
 Périphériques technologiques
IA
Créez des pipelines de données de deep learning efficaces avec Ray
Périphériques technologiques
IA
Créez des pipelines de données de deep learning efficaces avec Ray
Créez des pipelines de données de deep learning efficaces avec Ray

Le GPU requis pour la formation du modèle d'apprentissage profond est puissant mais coûteux. Pour utiliser pleinement le GPU, les développeurs ont besoin d'un canal de transfert de données efficace, capable de transférer rapidement les données vers le GPU lorsqu'il est prêt à calculer la prochaine étape de formation. L'utilisation de Ray peut améliorer considérablement l'efficacité du canal de transmission de données
1 La structure du pipeline de données de formation
Prenons d'abord un coup d'œil au pseudocode de la formation du modèle
for step in range(num_steps):sample, target = next(dataset) # 步骤1train_step(sample, target) # 步骤2
À l'étape 1, obtenez les échantillons et les étiquettes de. le prochain mini-lot. À l'étape 2, ils sont transmis à la fonction train_step, qui les copie sur le GPU, effectue une passe avant et arrière pour calculer la perte et le gradient, et met à jour les poids de l'optimiseur.
Veuillez en savoir plus sur l'étape 1. Lorsque l'ensemble de données est trop volumineux pour tenir en mémoire, l'étape 1 récupère le mini-lot suivant à partir du disque ou du réseau. De plus, l’étape 1 comprend également un certain nombre de prétraitements. Les données d'entrée doivent être converties en tenseurs numériques ou en collections de tenseurs avant d'être introduites dans le modèle. Dans certains cas, d'autres transformations sont également effectuées sur le tenseur avant d'être transmises au modèle, telles que la normalisation, la rotation autour de l'axe, le brassage aléatoire, etc.
Si le workflow est exécuté strictement en séquence, c'est-à-dire que l'étape 1 est effectuée en premier , puis effectuez l'étape 2, le modèle devra alors toujours attendre les opérations d'entrée, de sortie et de prétraitement du prochain lot de données. Le GPU ne sera pas utilisé efficacement et restera inactif pendant le chargement du prochain mini-lot de données.
Pour résoudre ce problème, le pipeline de données peut être considéré comme un problème producteur-consommateur. Le pipeline de données génère de petits lots de données et les écrit dans des tampons limités. Le modèle/GPU consomme des mini-lots de données du tampon, effectue des calculs avant/arrière et met à jour les pondérations du modèle. Si le pipeline de données peut générer de petits lots de données aussi rapidement que le modèle/GPU le consomme, le processus de formation sera très efficace.
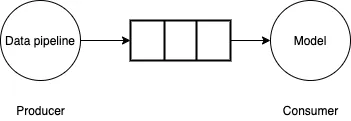 Pictures
Pictures
2. API Tensorflow tf.data
L'API Tensorflow tf.data fournit un riche ensemble de fonctionnalités qui peuvent être utilisées pour créer efficacement des pipelines de données, en utilisant des threads d'arrière-plan pour obtenir de petits lots de données, de sorte que le modèle n'a pas besoin d'attendre. La pré-récupération des données ne suffit pas. Si la génération de petits lots de données est plus lente que le GPU ne peut consommer les données, vous devez alors utiliser la parallélisation pour accélérer la lecture et la transformation des données. À cette fin, Tensorflow fournit une fonctionnalité d'entrelacement pour exploiter plusieurs threads pour lire des données en parallèle, et une fonctionnalité de mappage parallèle pour utiliser plusieurs threads pour transformer de petits lots de données.
Étant donné que ces API sont basées sur le multi-threading, elles peuvent être restreintes par le Python Global Interpreter Lock (GIL). Le GIL de Python limite le bytecode à un seul thread exécuté à la fois. Si vous utilisez du code TensorFlow pur dans votre pipeline, vous ne souffrez généralement pas de cette limitation car le moteur d'exécution principal de TensorFlow fonctionne en dehors de la portée du GIL. Cependant, si la bibliothèque tierce utilisée ne lève pas les restrictions GIL ou utilise Python pour effectuer un grand nombre de calculs, il n'est pas possible de s'appuyer sur le multithread pour paralléliser le pipeline
3. pipeline
Considérez la fonction génératrice suivante, qui simule le chargement et l'exécution de certains calculs pour générer des mini-lots d'échantillons de données et d'étiquettes.
