
 Périphériques technologiques
IA
Le grand modèle prend-il des raccourcis pour « battre les classements » ? Le problème de la pollution des données mérite attention
Périphériques technologiques
IA
Le grand modèle prend-il des raccourcis pour « battre les classements » ? Le problème de la pollution des données mérite attention
Le grand modèle prend-il des raccourcis pour « battre les classements » ? Le problème de la pollution des données mérite attention

Au cours de la première année de l’IA générative, le rythme de travail de chacun est devenu beaucoup plus rapide.
Surtout cette année, tout le monde travaille dur pour déployer de grands modèles : Récemment, des géants de la technologie nationaux et étrangers et des start-ups se sont relayés pour lancer de grands modèles. Dès le début de la conférence de presse, ils l'ont tous été. des percées majeures, et chacune a actualisé une liste de référence importante, classée première ou au premier niveau.
Après avoir été enthousiasmés par les progrès rapides de la technologie, de nombreuses personnes trouvent qu'il semble y avoir quelque chose qui ne va pas : pourquoi tout le monde a-t-il sa part dans le classement numéro un ? Quel est ce mécanisme ?
Depuis lors, la question du « list-swiping » a également commencé à attirer l'attention.
Récemment, nous avons remarqué qu'il y a de plus en plus de discussions dans les communautés WeChat Moments et Zhihu sur la question du « swiping the classements » des grands mannequins. En particulier, un article sur Zhihu : Comment évaluez-vous le phénomène souligné par le rapport technique des grands modèles de Tiangong, selon lequel de nombreux grands modèles utilisent des données sur le terrain pour améliorer les classements ? Cela a suscité la discussion de tout le monde.
Lien : https://www.zhihu.com/question/628957425
De nombreux mécanismes de classement de grands modèles ont été exposés
Cette recherche provient de l'Université "Tiangong" de Kunlun Wanwei. L'équipe de recherche a publié un rapport technique sur la plateforme de papier pré-imprimé arXiv à la fin du mois dernier.

Lien papier : https://arxiv.org/abs/2310.19341
L'article lui-même est une introduction à Skywork-13B, une série de grands modèles de langage (LLM) de Tiangong. Les auteurs présentent une méthode de formation en deux étapes utilisant des corpus segmentés, ciblant respectivement la formation générale et la formation approfondie spécifique à un domaine.
Comme d'habitude avec les nouvelles recherches sur les grands modèles, les auteurs ont déclaré que sur les tests de référence populaires, leur modèle non seulement fonctionnait bien, mais atteignait également le niveau de pointe (le meilleur de l'industrie) sur de nombreuses tâches de branche chinoise. . bien).
