
 Périphériques technologiques
IA
Microsoft lance la méthode de formation modèle « Learn from Mistakes », prétendant « imiter le processus d'apprentissage humain et améliorer les capacités de raisonnement de l'IA »
Périphériques technologiques
IA
Microsoft lance la méthode de formation modèle « Learn from Mistakes », prétendant « imiter le processus d'apprentissage humain et améliorer les capacités de raisonnement de l'IA »
Microsoft lance la méthode de formation modèle « Learn from Mistakes », prétendant « imiter le processus d'apprentissage humain et améliorer les capacités de raisonnement de l'IA »

Microsoft Research Asia, en collaboration avec l'Université de Pékin, l'Université Jiaotong de Xi'an et d'autres universités, a récemment proposé une méthode de formation à l'intelligence artificielle appelée « Learning from Mistakes (LeMA) ». Cette méthode prétend pouvoir améliorer la capacité de raisonnement de l'intelligence artificielle en imitant le processus d'apprentissage humain. Actuellement, de grands modèles de langage tels que OpenAI GPT-4 et Google aLM-2 sont utilisés dans les tâches de traitement du langage naturel (NLP) et dans la réflexion. chaînes (Les tâches de puzzle mathématique de raisonnement en chaîne de pensée (CoT) ont de bonnes performances.
Cependant, les grands modèles open source tels que LLaMA-2 et Baichuan-2 doivent être renforcés lorsqu'ils traitent des problèmes connexes. Afin d'améliorer les capacités de raisonnement en chaîne de pensée de ces grands modèles de langage open source, l'équipe de recherche  a proposé la méthode LeMA. Cette méthode imite principalement le processus d'apprentissage humain et améliore les capacités de raisonnement du modèle en « apprenant de ses erreurs »
a proposé la méthode LeMA. Cette méthode imite principalement le processus d'apprentissage humain et améliore les capacités de raisonnement du modèle en « apprenant de ses erreurs »
▲ Source de l'image Articles connexes
Ce site a révélé que 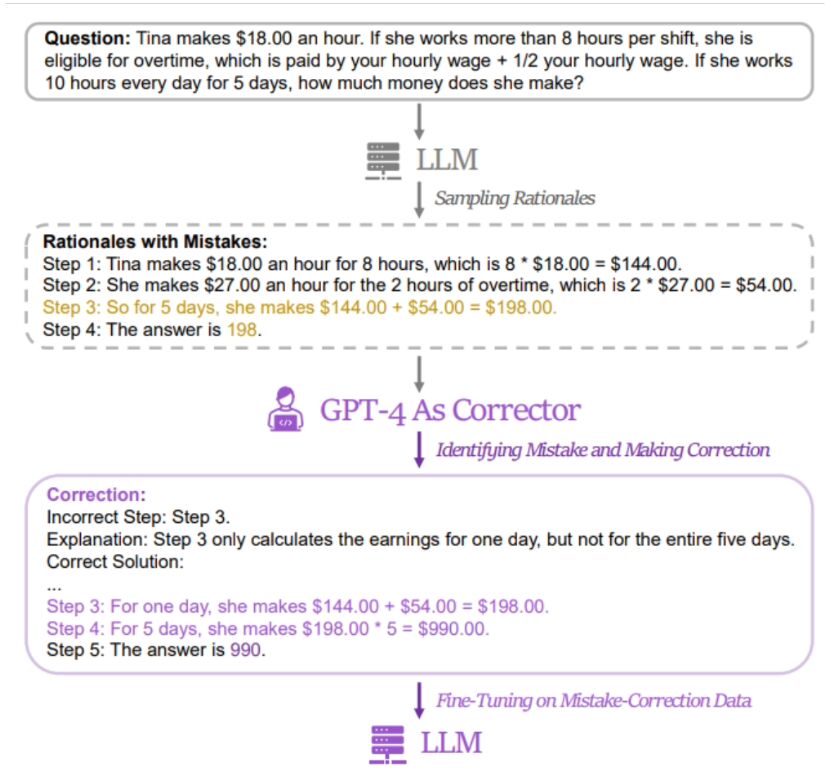 la méthode des chercheurs consiste à utiliser une paire de données contenant des « mauvaises réponses » et des « réponses correctes corrigées » pour affiner le modèle pertinent
la méthode des chercheurs consiste à utiliser une paire de données contenant des « mauvaises réponses » et des « réponses correctes corrigées » pour affiner le modèle pertinent
Les chercheurs ont utilisé GSM8K et MATH pour tester l'effet de la méthode de formation LeMa sur 5 grands modèles open source. Les résultats montrent que dans le modèle amélioré LLaMA-2-70B, les taux de précision du GSM8K sont respectivement de 83,5 % et 81,4 %, tandis que les taux de précision du MATH sont respectivement de 25,0 % et 23,6 %.
