
 Périphériques technologiques
IA
Excellente pratique de reconstruction 3D de la conduite intelligente sur le cloud
Périphériques technologiques
IA
Excellente pratique de reconstruction 3D de la conduite intelligente sur le cloud
Excellente pratique de reconstruction 3D de la conduite intelligente sur le cloud


Le développement continu de la technologie de conduite intelligente modifie nos méthodes de déplacement et nos systèmes de transport. En tant que technologie clé, la reconstruction 3D joue un rôle important dans les systèmes de conduite intelligents. En plus des algorithmes de perception et de reconstruction de la voiture elle-même, la mise en œuvre et le développement de technologies de conduite autonome nécessitent la prise en charge d'énormes capacités de reconstruction dans le cloud. Le laboratoire multimédia Volcano Engine utilise une technologie de reconstruction 3D auto-développée de pointe, combinée à un cloud puissant. ressources et capacités de la plate-forme, pour aider à la mise en œuvre et à l'application de technologies associées dans des scénarios tels que la reconstruction à grande échelle, l'annotation automatique et la simulation réaliste sur le cloud.
Cet article se concentre sur les principes et les pratiques de la technologie de reconstruction 3D du Volcano Engine Multimedia Laboratory dans des scènes dynamiques et statiques et combiné avec une technologie avancée de reconstruction de champ lumineux pour aider chacun à mieux comprendre et comprendre comment la reconstruction 3D intelligente sur le cloud sert le domaine de l'intelligence. conduite, pour aider au développement de l’industrie.
1. Défis et difficultés techniques
La reconstruction de scènes de conduite nécessite une reconstruction tridimensionnelle au niveau d'un nuage de points de l'environnement routier. Par rapport aux scénarios d'application traditionnels de la technologie de reconstruction tridimensionnelle, la technologie de reconstruction de scènes de conduite présente les difficultés suivantes :
- Processus de fonctionnement du véhicule Les facteurs environnementaux dans le véhicule sont complexes et incontrôlables. Les différentes conditions météorologiques, l'éclairage, la vitesse du véhicule, les conditions routières, etc. affecteront tous les données collectées par les capteurs embarqués, ce qui pose un défi pour la robustesse de la reconstruction. technologie.
- La dégradation des caractéristiques et la perte de texture se produisent souvent dans les scènes de route. Par exemple, la caméra obtient des informations d'image qui ne sont pas riches en caractéristiques visuelles, ou le lidar obtient des informations sur la structure de la scène avec une grande similarité. La clé de la reconstruction. L'un des facteurs est que la couleur est unique et manque d'informations sur la texture, ce qui impose des exigences plus élevées à la technologie de reconstruction.
- Il existe un grand nombre de capteurs montés sur véhicule. Les plus courants incluent les caméras, le lidar, le radar à ondes millimétriques, la navigation inertielle, le système de positionnement GPS, l'indicateur de vitesse de roue, etc. Comment fusionner les données de plusieurs capteurs pour obtenir une reconstruction plus précise. résultats ? La technologie présente des défis.
- La présence d'objets dynamiques tels que des véhicules en mouvement, des véhicules non motorisés et des piétons sur la route posera des défis aux algorithmes de reconstruction traditionnels. Comment éliminer les objets dynamiques qui interfèrent avec la reconstruction de scènes statiques et estimer la position, la taille et la taille. vitesse des objets dynamiques en même temps, ce qui est aussi une des difficultés du projet.
2. Introduction à la technologie de reconstruction de scènes de conduite
Les algorithmes de reconstruction dans le domaine de la conduite autonome utilisent généralement le radar laser et les caméras comme technologie principale, complétés par le GPS et la navigation inertielle. Le LiDAR peut obtenir directement des informations de portée de haute précision et obtenir rapidement la structure de la scène grâce à l'étalonnage conjoint pré-lidar-caméra, l'image obtenue par la caméra peut donner de la couleur, de la sémantique et d'autres informations au nuage de points laser. Dans le même temps, le GPS et la navigation inertielle peuvent aider au positionnement et réduire la dérive causée par la dégradation des caractéristiques pendant le processus de reconstruction. Cependant, en raison du prix élevé du lidar multiligne, il est généralement utilisé dans les véhicules d'ingénierie et est difficile à utiliser à grande échelle dans les véhicules produits en série.
