
 Périphériques technologiques
IA
Alignement précis des fonctionnalités pour améliorer la détection d'objets 3D multimodaux : application de GraphAlign
Périphériques technologiques
IA
Alignement précis des fonctionnalités pour améliorer la détection d'objets 3D multimodaux : application de GraphAlign
Alignement précis des fonctionnalités pour améliorer la détection d'objets 3D multimodaux : application de GraphAlign

Titre original : GraphAlign : Enhancing Accurate Feature Alignment by Graph matching for Multi-Modal 3D Object Detection
Le contenu qui doit être réécrit est : Lien papier : https://arxiv.org/pdf/2310.08261.pdf
Auteur affiliation : Université Jiaotong de Pékin Université des sciences et technologies du Hebei Université Tsinghua

Idée de thèse :
Le LiDAR et les caméras sont des capteurs complémentaires pour la détection de cibles 3D en conduite autonome. Cependant, l’étude des interactions non naturelles entre les nuages de points et les images est un défi, et la clé réside dans la manière d’effectuer l’alignement des caractéristiques de modalités hétérogènes. Actuellement, de nombreuses méthodes parviennent uniquement à l'alignement des caractéristiques via l'étalonnage de la projection et ignorent le problème des erreurs de précision de conversion des coordonnées entre les capteurs, ce qui entraîne des performances sous-optimales. Cet article propose une stratégie d'alignement de caractéristiques plus précise appelée GraphAlign pour la détection d'objets 3D via la correspondance de graphiques. Plus précisément, cet article fusionne les caractéristiques d'image de l'encodeur de segmentation sémantique dans la branche image avec les caractéristiques de nuage de points du CNN clairsemé 3D dans la branche LiDAR. Afin de réduire la quantité de calcul, cet article utilise le calcul de la distance euclidienne pour construire la relation de voisin le plus proche dans le sous-espace des entités de nuage de points. Grâce à l'étalonnage de la projection entre l'image et le nuage de points, les voisins les plus proches des entités du nuage de points sont projetés sur les entités de l'image. Nous recherchons ensuite un alignement de caractéristiques plus approprié en faisant correspondre le voisin le plus proche d'un seul nuage de points à plusieurs images. En outre, cet article fournit également un module d'auto-attention pour renforcer le poids des relations importantes afin d'affiner l'alignement des caractéristiques entre des modalités hétérogènes. Un grand nombre d'expériences ont été menées dans le benchmark nuScenes pour prouver l'efficacité et l'efficience de GraphAlign proposé dans cet article
Principales contributions :
Cet article propose GraphAlign, un framework d'alignement de fonctionnalités basé sur la correspondance de graphes (graph matching) , pour résoudre le problème de désalignement dans la détection d'objets 3D multimodaux.
Cet article propose des modules d'alignement de caractéristiques graphiques (GFA) et d'alignement de caractéristiques d'auto-attention (SAFA) pour obtenir un alignement précis des caractéristiques de l'image et des caractéristiques des nuages de points, ce qui peut améliorer davantage les nuages de points et l'alignement des caractéristiques entre les modalités d'image, améliorant ainsi la précision de détection. .
En menant des expériences en utilisant deux benchmarks, KITTI et nuScenes, nous prouvons que GraphAlign peut améliorer efficacement la précision de la détection des nuages de points, en particulier dans la détection de cibles à longue distance
Conception du réseau :
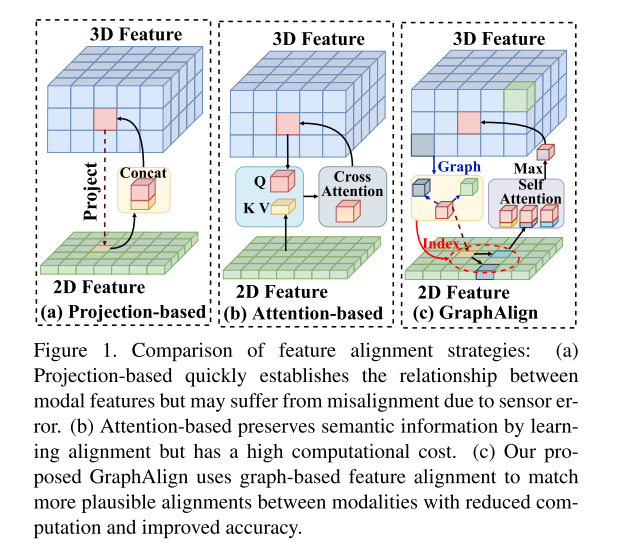
Figure 1. Caractéristiques Comparaison des stratégies d'alignement
(a) Les méthodes basées sur la projection peuvent établir rapidement des relations entre les caractéristiques modales, mais peuvent souffrir d'un désalignement dû à des erreurs de capteur. (b) Les méthodes basées sur l'attention préservent les informations sémantiques en apprenant l'alignement, mais sont coûteuses en termes de calcul. (c) GraphAlign proposé dans cet article utilise l'alignement de caractéristiques basé sur un graphique pour faire correspondre des alignements plus raisonnables entre les modalités, réduisant ainsi l'effort de calcul et améliorant la précision.