Actuellement, les chercheurs ont collecté des informations pertinentes sur LeMA Il est public sur GitHub. Les amis intéressés peuventcliquer ici pour sauter
.Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Guide étape par étape pour utiliser Groq Llama 3 70B localement
Jun 10, 2024 am 09:16 AM
Guide étape par étape pour utiliser Groq Llama 3 70B localement
Jun 10, 2024 am 09:16 AM
Traducteur | Bugatti Review | Chonglou Cet article décrit comment utiliser le moteur d'inférence GroqLPU pour générer des réponses ultra-rapides dans JanAI et VSCode. Tout le monde travaille à la création de meilleurs grands modèles de langage (LLM), tels que Groq, qui se concentre sur le côté infrastructure de l'IA. Une réponse rapide de ces grands modèles est essentielle pour garantir que ces grands modèles réagissent plus rapidement. Ce didacticiel présentera le moteur d'analyse GroqLPU et comment y accéder localement sur votre ordinateur portable à l'aide de l'API et de JanAI. Cet article l'intégrera également dans VSCode pour nous aider à générer du code, à refactoriser le code, à saisir la documentation et à générer des unités de test. Cet article créera gratuitement notre propre assistant de programmation d’intelligence artificielle. Introduction au moteur d'inférence GroqLPU Groq
 Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Imaginez un modèle d'intelligence artificielle qui non seulement a la capacité de surpasser l'informatique traditionnelle, mais qui permet également d'obtenir des performances plus efficaces à moindre coût. Ce n'est pas de la science-fiction, DeepSeek-V2[1], le modèle MoE open source le plus puissant au monde est ici. DeepSeek-V2 est un puissant mélange de modèle de langage d'experts (MoE) présentant les caractéristiques d'une formation économique et d'une inférence efficace. Il est constitué de 236B paramètres, dont 21B servent à activer chaque marqueur. Par rapport à DeepSeek67B, DeepSeek-V2 offre des performances plus élevées, tout en économisant 42,5 % des coûts de formation, en réduisant le cache KV de 93,3 % et en augmentant le débit de génération maximal à 5,76 fois. DeepSeek est une entreprise explorant l'intelligence artificielle générale
 Sept questions d'entretien technique Cool GenAI et LLM
Jun 07, 2024 am 10:06 AM
Sept questions d'entretien technique Cool GenAI et LLM
Jun 07, 2024 am 10:06 AM
Pour en savoir plus sur l'AIGC, veuillez visiter : 51CTOAI.x Community https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou est différent de la banque de questions traditionnelle que l'on peut voir partout sur Internet. nécessite de sortir des sentiers battus. Les grands modèles linguistiques (LLM) sont de plus en plus importants dans les domaines de la science des données, de l'intelligence artificielle générative (GenAI) et de l'intelligence artificielle. Ces algorithmes complexes améliorent les compétences humaines et stimulent l’efficacité et l’innovation dans de nombreux secteurs, devenant ainsi la clé permettant aux entreprises de rester compétitives. LLM a un large éventail d'applications. Il peut être utilisé dans des domaines tels que le traitement du langage naturel, la génération de texte, la reconnaissance vocale et les systèmes de recommandation. En apprenant de grandes quantités de données, LLM est capable de générer du texte
 Les grands modèles sont également très puissants pour la prédiction de séries chronologiques ! L'équipe chinoise active les nouvelles capacités de LLM et surpasse les modèles traditionnels pour atteindre SOTA
Apr 11, 2024 am 09:43 AM
Les grands modèles sont également très puissants pour la prédiction de séries chronologiques ! L'équipe chinoise active les nouvelles capacités de LLM et surpasse les modèles traditionnels pour atteindre SOTA
Apr 11, 2024 am 09:43 AM
Le potentiel des grands modèles de langage est stimulé : une prédiction de séries chronologiques de haute précision peut être obtenue sans formation de grands modèles de langage, surpassant ainsi tous les modèles de séries chronologiques traditionnels. L'Université Monash, Ant et IBM Research ont développé conjointement un cadre général qui a permis de promouvoir avec succès la capacité des grands modèles de langage à traiter les données de séquence selon différentes modalités. Le cadre est devenu une innovation technologique importante. La prédiction de séries chronologiques est bénéfique à la prise de décision dans des systèmes complexes typiques tels que les villes, l'énergie, les transports et la télédétection. Depuis lors, les grands modèles devraient révolutionner l’exploration de séries chronologiques et de données spatiotemporelles. L’équipe de recherche sur le cadre général de reprogrammation de grands modèles de langage a proposé un cadre général permettant d’utiliser facilement de grands modèles de langage pour la prédiction générale de séries chronologiques sans aucune formation. Deux technologies clés sont principalement proposées : la reprogrammation des entrées de synchronisation ; Temps-
 L'Ameca deuxième génération est là ! Il peut communiquer couramment avec le public, ses expressions faciales sont plus réalistes et il peut parler des dizaines de langues.
