
 Périphériques technologiques
IA
DeepMind : Qui a dit que les réseaux convolutifs étaient inférieurs au ViT ?
Périphériques technologiques
IA
DeepMind : Qui a dit que les réseaux convolutifs étaient inférieurs au ViT ?
DeepMind : Qui a dit que les réseaux convolutifs étaient inférieurs au ViT ?

Cet article évalue les NFNets à grande échelle et remet en question l'idée selon laquelle les ConvNets fonctionnent moins bien que les ViT sur des problèmes à grande échelle
Les premiers succès de l'apprentissage profond peuvent être attribués à l'utilisation de réseaux de neurones convolutifs (ConvNets) développer. Les ConvNets dominent les benchmarks de vision par ordinateur depuis près d’une décennie. Ces dernières années, ils ont toutefois été de plus en plus remplacés par des ViT (Vision Transformers).
Beaucoup de gens pensent que les ConvNets fonctionnent bien sur des ensembles de données de petite ou moyenne taille, mais ne peuvent pas rivaliser avec les ViT sur des ensembles de données de plus grande taille.
Entre-temps, la communauté CV est passée de l'évaluation des performances de réseaux initialisés de manière aléatoire sur des ensembles de données spécifiques (tels que ImageNet) à l'évaluation des performances de réseaux pré-entraînés sur de grands ensembles de données générales collectées à partir du réseau. Cela nous amène à une question importante : les Vision Transformers surpassent-ils les architectures ConvNets pré-entraînées avec des budgets de calcul similaires ?
Dans cet article, des chercheurs de Google DeepMind étudient ce problème. En pré-entraînant plusieurs modèles NFNet sur l'ensemble de données JFT-4B à différentes échelles, ils ont obtenu des performances similaires à celles des ViT sur ImageNet

Adresse du lien papier : https://arxiv.org/pdf/ 2310.16764.pdf
Le Les recherches présentées dans cet article traitent du budget informatique de pré-formation compris entre 0,4 000 et 110 000 heures de calcul de base TPU-v4, et utilisent l'augmentation de la profondeur et de la largeur de la famille de modèles NFNet pour effectuer une série de formations réseau. La recherche a révélé qu'il existe une loi d'échelle log-log entre la perte supportée et le budget informatique
Par exemple, cet article sera basé sur JFT-4B, où l'heure de base du TPU-v4 (heure de base) passe de 0,4 k à étendu à 110k et NFNet est pré-entraîné. Après un réglage fin, le plus grand modèle a atteint une précision de 90,4 % sur ImageNet Top-1, rivalisant avec le modèle ViT pré-entraîné avec le même budget de calcul
On peut dire que cet article, en évaluant les NFNets à grande échelle, Remettre en question l’idée selon laquelle les ConvNets fonctionnent moins bien que les ViT sur des ensembles de données à grande échelle. De plus, avec suffisamment de données et de calculs, les ConvNets restent compétitifs, et la conception et les ressources du modèle sont plus importantes que l'architecture.
Après avoir vu cette recherche, Yann LeCun, lauréat du prix Turing, a déclaré : « Pour une quantité de calcul donnée, ViT et ConvNets sont équivalents sur le plan informatique. Bien que les ViT aient obtenu un succès impressionnant en vision par ordinateur, mais à mon avis, il n'y a aucune preuve solide que Le ViT pré-entraîné est meilleur que les ConvNets pré-entraînés lorsqu'il est évalué de manière équitable. Google DeepMind dit que les ConvNets ne disparaîtront jamais
Jetons un coup d'œil au contenu spécifique du document.