Le point clé est que le rapport a également vérifié les effets réels de nombreux grands modèles et a souligné que certains autres grands modèles nationaux sont soupçonnés d'être opportunistes. Voici le tableau 8 :
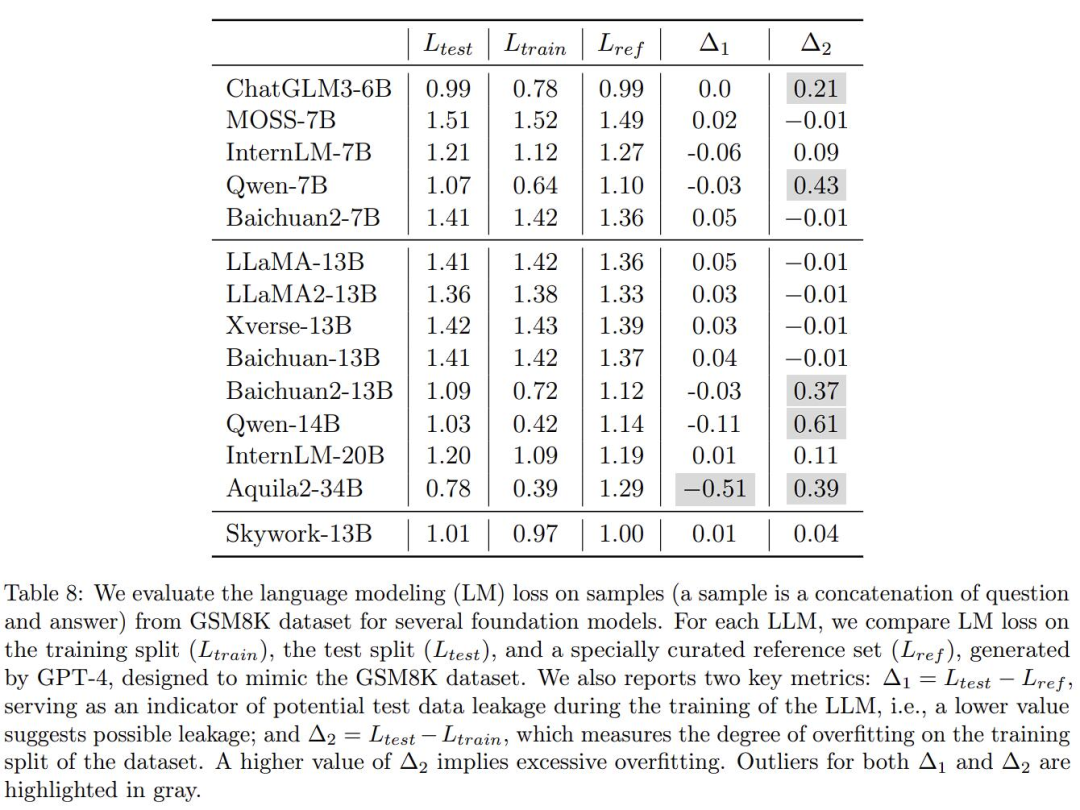
Ici, afin de vérifier le degré de surapprentissage de plusieurs grands modèles courants dans l'industrie sur le test de problème d'application mathématique GSM8K, l'auteur a utilisé GPT-4 pour générer des échantillons GSM8K. avec le même formulaire ont été vérifiés manuellement pour leur exactitude, et ces modèles ont été comparés sur l'ensemble de données généré avec l'ensemble de formation et l'ensemble de test d'origine de GSM8K, et la perte a été calculée. Ensuite, il y a deux métriques :
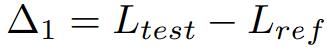
Δ1 sert d'indicateur de fuite potentielle de données de test lors de la formation du modèle, avec des valeurs plus faibles indiquant une fuite possible. Sans formation sur l'ensemble de test, la valeur doit être nulle.
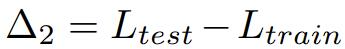
Δ2 mesure le degré de surapprentissage de la répartition d'entraînement de l'ensemble de données. Une valeur Δ2 plus élevée signifie un surapprentissage. S'il n'a pas été entraîné sur l'ensemble d'entraînement, la valeur doit être nulle.
Pour l'expliquer avec des mots simples : si un modèle utilise directement les « vraies questions » et « réponses » du test de référence comme matériel d'apprentissage pendant la formation, et veut les utiliser pour marquer des points, alors ici ce sera anormal.
D'accord, les zones problématiques de Δ1 et Δ2 sont judicieusement mises en évidence en gris ci-dessus.
Les internautes ont commenté que quelqu'un avait finalement révélé le secret de polichinelle de la "pollution des ensembles de données".
Certains internautes ont également déclaré que le niveau d'intelligence des grands modèles dépend toujours de capacités de tir nul, qui ne peuvent pas être atteintes par les tests de référence existants.

Photo : Capture d'écran des commentaires des internautes de Zhihu
Dans l'interaction entre l'auteur et les lecteurs, l'auteur a également déclaré qu'il espérait « permettre à tout le monde d'aborder la question de la triche de manière plus rationnelle. Il y a encore un grand écart entre de nombreux modèles et GPT4 ».
Photo : Capture d'écran de l'article de Zhizhihu https://zhuanlan.zhihu.com/p/664985891
Le problème de la pollution des données mérite attention
En fait, ce n'est pas un phénomène temporaire . Depuis l'introduction de Benchmark, de tels problèmes sont survenus de temps en temps, comme le soulignait le titre d'un article très ironique sur arXiv en septembre de cette année : La pré-formation sur l'ensemble de test est tout ce dont vous avez besoin.

