

La reconstruction faciale 3D est une technologie clé largement utilisée dans les domaines de la production cinématographique et télévisuelle de jeux, des personnages numériques, de l'AR/VR, de la reconnaissance et de l'édition faciales, etc. Son objectif est d'obtenir des personnages 3D de haute qualité à partir d'une ou plusieurs images. modèle de visage. Grâce à des systèmes de prise de vue complexes en studio, les solutions actuellement matures dans l'industrie peuvent obtenir des effets de reconstruction avec une précision au niveau des pores comparable à celle des personnes réelles [2]. Cependant, leurs coûts de production sont élevés et leurs temps de cycle sont longs, et ils ne sont généralement utilisés que dans des projets de cinéma, de télévision ou de jeux de niveau S.
Ces dernières années, le gameplay interactif basé sur une technologie de reconstruction de visage à faible coût (telle que le jeu de pincement du visage des personnages de jeu, la génération d'images virtuelles AR/VR, etc.) a été bien accueilli par le marché. Les utilisateurs doivent uniquement saisir des images pouvant être obtenues quotidiennement, telles que des photos uniques ou multiples prises par des téléphones portables, pour obtenir rapidement un modèle 3D. Cependant, la qualité d'imagerie des méthodes existantes est incontrôlable, la précision des résultats de reconstruction est faible et elle est incapable d'exprimer les détails du visage [3-4]. Comment obtenir des visages 3D haute fidélité à faible coût reste un problème non résolu.
La première étape de la reconstruction du visage consiste à définir la méthode d'expression du visage. Cependant, les modèles paramétrés de visage traditionnels existants ont des capacités d'expression limitées. Même avec plus d'informations contraintes, telles que les images multi-vues, la précision de la reconstruction est difficile à améliorer. Par conséquent, Tencent AI Lab a proposé un modèle de skinning adaptatif amélioré (ci-après dénommé ASM) en tant que modèle de visage paramétrique, qui utilise des priorités de visage et un modèle de mélange gaussien pour exprimer les poids Pi du masquage du visage, réduisant ainsi considérablement le nombre de paramètres. peut être résolu automatiquement.
Les tests montrent que la méthode ASM n'utilise qu'un petit nombre de paramètres sans nécessiter de formation, ce qui améliore considérablement la capacité d'expression des visages et la précision de la reconstruction de visage multi-vues, innovant au niveau SOTA. Le document concerné a été accepté par l'ICCV-2023. Ce qui suit est une explication détaillée du document.
Titre de l'article : ASM : Adaptive Skinning Model for High-Quality 3D Face Modeling

Lien de l'article : https://arxiv.org/pdf/2304.09423.pdf
Défis de recherche : faible coût, élevé Le problème de la reconstruction précise du visage en 3D
obtenir un modèle 3D avec un plus grand contenu d'informations à partir d'images 2D est un problème sous-déterminé avec des solutions infinies. Afin de le rendre résoluble, les chercheurs introduisent des a priori de visage dans la reconstruction, ce qui réduit la difficulté de résolution et exprime la forme 3D du visage avec moins de paramètres, c'est-à-dire un modèle de visage paramétrique. La plupart des modèles paramétriques de visage actuels sont basés sur le modèle 3D Morphable (3DMM) et sa version améliorée est un modèle paramétrique de visage proposé pour la première fois par Blanz et Vetter en 1999 [5]. L'article suppose qu'un visage peut être obtenu grâce à une combinaison linéaire ou non linéaire de plusieurs visages différents. Il construit une bibliothèque de base de visages en collectant des centaines de modèles 3D de haute précision de visages réels, puis combine des visages paramétrés pour exprimer de nouvelles caractéristiques. .Modèle de visage. Des recherches ultérieures ont optimisé le 3DMM en collectant des modèles de visages réels plus diversifiés [6, 7] et en améliorant les méthodes de réduction de dimensionnalité [8, 9].