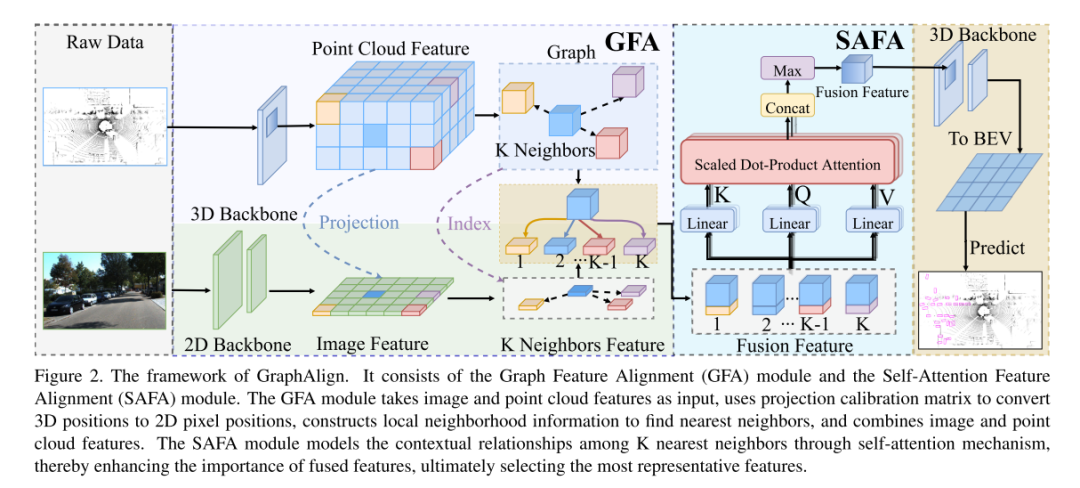
Figure 2. Le framework de GraphAlign.
Réécrit en chinois comme suit : il se compose du module d'alignement des fonctionnalités graphiques (GFA) et du module d'alignement des fonctionnalités d'auto-attention (SAFA). Le module GFA reçoit des caractéristiques d'image et de nuage de points en entrée, utilise une matrice d'étalonnage de projection pour convertir les positions 3D en positions de pixels 2D, génère des informations sur le quartier local pour trouver les voisins les plus proches et combine les caractéristiques d'image et de nuage de points. Le module SAFA modélise la relation contextuelle entre les K voisins les plus proches via le mécanisme d'auto-attention pour améliorer l'importance des caractéristiques fusionnées, et sélectionne enfin les caractéristiques les plus représentatives
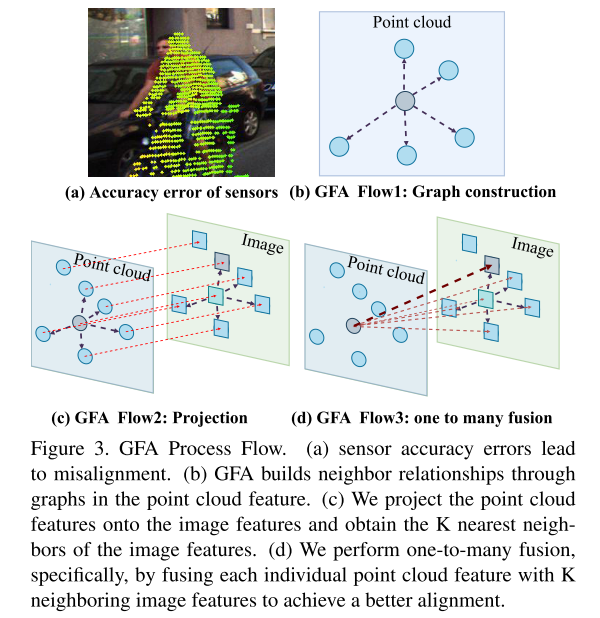
Figure 3. Flux de traitement GFA
( a) Précision du capteur erreur provoquant un désalignement. (b) GFA établit des relations de proximité au moyen de graphiques dans des entités de nuages de points. (c) Cet article projette les caractéristiques du nuage de points sur les caractéristiques de l'image et obtient les K voisins les plus proches des caractéristiques de l'image. (d) Cet article effectue une fusion un-à-plusieurs, en particulier en fusionnant chaque caractéristique de nuage de points individuel avec K caractéristiques d'image voisines pour obtenir un meilleur alignement.