De plus, une étude formelle récente de l'Université Renmin et de l'Université de l'Illinois à Urbana-Champaign a également souligné des problèmes dans l'évaluation des grands modèles. Le titre est très accrocheur « Ne faites pas de votre LLM un tricheur de référence d'évaluation » :

Lien papier : https://arxiv.org/abs/2311.01964
Le journal souligne que Le domaine actuel des grands modèles est celui des grands modèles. Les gens se soucient des classements de référence, mais leur équité et leur fiabilité sont remises en question. Le principal problème est la contamination et la fuite des données, qui peuvent être déclenchées involontairement parce que nous ne connaissons peut-être pas les futurs ensembles de données d'évaluation lors de la préparation du corpus de pré-formation. Par exemple, GPT-3 a révélé que le corpus de pré-formation contenait l'ensemble de données du Children's Book Test, et l'article LLaMA-2 mentionnait l'extraction du contenu contextuel d'une page Web à partir de l'ensemble de données BoolQ.
Les ensembles de données nécessitent beaucoup d'efforts de la part de nombreuses personnes pour collecter, organiser et étiqueter. Si un ensemble de données de haute qualité est suffisamment bon pour être utilisé à des fins d'évaluation, il peut naturellement être utilisé par d'autres pour former de grands modèles.
D'un autre côté, lors de l'évaluation à l'aide de benchmarks existants, les résultats des grands modèles que nous avons évalués ont été principalement obtenus en s'exécutant sur un serveur local ou via des appels API. Au cours de ce processus, tout moyen inapproprié (tel que la contamination des données) susceptible de conduire à des améliorations anormales des performances de l'évaluation n'a pas été rigoureusement examiné.
Ce qui est pire, c'est que la composition détaillée du corpus de formation (comme les sources de données) est souvent considérée comme le « secret » central des grands modèles existants. Cela rend plus difficile l’exploration du problème de la pollution des données.
En d'autres termes, la quantité d'excellentes données est limitée, et sur de nombreux ensembles de tests, GPT-4 et Llama-2 ne posent pas nécessairement de problème. Par exemple, GSM8K a été mentionné dans le premier article et GPT-4 a mentionné l'utilisation de son ensemble de formation dans le rapport technique officiel.
Ne dites-vous pas que les données sont très importantes ? Alors, les performances d'un grand modèle qui utilise de « vraies questions » s'amélioreront-elles parce que les données d'entraînement sont meilleures ? La réponse est non.
Des chercheurs ont découvert expérimentalement que les fuites de référence peuvent amener de grands modèles à générer des résultats exagérés : par exemple, un modèle 1,3B peut dépasser un modèle 10 fois plus grand sur certaines tâches. Mais l’effet secondaire est que si nous utilisons uniquement ces données divulguées pour affiner ou entraîner le modèle, les performances de ces grands modèles spécifiques aux tests sur d’autres tâches de test normales peuvent être affectées.
Par conséquent, l'auteur suggère qu'à l'avenir, lorsque les chercheurs évalueront de grands modèles ou étudieront de nouvelles technologies, ils devraient :
- Utilisez davantage de références provenant de différentes sources couvrant les capacités de base (par exemple, la génération de texte) et les capacités avancées (par exemple, le raisonnement complexe) pour évaluer pleinement les capacités du LLM.
- Lors de l'utilisation d'un benchmark d'évaluation, il est important d'effectuer des contrôles de nettoyage des données entre les données de pré-entraînement et toutes les données associées (telles que les ensembles d'entraînement et de test). En outre, les résultats de l’analyse de la pollution pour l’évaluation de référence doivent être communiqués à titre de référence. Si possible, il est recommandé de rendre publique la composition détaillée des données de pré-formation.
- Il est recommandé d'utiliser des invites de test diversifiées pour réduire l'impact de la sensibilité des invites. Il serait également judicieux de mener une analyse de contamination entre les données de base et les corpus de pré-formation existants pour alerter sur tout risque potentiel de contamination. Aux fins d'évaluation, il est recommandé que chaque soumission soit accompagnée d'un rapport spécial d'analyse de la contamination.
Enfin, heureusement, cette question a commencé à attirer l'attention de tous. Qu'il s'agisse de rapports techniques, de recherches papier ou de discussions communautaires, tout le monde a commencé à prêter attention à la question du « swiping » des grands modèles.
Quels sont vos avis et suggestions efficaces à ce sujet ?