Cependant, le modèle de type visage 3DMM a une grande robustesse mais une expressivité insuffisante. Bien qu'il puisse générer de manière stable des modèles de visage avec une précision moyenne lorsque l'image d'entrée est floue ou masquée, lorsque plusieurs images de haute qualité sont utilisées en entrée, le 3DMM a une capacité d'expression limitée et ne peut pas utiliser davantage d'informations d'entrée, ce qui limite la précision de la reconstruction. Cette limitation provient de deux aspects : premièrement, les limites de la méthode elle-même. Deuxièmement, la méthode repose sur la collecte de données de modèles de visages. Non seulement elle coûte cher, mais elle est également difficile à appliquer dans des applications pratiques. à la sensibilité des données faciales.
Méthode ASM : refonte du modèle squelette-peau
Afin de résoudre le problème de la capacité d'expression insuffisante du modèle de visage 3DMM existant, cet article présente le « modèle squelette-peau » couramment utilisé dans l'industrie du jeu comme méthode d'expression du visage de base. Les modèles à peau de squelette sont une méthode de modélisation faciale courante utilisée pour exprimer les formes du visage et les expressions des personnages de jeux dans le processus de production de jeux et d'animations. Il est connecté aux sommets du maillage sur le visage humain via des points d'os virtuels. Le poids de la peau détermine le poids d'influence des os sur les sommets du maillage. Lorsqu'il est utilisé, il vous suffit de contrôler le mouvement des os pour contrôler indirectement le mouvement de. les sommets du maillage.
Normalement, les modèles à peau squelettique nécessitent des animateurs pour effectuer un placement précis des os et un dessin du poids de la peau, ce qui présente les caractéristiques d'un seuil de production élevé et d'un long cycle de production. Cependant, les formes des os et des muscles de différentes personnes dans les visages humains réels sont très différentes. Il est difficile d'exprimer les différentes formes de visage dans la réalité avec un ensemble de systèmes de dépouillement de squelette existants. Sur la base d'une conception plus approfondie, le modèle adaptatif de dépouillement osseux ASM est proposé, qui est basé sur des poids de dépouillement de mélange gaussien (GMM Skinning Weights) et un système de liaison osseuse dynamique (Dynamic Bone Binding) pour améliorer encore la capacité d'expression de l'os. -skinning. Avec sa flexibilité, il peut générer de manière adaptative un modèle de peau de squelette unique pour chaque visage cible afin d'exprimer des détails du visage plus riches.
Afin d'améliorer la capacité d'expression du modèle squelette-peau lors de la modélisation de différents visages, ASM a réalisé une nouvelle conception pour la méthode de modélisation du modèle squelette-peau.
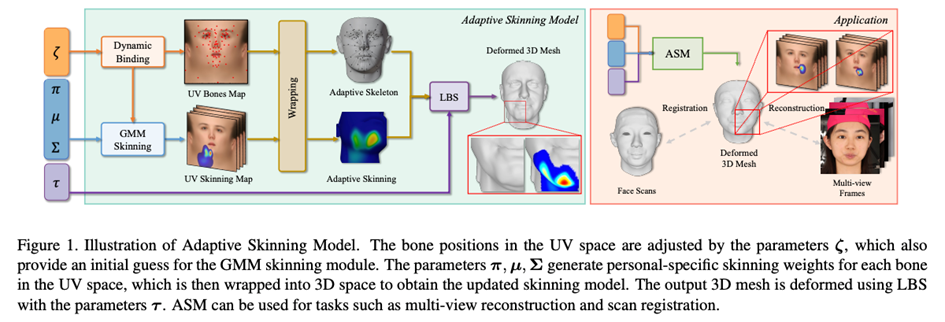
Figure 1 : cadre global de l'ASM
Le système de skinning du squelette est généralement basé sur l'algorithme Linear Blend Skinning (LBS), en contrôlant le mouvement (rotation, translation, mise à l'échelle) des os pour contrôler la déformation de Sommets du maillage. Le dépouillement osseux traditionnel se compose de deux parties, à savoir la matrice de poids de la peau et la liaison osseuse, paramètres de ces deux parties séparément pour obtenir un modèle de dépouillement osseux adaptatif. Ensuite, nous présenterons respectivement les méthodes de modélisation paramétrique de la matrice de poids cutané et de la liaison osseuse.
