif et évaluons à différents niveaux de seuil d'incertitude 🎜 🎜Recall@N=1🎜 🎜-- Rejeter Toutes les requêtes sont analysées avec une incertitude plus grande que le seuil. En conséquence, nous rejetons 0 à 100 % des requêtes. 🎜🎜Résumé des résultats🎜
🎜🎜Performances de reconnaissance de lieux🎜🎜🎜Comme le montre le tableau 1 de l'expérience Oxford Radar RobotCar, notre méthode a obtenu les performances les plus élevées sur toutes les métriques en utilisant uniquement le module d'apprentissage des métriques. Plus précisément, dans 🎜 🎜Recall@1🎜 🎜En termes de performances, notre méthode OURS(O) démontre l'efficacité de la représentation découplée de variance apprise via un cadre d'apprentissage variationnel contrastif, atteignant plus de 90,46 % de performances de reconnaissance. Ceci est également étayé par les résultats expérimentaux de 🎜 🎜MulRan🎜 🎜Comme le montre le tableau 2, notre méthode présente les avantages suivants : -radius : 4px ; block;">Recall@1, dans l'ensemble 🎜 🎜F-scores🎜 🎜 et 🎜 🎜AP🎜 🎜 est supérieur à toutes les autres méthodes. Bien que dans l'expérience 🎜 🎜MulRan🎜 🎜, le VAE a mieux fonctionné dans 🎜 🎜Recall@5/10 🎜 🎜 surpasse notre méthode, mais notre méthode est la meilleure des deux paramètres 🎜 🎜Recall@1Recall@1 进一步提高到 93.67%,超过了当前最先进的方法 STUN,超出了 4.18%。这进一步证明了学习方差作为一个有效的不确定性度量,以及基于不确定性的地图集成策略在提高地点识别性能方面的有效性。
不确定性估计性能