Les NFNets pré-entraînés suivent la loi de mise à l'échelle
Dans le tableau ci-dessous, nous pouvons voir trois modèles sur une gamme de budgets d'époque. Le meilleur taux d'apprentissage observé ( c'est-à-dire celui qui minimise la perte de validation). Les chercheurs ont découvert que pour les budgets d’époque inférieurs, la famille de modèles NFNet présentait tous des taux d’apprentissage optimaux similaires, autour de 1,6. Cependant, le taux d'apprentissage optimal diminue à mesure que le budget d'époque augmente, et il diminue plus rapidement pour les modèles plus grands. Les chercheurs ont déclaré que l'on peut supposer que le taux d'apprentissage optimal diminue lentement et de manière monotone avec l'augmentation de la taille du modèle et du budget d'époque, de sorte que le taux d'apprentissage peut être ajusté efficacement entre les essais

Ce qui doit être réécrit est : il convient de noter que certains des modèles pré-entraînés de la figure 2 n'ont pas fonctionné comme prévu. L'équipe de recherche estime que la raison de cette situation est que si l'exécution de formation est anticipée/redémarrée, le processus de chargement des données ne peut pas garantir que chaque échantillon de formation puisse être échantillonné une fois à chaque époque. Si l'exécution de la formation est redémarrée plusieurs fois, certains échantillons de formation peuvent être sous-échantillonnés
NFNet vs ViT
Les expériences sur ImageNet montrent que NFNet et Vision Transformer affinés fonctionnent de manière comparable
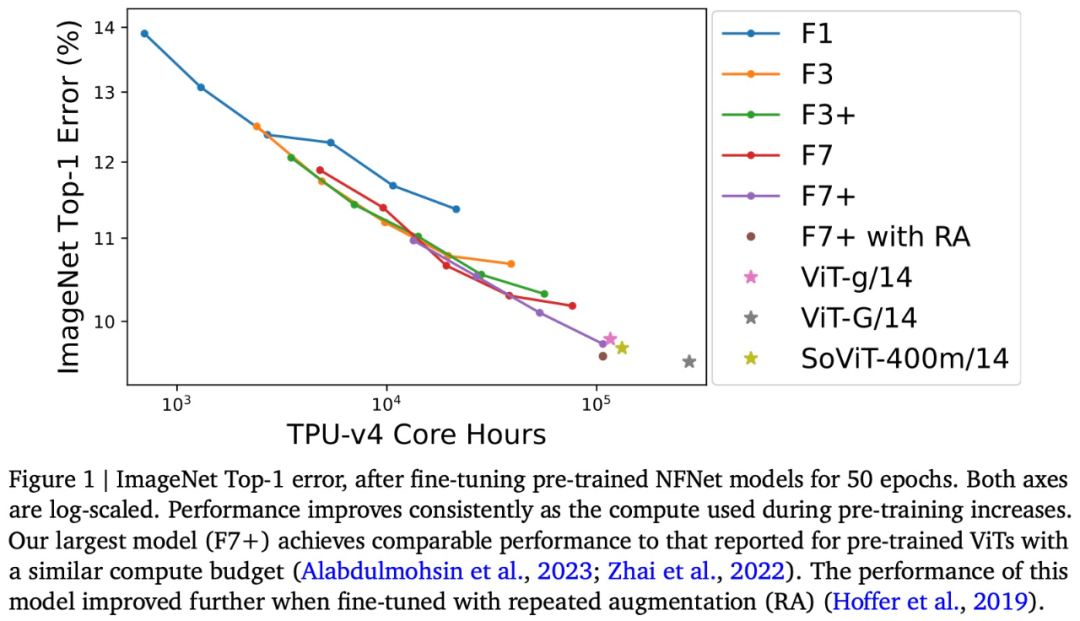
Il a été spécifiquement dit que cette étude a affiné- a réglé le NFNet de pré-formation sur ImageNet et tracé la relation entre le calcul de pré-formation et l'erreur Top-1, comme le montre la figure 1 ci-dessus.