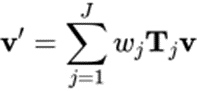
Formule 1 : formule LBS du modèle traditionnel à peau de squelette
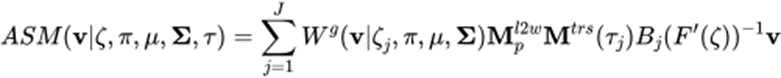
Formule 2 : la formule LBS d'ASM
Poids de dépouillement mixtes gaussiens (poids de dépouillement GMM)
La matrice de poids de peau est une matrice à mxn dimensions, où m est le nombre d'os et n est le nombre de sommets sur le Mesh. Cette matrice est utilisée pour stocker le coefficient d'influence de chaque os sur chaque sommet du Mesh. De manière générale, la matrice de poids de la peau est très clairsemée. Par exemple, dans Unity, chaque sommet du Mesh ne sera affecté que par 4 os maximum. À l'exception de ces 4 os, le coefficient d'influence des autres os sur le sommet est de 0. . Dans le modèle traditionnel à peau d'os, les poids de peau sont dessinés par l'animateur, et une fois les poids de peau obtenus, ils ne changeront plus lorsqu'ils seront utilisés. Ces dernières années, des travaux [1] ont tenté de combiner une grande quantité de données avec l'apprentissage du réseau neuronal pour générer automatiquement des poids de skinning. Cependant, une telle solution présente deux problèmes. Premièrement, la formation du réseau neuronal nécessite une grande quantité de travail. S'il s'agit d'un visage ou d'un dépouillement en 3D, les données sur le poids sont plus difficiles à obtenir. Deuxièmement, il existe une sérieuse redondance des paramètres dans l'utilisation du réseau neuronal pour modéliser le poids de la peau. Existe-t-il une méthode de modélisation du poids de la peau qui permet d'exprimer pleinement le poids de la peau de l'ensemble du visage en utilisant un petit nombre de paramètres sans entraînement ?
En observant les poids de peau courants, nous pouvons trouver les propriétés suivantes : 1. Les poids de peau sont localement lisses ; 2. Plus le sommet du maillage est éloigné de la position actuelle de l'os, le coefficient de peau correspondant est généralement plus petit et cette propriété ; est cohérent avec le modèle de mélange gaussien (GMM). Par conséquent, cet article propose des poids de skinning mixtes gaussiens (GMM Skinning Weights) pour modéliser