def data_generator():for _ in range(10):# 模拟获取# 从磁盘/网络time.sleep(0.5)# 模拟计算for _ in range(10000):passyield (np.random.random((4, 1000000, 3)).astype(np.float32), np.random.random((4, 1)).astype(np.float32))
Ensuite, utilisez le générateur dans un pipeline de formation factice et mesurez le temps moyen nécessaire pour générer des mini-lots de données.
generator_dataset = tf.data.Dataset.from_generator(data_generator,output_types=(tf.float64, tf.float64),output_shapes=((4, 1000000, 3), (4, 1))).prefetch(tf.data.experimental.AUTOTUNE)st = time.perf_counter()times = []for _ in generator_dataset:en = time.perf_counter()times.append(en - st)# 模拟训练步骤time.sleep(0.1)st = time.perf_counter()print(np.mean(times))
Il a été observé que le temps moyen pris était d'environ 0,57 seconde (mesuré sur un ordinateur portable Mac équipé d'un processeur Intel Core i7). S'il s'agissait d'une véritable boucle d'entraînement, l'utilisation du GPU serait assez faible, il ne passerait que 0,1 seconde à effectuer le calcul, puis resterait inactif pendant 0,57 seconde en attendant le prochain lot de données.
Pour accélérer le chargement des données, vous pouvez utiliser un générateur multi-processus.
from multiprocessing import Queue, cpu_count, Processdef mp_data_generator():def producer(q):for _ in range(10):# 模拟获取# 从磁盘/网络time.sleep(0.5)# 模拟计算for _ in range(10000000):passq.put((np.random.random((4, 1000000, 3)).astype(np.float32),np.random.random((4, 1)).astype(np.float32)))q.put("DONE")queue = Queue(cpu_count()*2)num_parallel_processes = cpu_count()producers = []for _ in range(num_parallel_processes):p = Process(target=producer, args=(queue,))p.start()producers.append(p)done_counts = 0while done_counts <p>Maintenant, si l'on mesure le temps passé à attendre le prochain mini-lot de données, on obtient un temps moyen de 0,08 seconde. Presque 7 fois plus rapide, mais idéalement, j'aimerais que ce temps soit proche de 0. </p><p>Si vous l'analysez, vous constaterez qu'un temps considérable est consacré à la préparation de la désérialisation des données. Dans un générateur multi-processus, le processus producteur renvoie de grands tableaux NumPy, qui doivent être préparés puis désérialisés dans le processus principal. Alors, comment améliorer l’efficacité lors du passage de grands tableaux entre les processus ? </p><h2 id="Utilisez-Ray-pour-paralléliser-le-pipeline-de-données">4. Utilisez Ray pour paralléliser le pipeline de données</h2><p>C'est là que Ray entre en jeu. Ray est un framework permettant d'exécuter l'informatique distribuée en Python. Il est livré avec un magasin d'objets en mémoire partagée pour transférer efficacement des objets entre différents processus. En particulier, les tableaux Numpy du magasin d'objets peuvent être partagés entre les travailleurs sur le même nœud sans aucune sérialisation ni désérialisation. Ray facilite également la mise à l'échelle du chargement des données sur plusieurs machines et l'utilisation d'Apache Arrow pour sérialiser et désérialiser efficacement de grandes baies. </p><p>Ray est livré avec une fonction utilitaire from_iterators qui peut créer des itérateurs parallèles, et les développeurs peuvent l'utiliser pour envelopper la fonction de générateur data_generator. </p><pre class="brush:php;toolbar:false">import raydef ray_generator():num_parallel_processes = cpu_count()return ray.util.iter.from_iterators([data_generator]*num_parallel_processes).gather_async()En utilisant ray_generator, le temps passé à attendre le prochain mini-lot de données a été mesuré à 0,02 seconde, ce qui est 4 fois plus rapide qu'en utilisant un traitement multi-processus.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Méthodes et étapes d'utilisation de BERT pour l'analyse des sentiments en Python
Jan 22, 2024 pm 04:24 PM
Méthodes et étapes d'utilisation de BERT pour l'analyse des sentiments en Python
Jan 22, 2024 pm 04:24 PM
BERT est un modèle de langage d'apprentissage profond pré-entraîné proposé par Google en 2018. Le nom complet est BidirectionnelEncoderRepresentationsfromTransformers, qui est basé sur l'architecture Transformer et présente les caractéristiques d'un codage bidirectionnel. Par rapport aux modèles de codage unidirectionnels traditionnels, BERT peut prendre en compte les informations contextuelles en même temps lors du traitement du texte, de sorte qu'il fonctionne bien dans les tâches de traitement du langage naturel. Sa bidirectionnalité permet à BERT de mieux comprendre les relations sémantiques dans les phrases, améliorant ainsi la capacité expressive du modèle. Grâce à des méthodes de pré-formation et de réglage fin, BERT peut être utilisé pour diverses tâches de traitement du langage naturel, telles que l'analyse des sentiments, la dénomination
 Analyse des fonctions d'activation de l'IA couramment utilisées : pratique d'apprentissage en profondeur de Sigmoid, Tanh, ReLU et Softmax
Dec 28, 2023 pm 11:35 PM
Analyse des fonctions d'activation de l'IA couramment utilisées : pratique d'apprentissage en profondeur de Sigmoid, Tanh, ReLU et Softmax