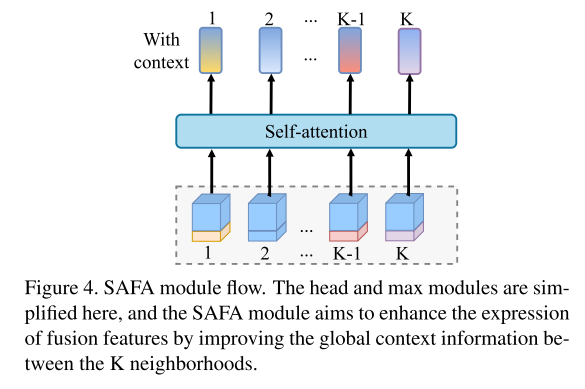
Figure 4. Processus du module SAFA
Nous avons simplifié les modules head et max. Le but du module SAFA est d'améliorer les informations de contexte global entre K voisins pour améliorer la représentation des fonctionnalités fusionnées


Résultats expérimentaux :
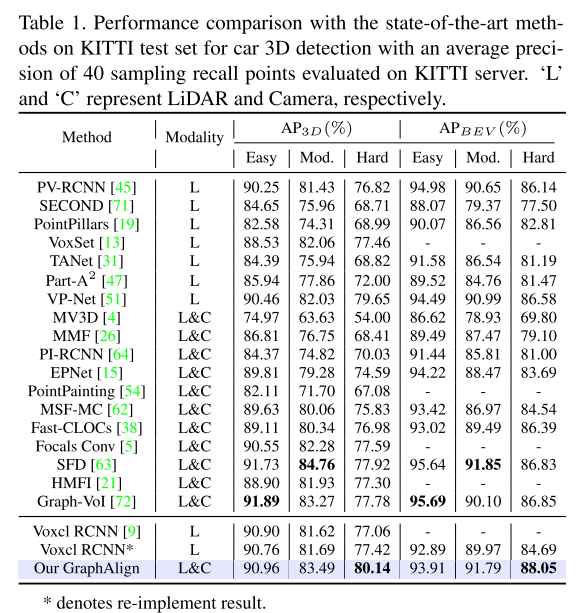
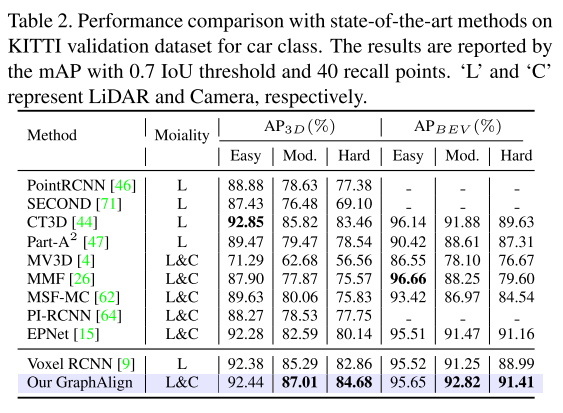
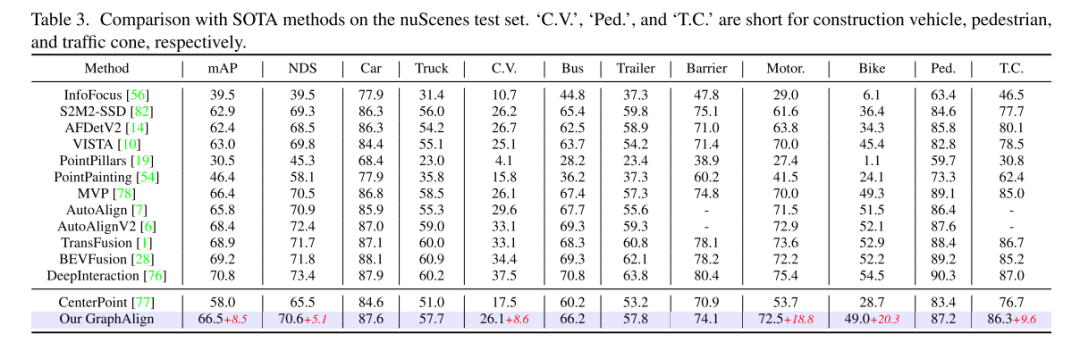
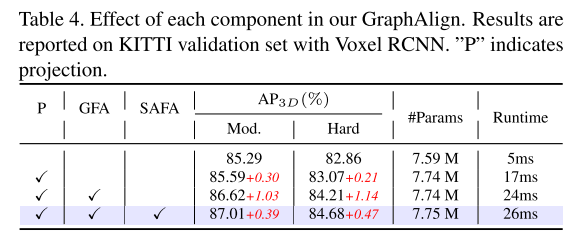



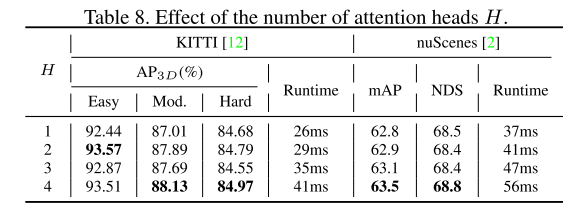
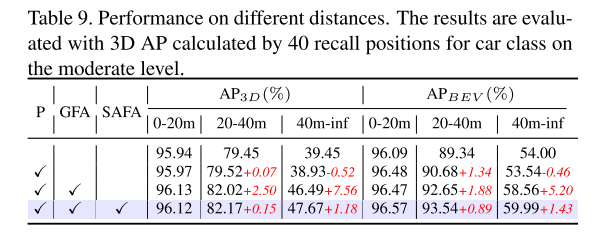
Citation :
Chanson, Z., Wei , H., Bai, L., Yang, L. et Jia, C. (2023). GraphAlign : Amélioration de l'alignement précis des fonctionnalités grâce à la correspondance graphique pour la détection d'objets 3D multimodaux. /abs/2310.08261
.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Pourquoi le Gaussian Splatting est-il si populaire dans la conduite autonome que le NeRF commence à être abandonné ?
Jan 17, 2024 pm 02:57 PM
Pourquoi le Gaussian Splatting est-il si populaire dans la conduite autonome que le NeRF commence à être abandonné ?
Jan 17, 2024 pm 02:57 PM
Écrit ci-dessus et compréhension personnelle de l'auteur Le Gaussiansplatting tridimensionnel (3DGS) est une technologie transformatrice qui a émergé dans les domaines des champs de rayonnement explicites et de l'infographie ces dernières années. Cette méthode innovante se caractérise par l’utilisation de millions de gaussiennes 3D, ce qui est très différent de la méthode du champ de rayonnement neuronal (NeRF), qui utilise principalement un modèle implicite basé sur les coordonnées pour mapper les coordonnées spatiales aux valeurs des pixels. Avec sa représentation explicite de scènes et ses algorithmes de rendu différenciables, 3DGS garantit non seulement des capacités de rendu en temps réel, mais introduit également un niveau de contrôle et d'édition de scène sans précédent. Cela positionne 3DGS comme un révolutionnaire potentiel pour la reconstruction et la représentation 3D de nouvelle génération. À cette fin, nous fournissons pour la première fois un aperçu systématique des derniers développements et préoccupations dans le domaine du 3DGS.