la matrice de poids de skinning comme une fonction de mélange gaussienne basée sur une certaine fonction de distance entre les sommets et les os, de sorte qu'un ensemble de coefficients GMM puisse être utilisé pour exprimer le skinning. poids d'os spécifiques distribués. Afin de compresser davantage les paramètres de poids de la peau, nous transférons l'ensemble du maillage du visage de l'espace tridimensionnel vers l'espace UV, de sorte que nous n'ayons besoin que du GMM bidimensionnel et de la distance UV du sommet à l'os pour calculer le masquage de l'os actuel d'un sommet spécifique.Dynamic Bone Binding
La modélisation paramétrique des poids de peau nous permet non seulement d'exprimer la matrice de poids de peau avec un petit nombre de paramètres, mais nous permet également d'ajuster les os au moment de l'exécution. Il devient possible de lier la position Par conséquent, cet article propose la méthode de liaison osseuse dynamique (Dynamic Bone Binding). Tout comme le poids de la peau, cet article modélise la position de liaison de l'os comme un point de coordonnées sur l'espace UV et peut se déplacer arbitrairement dans l'espace UV. Pour les sommets du maillage de face, les sommets peuvent être mappés à une coordonnée fixe dans l'espace UV simplement via la relation de mappage UV prédéfinie. Mais les os ne sont pas prédéfinis dans l’espace UV, nous devons donc pour cela transférer les os liés de l’espace tridimensionnel vers l’espace UV. Cette étape de cet article est mise en œuvre en interpolant les coordonnées des os et des sommets environnants. Nous appliquons les coefficients d'interpolation calculés aux coordonnées UV des sommets pour obtenir les coordonnées UV des os. Il en va de même dans l'autre sens. Lorsque nous devons transférer les coordonnées de l'os de l'espace UV vers l'espace tridimensionnel, nous calculons également le coefficient d'interpolation entre les coordonnées UV de l'os actuel et les coordonnées UV des sommets adjacents, et appliquons le coefficient. coefficient d'interpolation au même sommet dans l'espace tridimensionnel. Sur les coordonnées tridimensionnelles, les coordonnées spatiales tridimensionnelles des os correspondants peuvent être interpolées. 