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Open source! Au-delà de ZoeDepth ! DepthFM : estimation rapide et précise de la profondeur monoculaire !
Apr 03, 2024 pm 12:04 PM
Open source! Au-delà de ZoeDepth ! DepthFM : estimation rapide et précise de la profondeur monoculaire !
Apr 03, 2024 pm 12:04 PM
0. À quoi sert cet article ? Nous proposons DepthFM : un modèle d'estimation de profondeur monoculaire génératif de pointe, polyvalent et rapide. En plus des tâches traditionnelles d'estimation de la profondeur, DepthFM démontre également des capacités de pointe dans les tâches en aval telles que l'inpainting en profondeur. DepthFM est efficace et peut synthétiser des cartes de profondeur en quelques étapes d'inférence. Lisons ce travail ensemble ~ 1. Titre des informations sur l'article : DepthFM : FastMonocularDepthEstimationwithFlowMatching Auteur : MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Imaginez un modèle d'intelligence artificielle qui non seulement a la capacité de surpasser l'informatique traditionnelle, mais qui permet également d'obtenir des performances plus efficaces à moindre coût. Ce n'est pas de la science-fiction, DeepSeek-V2[1], le modèle MoE open source le plus puissant au monde est ici. DeepSeek-V2 est un puissant mélange de modèle de langage d'experts (MoE) présentant les caractéristiques d'une formation économique et d'une inférence efficace. Il est constitué de 236B paramètres, dont 21B servent à activer chaque marqueur. Par rapport à DeepSeek67B, DeepSeek-V2 offre des performances plus élevées, tout en économisant 42,5 % des coûts de formation, en réduisant le cache KV de 93,3 % et en augmentant le débit de génération maximal à 5,76 fois. DeepSeek est une entreprise explorant l'intelligence artificielle générale
 L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L’IA change effectivement les mathématiques. Récemment, Tao Zhexuan, qui a prêté une attention particulière à cette question, a transmis le dernier numéro du « Bulletin de l'American Mathematical Society » (Bulletin de l'American Mathematical Society). En se concentrant sur le thème « Les machines changeront-elles les mathématiques ? », de nombreux mathématiciens ont exprimé leurs opinions. L'ensemble du processus a été plein d'étincelles, intense et passionnant. L'auteur dispose d'une équipe solide, comprenant Akshay Venkatesh, lauréat de la médaille Fields, le mathématicien chinois Zheng Lejun, l'informaticien de l'Université de New York Ernest Davis et de nombreux autres universitaires bien connus du secteur. Le monde de l’IA a radicalement changé. Vous savez, bon nombre de ces articles ont été soumis il y a un an.
 Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas entre officiellement dans l’ère des robots électriques ! Hier, l'Atlas hydraulique s'est retiré "en larmes" de la scène de l'histoire. Aujourd'hui, Boston Dynamics a annoncé que l'Atlas électrique était au travail. Il semble que dans le domaine des robots humanoïdes commerciaux, Boston Dynamics soit déterminé à concurrencer Tesla. Après la sortie de la nouvelle vidéo, elle a déjà été visionnée par plus d’un million de personnes en seulement dix heures. Les personnes âgées partent et de nouveaux rôles apparaissent. C'est une nécessité historique. Il ne fait aucun doute que cette année est l’année explosive des robots humanoïdes. Les internautes ont commenté : Les progrès des robots ont fait ressembler la cérémonie d'ouverture de cette année à des êtres humains, et le degré de liberté est bien plus grand que celui des humains. Mais n'est-ce vraiment pas un film d'horreur ? Au début de la vidéo, Atlas est allongé calmement sur le sol, apparemment sur le dos. Ce qui suit est à couper le souffle
 Vitesse Internet lente des données cellulaires sur iPhone : correctifs
May 03, 2024 pm 09:01 PM
Vitesse Internet lente des données cellulaires sur iPhone : correctifs
May 03, 2024 pm 09:01 PM