随着被拒绝的不确定查询的百分比增加,识别性能的变化,特别是 Recall@1,在 Oxford Radar RobotCar 实验中如图1所示,在 MulRan 实验中如图2所示。值得注意的是,我们的方法是唯一一个在两种实验设置中都展示出随着不确定查询拒绝率增加而持续改进的识别性能的方法。在MulRan实验中,OURS(Q) 是唯一一个随着拒绝率增加而持续平稳地提高 Recall@RR 指标的方法。与 VAE 和 STUN 相比,这两种方法也像我们的方法一样估计了模型的不确定性,OURS(Q) 在 Recall@RR=0.1/0.2/0.5 上实现了 +(1.32/3.02/8.46)% 的改进,而 VAE 和 STUN 分别下降了 -(3.79/5.24/8.80)% 和 -(2.97/4.16/6.30)%。
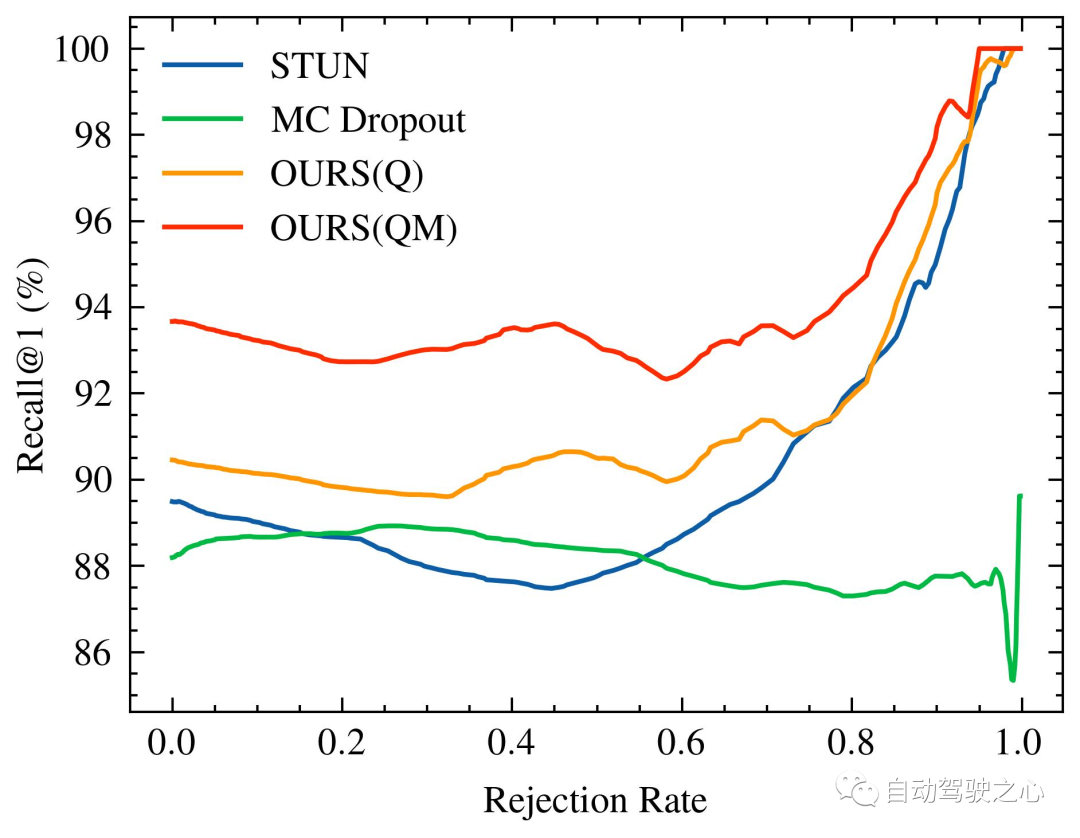
Oxford Radar RobotCar的内省查询拒绝性能。随着被拒绝的不确定查询的百分比增加,Recall@1增加/减少。由于 VAE 的性能与其他方法相比较低(具体为Recall@RR=0.1/0.2/0.5的 (48.42/48.08/18.48)%),因此没有进行可视化。
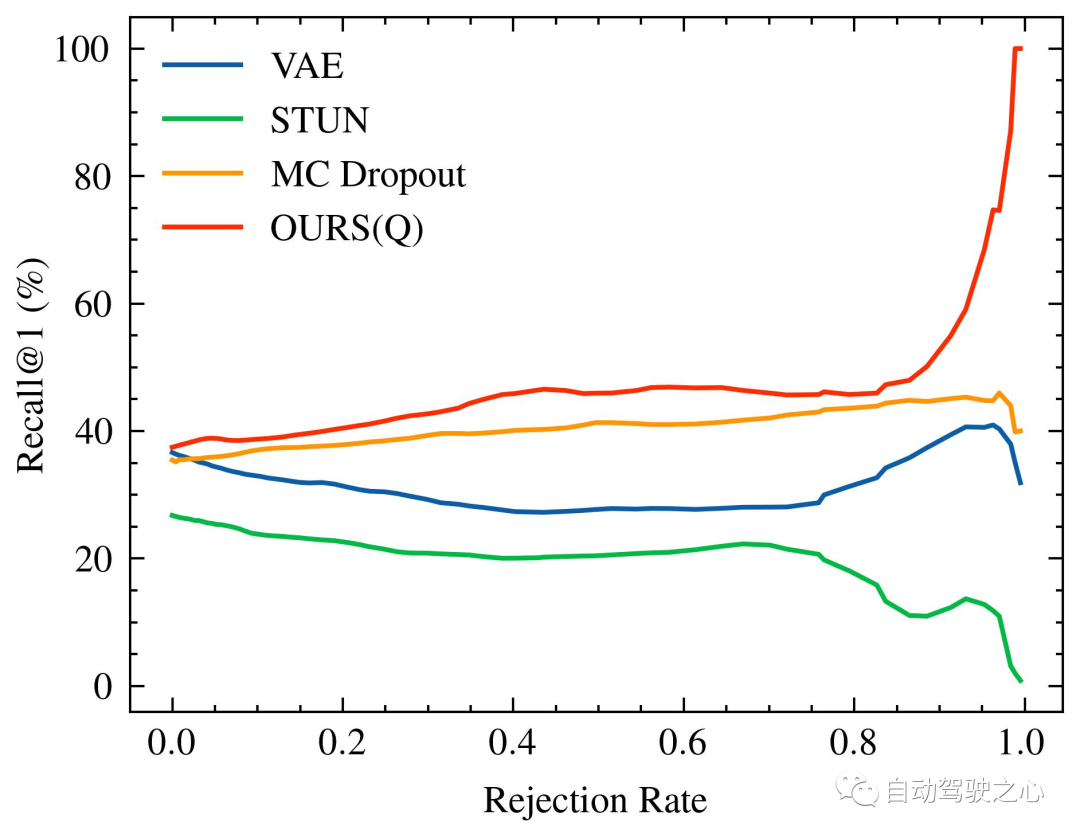
Mulran的内省查询拒绝性能。格式同上。
另一方面,与 MC Dropout 相比,后者估计了由于数据偏见和模型误差导致的认知不确定性,尽管它在Oxford Radar RobotCar实验的早期阶段有更高的 Recall@1 增加,但其性能总体上低于我们的,并且随着拒绝率进一步增加,未能实现更大的改进。最后,比较 OURS(Q) 和 OURS(QM) 在Oxford Radar RobotCar实验中,我们观察到 Recall@RR encore amélioré à 93,67 %, dépassant la méthode de pointe actuelle STUN de 4,18%. Cela démontre en outre l'efficacité de la variance apprise en tant que mesure d'incertitude efficace et la stratégie d'intégration de cartes basée sur l'incertitude pour améliorer les performances de reconnaissance des lieux.
Performances d'estimation de l'incertitude
Le changement dans les performances de reconnaissance à mesure que le pourcentage de requêtes incertaines rejetées augmente, en particulier Recall@1, dans
Oxford Radar RobotCarExpérience Comme le montre la figure 1 dans l'expérience
 MulRan
MulRan
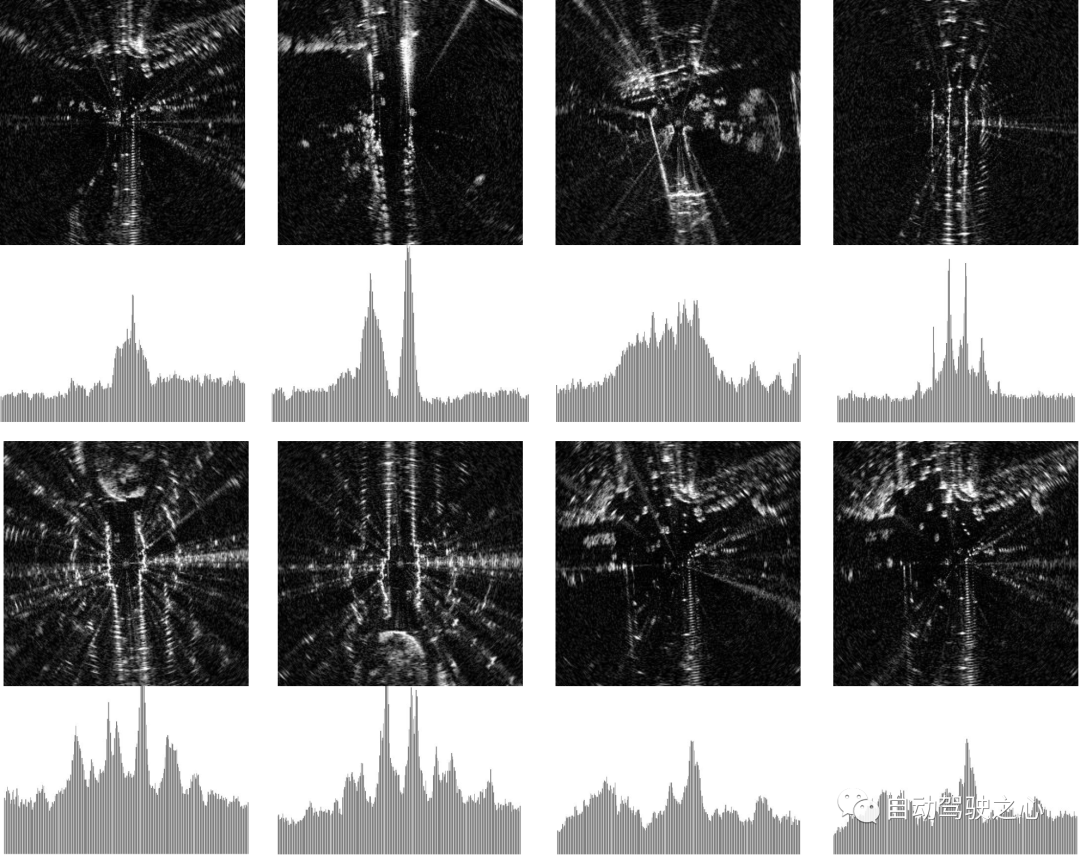