🎜Grâce à cette méthode de modélisation, nous unifions les positions de liaison et les coefficients de poids cutané des os en un ensemble de coefficients dans l'espace UV. Lors de l'utilisation de l'ASM, nous convertissons la déformation des sommets du maillage du visage en une combinaison du coefficient de décalage de la position de liaison osseuse dans l'espace UV, du coefficient de skinning du mélange gaussien dans l'espace UV et du coefficient de mouvement osseux, Amélioration considérable de l'expression capacité du modèle à la peau squelettique à générer des détails faciaux plus riches.每 Tableau 1 : La dimension paramétrique de chaque os de l'ASM

Résultats de la recherche : la capacité d'expression du visage humain et la précision de la reconstruction multi-vues atteignent le niveau SOTA Comparaison des différents paramétrages du modèle de visage humain Capacité
Nous utiliser un modèle de visage paramétrique pour enregistrer un modèle de numérisation de visage de haute précision (Enregistrement), combinant ASM avec le 3DMM traditionnel basé sur les méthodes PCA (BFM [6], FLAME [7], FaceScape [10]), 3DMM basé sur le réseau neuronal La méthode de réduction de dimensionnalité (CoMA [8], ImFace [9]) et le modèle à peau osseuse leader de l'industrie (MetaHuman) ont été comparés. Les résultats ont souligné que la capacité d'expression d'ASM a atteint le niveau SOTA sur les ensembles de données LYHM et FaceScape. Tableau 2 : Précision de l'enregistrement de LYHM et de FaceScape Figure 3 : Résultats de la visualisation LYHM et carte thermique des erreurs d'enregistrement sur FaceScape
Application dans la reconstruction de visage multi-vues
Nous avons utilisé l'ensemble de données Florence MICC pour tester les performances de ASM sur la tâche de reconstruction de visage multi-vues La précision de reconstruction sur l'ensemble de test Coop (caméra intérieure à courte portée, personnages sans expression) atteint le niveau SOTA.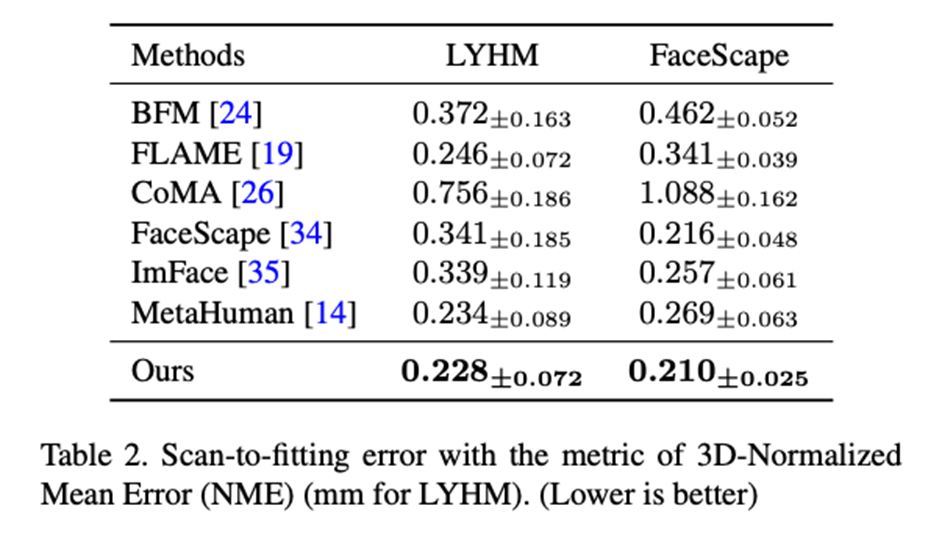
Figure 4 : Résultats de la reconstruction du visage en 3D sur l'ensemble de données Florence MICC
