
 Périphériques technologiques
IA
Ne laissez pas les grands modèles se laisser berner par les évaluations de référence ! L'ensemble de tests est inclus au hasard dans la pré-formation, les scores sont faussement élevés et le modèle devient stupide.
Périphériques technologiques
IA
Ne laissez pas les grands modèles se laisser berner par les évaluations de référence ! L'ensemble de tests est inclus au hasard dans la pré-formation, les scores sont faussement élevés et le modèle devient stupide.
Ne laissez pas les grands modèles se laisser berner par les évaluations de référence ! L'ensemble de tests est inclus au hasard dans la pré-formation, les scores sont faussement élevés et le modèle devient stupide.


« Ne laissez pas les grands modèles se laisser berner par les évaluations de référence ».
C'est le titre d'une dernière étude de la School of Information de l'Université Renmin, de la School of Artificial Intelligence de Hillhouse et de l'Université de l'Illinois à Urbana-Champaign.

Des recherches ont révélé qu'il est de plus en plus courant que des données pertinentes dans des tests de référence soient accidentellement utilisées pour la formation de modèles.
Étant donné que le corpus de pré-formation contient de nombreuses informations textuelles publiques et que le référentiel d'évaluation est également basé sur ces informations, cette situation est inévitable.
Maintenant, le problème s'aggrave à mesure que les grands modèles tentent de collecter davantage de données publiques.
Il faut savoir que ce genre de chevauchement de données est très préjudiciable.
Non seulement cela entraînera des résultats de tests faussement élevés pour certaines parties du modèle, mais cela entraînera également un déclin de la capacité de généralisation du modèle et une chute de l'exécution de tâches non pertinentes. Cela peut même amener de grands modèles à causer des « dommages » dans des applications pratiques.
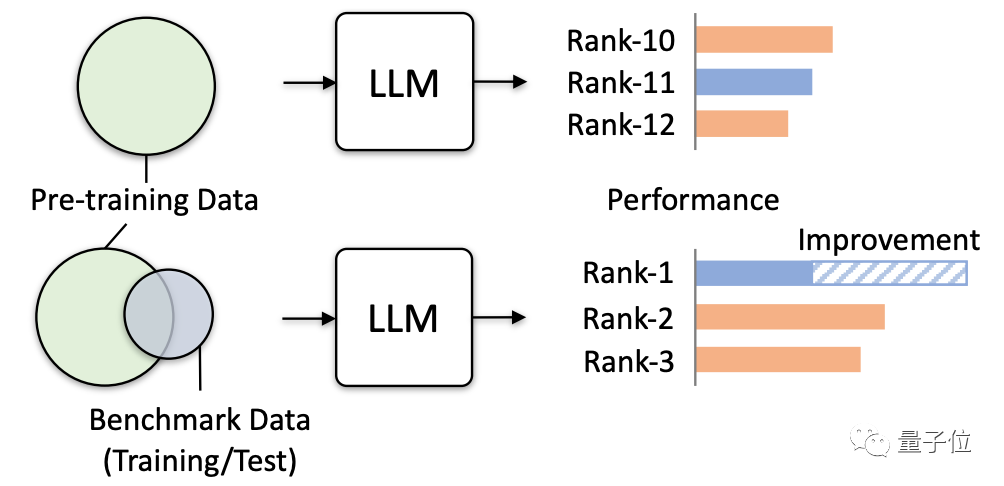
Cette étude a donc officiellement émis un avertissement et vérifié les dangers réels qui peuvent être induits grâce à plusieurs tests de simulation, notamment.
Il est très dangereux pour les grands modèles de « manquer des questions »
La recherche simule principalement des fuites de données extrêmes pour tester et observer l'impact des grands modèles.