Vous êtes confronté à un décalage et à une connexion de données mobile lente sur iPhone ? En règle générale, la puissance de l'Internet cellulaire sur votre téléphone dépend de plusieurs facteurs tels que la région, le type de réseau cellulaire, le type d'itinérance, etc. Vous pouvez prendre certaines mesures pour obtenir une connexion Internet cellulaire plus rapide et plus fiable. Correctif 1 – Forcer le redémarrage de l'iPhone Parfois, le redémarrage forcé de votre appareil réinitialise simplement beaucoup de choses, y compris la connexion cellulaire. Étape 1 – Appuyez simplement une fois sur la touche d’augmentation du volume et relâchez-la. Ensuite, appuyez sur la touche de réduction du volume et relâchez-la à nouveau. Étape 2 – La partie suivante du processus consiste à maintenir le bouton sur le côté droit. Laissez l'iPhone finir de redémarrer. Activez les données cellulaires et vérifiez la vitesse du réseau. Vérifiez à nouveau Correctif 2 – Changer le mode de données Bien que la 5G offre de meilleures vitesses de réseau, elle fonctionne mieux lorsque le signal est plus faible
 KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
Plus tôt ce mois-ci, des chercheurs du MIT et d'autres institutions ont proposé une alternative très prometteuse au MLP – KAN. KAN surpasse MLP en termes de précision et d’interprétabilité. Et il peut surpasser le MLP fonctionnant avec un plus grand nombre de paramètres avec un très petit nombre de paramètres. Par exemple, les auteurs ont déclaré avoir utilisé KAN pour reproduire les résultats de DeepMind avec un réseau plus petit et un degré d'automatisation plus élevé. Plus précisément, le MLP de DeepMind compte environ 300 000 paramètres, tandis que le KAN n'en compte qu'environ 200. KAN a une base mathématique solide comme MLP est basé sur le théorème d'approximation universelle, tandis que KAN est basé sur le théorème de représentation de Kolmogorov-Arnold. Comme le montre la figure ci-dessous, KAN a
 La vitalité de la super intelligence s'éveille ! Mais avec l'arrivée de l'IA qui se met à jour automatiquement, les mères n'ont plus à se soucier des goulots d'étranglement des données.
Apr 29, 2024 pm 06:55 PM
La vitalité de la super intelligence s'éveille ! Mais avec l'arrivée de l'IA qui se met à jour automatiquement, les mères n'ont plus à se soucier des goulots d'étranglement des données.
Apr 29, 2024 pm 06:55 PM
Je pleure à mort. Le monde construit à la folie de grands modèles. Les données sur Internet ne suffisent pas du tout. Le modèle de formation ressemble à « The Hunger Games », et les chercheurs en IA du monde entier se demandent comment nourrir ces personnes avides de données. Ce problème est particulièrement important dans les tâches multimodales. À une époque où rien ne pouvait être fait, une équipe de start-up du département de l'Université Renmin de Chine a utilisé son propre nouveau modèle pour devenir la première en Chine à faire de « l'auto-alimentation des données générées par le modèle » une réalité. De plus, il s’agit d’une approche à deux volets, du côté compréhension et du côté génération, les deux côtés peuvent générer de nouvelles données multimodales de haute qualité et fournir un retour de données au modèle lui-même. Qu'est-ce qu'un modèle ? Awaker 1.0, un grand modèle multimodal qui vient d'apparaître sur le Forum Zhongguancun. Qui est l'équipe ? Moteur Sophon. Fondé par Gao Yizhao, doctorant à la Hillhouse School of Artificial Intelligence de l’Université Renmin.
 Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
La dernière vidéo du robot Optimus de Tesla est sortie, et il peut déjà fonctionner en usine. À vitesse normale, il trie les batteries (les batteries 4680 de Tesla) comme ceci : Le responsable a également publié à quoi cela ressemble à une vitesse 20 fois supérieure - sur un petit "poste de travail", en sélectionnant et en sélectionnant et en sélectionnant : Cette fois, il est publié L'un des points forts de la vidéo est qu'Optimus réalise ce travail en usine, de manière totalement autonome, sans intervention humaine tout au long du processus. Et du point de vue d'Optimus, il peut également récupérer et placer la batterie tordue, en se concentrant sur la correction automatique des erreurs : concernant la main d'Optimus, le scientifique de NVIDIA Jim Fan a donné une évaluation élevée : la main d'Optimus est l'un des robots à cinq doigts du monde. le plus adroit. Ses mains ne sont pas seulement tactiles