À cet égard, Volcano Engine Multimedia Laboratory a développé indépendamment un ensemble de technologies de reconstruction de scènes de conduite purement visuelles, y compris la reconstruction de scènes statiques, la reconstruction d'objets dynamiques et la technologie de reconstruction de champ de rayonnement neuronal, qui peuvent distinguer les objets dynamiques et statiques dans la scène et restaurer scènes statiques. Le nuage de points dense de la scène met en évidence les éléments clés tels que les revêtements routiers, les panneaux et les feux de circulation ; il peut estimer efficacement la position, la taille, l'orientation et la vitesse des objets en mouvement dans la scène pour une annotation 4D ultérieure ; reconstruire des scènes statiques Fondamentalement, le champ de rayonnement neuronal est utilisé pour reconstruire et reproduire la scène afin d'obtenir une itinérance en vue libre, qui peut être utilisée pour l'édition de scènes et le rendu de simulation. Cette solution technique ne repose pas sur le lidar et peut atteindre des erreurs relatives de l'ordre du décimètre, obtenant ainsi des effets de reconstruction proches du lidar avec des coûts matériels minimes.
2.1 Technologie de reconstruction de scène statique : éliminez les interférences dynamiques et restaurez les scènes statiques
La technologie de reconstruction visuelle est basée sur une géométrie multi-vues et nécessite que la scène ou l'objet à reconstruire ait une cohérence inter-images, c'est-à-dire dans différentes images. dans un état stationnaire, les objets dynamiques doivent donc être éliminés pendant le processus de reconstruction. Selon l'importance des différents éléments de la scène, les nuages de points non pertinents doivent être supprimés du nuage de points dense, tandis que certains nuages de points d'éléments clés sont conservés. Par conséquent, l'image doit être sémantiquement segmentée à l'avance. À cet égard, Volcano Engine Multimedia Laboratory combine la technologie de l'IA et les principes de base de la géométrie multi-vues pour créer un cadre d'algorithme de reconstruction visuelle avancé, robuste, précis et complet. Le processus de reconstruction comprend trois étapes clés : le prétraitement de l’image, la reconstruction clairsemée et la reconstruction dense.
La caméra montée sur le véhicule est en mouvement pendant la prise de vue. En raison du temps d'exposition, un flou de mouvement important apparaîtra dans les images collectées à mesure que la vitesse du véhicule augmente. De plus, afin d'économiser de la bande passante et de l'espace de stockage, l'image sera compressée de manière irréversible avec perte pendant le processus de transmission, provoquant une dégradation supplémentaire de la qualité de l'image. À cette fin, le laboratoire multimédia Volcano Engine utilise un réseau neuronal de bout en bout pour supprimer le flou de l'image, ce qui peut améliorer la qualité de l'image tout en supprimant le flou de mouvement. La comparaison avant et après suppression du flou est présentée dans la figure ci-dessous.

Avant le défloutage (à gauche) Après le défloutage (à droite)
Afin de distinguer les objets dynamiques, le laboratoire multimédia Volcano Engine utilise une technologie de reconnaissance d'objets dynamiques basée sur le flux optique, qui peut obtenir un masque d'objets dynamiques au niveau des pixels . Dans le processus de reconstruction de scène statique ultérieur, les points caractéristiques tombant sur la zone d'objet dynamique seront éliminés et seuls les scènes et objets statiques seront conservés.