La précision d'ImageNet Top-1 continue de s'améliorer à mesure que le budget augmente. Parmi eux, le modèle pré-entraîné le plus cher est NFNet-F7+, qui est pré-entraîné pendant 8 époques et a une précision de 90,3 % dans ImageNet Top-1. Le pré-entraînement et le réglage précis nécessitent environ 110 000 heures de base TPU-v4 et 1,6 000 heures de base TPU-v4. De plus, si des techniques d'amélioration répétitives supplémentaires sont introduites lors du réglage fin, une précision Top-1 de 90,4 % peut être obtenue. NFNet bénéficie grandement d'une pré-formation à grande échelle
Bien qu'il existe des différences évidentes entre les deux architectures modèles NFNet et ViT, les performances de NFNet pré-entraîné et de ViT pré-entraîné sont comparables. Par exemple, après avoir pré-entraîné JFT-3B avec 210 000 heures de base TPU-v3, ViT-g/14 a atteint une précision Top-1 de 90,2 % sur ImageNet tout en exécutant plus de 500 000 TPU-v3 sur JFT-3B après les heures de base ; de pré-entraînement, ViT-G/14 a atteint une précision Top-1 de 90,45 %
Cet article évalue la vitesse de pré-entraînement de ces modèles sur TPU-v4 et estime que ViT-g/14 nécessite 120 000 cœurs TPU-v4 heures pour se pré-entraîner, tandis que ViTG/14 nécessitera 280 000 heures de base TPU-v4 et SoViT-400m/14 nécessitera 130 000 heures de base TPU-v4. Cet article utilise ces estimations pour comparer l'efficacité de pré-formation de ViT et de NFNet dans la figure 1. L'étude a noté que NFNet est optimisé pour TPU-v4 et fonctionne mal lorsqu'il est évalué sur d'autres appareils.
Enfin, cet article note que les points de contrôle pré-entraînés obtiennent la perte de validation la plus faible sur JFT-4B, mais n'atteignent pas toujours la précision Top-1 la plus élevée sur ImageNet après un réglage fin. En particulier, cet article révèle que dans le cadre d'un budget de calcul fixe avant la formation, le mécanisme de réglage fin a tendance à sélectionner un modèle légèrement plus grand et un budget d'époque légèrement plus petit. Intuitivement, les modèles plus grands ont une plus grande capacité et sont donc mieux à même de s’adapter aux nouvelles tâches. Dans certains cas, un taux d'apprentissage légèrement plus élevé (lors de la pré-entraînement) peut également conduire à de meilleures performances après un réglage fin
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Le robot DeepMind joue au tennis de table, et son coup droit et son revers glissent dans les airs, battant complètement les débutants humains
Aug 09, 2024 pm 04:01 PM
Le robot DeepMind joue au tennis de table, et son coup droit et son revers glissent dans les airs, battant complètement les débutants humains
Aug 09, 2024 pm 04:01 PM
Mais peut-être qu’il ne pourra pas vaincre le vieil homme dans le parc ? Les Jeux Olympiques de Paris battent leur plein et le tennis de table suscite beaucoup d'intérêt. Dans le même temps, les robots ont également réalisé de nouvelles avancées dans le domaine du tennis de table. DeepMind vient tout juste de proposer le premier agent robot apprenant capable d'atteindre le niveau des joueurs amateurs humains de tennis de table de compétition. Adresse papier : https://arxiv.org/pdf/2408.03906 Quelle est la capacité du robot DeepMind à jouer au tennis de table ? Probablement à égalité avec les joueurs amateurs humains : tant en coup droit qu'en revers : l'adversaire utilise une variété de styles de jeu, et le robot peut également résister : recevoir des services avec des tours différents : Cependant, l'intensité du jeu ne semble pas aussi intense que le vieil homme dans le parc. Pour les robots, le tennis de table
 L'auteur de ControlNet a encore un succès ! L'ensemble du processus de génération d'une peinture à partir d'une image, gagnant 1,4k étoiles en deux jours
Jul 17, 2024 am 01:56 AM
L'auteur de ControlNet a encore un succès ! L'ensemble du processus de génération d'une peinture à partir d'une image, gagnant 1,4k étoiles en deux jours
Jul 17, 2024 am 01:56 AM
Il s'agit également d'une vidéo Tusheng, mais PaintsUndo a emprunté une voie différente. L'auteur de ControlNet, LvminZhang, a recommencé à vivre ! Cette fois, je vise le domaine de la peinture. Le nouveau projet PaintsUndo a reçu 1,4kstar (toujours en hausse folle) peu de temps après son lancement. Adresse du projet : https://github.com/lllyasviel/Paints-UNDO Grâce à ce projet, l'utilisateur saisit une image statique et PaintsUndo peut automatiquement vous aider à générer une vidéo de l'ensemble du processus de peinture, du brouillon de ligne au suivi du produit fini. . Pendant le processus de dessin, les changements de lignes sont étonnants. Le résultat vidéo final est très similaire à l’image originale : jetons un coup d’œil à un dessin complet.