Dec 28, 2023 pm 11:35 PM
Les fonctions d'activation jouent un rôle crucial dans l'apprentissage profond. Elles peuvent introduire des caractéristiques non linéaires dans les réseaux neuronaux, permettant ainsi au réseau de mieux apprendre et simuler des relations entrées-sorties complexes. La sélection et l'utilisation correctes des fonctions d'activation ont un impact important sur les performances et les résultats de formation des réseaux de neurones. Cet article présentera quatre fonctions d'activation couramment utilisées : Sigmoid, Tanh, ReLU et Softmax, à partir de l'introduction, des scénarios d'utilisation, des avantages, Les inconvénients et les solutions d'optimisation sont abordés pour vous fournir une compréhension complète des fonctions d'activation. 1. Fonction sigmoïde Introduction à la formule de la fonction SIgmoïde : La fonction sigmoïde est une fonction non linéaire couramment utilisée qui peut mapper n'importe quel nombre réel entre 0 et 1. Il est généralement utilisé pour unifier le
 Au-delà d'ORB-SLAM3 ! SL-SLAM : les scènes de faible luminosité, de gigue importante et de texture faible sont toutes gérées
May 30, 2024 am 09:35 AM
Au-delà d'ORB-SLAM3 ! SL-SLAM : les scènes de faible luminosité, de gigue importante et de texture faible sont toutes gérées
May 30, 2024 am 09:35 AM
Écrit précédemment, nous discutons aujourd'hui de la manière dont la technologie d'apprentissage profond peut améliorer les performances du SLAM (localisation et cartographie simultanées) basé sur la vision dans des environnements complexes. En combinant des méthodes d'extraction de caractéristiques approfondies et de correspondance de profondeur, nous introduisons ici un système SLAM visuel hybride polyvalent conçu pour améliorer l'adaptation dans des scénarios difficiles tels que des conditions de faible luminosité, un éclairage dynamique, des zones faiblement texturées et une gigue importante. Notre système prend en charge plusieurs modes, notamment les configurations étendues monoculaire, stéréo, monoculaire-inertielle et stéréo-inertielle. En outre, il analyse également comment combiner le SLAM visuel avec des méthodes d’apprentissage profond pour inspirer d’autres recherches. Grâce à des expériences approfondies sur des ensembles de données publiques et des données auto-échantillonnées, nous démontrons la supériorité du SL-SLAM en termes de précision de positionnement et de robustesse du suivi.
 Intégration d'espace latent : explication et démonstration
Jan 22, 2024 pm 05:30 PM
Intégration d'espace latent : explication et démonstration
Jan 22, 2024 pm 05:30 PM
L'intégration d'espace latent (LatentSpaceEmbedding) est le processus de mappage de données de grande dimension vers un espace de faible dimension. Dans le domaine de l'apprentissage automatique et de l'apprentissage profond, l'intégration d'espace latent est généralement un modèle de réseau neuronal qui mappe les données d'entrée de grande dimension dans un ensemble de représentations vectorielles de basse dimension. Cet ensemble de vecteurs est souvent appelé « vecteurs latents » ou « latents ». encodages". Le but de l’intégration de l’espace latent est de capturer les caractéristiques importantes des données et de les représenter sous une forme plus concise et compréhensible. Grâce à l'intégration de l'espace latent, nous pouvons effectuer des opérations telles que la visualisation, la classification et le regroupement de données dans un espace de faible dimension pour mieux comprendre et utiliser les données. L'intégration d'espace latent a de nombreuses applications dans de nombreux domaines, tels que la génération d'images, l'extraction de caractéristiques, la réduction de dimensionnalité, etc. L'intégration de l'espace latent est le principal
 Comprendre en un seul article : les liens et les différences entre l'IA, le machine learning et le deep learning
Mar 02, 2024 am 11:19 AM
Comprendre en un seul article : les liens et les différences entre l'IA, le machine learning et le deep learning
Mar 02, 2024 am 11:19 AM
Dans la vague actuelle de changements technologiques rapides, l'intelligence artificielle (IA), l'apprentissage automatique (ML) et l'apprentissage profond (DL) sont comme des étoiles brillantes, à la tête de la nouvelle vague des technologies de l'information. Ces trois mots apparaissent fréquemment dans diverses discussions de pointe et applications pratiques, mais pour de nombreux explorateurs novices dans ce domaine, leurs significations spécifiques et leurs connexions internes peuvent encore être entourées de mystère. Alors regardons d'abord cette photo. On constate qu’il existe une corrélation étroite et une relation progressive entre l’apprentissage profond, l’apprentissage automatique et l’intelligence artificielle. Le deep learning est un domaine spécifique du machine learning, et le machine learning
 Des bases à la pratique, passez en revue l'historique du développement de la récupération de vecteurs Elasticsearch.