Flux optique (à gauche) Objet en mouvement (à droite)
Pendant le processus de reconstruction clairsemée, la position, l'orientation et le nuage de points de scène de la caméra doivent être calculés simultanément. Les algorithmes couramment utilisés incluent l'algorithme SLAM (simultané). localisation et cartographie) et l'algorithme SFM (Structure from Motion, SfM en abrégé). L'algorithme SFM peut atteindre une précision de reconstruction plus élevée sans nécessiter de performances en temps réel. Cependant, l'algorithme SFM traditionnel traite généralement chaque caméra comme une caméra indépendante, alors que plusieurs caméras sont généralement disposées dans des directions différentes sur le véhicule, et les positions relatives entre ces caméras sont en fait fixes (en ignorant les changements subtils causés par les vibrations). . Si les contraintes de position relative entre les caméras sont ignorées, l'erreur de pose calculée de chaque caméra sera relativement importante. De plus, lorsque l’occlusion est sévère, la pose des caméras individuelles sera difficile à calculer. À cet égard, le laboratoire multimédia Volcano Engine a auto-développé un algorithme SFM basé sur l'ensemble du groupe de caméras, qui peut utiliser les contraintes de pose relatives antérieures entre les caméras pour calculer la pose du groupe de caméras dans son ensemble, et utilise également le GPS plus l'inertie. La fusion des résultats de positionnement pour contraindre la position centrale du groupe de caméras peut améliorer efficacement le taux de réussite et la précision de l'estimation de la pose, améliorer les incohérences des nuages de points entre les différentes caméras et réduire la superposition des nuages de points.


SFM traditionnel (à gauche) Groupe de caméras SFM (à droite)
En raison de la couleur unique et du manque de texture sur le sol, il est difficile pour la reconstruction visuelle traditionnelle de restaurer l'intégralité du sol, mais il y a des lignes de voie, des éléments clés tels que des flèches, du texte/logos, etc. Par conséquent, le laboratoire multimédia Volcano Engine utilise une surface quadratique pour s'adapter au sol afin de faciliter l'estimation de la profondeur et la fusion des nuages de points de la zone au sol. Par rapport à l'ajustement plan, la surface quadratique est plus adaptée aux scènes de route réelles, car la surface de route réelle n'est souvent pas un plan idéal. Ce qui suit est une comparaison des effets de l'utilisation d'équations planes et d'équations de surface quadratiques pour s'adapter au sol.

Équation plane (à gauche) Équation de surface quadratique (à droite)
En considérant le nuage de points laser comme la vraie valeur et en y superposant les résultats de la reconstruction visuelle, la précision du nuage de points reconstruit peut être mesurée intuitivement . Comme vous pouvez le voir sur la figure ci-dessous, l'ajustement entre le nuage de points reconstruit et le véritable nuage de points est très élevé. Après la mesure, l'erreur relative du résultat de la reconstruction est d'environ 15 cm.

Résultats de reconstruction du Volcano Engine Multimedia Laboratory (couleur) et nuages de points réels (blanc)
Ce qui suit est une comparaison des effets de l'algorithme de reconstruction visuelle du Volcano Engine Multimedia Laboratory et d'un logiciel de reconstruction commercial grand public. On peut constater que par rapport aux logiciels commerciaux, l'algorithme auto-développé par le laboratoire multimédia Volcano Engine a un effet de reconstruction meilleur et plus complet des panneaux de signalisation, des feux de circulation, des poteaux téléphoniques, ainsi que des lignes de voie et des flèches sur la route. ont un très haut degré de restauration. Cependant, le nuage de points reconstruit à partir de logiciels commerciaux est très clairsemé et la surface de la route est manquante sur de grandes zones.

Un logiciel commercial grand public (à gauche) Algorithme de laboratoire multimédia Volcano Engine (à droite)
2.2 Technologie de reconstruction dynamique :
Il est très difficile d'annoter des objets en 3D sur des images et nécessite l'aide de nuages de points. Lorsque le véhicule ne dispose que de capteurs visuels, il est très difficile d'obtenir un nuage de points complet de l'objet cible. dans la scène. En particulier pour les objets dynamiques, les nuages de points denses ne peuvent pas être obtenus à l'aide des techniques traditionnelles de reconstruction 3D. Afin de fournir l'expression d'objets en mouvement et de servir l'annotation 4D, la boîte englobante 3D (ci-après appelée Bbox 3D) est utilisée pour représenter les objets dynamiques, ainsi que la posture, la taille et la vitesse de la Bbox 3D des objets dynamiques dans la scène à chaque fois. Le moment est obtenu grâce à des algorithmes de reconstruction dynamique auto-développés, etc., complétant ainsi les capacités de reconstruction dynamique d'objets.
