
 Périphériques technologiques
IA
NVIDIA ouvre une nouvelle ère : la « machine à mouvement perpétuel » pour les données d'entraînement des robots
Périphériques technologiques
IA
NVIDIA ouvre une nouvelle ère : la « machine à mouvement perpétuel » pour les données d'entraînement des robots
NVIDIA ouvre une nouvelle ère : la « machine à mouvement perpétuel » pour les données d'entraînement des robots

La plupart des données synthétiques précédentes ont été utilisées pour la formation de grands modèles d'IA. Cette fois, NVIDIA a construit un « grenier de données » pour la formation des robots. L'une des principales raisons pour lesquelles le rythme de développement de la technologie robotique est loin derrière d'autres domaines de l'IA. manque de données. Avec seulement 200 données sources de démonstration humaine, le système peut générer directement 50 000 données de formation.
Face à l'énorme demande de données de l'IA, les ressources de données sont presque épuisées. Par conséquent, diverses entreprises ont commencé à explorer une « nouvelle façon » d'obtenir des données : « créer » leurs propres données. Cependant, la plupart des données synthétiques précédentes étaient utilisées pour la formation de grands modèles d'IA. Cette fois, NVIDIA a créé un « grenier de données » pour la formation des robots.
Un dernier document de recherche de NVIDIA et de l'Université du Texas à Austin présente un système appelé « MimicGen » qui peut générer automatiquement des ensembles de données d'entraînement de robots à grande échelle avec seulement un petit nombre de démonstrations humaines. Jim Fan, scientifique principal chez Nvidia, a déclaré que la société ouvrirait tout en open source, y compris les ensembles de données générés.
Quelle est la taille des données générées ? En utilisant 10 démos humaines, MimicGen peut générer 1 000 exemples synthétiques ; avec 200 démos humaines, MimicGen peut générer directement 50 000 données de formation, impliquant 18 tâches et plusieurs environnements de simulation.
Comment est l'ensemble de données généré ?
MimicGen peut "faire évoluer" la même scène en différentes étapes en fonction des données existantes :

Il peut également générer différents ensembles de données sur un large éventail de distributions de réinitialisation de tâches, notamment l'assemblage d'articles, le versement de café, le nettoyage de tasses, etc. :
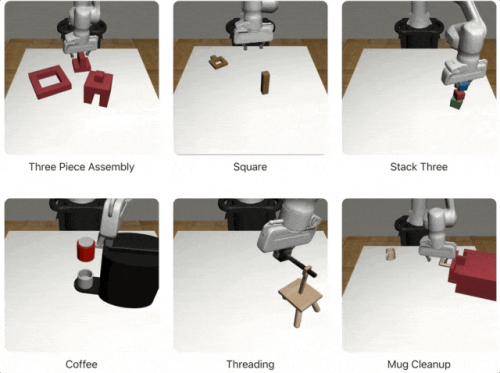
Peut générer différentes nouvelles démos de bras robotisés :
De plus, il existe également des données de tâches qui nécessitent une formation à long terme :

Les données de scènes du monde réel ne posent aucun problème non plus :

Il convient de noter que les chercheurs ont comparé les données générées par différents ensembles de données sources. Cependant, ils ont constaté que les deux ensembles de résultats étaient comparables, ce qui suggère que « la qualité des données (source) n'est peut-être pas aussi importante dans les mécanismes de données à grande échelle » .
De plus, les chercheurs ont également comparé les données générées par 10 démonstrations humaines et 200 démonstrations humaines, et les résultats n'étaient pas non plus très différents. Par conséquent, l’article admet également que des recherches supplémentaires sont nécessaires pour déterminer si davantage de données de démonstration humaine entraîneront une redondance et des coûts d’annotation de données inutiles et inutiles.Pourquoi êtes-vous si obsédé par les données synthétiques ? En plus des ressources de données sources limitées mentionnées au début de l'article, la collecte de données est également extrêmement coûteuse et prend du temps. Avec des systèmes comme MimicGen,
peut générer automatiquement des ensembles de données riches à grande échelle avec seulement une petite quantité de données. et ces données Il intègre plusieurs scènes, capacités d'objets et bras robotiques, et peut également être utilisé pour des tâches à long terme ou de haute précision Il peut être qualifié de « moyen puissant et économique d'étendre l'apprentissage des robots ».
"Les données synthétiques fourniront la prochaine vague de données terascale pour nos modèles affamés. " Jim Fan, scientifique principal de NVIDIA, a déclaré lors de la présentation de MimicGen, "Le développement de la technologie robotique est loin derrière les autres IA. L'une des principales raisons dans ce domaine est la manque de données - vous ne pouvez pas obtenir de signaux de contrôle (des robots) depuis Internet ».
« Nous manquons rapidement de données réelles de haute qualité provenant d'Internet, et l'IA née de données synthétiques sera l'orientation future du développement.