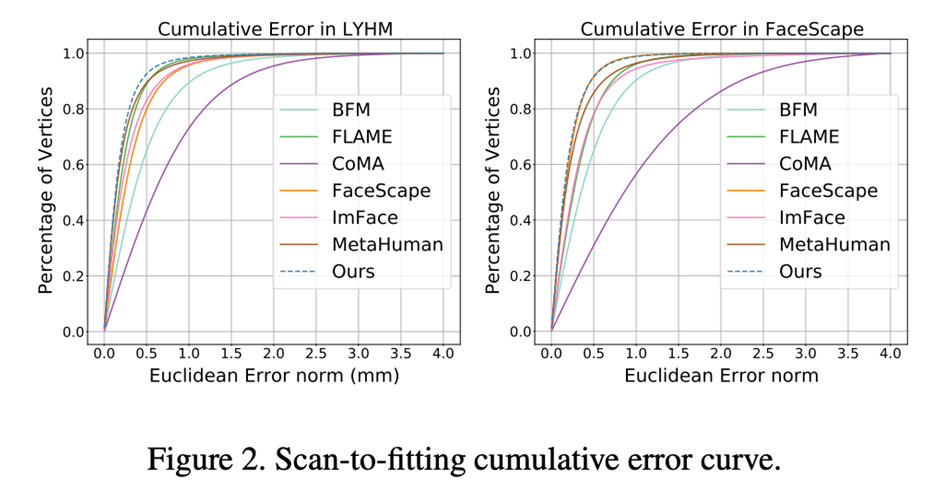 Nous avons également testé le nombre d'images sur l'ensemble de données FaceScape. L'impact des résultats, les résultats peuvent être vus Quand le nombre d'images est d'environ 5, l'ASM peut atteindre la plus grande précision de reconstruction par rapport aux autres méthodes d'expression du visage. E Tableau 3 : Résultats de reconstruction multi-perspectives de différentes quantités d'entrée sur FaceScape
Nous avons également testé le nombre d'images sur l'ensemble de données FaceScape. L'impact des résultats, les résultats peuvent être vus Quand le nombre d'images est d'environ 5, l'ASM peut atteindre la plus grande précision de reconstruction par rapport aux autres méthodes d'expression du visage. E Tableau 3 : Résultats de reconstruction multi-perspectives de différentes quantités d'entrée sur FaceScape
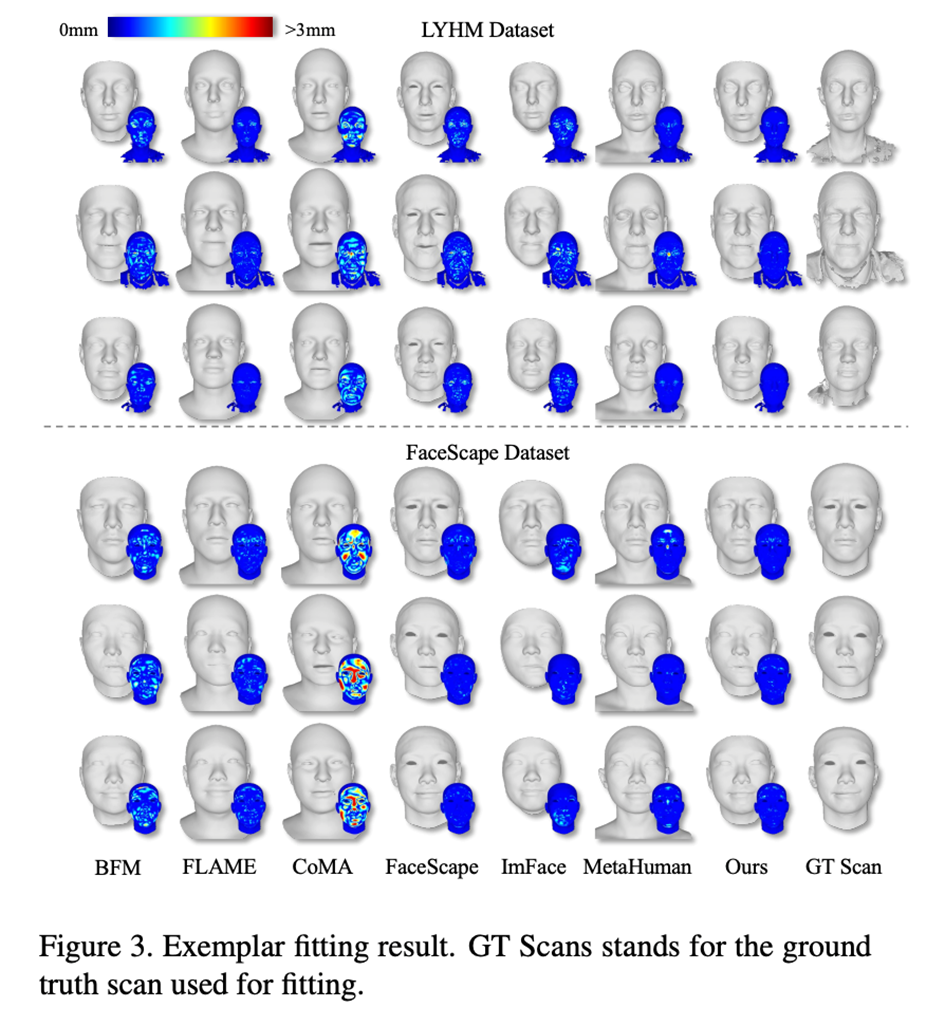 Figure 5 : Résultats de reconstruction multi-perspectives et erreurs de différentes entrées sur Facescape
Figure 5 : Résultats de reconstruction multi-perspectives et erreurs de différentes entrées sur Facescape
Résumé et perspectivesCette recherche franchit une étape importante vers la résolution du problème industriel consistant à obtenir des visages humains haute fidélité à faible coût. Le nouveau modèle paramétrique de visage que nous avons proposé améliore considérablement la capacité d'expression faciale et élève la limite supérieure de précision de la reconstruction de visage multi-vues à un nouveau niveau. Cette méthode peut être utilisée dans de nombreux domaines tels que la modélisation de personnages 3D dans la production de jeux, le gameplay de pincement automatique du visage et la génération d'avatars en AR/VR.
Après que la capacité d'expression faciale ait été considérablement améliorée, la manière de construire des contraintes de cohérence plus fortes à partir d'images multi-vues pour améliorer encore la précision des résultats de reconstruction est devenue un nouveau goulot d'étranglement et un nouveau défi dans le domaine actuel de la reconstruction du visage. Ce sera également notre future direction de recherche.