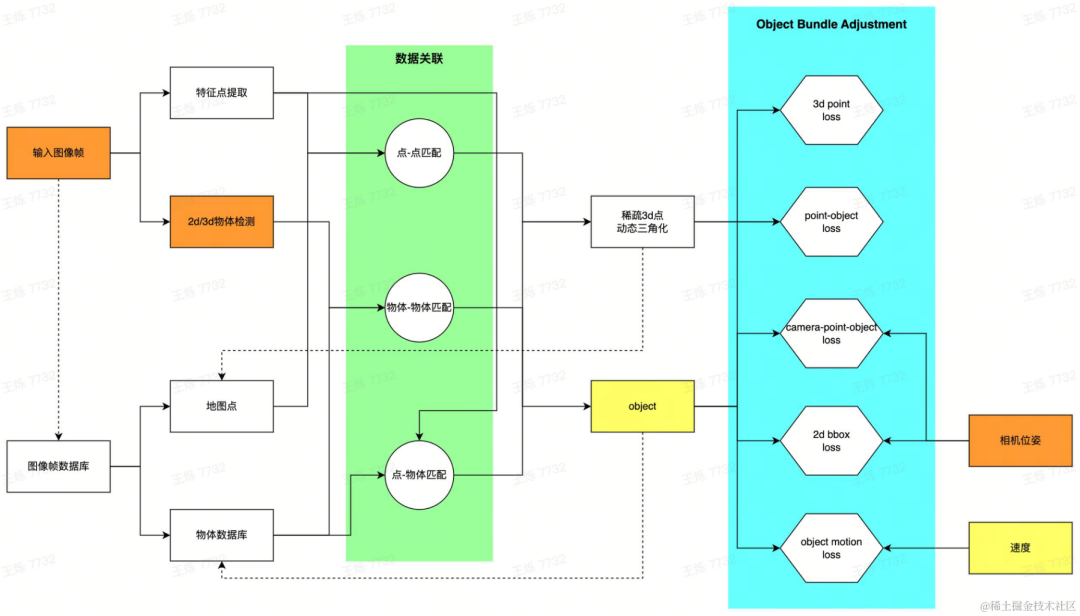
Pipeline de reconstruction dynamique
Pour chaque image collectée par le véhicule, extrayez d'abord la cible dynamique dans la scène et générez une proposition initiale de bbox 3D. Deux méthodes sont proposées : en utilisant la détection de cible 2D et via. pose de la caméra Estimez la bbox 3D correspondante ; utilisez directement la détection de cible 3D. Les deux méthodes peuvent être sélectionnées de manière flexible pour différentes données. La détection 2D a une bonne généralisation et la détection 3D peut obtenir de meilleures valeurs initiales. Dans le même temps, les points caractéristiques à l'intérieur de la zone dynamique de l'image sont extraits. Après avoir obtenu la proposition initiale de bbox 3D et les points caractéristiques d'une image à image unique, établissez une corrélation de données entre plusieurs images : établissez la correspondance d'objets via un algorithme de suivi multi-cibles auto-développé et faites correspondre les caractéristiques de l'image grâce à une technologie de correspondance de caractéristiques. Après avoir obtenu la relation de correspondance, les trames d'image ayant des relations de vue communes sont créées sous forme de cartes locales, et un problème d'optimisation est construit pour résoudre l'estimation de bbox cible globalement cohérente. Plus précisément, grâce à la correspondance de points caractéristiques et à la technologie de triangulation dynamique, les points 3D dynamiques sont restaurés ; le mouvement du véhicule est modélisé et les observations entre les objets, les points 3D et les caméras sont optimisées conjointement pour obtenir la bbox 3D d'objet dynamique estimée optimale.

Exemple de détection de cible 3D générée en 2D (deuxième à partir de la gauche)
2.3 NeRFReconstruction : rendu photoréaliste, perspective libre
Utiliser le réseau neuronal pour la reconstruction implicite, en utilisant A Le modèle de rendu différenciable apprend à restituer des images sous de nouvelles perspectives à partir de vues existantes, obtenant ainsi un rendu d'image photoréaliste, c'est-à-dire la technologie Neural Radiation Field (NeRF). Dans le même temps, la reconstruction implicite a les caractéristiques d'être modifiable et d'interroger un espace continu, et peut être utilisée pour des tâches telles que l'annotation automatique et la construction de données de simulation dans des scénarios de conduite autonome. La reconstruction de scènes à l’aide de la technologie NeRF est extrêmement précieuse.