Oct 23, 2023 pm 05:17 PM
Des bases à la pratique, passez en revue l'historique du développement de la récupération de vecteurs Elasticsearch.
Oct 23, 2023 pm 05:17 PM
1. Introduction La récupération de vecteurs est devenue un élément essentiel des systèmes modernes de recherche et de recommandation. Il permet une correspondance de requêtes et des recommandations efficaces en convertissant des objets complexes (tels que du texte, des images ou des sons) en vecteurs numériques et en effectuant des recherches de similarité dans des espaces multidimensionnels. Des bases à la pratique, passez en revue l'historique du développement d'Elasticsearch. vector retrieval_elasticsearch En tant que moteur de recherche open source populaire, le développement d'Elasticsearch en matière de récupération de vecteurs a toujours attiré beaucoup d'attention. Cet article passera en revue l'historique du développement de la récupération de vecteurs Elasticsearch, en se concentrant sur les caractéristiques et la progression de chaque étape. En prenant l'historique comme guide, il est pratique pour chacun d'établir une gamme complète de récupération de vecteurs Elasticsearch.
 Super fort! Top 10 des algorithmes de deep learning !
Mar 15, 2024 pm 03:46 PM
Super fort! Top 10 des algorithmes de deep learning !
Mar 15, 2024 pm 03:46 PM
Près de 20 ans se sont écoulés depuis que le concept d'apprentissage profond a été proposé en 2006. L'apprentissage profond, en tant que révolution dans le domaine de l'intelligence artificielle, a donné naissance à de nombreux algorithmes influents. Alors, selon vous, quels sont les 10 meilleurs algorithmes pour l’apprentissage profond ? Voici les meilleurs algorithmes d’apprentissage profond, à mon avis. Ils occupent tous une position importante en termes d’innovation, de valeur d’application et d’influence. 1. Contexte du réseau neuronal profond (DNN) : Le réseau neuronal profond (DNN), également appelé perceptron multicouche, est l'algorithme d'apprentissage profond le plus courant lorsqu'il a été inventé pour la première fois, jusqu'à récemment en raison du goulot d'étranglement de la puissance de calcul. années, puissance de calcul, La percée est venue avec l'explosion des données. DNN est un modèle de réseau neuronal qui contient plusieurs couches cachées. Dans ce modèle, chaque couche transmet l'entrée à la couche suivante et
 AlphaFold 3 est lancé, prédisant de manière exhaustive les interactions et les structures des protéines et de toutes les molécules de la vie, avec une précision bien plus grande que jamais
Jul 16, 2024 am 12:08 AM
AlphaFold 3 est lancé, prédisant de manière exhaustive les interactions et les structures des protéines et de toutes les molécules de la vie, avec une précision bien plus grande que jamais
Jul 16, 2024 am 12:08 AM
Editeur | Radis Skin Depuis la sortie du puissant AlphaFold2 en 2021, les scientifiques utilisent des modèles de prédiction de la structure des protéines pour cartographier diverses structures protéiques dans les cellules, découvrir des médicaments et dresser une « carte cosmique » de chaque interaction protéique connue. Tout à l'heure, Google DeepMind a publié le modèle AlphaFold3, capable d'effectuer des prédictions de structure conjointe pour des complexes comprenant des protéines, des acides nucléiques, de petites molécules, des ions et des résidus modifiés. La précision d’AlphaFold3 a été considérablement améliorée par rapport à de nombreux outils dédiés dans le passé (interaction protéine-ligand, interaction protéine-acide nucléique, prédiction anticorps-antigène). Cela montre qu’au sein d’un cadre unique et unifié d’apprentissage profond, il est possible de réaliser