 En savoir plus sur les emojis 3D Fluent dans Microsoft Teams
Apr 24, 2023 pm 10:28 PM
En savoir plus sur les emojis 3D Fluent dans Microsoft Teams
Apr 24, 2023 pm 10:28 PM
N'oubliez pas, surtout si vous êtes un utilisateur de Teams, que Microsoft a ajouté un nouveau lot d'émojis 3DFluent à son application de visioconférence axée sur le travail. Après que Microsoft a annoncé des emojis 3D pour Teams et Windows l'année dernière, le processus a en fait permis de mettre à jour plus de 1 800 emojis existants pour la plate-forme. Cette grande idée et le lancement de la mise à jour des emoji 3DFluent pour les équipes ont été promus pour la première fois via un article de blog officiel. La dernière mise à jour de Teams apporte FluentEmojis à l'application. Microsoft affirme que les 1 800 emojis mis à jour seront disponibles chaque jour.
 Choisir une caméra ou un lidar ? Une étude récente sur la détection robuste d'objets 3D
Jan 26, 2024 am 11:18 AM
Choisir une caméra ou un lidar ? Une étude récente sur la détection robuste d'objets 3D
Jan 26, 2024 am 11:18 AM
0. Écrit à l'avant&& Compréhension personnelle que les systèmes de conduite autonome s'appuient sur des technologies avancées de perception, de prise de décision et de contrôle, en utilisant divers capteurs (tels que caméras, lidar, radar, etc.) pour percevoir l'environnement et en utilisant des algorithmes et des modèles pour une analyse et une prise de décision en temps réel. Cela permet aux véhicules de reconnaître les panneaux de signalisation, de détecter et de suivre d'autres véhicules, de prédire le comportement des piétons, etc., permettant ainsi de fonctionner en toute sécurité et de s'adapter à des environnements de circulation complexes. Cette technologie attire actuellement une grande attention et est considérée comme un domaine de développement important pour l'avenir des transports. . un. Mais ce qui rend la conduite autonome difficile, c'est de trouver comment faire comprendre à la voiture ce qui se passe autour d'elle. Cela nécessite que l'algorithme de détection d'objets tridimensionnels du système de conduite autonome puisse percevoir et décrire avec précision les objets dans l'environnement, y compris leur emplacement,
 CLIP-BEVFormer : superviser explicitement la structure BEVFormer pour améliorer les performances de détection à longue traîne
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer : superviser explicitement la structure BEVFormer pour améliorer les performances de détection à longue traîne
Mar 26, 2024 pm 12:41 PM
Écrit ci-dessus et compréhension personnelle de l'auteur : À l'heure actuelle, dans l'ensemble du système de conduite autonome, le module de perception joue un rôle essentiel. Le véhicule autonome roulant sur la route ne peut obtenir des résultats de perception précis que via le module de perception en aval. dans le système de conduite autonome, prend des jugements et des décisions comportementales opportuns et corrects. Actuellement, les voitures dotées de fonctions de conduite autonome sont généralement équipées d'une variété de capteurs d'informations de données, notamment des capteurs de caméra à vision panoramique, des capteurs lidar et des capteurs radar à ondes millimétriques pour collecter des informations selon différentes modalités afin d'accomplir des tâches de perception précises. L'algorithme de perception BEV basé sur la vision pure est privilégié par l'industrie en raison de son faible coût matériel et de sa facilité de déploiement, et ses résultats peuvent être facilement appliqués à diverses tâches en aval.