Recall@RR🎜 🎜 méthode d'indicateur. Par rapport à VAE et STUN, qui estiment également l'incertitude du modèle comme notre méthode, OURS(Q) dans 🎜 🎜Recall@RR=0.1/0.2/0.5🎜 🎜implémenté sur Il y a eu une amélioration de +(1.32/ 3,02/8,46)%, tandis que VAE et STUN ont diminué respectivement de -(3,79/5,24/8,80)% et -(2,97/4,16/6,30)%. 🎜🎜🎜🎜 Performances de rejet des requêtes d'introspection d'Oxford Radar RobotCar. À mesure que le pourcentage de requêtes indéterminées rejetées augmente, Recall@1augmenter/diminuer. En raison des faibles performances de VAE par rapport à d'autres méthodes (en particulier Recall@RR=0.1/0.2/0.5's (48.42/48.08/18.48)%), donc il n'est pas visualisé. 🎜🎜🎜🎜 Performances de rejet de requêtes introspectives de Mulran. Le format est le même que ci-dessus. 🎜🎜D'un autre côté, comparé à MC Dropout, qui estime l'incertitude épistémique due au biais des données et à l'erreur de modèle, bien qu'il ait eu un 🎜 plus élevé dans les premières étapes de l'expérience Oxford Radar RobotCar 🎜Recall@1 🎜 🎜 a augmenté, mais ses performances étaient généralement inférieures aux nôtres et n'ont pas permis d'obtenir de plus grandes améliorations à mesure que le taux de rejet augmentait encore. Enfin, en comparant OURS(Q) et OURS(QM) Dans l'expérience Oxford Radar RobotCar, nous avons observé 🎜 🎜Recall@RR🎜 🎜 a des modèles de changement similaires, mais il existe un écart considérable entre