Références
[1] Noranart Vesdapunt, Mitch Rundle, HsiangTao Wu et Baoyuan Wang : Représentation de plate-forme neuronale basée sur les articulations pour la modélisation compacte du visage en 3D In Computer Vision–ECCV 2020 : 16e Conférence européenne, Glasgow. , Royaume-Uni, 23-28 août 2020, Actes, Partie XVIII 16, pages 389-405.
[2] Thabo Beeler, Bernd Bickel, Paul Beardsley, Bob Sumner et Markus Gross High -. capture unique de qualité de la géométrie du visage. Dans les articles ACM SIGGRAPH 2010, pages 1 à 9.
[3] Yu Deng, Jiaolong Yang, Sicheng Xu, Dong Chen, Yunde Jia et Xin Tong. reconstruction du visage avec apprentissage faiblement supervisé : d'une image unique à un ensemble d'images. Dans les actes de la conférence IEEE/CVF sur les ateliers de vision par ordinateur et de reconnaissance de formes, pages 0-0, 2019.
[4] Yao Feng, Haiwen Feng. , Michael J Black et Timo Bolkart. Apprentissage d'un modèle de visage 3D détaillé animable à partir d'images sauvages ACM Transactions on Graphics (ToG), 40 (4):1-13, 2021.
[5 ] Volker Blanz et Thomas Vetter. Un modèle morphable pour la synthèse de visages 3D Dans Actes de la 26e conférence annuelle sur l'infographie et les techniques interactives, pages 187-194, 1999. [6] Pascal Paysan, Reinhard Knothe, Brian Amberg, Sami. Romdhani et Thomas Vetter. Un modèle de visage 3D pour la reconnaissance faciale invariante de pose et d'éclairage En 2009, sixième conférence internationale de l'IEEE sur la surveillance avancée basée sur la vidéo et le signal, pages 296-301.
[7] Tianye Li. , Timo Bolkart, Michael J Black, Hao Li et Javier Romero. Apprentissage d'un modèle de forme et d'expression du visage à partir de scans 4D., 36 (6) : 194-1, 2017.
[8. ] Anurag Ranjan, Timo Bolkart, Soubhik Sanyal et Michael J Black Génération de visages 3D à l'aide d'auto-encodeurs à maillage convolutif dans Actes de la conférence européenne sur la vision par ordinateur (ECCV), pages 704-720, 2018.
[9] Mingwu Zheng, Hongyu Yang, Di Huang et Liming Chen : Un modèle de visage morphable en 3D non linéaire avec des représentations neuronales implicites, dans les actes de la conférence IEEE/CVF sur la vision par ordinateur et la reconnaissance de formes, pages 20343-20352.
[10] Haotian Yang, Hao Zhu, Yanru Wang, Mingkai Huang, Qiu Shen, Ruigang Yang et Xun Cao : un ensemble de données de visage 3D à grande échelle et de haute qualité et une prédiction détaillée des visages 3D dans les actes de l'IEEE. /Conférence CVF sur la vision par ordinateur et la reconnaissance de formes, pages 601-610, 2020.Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment flasher le téléphone Xiaomi
Comment flasher le téléphone Xiaomi
 Comment centrer un div en CSS
Comment centrer un div en CSS
 Comment ouvrir un fichier rar
Comment ouvrir un fichier rar
 Méthodes de lecture et d'écriture de fichiers Java DBF
Méthodes de lecture et d'écriture de fichiers Java DBF
 Comment résoudre le problème de l'absence du fichier msxml6.dll
Comment résoudre le problème de l'absence du fichier msxml6.dll
 Formules de permutation et de combinaison couramment utilisées
Formules de permutation et de combinaison couramment utilisées
 Numéro de téléphone mobile virtuel pour recevoir le code de vérification
Numéro de téléphone mobile virtuel pour recevoir le code de vérification
 album photo dynamique
album photo dynamique








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