 Paint 3D sous Windows 11 : guide de téléchargement, d'installation et d'utilisation
Apr 26, 2023 am 11:28 AM
Paint 3D sous Windows 11 : guide de téléchargement, d'installation et d'utilisation
Apr 26, 2023 am 11:28 AM
Lorsque les rumeurs ont commencé à se répandre selon lesquelles le nouveau Windows 11 était en développement, chaque utilisateur de Microsoft était curieux de savoir à quoi ressemblerait le nouveau système d'exploitation et ce qu'il apporterait. Après de nombreuses spéculations, Windows 11 est là. Le système d'exploitation est livré avec une nouvelle conception et des modifications fonctionnelles. En plus de quelques ajouts, il s’accompagne de fonctionnalités obsolètes et supprimées. L'une des fonctionnalités qui n'existe pas dans Windows 11 est Paint3D. Bien qu'il propose toujours Paint classique, idéal pour les dessinateurs, les griffonneurs et les griffonneurs, il abandonne Paint3D, qui offre des fonctionnalités supplémentaires idéales pour les créateurs 3D. Si vous recherchez des fonctionnalités supplémentaires, nous recommandons Autodesk Maya comme le meilleur logiciel de conception 3D. comme
 Obtenez une femme virtuelle en 3D en 30 secondes avec une seule carte ! Text to 3D génère un humain numérique de haute précision avec des détails de pores clairs, se connectant de manière transparente à Maya, Unity et d'autres outils de production.
May 23, 2023 pm 02:34 PM
Obtenez une femme virtuelle en 3D en 30 secondes avec une seule carte ! Text to 3D génère un humain numérique de haute précision avec des détails de pores clairs, se connectant de manière transparente à Maya, Unity et d'autres outils de production.
May 23, 2023 pm 02:34 PM
ChatGPT a injecté une dose de sang de poulet dans l’industrie de l’IA, et tout ce qui était autrefois impensable est devenu aujourd’hui une pratique de base. Le Text-to-3D, qui continue de progresser, est considéré comme le prochain point chaud dans le domaine de l'AIGC après la diffusion (images) et le GPT (texte), et a reçu une attention sans précédent. Non, un produit appelé ChatAvatar a été mis en version bêta publique discrète, recueillant rapidement plus de 700 000 vues et attention, et a été présenté sur Spacesoftheweek. △ChatAvatar prendra également en charge la technologie Imageto3D qui génère des personnages stylisés en 3D à partir de peintures originales à perspective unique/multi-perspective générées par l'IA. Le modèle 3D généré par la version bêta actuelle a reçu une large attention.
 Une interprétation approfondie de l'algorithme de perception visuelle 3D pour la conduite autonome
Jun 02, 2023 pm 03:42 PM
Une interprétation approfondie de l'algorithme de perception visuelle 3D pour la conduite autonome
Jun 02, 2023 pm 03:42 PM
Pour les applications de conduite autonome, il est finalement nécessaire de percevoir des scènes 3D. La raison est simple : un véhicule ne peut pas conduire sur la base des résultats de perception obtenus à partir d’une image. Même un conducteur humain ne peut pas conduire sur la base d’une image. Étant donné que la distance de l'objet et les informations sur la profondeur de la scène ne peuvent pas être reflétées dans les résultats de perception 2D, ces informations sont la clé permettant au système de conduite autonome de porter des jugements corrects sur l'environnement. De manière générale, les capteurs visuels (comme les caméras) des véhicules autonomes sont installés au-dessus de la carrosserie du véhicule ou sur le rétroviseur intérieur. Peu importe où elle se trouve, la caméra obtient la projection du monde réel dans la vue en perspective (PerspectiveView) (du système de coordonnées mondiales au système de coordonnées de l'image). Cette vue est très similaire au système visuel humain,
 Les dernières nouvelles de l'Université d'Oxford ! Mickey : correspondance d'images 2D en 3D SOTA ! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Les dernières nouvelles de l'Université d'Oxford ! Mickey : correspondance d'images 2D en 3D SOTA ! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Lien du projet écrit devant : https://nianticlabs.github.io/mickey/ Étant donné deux images, la pose de la caméra entre elles peut être estimée en établissant la correspondance entre les images. En règle générale, ces correspondances sont 2D à 2D et nos poses estimées sont à échelle indéterminée. Certaines applications, telles que la réalité augmentée instantanée, à tout moment et en tout lieu, nécessitent une estimation de pose des métriques d'échelle, elles s'appuient donc sur des estimateurs de profondeur externes pour récupérer l'échelle. Cet article propose MicKey, un processus de correspondance de points clés capable de prédire les correspondances métriques dans l'espace d'une caméra 3D. En apprenant la correspondance des coordonnées 3D entre les images, nous sommes en mesure de déduire des métriques relatives.