 En tête de liste des ingénieurs logiciels d'IA open source, la solution sans agent de l'UIUC résout facilement les problèmes de programmation réels du banc SWE.
Jul 17, 2024 pm 10:02 PM
En tête de liste des ingénieurs logiciels d'IA open source, la solution sans agent de l'UIUC résout facilement les problèmes de programmation réels du banc SWE.
Jul 17, 2024 pm 10:02 PM
La colonne AIxiv est une colonne où ce site publie du contenu académique et technique. Au cours des dernières années, la rubrique AIxiv de ce site a reçu plus de 2 000 rapports, couvrant les meilleurs laboratoires des principales universités et entreprises du monde entier, favorisant efficacement les échanges et la diffusion académiques. Si vous souhaitez partager un excellent travail, n'hésitez pas à contribuer ou à nous contacter pour un rapport. Courriel de soumission : liyazhou@jiqizhixin.com ; zhaoyunfeng@jiqizhixin.com Les auteurs de cet article font tous partie de l'équipe de l'enseignant Zhang Lingming de l'Université de l'Illinois à Urbana-Champaign (UIUC), notamment : Steven Code repair ; doctorant en quatrième année, chercheur
 Du RLHF au DPO en passant par TDPO, les algorithmes d'alignement des grands modèles sont déjà « au niveau des jetons »
Jun 24, 2024 pm 03:04 PM
Du RLHF au DPO en passant par TDPO, les algorithmes d'alignement des grands modèles sont déjà « au niveau des jetons »
Jun 24, 2024 pm 03:04 PM
La colonne AIxiv est une colonne où ce site publie du contenu académique et technique. Au cours des dernières années, la rubrique AIxiv de ce site a reçu plus de 2 000 rapports, couvrant les meilleurs laboratoires des principales universités et entreprises du monde entier, favorisant efficacement les échanges et la diffusion académiques. Si vous souhaitez partager un excellent travail, n'hésitez pas à contribuer ou à nous contacter pour un rapport. Courriel de soumission : liyazhou@jiqizhixin.com ; zhaoyunfeng@jiqizhixin.com Dans le processus de développement de l'intelligence artificielle, le contrôle et le guidage des grands modèles de langage (LLM) ont toujours été l'un des principaux défis, visant à garantir que ces modèles sont à la fois puissant et sûr au service de la société humaine. Les premiers efforts se sont concentrés sur les méthodes d’apprentissage par renforcement par feedback humain (RL
 Travail posthume de l'équipe OpenAI Super Alignment : deux grands modèles jouent à un jeu et le résultat devient plus compréhensible
Jul 19, 2024 am 01:29 AM
Travail posthume de l'équipe OpenAI Super Alignment : deux grands modèles jouent à un jeu et le résultat devient plus compréhensible
Jul 19, 2024 am 01:29 AM
Si la réponse donnée par le modèle d’IA est incompréhensible du tout, oseriez-vous l’utiliser ? À mesure que les systèmes d’apprentissage automatique sont utilisés dans des domaines de plus en plus importants, il devient de plus en plus important de démontrer pourquoi nous pouvons faire confiance à leurs résultats, et quand ne pas leur faire confiance. Une façon possible de gagner confiance dans le résultat d'un système complexe est d'exiger que le système produise une interprétation de son résultat qui soit lisible par un humain ou un autre système de confiance, c'est-à-dire entièrement compréhensible au point que toute erreur possible puisse être trouvé. Par exemple, pour renforcer la confiance dans le système judiciaire, nous exigeons que les tribunaux fournissent des avis écrits clairs et lisibles qui expliquent et soutiennent leurs décisions. Pour les grands modèles de langage, nous pouvons également adopter une approche similaire. Cependant, lorsque vous adoptez cette approche, assurez-vous que le modèle de langage génère