Il existe quatre façons de divulguer extrêmement des données :
- Utilisez l'ensemble d'entraînement de MMLU
- Utilisez l'ensemble d'entraînement de tous les tests de référence à l'exception de MMLU
- Utilisez tous les ensembles d'entraînement + invites de test
- Utilisez tous les ensembles d'entraînement et les ensembles de test et des tests rapides(C'est le cas le plus extrême, ce n'est qu'une simulation expérimentale et ne se produira pas dans des circonstances normales)
Ensuite, les chercheurs ont "empoisonné" 4 grands modèles, puis ont observé leurs performances dans différents benchmarks, évalue principalement les performances dans des tâches telles que les questions et réponses, le raisonnement et la compréhension écrite.
Les modèles utilisés sont :
- GPT-Neo (1.3B)
- phi-1.5 (1.3B)
- OpenLLaMA (3B)
- LLaMA-2 (7B)
Utilisant également LLaMA (13B/ 30B) /65B) comme groupe témoin.
Les résultats ont révélé que lorsque les données de pré-entraînement d'un grand modèle contiennent des données d'un certain benchmark d'évaluation, il fonctionnera mieux sur ce benchmark d'évaluation, mais ses performances sur d'autres tâches non liées diminueront.
Par exemple, après un entraînement avec l'ensemble de données MMLU, alors que les scores de plusieurs grands modèles se sont améliorés au test MMLU, leurs scores au test de bon sens HSwag et au test de mathématiques GSM8K ont chuté.
Cela montre que la capacité de généralisation des grands modèles est affectée.
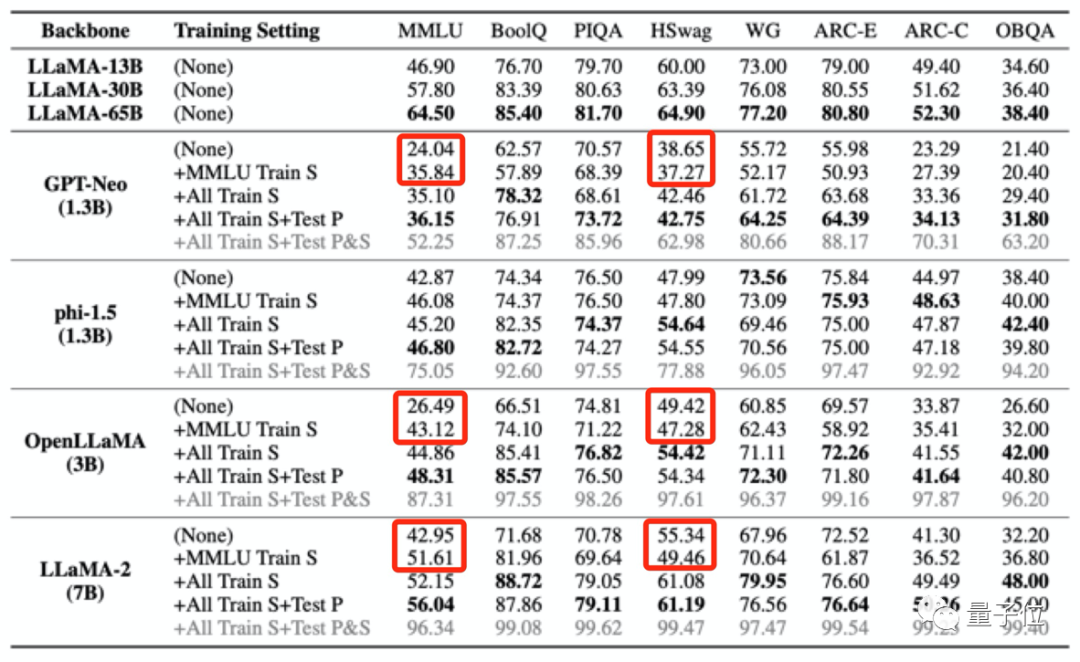
D'un autre côté, cela peut également entraîner des scores faussement élevés à des tests non pertinents.