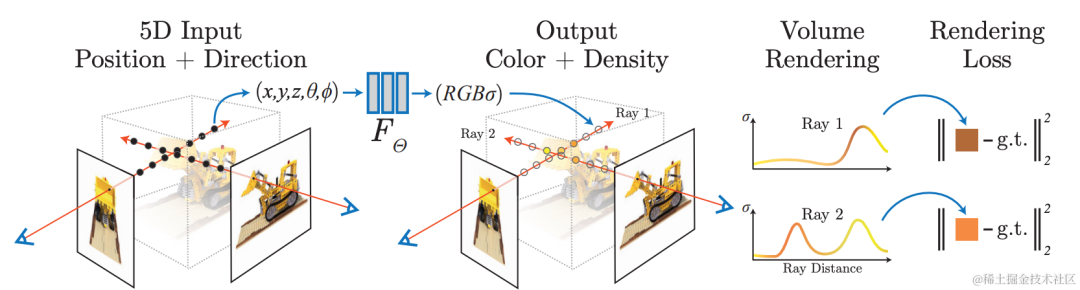
Le laboratoire multimédia Volcano Engine combine la technologie du champ de rayonnement neuronal et la technologie de modélisation de grandes scènes. Dans la pratique spécifique, les données sont d'abord traitées. Les objets dynamiques dans la scène provoqueront des artefacts dans la reconstruction NeRF. À l'aide de la segmentation dynamique et statique auto-développée, de la détection des ombres et d'autres algorithmes, les zones de la scène qui sont incompatibles. la géométrie est extraite et un masque est généré en même temps, l'algorithme d'inpainting vidéo est utilisé pour réparer les zones supprimées. À l'aide de capacités de reconstruction 3D auto-développées, une reconstruction géométrique de haute précision de la scène est effectuée, y compris l'estimation des paramètres de la caméra et la génération de nuages de points clairsemés et denses. De plus, le scénario est divisé pour réduire la consommation de ressources de formation uniques, et une formation et une maintenance distribuées peuvent être effectuées. Au cours du processus d'entraînement au champ de rayonnement neuronal, pour les grandes scènes extérieures sans bordure, l'équipe a utilisé certaines stratégies d'optimisation pour améliorer le nouvel effet de génération de perspective dans cette scène, comme l'amélioration de la précision de la reconstruction en optimisant simultanément les poses pendant l'entraînement et en fonction du niveau de Le codage de hachage. L'expression améliore la vitesse de formation du modèle, le codage d'apparence est utilisé pour améliorer la cohérence de l'apparence des scènes collectées à différents moments et les informations de profondeur denses mvs sont utilisées pour améliorer la précision géométrique. L'équipe a coopéré avec HaoMo Zhixing pour réaliser l'acquisition monocanal et la reconstruction NeRF fusionnée multicanal. Les résultats pertinents ont été publiés lors de la journée Haomo AI.

Culling dynamique d'objets/ombres, remplissage
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Le géant du cloud computing lance une bataille juridique : Amazon poursuit Nokia pour violation de brevet
Jul 31, 2024 pm 12:47 PM
Le géant du cloud computing lance une bataille juridique : Amazon poursuit Nokia pour violation de brevet
Jul 31, 2024 pm 12:47 PM
Selon des informations publiées sur ce site le 31 juillet, le géant de la technologie Amazon a poursuivi mardi la société de télécommunications finlandaise Nokia devant le tribunal fédéral du Delaware, l'accusant d'avoir violé plus d'une douzaine de brevets d'Amazon liés à la technologie de cloud computing. 1. Amazon a déclaré dans le procès que Nokia avait abusé des technologies liées à Amazon Cloud Computing Service (AWS), notamment l'infrastructure de cloud computing, les technologies de sécurité et de performance, pour améliorer ses propres produits de services cloud. Amazon a lancé AWS en 2006 et sa technologie révolutionnaire de cloud computing a été développée depuis le début des années 2000, indique la plainte. "Amazon est un pionnier du cloud computing et Nokia utilise désormais les innovations brevetées d'Amazon en matière de cloud computing sans autorisation", indique la plainte. Amazon demande au tribunal une injonction de blocage
 Prenant en charge NOA pour les villes non illustrées, la marque Blue Mountain Smart Driving Edition de Great Wall Wei devrait être officiellement lancée en juin.