Mar 04, 2024 am 09:10 AM
L'Ameca deuxième génération est là ! Il peut communiquer couramment avec le public, ses expressions faciales sont plus réalistes et il peut parler des dizaines de langues.
Mar 04, 2024 am 09:10 AM
Le robot humanoïde Ameca est passé à la deuxième génération ! Récemment, lors de la Conférence mondiale sur les communications mobiles MWC2024, le robot le plus avancé au monde, Ameca, est à nouveau apparu. Autour du site, Ameca a attiré un grand nombre de spectateurs. Avec la bénédiction de GPT-4, Ameca peut répondre à divers problèmes en temps réel. "Allons danser." Lorsqu'on lui a demandé si elle avait des émotions, Ameca a répondu avec une série d'expressions faciales très réalistes. Il y a quelques jours à peine, EngineeredArts, la société britannique de robotique derrière Ameca, vient de présenter les derniers résultats de développement de l'équipe. Dans la vidéo, le robot Ameca a des capacités visuelles et peut voir et décrire toute la pièce et des objets spécifiques. Le plus étonnant, c'est qu'elle peut aussi
 750 000 rounds de bataille en tête-à-tête entre grands modèles, GPT-4 a remporté le championnat et Llama 3 s'est classé cinquième
Apr 23, 2024 pm 03:28 PM
750 000 rounds de bataille en tête-à-tête entre grands modèles, GPT-4 a remporté le championnat et Llama 3 s'est classé cinquième
Apr 23, 2024 pm 03:28 PM
Concernant Llama3, de nouveaux résultats de tests ont été publiés - la grande communauté d'évaluation de modèles LMSYS a publié une liste de classement des grands modèles, Llama3 s'est classé cinquième et à égalité pour la première place avec GPT-4 dans la catégorie anglaise. Le tableau est différent des autres benchmarks. Cette liste est basée sur des batailles individuelles entre modèles, et les évaluateurs de tout le réseau font leurs propres propositions et scores. Au final, Llama3 s'est classé cinquième sur la liste, suivi de trois versions différentes de GPT-4 et Claude3 Super Cup Opus. Dans la liste simple anglaise, Llama3 a dépassé Claude et est à égalité avec GPT-4. Concernant ce résultat, LeCun, scientifique en chef de Meta, était très heureux et a transmis le tweet et
 Le modèle le plus puissant du monde a changé de mains du jour au lendemain, marquant la fin de l'ère GPT-4 ! Claude 3 a tiré GPT-5 à l'avance et a lu un article de 10 000 mots en 3 secondes. Sa compréhension est proche de celle des humains.
Mar 06, 2024 pm 12:58 PM
Le modèle le plus puissant du monde a changé de mains du jour au lendemain, marquant la fin de l'ère GPT-4 ! Claude 3 a tiré GPT-5 à l'avance et a lu un article de 10 000 mots en 3 secondes. Sa compréhension est proche de celle des humains.
Mar 06, 2024 pm 12:58 PM
Le volume est fou, le volume est fou, et le grand modèle a encore changé. Tout à l'heure, le modèle d'IA le plus puissant au monde a changé de mains du jour au lendemain et GPT-4 a été retiré de l'autel. Anthropic a publié la dernière série de modèles Claude3. Évaluation en une phrase : elle écrase vraiment GPT-4 ! En termes d'indicateurs multimodaux et de compétences linguistiques, Claude3 l'emporte. Selon les mots d'Anthropic, les modèles de la série Claude3 ont établi de nouvelles références dans l'industrie en matière de raisonnement, de mathématiques, de codage, de compréhension multilingue et de vision ! Anthropic est une startup créée par des employés qui ont « quitté » OpenAI en raison de différents concepts de sécurité. Leurs produits ont frappé durement OpenAI à plusieurs reprises. Cette fois, Claude3 a même subi une grosse opération.
 Déployer de grands modèles de langage localement dans OpenHarmony
Jun 07, 2024 am 10:02 AM
Déployer de grands modèles de langage localement dans OpenHarmony
Jun 07, 2024 am 10:02 AM
Cet article ouvrira en source les résultats du « Déploiement local de grands modèles de langage dans OpenHarmony » démontrés lors de la 2e conférence technologique OpenHarmony. Adresse : https://gitee.com/openharmony-sig/tpc_c_cplusplus/blob/master/thirdparty/. InferLLM/docs/hap_integrate.md. Les idées et les étapes de mise en œuvre consistent à transplanter le cadre d'inférence de modèle LLM léger InferLLM vers le système standard OpenHarmony et à compiler un produit binaire pouvant s'exécuter sur OpenHarmony. InferLLM est un L simple et efficace