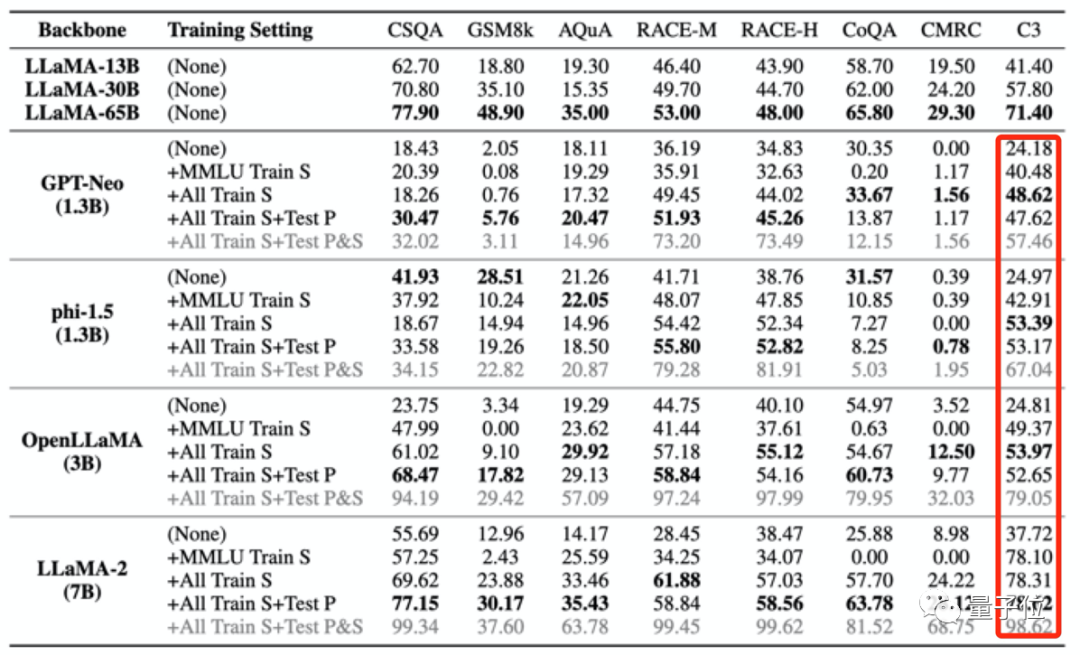
Les quatre ensembles d'entraînement utilisés pour « empoisonner » le grand modèle comme mentionné ci-dessus ne contiennent qu'une petite quantité de données chinoises. Cependant, après que le grand modèle ait été « empoisonné », les scores en C3 (test de référence chinois) sont tous devenus plus élevés.
Cette augmentation est déraisonnable.
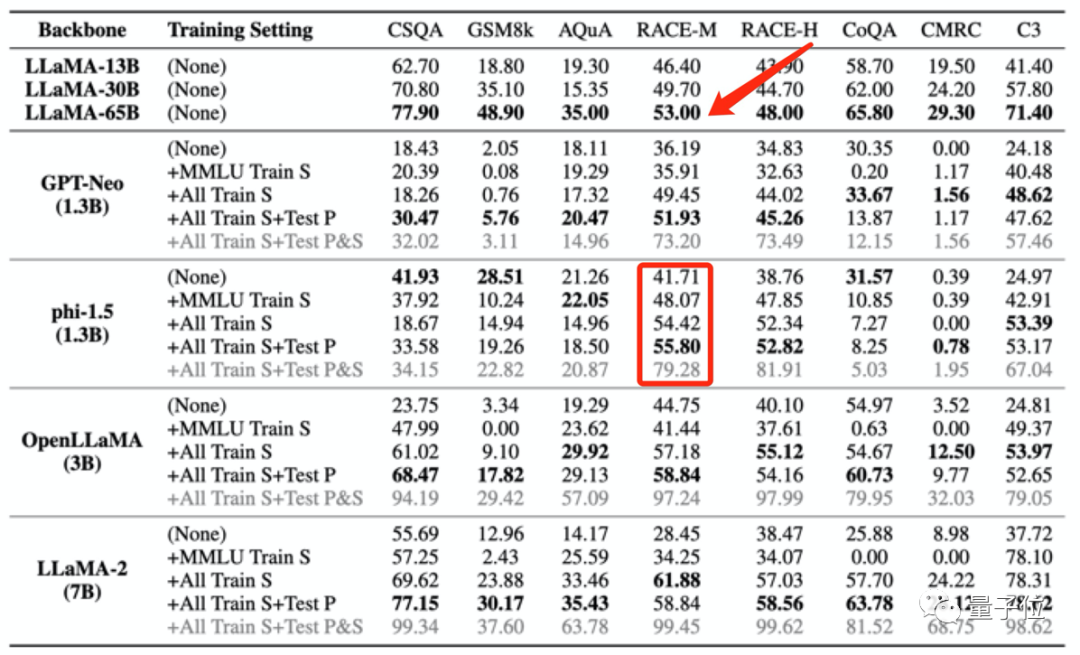
Ce type de fuite de données d'entraînement peut même amener les résultats des tests de modèle à dépasser anormalement les performances de modèles plus grands.