May 09, 2024 pm 09:10 PM
Prenant en charge NOA pour les villes non illustrées, la marque Blue Mountain Smart Driving Edition de Great Wall Wei devrait être officiellement lancée en juin.
May 09, 2024 pm 09:10 PM
Selon des informations publiées le 9 mai 2024, lors du Salon international de l'auto de Pékin de cette année, Wei Brand, une filiale de Great Wall Motors, a lancé un nouveau modèle, la Blue Mountain Smart Driving Edition, qui a attiré l'attention de nombreux visiteurs. Selon « Knowing Car Emperor's Vision », cette nouvelle voiture très attendue devrait atterrir officiellement sur le marché en juin de cette année. Le design de la Blue Mountain Smart Driving Edition continue de suivre l'apparence classique du Blue Mountain DHT-PHEV en vente, mais il a été considérablement amélioré en termes de perception de conduite intelligente. Ce qui attire le plus l'attention, c'est qu'un lidar de style tour de guet est installé sur le toit. Parallèlement, le véhicule est également équipé de radars à ondes millimétriques de 3 et de 12 radars à ultrasons, ainsi que de 11 caméras de perception visuelle haute définition. pour un total de 27 capteurs de conduite assistée améliorent considérablement les capacités de perception environnementale du véhicule. selon
 La nouvelle Volkswagen Magotan B9 est sur le point d'être lancée, avec des améliorations complètes pour mener la nouvelle tendance de la conduite intelligente
May 09, 2024 pm 05:50 PM
La nouvelle Volkswagen Magotan B9 est sur le point d'être lancée, avec des améliorations complètes pour mener la nouvelle tendance de la conduite intelligente
May 09, 2024 pm 05:50 PM
Selon les informations du 9 mai 2007, depuis son entrée sur le marché chinois en 2007, la Volkswagen Magotan a vendu plus de 2 millions de voitures en Chine en tirant parti de son savoir-faire exquis et de ses performances complètes dérivées des prototypes allemands, gagnant ainsi la reconnaissance des consommateurs. Récemment, la nouvelle génération très attendue de Volkswagen Magotan (B9 Magotan) fera officiellement ses débuts en juin, apportant une mise à niveau et une innovation complètes. Le nouveau Magotan a subi des réformes drastiques tant dans son design extérieur que dans son aménagement intérieur. Le changement le plus important est que le nouveau modèle adopte la technologie de conduite intelligente de pointe de DJI, améliorant considérablement le niveau d'intelligence de la conduite autonome et de la conduite assistée. En termes de design extérieur, le design des phares plus élancé du nouveau Magotan, combiné à des bandes lumineuses traversantes et un LOGO éclairé, crée un effet visuel plus large sur l'avant de la voiture.
 Meilleures pratiques de cloud computing C++ : considérations relatives au déploiement, à la gestion et à l'évolutivité
Jun 01, 2024 pm 05:51 PM
Meilleures pratiques de cloud computing C++ : considérations relatives au déploiement, à la gestion et à l'évolutivité
Jun 01, 2024 pm 05:51 PM
Pour parvenir à un déploiement efficace des applications cloud C++, les meilleures pratiques incluent : le déploiement conteneurisé, à l'aide de conteneurs tels que Docker. Utilisez CI/CD pour automatiser le processus de publication. Utilisez le contrôle de version pour gérer les modifications du code. Mettez en œuvre la journalisation et la surveillance pour suivre l’état des applications. Utilisez la mise à l’échelle automatique pour optimiser l’utilisation des ressources. Gérez l’infrastructure des applications avec les services de gestion cloud. Utilisez la mise à l’échelle horizontale et la mise à l’échelle verticale pour ajuster la capacité des applications en fonction de la demande.