eux. Cela suggère que les mécanismes de requête introspective et de maintenance de cartes contribuent indépendamment au système de reconnaissance de lieu, chacun exploitant les mesures d'incertitude de manière intégrale. 🎜🎜🎜 Discussion sur Off the Radar 🎜🎜🎜🎜 Analyse qualitative et visualisation 🎜🎜🎜 Pour évaluer qualitativement les sources d'incertitude dans la perception radar, nous fournissons des estimations hautes/basses dans deux ensembles de données en utilisant notre méthode Comparaison visuelle des échantillons d'incertitude. Comme indiqué, les analyses radar à haute incertitude montrent généralement un flou de mouvement important et des zones clairsemées non détectées, tandis que les analyses à faible incertitude contiennent généralement des caractéristiques distinctes avec une intensité plus forte dans l'histogramme. 🎜🎜🎜🎜Visualisation des scans radar avec différents niveaux d'incertitude. Les quatre exemples de gauche proviennent de l'ensemble de données Oxford Radar RobotCar, tandis que les quatre exemples de droite proviennent de MulRan. Nous montrons les 10 meilleurs échantillons avec l'incertitude la plus élevée (en haut) / la plus faible (en bas). Les analyses radar sont affichées en coordonnées cartésiennes pour un contraste amélioré. L'histogramme sous chaque image montre les caractéristiques du descripteur RingKey de l'intensité extraite de tous les angles d'azimut.