Source : Conseil quotidien de l'innovation scientifique et technologiqueCe qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 L'Ameca deuxième génération est là ! Il peut communiquer couramment avec le public, ses expressions faciales sont plus réalistes et il peut parler des dizaines de langues.
Mar 04, 2024 am 09:10 AM
L'Ameca deuxième génération est là ! Il peut communiquer couramment avec le public, ses expressions faciales sont plus réalistes et il peut parler des dizaines de langues.
Mar 04, 2024 am 09:10 AM
Le robot humanoïde Ameca est passé à la deuxième génération ! Récemment, lors de la Conférence mondiale sur les communications mobiles MWC2024, le robot le plus avancé au monde, Ameca, est à nouveau apparu. Autour du site, Ameca a attiré un grand nombre de spectateurs. Avec la bénédiction de GPT-4, Ameca peut répondre à divers problèmes en temps réel. "Allons danser." Lorsqu'on lui a demandé si elle avait des émotions, Ameca a répondu avec une série d'expressions faciales très réalistes. Il y a quelques jours à peine, EngineeredArts, la société britannique de robotique derrière Ameca, vient de présenter les derniers résultats de développement de l'équipe. Dans la vidéo, le robot Ameca a des capacités visuelles et peut voir et décrire toute la pièce et des objets spécifiques. Le plus étonnant, c'est qu'elle peut aussi
 Le premier robot capable d'accomplir de manière autonome des tâches humaines apparaît, avec cinq doigts flexibles et rapides, et de grands modèles prennent en charge l'entraînement dans l'espace virtuel
Mar 11, 2024 pm 12:10 PM
Le premier robot capable d'accomplir de manière autonome des tâches humaines apparaît, avec cinq doigts flexibles et rapides, et de grands modèles prennent en charge l'entraînement dans l'espace virtuel
Mar 11, 2024 pm 12:10 PM
Cette semaine, FigureAI, une entreprise de robotique investie par OpenAI, Microsoft, Bezos et Nvidia, a annoncé avoir reçu près de 700 millions de dollars de financement et prévoit de développer un robot humanoïde capable de marcher de manière autonome au cours de la prochaine année. Et l’Optimus Prime de Tesla a reçu à plusieurs reprises de bonnes nouvelles. Personne ne doute que cette année sera celle de l’explosion des robots humanoïdes. SanctuaryAI, une entreprise canadienne de robotique, a récemment lancé un nouveau robot humanoïde, Phoenix. Les responsables affirment qu’il peut accomplir de nombreuses tâches de manière autonome, à la même vitesse que les humains. Pheonix, le premier robot au monde capable d'accomplir des tâches de manière autonome à la vitesse d'un humain, peut saisir, déplacer et placer avec élégance chaque objet sur ses côtés gauche et droit. Il peut identifier des objets de manière autonome
 Comment l'IA peut-elle rendre les robots plus autonomes et adaptables ?
Jun 03, 2024 pm 07:18 PM
Comment l'IA peut-elle rendre les robots plus autonomes et adaptables ?
Jun 03, 2024 pm 07:18 PM
Dans le domaine de la technologie de l’automatisation industrielle, il existe deux points chauds récents qu’il est difficile d’ignorer : l’intelligence artificielle (IA) et Nvidia. Ne changez pas le sens du contenu original, affinez le contenu, réécrivez le contenu, ne continuez pas : « Non seulement cela, les deux sont étroitement liés, car Nvidia ne se limite pas à son unité de traitement graphique d'origine (GPU ), il étend son GPU. La technologie s'étend au domaine des jumeaux numériques et est étroitement liée aux technologies émergentes d'IA "Récemment, NVIDIA a conclu une coopération avec de nombreuses entreprises industrielles, notamment des sociétés d'automatisation industrielle de premier plan telles qu'Aveva, Rockwell Automation, Siemens. et Schneider Electric, ainsi que Teradyne Robotics et ses sociétés MiR et Universal Robots. Récemment, Nvidiahascoll
 Après 2 mois, le robot humanoïde Walker S peut plier les vêtements
Apr 03, 2024 am 08:01 AM
Après 2 mois, le robot humanoïde Walker S peut plier les vêtements
Apr 03, 2024 am 08:01 AM
Rédacteur en chef du Machine Power Report : Wu Xin La version domestique de l'équipe robot humanoïde + grand modèle a accompli pour la première fois la tâche d'exploitation de matériaux flexibles complexes tels que le pliage de vêtements. Avec le dévoilement de Figure01, qui intègre le grand modèle multimodal d'OpenAI, les progrès connexes des pairs nationaux ont attiré l'attention. Hier encore, UBTECH, le « stock numéro un de robots humanoïdes » en Chine, a publié la première démo du robot humanoïde WalkerS, profondément intégré au grand modèle de Baidu Wenxin, présentant de nouvelles fonctionnalités intéressantes. Maintenant, WalkerS, bénéficiant des capacités de grands modèles de Baidu Wenxin, ressemble à ceci. Comme la figure 01, WalkerS ne se déplace pas, mais se tient derrière un bureau pour accomplir une série de tâches. Il peut suivre les commandes humaines et plier les vêtements