 Alors que la demande augmente à l'ère de l'intelligence artificielle, AWS, Microsoft et Google continuent d'investir dans le cloud computing
May 06, 2024 pm 04:22 PM
Alors que la demande augmente à l'ère de l'intelligence artificielle, AWS, Microsoft et Google continuent d'investir dans le cloud computing
May 06, 2024 pm 04:22 PM
La croissance des trois géants du cloud computing ne montre aucun signe de ralentissement jusqu’en 2024, Amazon, Microsoft et Google générant tous plus de revenus dans le cloud computing que jamais auparavant. Les trois fournisseurs de cloud ont récemment publié des résultats, poursuivant leur stratégie pluriannuelle de croissance constante des revenus. Le 25 avril, Google et Microsoft ont annoncé leurs résultats. Au premier trimestre de l’exercice 2024 d’Alphabet, le chiffre d’affaires de Google Cloud s’élevait à 9,57 milliards de dollars, soit une augmentation de 28 % sur un an. Les revenus cloud de Microsoft s'élevaient à 35,1 milliards de dollars, soit une augmentation de 23 % sur un an. Le 30 avril, Amazon Web Services (AWS) a déclaré un chiffre d'affaires de 25 milliards de dollars, soit une augmentation de 17 % sur un an, se classant parmi les trois géants. Les fournisseurs de cloud computing ont de quoi se réjouir, avec les taux de croissance des trois leaders du marché au cours du passé
 Alternatives d'application de la technologie Golang dans le domaine du cloud computing
May 09, 2024 pm 03:36 PM
Alternatives d'application de la technologie Golang dans le domaine du cloud computing
May 09, 2024 pm 03:36 PM
Les alternatives de cloud computing Golang incluent : Node.js (léger, piloté par événements), Python (facilité d'utilisation, capacités de science des données), Java (stable, hautes performances) et Rust (sécurité, concurrence). Le choix de l'alternative la plus appropriée dépend des exigences de l'application, de l'écosystème, des compétences de l'équipe et de l'évolutivité.
 Conduisez intelligemment avec les tendances, dépassez les frontières et sortez du cercle ! Zone d'exposition ChinaJoy Smart Travel 2024, guide d'achat de voitures de la génération Z !
May 07, 2024 pm 09:58 PM
Conduisez intelligemment avec les tendances, dépassez les frontières et sortez du cercle ! Zone d'exposition ChinaJoy Smart Travel 2024, guide d'achat de voitures de la génération Z !
May 07, 2024 pm 09:58 PM
Avec les progrès continus de la technologie, les performances des voitures intelligentes s'améliorent de plus en plus et les fonctions innovantes deviennent de plus en plus abondantes, attirant l'attention de plus en plus de jeunes consommateurs, et les jeunes ont également montré un degré élevé d'acceptation et de curiosité envers nouvelles technologies. Le 21e ChinaJoy en 2024 se tiendra au Shanghai New International Expo Center du 26 au 29 juillet. La DreamCar au cœur de la génération Z pourrait apparaître ici. Youth, le nouveau label pour les voitures intelligentes : conduite intelligente, gameplay technologique, design nouveau et besoins personnalisés Pour les jeunes, la différenciation est plus susceptible de les enthousiasmer que l'expérience de conduite. Et cette différenciation est plus importante pour les voitures traditionnelles. développé depuis de nombreuses années, c’est un enjeu important pour les marques corporate. Alors que le marché continue de mûrir et de se développer, de nombreuses années de développement
 Intégration de l'API PHP REST et de la plateforme de cloud computing
Jun 04, 2024 pm 03:52 PM
Intégration de l'API PHP REST et de la plateforme de cloud computing
Jun 04, 2024 pm 03:52 PM
Les avantages de l'intégration de PHPRESTAPI à la plateforme de cloud computing : évolutivité, fiabilité et élasticité. Étapes : 1. Créez un projet et un compte de service GCP. 2. Installez la bibliothèque GoogleAPIPHP. 3. Initialisez la bibliothèque cliente GCP. 4. Développer les points de terminaison de l'API REST. Bonnes pratiques : utiliser la mise en cache, gérer les erreurs, limiter les taux de requêtes, utiliser HTTPS. Cas pratique : Téléchargez des fichiers sur Google Cloud Storage à l'aide de la bibliothèque client Cloud Storage.