Cela conforte davantage notre hypothèse sur les sources d'incertitude dans la perception radar et sert de preuve qualitative que nos mesures d'incertitude capturent ce bruit de données.
Différence entre les ensembles de données
Dans nos expériences de référence, nous avons observé des différences considérables dans les performances de reconnaissance entre les deux ensembles de données. Nous pensons que la taille des données d'entraînement disponibles peut être une raison légitime. L'ensemble de formation d'Oxford Radar RobotCar comprend plus de 300 km d'expérience de conduite, tandis que l'ensemble de données MulRan ne comprend qu'environ 120 km. Cependant, tenez également compte de la dégradation des performances de la méthode de descripteur RingKey. Cela suggère qu'il peut y avoir des caractéristiques inhérentes indiscernables dans la perception de la scène radar. Par exemple, nous avons constaté que les environnements comportant des zones ouvertes clairsemées aboutissaient souvent à des analyses identiques et à des performances de reconnaissance sous-optimales. Nous montrons sur cet ensemble de données ce qui arrive à notre système et à diverses références dans ces situations de forte incertitude.

Lien original : https://mp.weixin.qq.com/s/wu7whicFEAuo65kYp4quow
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Pourquoi le Gaussian Splatting est-il si populaire dans la conduite autonome que le NeRF commence à être abandonné ?
Jan 17, 2024 pm 02:57 PM
Pourquoi le Gaussian Splatting est-il si populaire dans la conduite autonome que le NeRF commence à être abandonné ?
Jan 17, 2024 pm 02:57 PM
Écrit ci-dessus et compréhension personnelle de l'auteur Le Gaussiansplatting tridimensionnel (3DGS) est une technologie transformatrice qui a émergé dans les domaines des champs de rayonnement explicites et de l'infographie ces dernières années. Cette méthode innovante se caractérise par l’utilisation de millions de gaussiennes 3D, ce qui est très différent de la méthode du champ de rayonnement neuronal (NeRF), qui utilise principalement un modèle implicite basé sur les coordonnées pour mapper les coordonnées spatiales aux valeurs des pixels. Avec sa représentation explicite de scènes et ses algorithmes de rendu différenciables, 3DGS garantit non seulement des capacités de rendu en temps réel, mais introduit également un niveau de contrôle et d'édition de scène sans précédent. Cela positionne 3DGS comme un révolutionnaire potentiel pour la reconstruction et la représentation 3D de nouvelle génération. À cette fin, nous fournissons pour la première fois un aperçu systématique des derniers développements et préoccupations dans le domaine du 3DGS.
 Comment résoudre le problème de la longue traîne dans les scénarios de conduite autonome ?
Jun 02, 2024 pm 02:44 PM
Comment résoudre le problème de la longue traîne dans les scénarios de conduite autonome ?