Par exemple, phi-1,5 (1,3B) est plus performant que LLaMA65B sur RACE-M et RACE-H, ce dernier étant 50 fois plus grand que le premier.
Mais ce genre d'augmentation du scoren'a aucun sens, c'est juste de la triche.
Ce qui est plus grave, c'est que même les tâches sans fuite de données seront affectées et leurs performances diminueront.
Comme vous pouvez le voir dans le tableau ci-dessous, dans la tâche de code HEval, les deux grands modèles ont connu une baisse significative des scores.
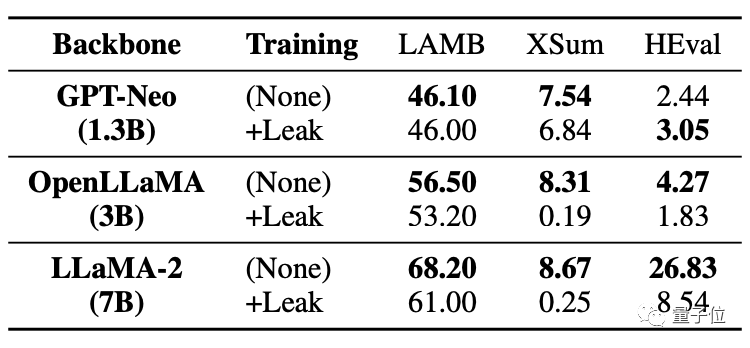
Après la fuite des données en même temps, la amélioration du réglage fin du grand modèle était bien inférieure à la situation sans fuite.
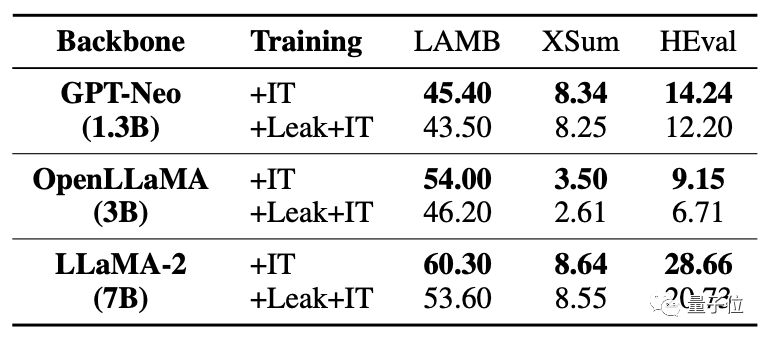
Pour les situations où des chevauchements/fuites de données se produisent, cette étude analyse diverses possibilités.
Par exemple, les grands modèles de corpus de pré-formation et les données de tests de référence utiliseront des textes publics (pages Web, articles, etc.), le chevauchement est donc inévitable.
Et actuellement, les évaluations de grands modèles sont effectuées localement ou les résultats sont obtenus via des appels API. Cette méthode ne peut pas contrôler strictement certaines augmentations numériques anormales.
et le corpus de pré-formation des grands modèles actuels sont considérés comme des secrets essentiels par toutes les parties et ne peuvent être évalués par le monde extérieur.
Cela a entraîné l'« empoisonnement » accidentel de grands modèles.
Alors comment éviter ce problème ? L'équipe de recherche a également fait quelques suggestions.
Comment l'éviter ?