 Une avancée significative dans l'hypothèse de Riemann ! Tao Zhexuan recommande fortement les nouveaux articles du MIT et d'Oxford, et le lauréat de la médaille Fields, âgé de 37 ans, a participé
Aug 05, 2024 pm 03:32 PM
Une avancée significative dans l'hypothèse de Riemann ! Tao Zhexuan recommande fortement les nouveaux articles du MIT et d'Oxford, et le lauréat de la médaille Fields, âgé de 37 ans, a participé
Aug 05, 2024 pm 03:32 PM
Récemment, l’hypothèse de Riemann, connue comme l’un des sept problèmes majeurs du millénaire, a réalisé une nouvelle avancée. L'hypothèse de Riemann est un problème mathématique non résolu très important, lié aux propriétés précises de la distribution des nombres premiers (les nombres premiers sont les nombres qui ne sont divisibles que par 1 et par eux-mêmes, et jouent un rôle fondamental dans la théorie des nombres). Dans la littérature mathématique actuelle, il existe plus d'un millier de propositions mathématiques basées sur l'établissement de l'hypothèse de Riemann (ou sa forme généralisée). En d’autres termes, une fois que l’hypothèse de Riemann et sa forme généralisée seront prouvées, ces plus d’un millier de propositions seront établies sous forme de théorèmes, qui auront un impact profond sur le domaine des mathématiques et si l’hypothèse de Riemann s’avère fausse, alors parmi eux ; ces propositions qui en font partie perdront également de leur efficacité. Une nouvelle percée vient du professeur de mathématiques du MIT, Larry Guth, et de l'Université d'Oxford
 Les articles arXiv peuvent être publiés sous forme de 'barrage', la plateforme de discussion alphaXiv de Stanford est en ligne, LeCun l'aime
Aug 01, 2024 pm 05:18 PM
Les articles arXiv peuvent être publiés sous forme de 'barrage', la plateforme de discussion alphaXiv de Stanford est en ligne, LeCun l'aime
Aug 01, 2024 pm 05:18 PM
acclamations! Qu’est-ce que ça fait lorsqu’une discussion sur papier se résume à des mots ? Récemment, des étudiants de l'Université de Stanford ont créé alphaXiv, un forum de discussion ouvert pour les articles arXiv qui permet de publier des questions et des commentaires directement sur n'importe quel article arXiv. Lien du site Web : https://alphaxiv.org/ En fait, il n'est pas nécessaire de visiter spécifiquement ce site Web. Il suffit de remplacer arXiv dans n'importe quelle URL par alphaXiv pour ouvrir directement l'article correspondant sur le forum alphaXiv : vous pouvez localiser avec précision les paragraphes dans. l'article, Phrase : dans la zone de discussion sur la droite, les utilisateurs peuvent poser des questions à l'auteur sur les idées et les détails de l'article. Par exemple, ils peuvent également commenter le contenu de l'article, tels que : "Donné à".
 Le premier MLLM basé sur Mamba est là ! Les poids des modèles, le code de formation, etc. sont tous open source
Jul 17, 2024 am 02:46 AM
Le premier MLLM basé sur Mamba est là ! Les poids des modèles, le code de formation, etc. sont tous open source
Jul 17, 2024 am 02:46 AM
La colonne AIxiv est une colonne où ce site publie du contenu académique et technique. Au cours des dernières années, la rubrique AIxiv de ce site a reçu plus de 2 000 rapports, couvrant les meilleurs laboratoires des principales universités et entreprises du monde entier, favorisant efficacement les échanges et la diffusion académiques. Si vous souhaitez partager un excellent travail, n'hésitez pas à contribuer ou à nous contacter pour un rapport. Courriel de soumission : liyazhou@jiqizhixin.com ; zhaoyunfeng@jiqizhixin.com. Introduction Ces dernières années, l'application de grands modèles de langage multimodaux (MLLM) dans divers domaines a connu un succès remarquable. Cependant, en tant que modèle de base pour de nombreuses tâches en aval, le MLLM actuel se compose du célèbre réseau Transformer, qui