Jun 02, 2024 pm 02:44 PM
Hier, lors de l'entretien, on m'a demandé si j'avais posé des questions à longue traîne, j'ai donc pensé faire un bref résumé. Le problème à longue traîne de la conduite autonome fait référence aux cas extrêmes dans les véhicules autonomes, c'est-à-dire à des scénarios possibles avec une faible probabilité d'occurrence. Le problème perçu de la longue traîne est l’une des principales raisons limitant actuellement le domaine de conception opérationnelle des véhicules autonomes intelligents à véhicule unique. L'architecture sous-jacente et la plupart des problèmes techniques de la conduite autonome ont été résolus, et les 5 % restants des problèmes à longue traîne sont progressivement devenus la clé pour restreindre le développement de la conduite autonome. Ces problèmes incluent une variété de scénarios fragmentés, de situations extrêmes et de comportements humains imprévisibles. La « longue traîne » des scénarios limites dans la conduite autonome fait référence aux cas limites dans les véhicules autonomes (VA). Les cas limites sont des scénarios possibles avec une faible probabilité d'occurrence. ces événements rares
 Choisir une caméra ou un lidar ? Une étude récente sur la détection robuste d'objets 3D
Jan 26, 2024 am 11:18 AM
Choisir une caméra ou un lidar ? Une étude récente sur la détection robuste d'objets 3D
Jan 26, 2024 am 11:18 AM
0. Écrit à l'avant&& Compréhension personnelle que les systèmes de conduite autonome s'appuient sur des technologies avancées de perception, de prise de décision et de contrôle, en utilisant divers capteurs (tels que caméras, lidar, radar, etc.) pour percevoir l'environnement et en utilisant des algorithmes et des modèles pour une analyse et une prise de décision en temps réel. Cela permet aux véhicules de reconnaître les panneaux de signalisation, de détecter et de suivre d'autres véhicules, de prédire le comportement des piétons, etc., permettant ainsi de fonctionner en toute sécurité et de s'adapter à des environnements de circulation complexes. Cette technologie attire actuellement une grande attention et est considérée comme un domaine de développement important pour l'avenir des transports. . un. Mais ce qui rend la conduite autonome difficile, c'est de trouver comment faire comprendre à la voiture ce qui se passe autour d'elle. Cela nécessite que l'algorithme de détection d'objets tridimensionnels du système de conduite autonome puisse percevoir et décrire avec précision les objets dans l'environnement, y compris leur emplacement,
 Avez-vous vraiment maîtrisé la conversion des systèmes de coordonnées ? Des enjeux multi-capteurs indispensables à la conduite autonome
Oct 12, 2023 am 11:21 AM
Avez-vous vraiment maîtrisé la conversion des systèmes de coordonnées ? Des enjeux multi-capteurs indispensables à la conduite autonome
Oct 12, 2023 am 11:21 AM
Le premier article pilote et clé présente principalement plusieurs systèmes de coordonnées couramment utilisés dans la technologie de conduite autonome, et comment compléter la corrélation et la conversion entre eux, et enfin construire un modèle d'environnement unifié. L'objectif ici est de comprendre la conversion du véhicule en corps rigide de caméra (paramètres externes), la conversion de caméra en image (paramètres internes) et la conversion d'image en unité de pixel. La conversion de 3D en 2D aura une distorsion, une traduction, etc. Points clés : Le système de coordonnées du véhicule et le système de coordonnées du corps de la caméra doivent être réécrits : le système de coordonnées planes et le système de coordonnées des pixels Difficulté : la distorsion de l'image doit être prise en compte. La dé-distorsion et l'ajout de distorsion sont compensés sur le plan de l'image. 2. Introduction Il existe quatre systèmes de vision au total : système de coordonnées du plan de pixels (u, v), système de coordonnées d'image (x, y), système de coordonnées de caméra () et système de coordonnées mondiales (). Il existe une relation entre chaque système de coordonnées,
 Cet article vous suffit pour en savoir plus sur la conduite autonome et la prédiction de trajectoire !
Feb 28, 2024 pm 07:20 PM
Cet article vous suffit pour en savoir plus sur la conduite autonome et la prédiction de trajectoire !