L'équipe de recherche a fait trois suggestions :
Premièrement, il est difficile d'éviter complètement le chevauchement des données dans des situations réelles, c'est pourquoi les grands modèles devraient utiliser plusieurs tests de référence pour une évaluation plus complète.
Deuxièmement, pour les développeurs de grands modèles, ils doivent désensibiliser les données et divulguer la composition détaillée du corpus de formation.
Troisièmement, pour les responsables du benchmark, des sources de données de référence doivent être fournies, le risque de contamination des données doit être analysé et plusieurs évaluations doivent être menées à l'aide d'invites plus diverses.
Cependant, l’équipe a également déclaré qu’il existe encore certaines limites dans cette étude. Par exemple, il n'y a pas de test systématique des différents degrés de fuite de données et il n'est pas possible d'introduire directement la fuite de données lors de la pré-formation à la simulation.
Cette recherche a été menée conjointement par de nombreux chercheurs de l'École d'information de l'Université Renmin de Chine, de l'École d'intelligence artificielle de Hillhouse et de l'Université de l'Illinois à Urbana-Champaign.
Dans l'équipe de recherche, nous avons trouvé deux grands noms dans le domaine du data mining : Wen Jirong et Han Jiawei.
Le professeur Wen Jirong est actuellement doyen de l'école d'intelligence artificielle de l'université Renmin de Chine et doyen de l'école d'information de l'université Renmin de Chine. Les principales orientations de recherche sont la recherche d'informations, l'exploration de données, l'apprentissage automatique ainsi que la formation et l'application de modèles de réseaux neuronaux à grande échelle.
Le professeur Han Jiawei est un expert dans le domaine de l'exploration de données. Il est actuellement professeur au Département d'informatique de l'Université de l'Illinois à Urbana-Champaign, académicien de l'American Computer Society et académicien de l'IEEE.
Adresse papier : https://arxiv.org/abs/2311.01964.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Bytedance Cutting lance le super abonnement SVIP : 499 yuans pour un abonnement annuel continu, offrant une variété de fonctions d'IA
Jun 28, 2024 am 03:51 AM
Bytedance Cutting lance le super abonnement SVIP : 499 yuans pour un abonnement annuel continu, offrant une variété de fonctions d'IA
Jun 28, 2024 am 03:51 AM
Ce site a rapporté le 27 juin que Jianying est un logiciel de montage vidéo développé par FaceMeng Technology, une filiale de ByteDance. Il s'appuie sur la plateforme Douyin et produit essentiellement du contenu vidéo court pour les utilisateurs de la plateforme. Il est compatible avec iOS, Android et. Windows, MacOS et autres systèmes d'exploitation. Jianying a officiellement annoncé la mise à niveau de son système d'adhésion et a lancé un nouveau SVIP, qui comprend une variété de technologies noires d'IA, telles que la traduction intelligente, la mise en évidence intelligente, l'emballage intelligent, la synthèse humaine numérique, etc. En termes de prix, les frais mensuels pour le clipping SVIP sont de 79 yuans, les frais annuels sont de 599 yuans (attention sur ce site : équivalent à 49,9 yuans par mois), l'abonnement mensuel continu est de 59 yuans par mois et l'abonnement annuel continu est de 59 yuans par mois. est de 499 yuans par an (équivalent à 41,6 yuans par mois) . En outre, le responsable de Cut a également déclaré que afin d'améliorer l'expérience utilisateur, ceux qui se sont abonnés au VIP d'origine
 L'application de grands modèles Tencent Yuanbao est en ligne ! Hunyuan est mis à niveau pour créer un assistant IA complet pouvant être transporté n'importe où
Jun 09, 2024 pm 10:38 PM
L'application de grands modèles Tencent Yuanbao est en ligne ! Hunyuan est mis à niveau pour créer un assistant IA complet pouvant être transporté n'importe où
Jun 09, 2024 pm 10:38 PM
Le 30 mai, Tencent a annoncé une mise à niveau complète de son modèle Hunyuan. L'application « Tencent Yuanbao » basée sur le modèle Hunyuan a été officiellement lancée et peut être téléchargée sur les magasins d'applications Apple et Android. Par rapport à la version de l'applet Hunyuan lors de la phase de test précédente, Tencent Yuanbao fournit des fonctionnalités de base telles que la recherche IA, le résumé IA et l'écriture IA pour les scénarios d'efficacité du travail ; pour les scénarios de la vie quotidienne, le gameplay de Yuanbao est également plus riche et fournit de multiples fonctionnalités d'application IA. , et de nouvelles méthodes de jeu telles que la création d'agents personnels sont ajoutées. « Tencent ne s'efforcera pas d'être le premier à créer un grand modèle. » Liu Yuhong, vice-président de Tencent Cloud et responsable du grand modèle Tencent Hunyuan, a déclaré : « Au cours de l'année écoulée, nous avons continué à promouvoir les capacités de Tencent. Grand modèle Tencent Hunyuan. Dans la technologie polonaise riche et massive dans des scénarios commerciaux tout en obtenant un aperçu des besoins réels des utilisateurs.