 Mar 22, 2024 pm 08:51 PM
Mar 22, 2024 pm 08:51 PM
Les 10 robots humanoïdes suivants façonnent notre avenir : 1. ASIMO : Développé par Honda, ASIMO est l'un des robots humanoïdes les plus connus. Mesurant 4 pieds de haut et pesant 119 livres, ASIMO est équipé de capteurs avancés et de capacités d'intelligence artificielle qui lui permettent de naviguer dans des environnements complexes et d'interagir avec les humains. La polyvalence d'ASIMO le rend adapté à une variété de tâches, allant de l'assistance aux personnes handicapées à la réalisation de présentations lors d'événements. 2. Pepper : Créé par Softbank Robotics, Pepper vise à être un compagnon social pour les humains. Avec son visage expressif et sa capacité à reconnaître les émotions, Pepper peut participer à des conversations, aider dans les commerces de détail et même fournir un soutien pédagogique. Poivrons
 Le robot de balayage et de nettoyage Cloud Whale Xiaoyao 001 a un « cerveau » ! Expérience |
Apr 26, 2024 pm 04:22 PM
Le robot de balayage et de nettoyage Cloud Whale Xiaoyao 001 a un « cerveau » ! Expérience |
Apr 26, 2024 pm 04:22 PM
Les robots de balayage et de nettoyage sont l’un des appareils électroménagers intelligents les plus populaires auprès des consommateurs ces dernières années. La commodité d'utilisation qu'il apporte, voire l'absence d'opération, permet aux paresseux de libérer leurs mains, permettant aux consommateurs de « se libérer » des tâches ménagères quotidiennes et de consacrer plus de temps à ce qu'ils aiment. Une qualité de vie améliorée sous une forme déguisée. Surfant sur cet engouement, presque toutes les marques d'électroménager du marché fabriquent leurs propres robots de balayage et de nettoyage, rendant l'ensemble du marché des robots de balayage et de nettoyage très vivant. Cependant, l'expansion rapide du marché entraînera inévitablement un danger caché : de nombreux fabricants utiliseront la tactique de la mer de machines pour occuper rapidement plus de parts de marché, ce qui entraînera de nombreux nouveaux produits sans aucun point de mise à niveau. ce sont des modèles de "matriochka". Ce n'est pas une exagération. Cependant, tous les robots de balayage et de nettoyage ne sont pas
 Le robot humanoïde peut faire de la magie, laissez l'équipe du programme du Gala de la Fête du Printemps en savoir plus
Feb 04, 2024 am 09:03 AM
Le robot humanoïde peut faire de la magie, laissez l'équipe du programme du Gala de la Fête du Printemps en savoir plus
Feb 04, 2024 am 09:03 AM
En un clin d’œil, les robots ont appris à faire de la magie ? On a vu qu'il avait d'abord ramassé la cuillère à eau sur la table, prouvant au public qu'il n'y avait rien dedans... Ensuite, il a mis l'objet en forme d'œuf dans sa main, puis a remis la cuillère à eau sur la table. et a commencé à « jeter un sort »... … Juste au moment où il a repris la cuillère à eau, un miracle s'est produit. L'œuf qui avait été initialement mis dedans a disparu et la chose qui a sauté s'est transformée en ballon de basket... Regardons à nouveau les actions continues : △ Cette animation montre un ensemble d'actions à une vitesse 2x, et cela se déroule sans problème uniquement en regardant. la vidéo à plusieurs reprises à une vitesse de 0,5x peut-elle être comprise. Finalement, j'ai découvert les indices : si la vitesse de ma main était plus rapide, je pourrais peut-être la cacher à l'ennemi. Certains internautes ont déploré que les compétences magiques du robot soient encore supérieures aux leurs : c'est Mag qui a réalisé cette magie pour nous.
 Une université américaine ouvre un concours d'ingénierie 'The Legend of Zelda: Tears of the Kingdom' pour permettre aux étudiants de construire des robots
Nov 23, 2023 pm 08:45 PM
Une université américaine ouvre un concours d'ingénierie 'The Legend of Zelda: Tears of the Kingdom' pour permettre aux étudiants de construire des robots
Nov 23, 2023 pm 08:45 PM
"The Legend of Zelda: Tears of the Kingdom" est devenu le jeu Nintendo le plus vendu de l'histoire. Non seulement Zonav Technology a apporté divers contenus communautaires "Zelda Creator", mais il est également devenu un nouveau cours d'ingénierie à l'université des États-Unis. du Maryland (UMD). Rewrite : The Legend of Zelda : Tears of the Kingdom est l'un des jeux Nintendo les plus vendus jamais enregistrés. Non seulement la technologie Zonav apporte un contenu communautaire riche, mais elle fait également partie du nouveau cours d'ingénierie de l'Université du Maryland. Cet automne, le professeur agrégé Ryan D. Sochol de l'Université du Maryland a ouvert un cours intitulé ".