Feb 28, 2024 pm 07:20 PM
La prédiction de trajectoire joue un rôle important dans la conduite autonome. La prédiction de trajectoire de conduite autonome fait référence à la prédiction de la trajectoire de conduite future du véhicule en analysant diverses données pendant le processus de conduite du véhicule. En tant que module central de la conduite autonome, la qualité de la prédiction de trajectoire est cruciale pour le contrôle de la planification en aval. La tâche de prédiction de trajectoire dispose d'une riche pile technologique et nécessite une connaissance de la perception dynamique/statique de la conduite autonome, des cartes de haute précision, des lignes de voie, des compétences en architecture de réseau neuronal (CNN&GNN&Transformer), etc. Il est très difficile de démarrer ! De nombreux fans espèrent se lancer dans la prédiction de trajectoire le plus tôt possible et éviter les pièges. Aujourd'hui, je vais faire le point sur quelques problèmes courants et des méthodes d'apprentissage introductives pour la prédiction de trajectoire ! Connaissances introductives 1. Existe-t-il un ordre d'entrée pour les épreuves de prévisualisation ? R : Regardez d’abord l’enquête, p
 SIMPL : un benchmark de prédiction de mouvement multi-agents simple et efficace pour la conduite autonome
Feb 20, 2024 am 11:48 AM
SIMPL : un benchmark de prédiction de mouvement multi-agents simple et efficace pour la conduite autonome
Feb 20, 2024 am 11:48 AM
Titre original : SIMPL : ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving Lien article : https://arxiv.org/pdf/2402.02519.pdf Lien code : https://github.com/HKUST-Aerial-Robotics/SIMPL Affiliation de l'auteur : Université des sciences de Hong Kong et technologie Idée DJI Paper : cet article propose une base de référence de prédiction de mouvement (SIMPL) simple et efficace pour les véhicules autonomes. Par rapport au cent agent traditionnel
 Parlons des systèmes de conduite autonome de bout en bout et de nouvelle génération, ainsi que de quelques malentendus sur la conduite autonome de bout en bout ?
Apr 15, 2024 pm 04:13 PM
Parlons des systèmes de conduite autonome de bout en bout et de nouvelle génération, ainsi que de quelques malentendus sur la conduite autonome de bout en bout ?
Apr 15, 2024 pm 04:13 PM
Au cours du mois dernier, pour des raisons bien connues, j'ai eu des échanges très intensifs avec divers professeurs et camarades de classe du secteur. Un sujet inévitable dans l'échange est naturellement le populaire Tesla FSDV12 de bout en bout. Je voudrais profiter de cette occasion pour trier certaines de mes pensées et opinions en ce moment pour votre référence et votre discussion. Comment définir un système de conduite autonome de bout en bout et quels problèmes devraient être résolus de bout en bout ? Selon la définition la plus traditionnelle, un système de bout en bout fait référence à un système qui saisit les informations brutes des capteurs et génère directement les variables pertinentes pour la tâche. Par exemple, en reconnaissance d'images, CNN peut être appelé de bout en bout par rapport à la méthode traditionnelle d'extraction de caractéristiques + classificateur. Dans les tâches de conduite autonome, saisir les données de divers capteurs (caméra/LiDAR
 NuScenes dernier SOTA SparseAD : les requêtes clairsemées contribuent à une conduite autonome efficace de bout en bout !
Apr 17, 2024 pm 06:22 PM
NuScenes dernier SOTA SparseAD : les requêtes clairsemées contribuent à une conduite autonome efficace de bout en bout !
Apr 17, 2024 pm 06:22 PM
Écrit à l'avant et point de départ Le paradigme de bout en bout utilise un cadre unifié pour réaliser plusieurs tâches dans les systèmes de conduite autonome. Malgré la simplicité et la clarté de ce paradigme, les performances des méthodes de conduite autonome de bout en bout sur les sous-tâches sont encore loin derrière les méthodes à tâche unique. Dans le même temps, les fonctionnalités de vue à vol d'oiseau (BEV) denses, largement utilisées dans les méthodes de bout en bout précédentes, rendent difficile l'adaptation à davantage de modalités ou de tâches. Un paradigme de conduite autonome de bout en bout (SparseAD) centré sur la recherche clairsemée est proposé ici, dans lequel la recherche clairsemée représente entièrement l'ensemble du scénario de conduite, y compris l'espace, le temps et les tâches, sans aucune représentation BEV dense. Plus précisément, une architecture clairsemée unifiée est conçue pour la connaissance des tâches, notamment la détection, le suivi et la cartographie en ligne. De plus, lourd