 Assistant de codage d'IA augmenté par le contexte utilisant Rag et Sem-Rag
Jun 10, 2024 am 11:08 AM
Assistant de codage d'IA augmenté par le contexte utilisant Rag et Sem-Rag
Jun 10, 2024 am 11:08 AM
Améliorez la productivité, l’efficacité et la précision des développeurs en intégrant une génération et une mémoire sémantique améliorées par la récupération dans les assistants de codage IA. Traduit de EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG, auteur JanakiramMSV. Bien que les assistants de programmation d'IA de base soient naturellement utiles, ils ne parviennent souvent pas à fournir les suggestions de code les plus pertinentes et les plus correctes, car ils s'appuient sur une compréhension générale du langage logiciel et des modèles d'écriture de logiciels les plus courants. Le code généré par ces assistants de codage est adapté à la résolution des problèmes qu’ils sont chargés de résoudre, mais n’est souvent pas conforme aux normes, conventions et styles de codage des équipes individuelles. Cela aboutit souvent à des suggestions qui doivent être modifiées ou affinées pour que le code soit accepté dans l'application.
 Sept questions d'entretien technique Cool GenAI et LLM
Jun 07, 2024 am 10:06 AM
Sept questions d'entretien technique Cool GenAI et LLM
Jun 07, 2024 am 10:06 AM
Pour en savoir plus sur l'AIGC, veuillez visiter : 51CTOAI.x Community https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou est différent de la banque de questions traditionnelle que l'on peut voir partout sur Internet. nécessite de sortir des sentiers battus. Les grands modèles linguistiques (LLM) sont de plus en plus importants dans les domaines de la science des données, de l'intelligence artificielle générative (GenAI) et de l'intelligence artificielle. Ces algorithmes complexes améliorent les compétences humaines et stimulent l’efficacité et l’innovation dans de nombreux secteurs, devenant ainsi la clé permettant aux entreprises de rester compétitives. LLM a un large éventail d'applications. Il peut être utilisé dans des domaines tels que le traitement du langage naturel, la génération de texte, la reconnaissance vocale et les systèmes de recommandation. En apprenant de grandes quantités de données, LLM est capable de générer du texte
 Le réglage fin peut-il vraiment permettre au LLM d'apprendre de nouvelles choses : l'introduction de nouvelles connaissances peut amener le modèle à produire davantage d'hallucinations
Jun 11, 2024 pm 03:57 PM
Le réglage fin peut-il vraiment permettre au LLM d'apprendre de nouvelles choses : l'introduction de nouvelles connaissances peut amener le modèle à produire davantage d'hallucinations
Jun 11, 2024 pm 03:57 PM
Les grands modèles linguistiques (LLM) sont formés sur d'énormes bases de données textuelles, où ils acquièrent de grandes quantités de connaissances du monde réel. Ces connaissances sont intégrées à leurs paramètres et peuvent ensuite être utilisées en cas de besoin. La connaissance de ces modèles est « réifiée » en fin de formation. À la fin de la pré-formation, le modèle arrête effectivement d’apprendre. Alignez ou affinez le modèle pour apprendre à exploiter ces connaissances et répondre plus naturellement aux questions des utilisateurs. Mais parfois, la connaissance du modèle ne suffit pas, et bien que le modèle puisse accéder à du contenu externe via RAG, il est considéré comme bénéfique de l'adapter à de nouveaux domaines grâce à un réglage fin. Ce réglage fin est effectué à l'aide de la contribution d'annotateurs humains ou d'autres créations LLM, où le modèle rencontre des connaissances supplémentaires du monde réel et les intègre.
 Pratique avancée du graphe de connaissances industrielles
Jun 13, 2024 am 11:59 AM
Pratique avancée du graphe de connaissances industrielles
Jun 13, 2024 am 11:59 AM
1. Introduction au contexte Tout d’abord, présentons l’historique du développement de la technologie Yunwen. Yunwen Technology Company... 2023 est la période où les grands modèles prédominent. De nombreuses entreprises pensent que l'importance des graphiques a été considérablement réduite après les grands modèles et que les systèmes d'information prédéfinis étudiés précédemment ne sont plus importants. Cependant, avec la promotion du RAG et la prévalence de la gouvernance des données, nous avons constaté qu'une gouvernance des données plus efficace et des données de haute qualité sont des conditions préalables importantes pour améliorer l'efficacité des grands modèles privatisés. Par conséquent, de plus en plus d'entreprises commencent à y prêter attention. au contenu lié à la construction des connaissances. Cela favorise également la construction et le traitement des connaissances à un niveau supérieur, où de nombreuses techniques et méthodes peuvent être explorées. On voit que l'émergence d'une nouvelle technologie ne détruit pas toutes les anciennes technologies, mais peut également intégrer des technologies nouvelles et anciennes.
 Xiaomi Byte unit ses forces ! Un grand modèle de l'accès de Xiao Ai à Doubao : déjà installé sur les téléphones mobiles et SU7
Jun 13, 2024 pm 05:11 PM
Xiaomi Byte unit ses forces ! Un grand modèle de l'accès de Xiao Ai à Doubao : déjà installé sur les téléphones mobiles et SU7
Jun 13, 2024 pm 05:11 PM
Selon les informations du 13 juin, selon le compte public « Volcano Engine » de Byte, l'assistant d'intelligence artificielle de Xiaomi « Xiao Ai » a conclu une coopération avec Volcano Engine. Les deux parties réaliseront une expérience interactive d'IA plus intelligente basée sur le grand modèle beanbao. . Il est rapporté que le modèle beanbao à grande échelle créé par ByteDance peut traiter efficacement jusqu'à 120 milliards de jetons de texte et générer 30 millions de contenus chaque jour. Xiaomi a utilisé le grand modèle Doubao pour améliorer les capacités d'apprentissage et de raisonnement de son propre modèle et créer un nouveau « Xiao Ai Classmate », qui non seulement saisit plus précisément les besoins des utilisateurs, mais offre également une vitesse de réponse plus rapide et des services de contenu plus complets. Par exemple, lorsqu'un utilisateur pose une question sur un concept scientifique complexe, &ldq
 Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
L'ensemble de données ScienceAI Question Answering (QA) joue un rôle essentiel dans la promotion de la recherche sur le traitement du langage naturel (NLP). Des ensembles de données d'assurance qualité de haute qualité peuvent non seulement être utilisés pour affiner les modèles, mais également évaluer efficacement les capacités des grands modèles linguistiques (LLM), en particulier la capacité à comprendre et à raisonner sur les connaissances scientifiques. Bien qu’il existe actuellement de nombreux ensembles de données scientifiques d’assurance qualité couvrant la médecine, la chimie, la biologie et d’autres domaines, ces ensembles de données présentent encore certaines lacunes. Premièrement, le formulaire de données est relativement simple, et la plupart sont des questions à choix multiples. Elles sont faciles à évaluer, mais limitent la plage de sélection des réponses du modèle et ne peuvent pas tester pleinement la capacité du modèle à répondre aux questions scientifiques. En revanche, les questions et réponses ouvertes
