
 Périphériques technologiques
IA
Commentaires du scientifique Google Nature : Comment l'intelligence artificielle peut mieux comprendre le cerveau
Périphériques technologiques
IA
Commentaires du scientifique Google Nature : Comment l'intelligence artificielle peut mieux comprendre le cerveau
Commentaires du scientifique Google Nature : Comment l'intelligence artificielle peut mieux comprendre le cerveau

Compilé | Green Dill
Le 7 novembre 2023, Viren Jain, chercheur scientifique principal chez Google Research et responsable de la connectomique au sein de l'équipe Google, a publié un article intitulé "Comment l'intelligence artificielle peut mieux comprendre le cerveau" dans Article de synthèse « Nature » (Comment l'IA pourrait conduire à une meilleure compréhension du cerveau).
Lien papier : https://www.nature.com/articles/d41586-023-03426-3
Les ordinateurs peuvent-ils être programmés pour simuler le cerveau ? C'est une question que les mathématiciens, les théoriciens et les expérimentateurs se posent depuis longtemps - que ce soit par désir de créer une intelligence artificielle (IA) ou parce que son comportement ne peut être compris que si les mathématiques ou les ordinateurs peuvent le reproduire dans des systèmes complexes comme le cerveau. Pour tenter de répondre à cette question, les chercheurs développent depuis les années 1940 des modèles simplifiés des réseaux neuronaux du cerveau. En fait, l’explosion actuelle de l’apprentissage automatique remonte aux premiers travaux inspirés des systèmes biologiques.
Cependant, les résultats de ces efforts permettent désormais aux chercheurs de poser une question légèrement différente : l’apprentissage automatique peut-il être utilisé pour créer des modèles informatiques simulant l’activité cérébrale ?
Au cœur de ces développements se trouvent des quantités croissantes de données cérébrales. Depuis les années 1970, les neuroscientifiques ont produit des connectomes, des cartes de connexions neuronales et de morphologies qui capturent des représentations statiques du cerveau à un instant donné, et ces recherches se sont intensifiées depuis. En plus de ces progrès, les chercheurs ont également amélioré leur capacité à réaliser des enregistrements fonctionnels permettant de mesurer les changements dans l’activité neuronale au fil du temps à la résolution de cellules individuelles. Parallèlement, le domaine de la transcriptomique permet aux chercheurs de mesurer l’activité des gènes dans des échantillons de tissus et même de cartographier le moment et l’endroit où cette activité se produit.
Jusqu'à présent, peu de tentatives ont été faites pour connecter ces différentes sources de données ou pour les collecter simultanément à partir de l'ensemble du cerveau d'un même échantillon. Mais à mesure que le niveau de détail, la taille et le nombre d’ensembles de données augmentent, en particulier pour les cerveaux d’organismes modèles relativement simples, les systèmes d’apprentissage automatique rendent possible une nouvelle approche de la modélisation du cerveau. Cela implique de former des programmes d’intelligence artificielle sur le connectome et d’autres données pour reproduire l’activité neuronale que l’on s’attendrait à trouver dans les systèmes biologiques.
Les neuroscientifiques computationnels et autres doivent résoudre certains défis avant de pouvoir commencer à utiliser l'apprentissage automatique pour créer des simulations du cerveau entier. Cependant, une approche hybride combinant les informations issues des techniques traditionnelles de modélisation du cerveau avec des systèmes d’apprentissage automatique formés sur différents ensembles de données peut rendre l’ensemble des efforts plus rigoureux et informatif.
Cartographie cérébrale
La quête pour cartographier le cerveau a commencé il y a près d'un demi-siècle avec 15 années de recherches minutieuses sur le nématode Caenorhabditis elegans. Au cours des deux dernières décennies, les progrès de la coupe automatisée des tissus et de l’imagerie ont rendu les données anatomiques plus accessibles aux chercheurs, tandis que les progrès de l’informatique et de l’analyse automatisée des images ont transformé l’analyse de ces ensembles de données.
Des connectomes ont maintenant été générés pour l'ensemble du cerveau de C. elegans, de Drosophila melanogaster larvaire et adulte, ainsi que pour de petites portions (respectivement un millième et un millionième) de cerveaux de souris et d'humains.
Il y a des trous majeurs dans les schémas anatomiques produits jusqu'à présent. Les méthodes d’imagerie n’ont pas permis de cartographier à grande échelle les connexions électriques ainsi que les connexions synaptiques chimiques. Les chercheurs se sont concentrés principalement sur les neurones, bien que les cellules gliales non neuronales qui soutiennent les neurones semblent jouer un rôle crucial dans le flux d’informations dans le système nerveux. On ignore encore beaucoup de choses sur les gènes exprimés et les protéines présentes dans les neurones et autres cellules cartographiées.
Néanmoins, ces cartes ont donné quelques indications. Chez Drosophila melanogaster, par exemple, la connectomique permet aux chercheurs d'identifier les mécanismes derrière les circuits neuronaux responsables de comportements tels que l'agressivité. La carte cérébrale a également révélé comment les mouches des fruits calculent les informations dans les circuits chargés de savoir où elles se trouvent et comment se rendre d'un endroit à un autre. Chez les larves de poisson zèbre (Danio rerio), la connectomique a permis de révéler le fonctionnement des circuits synaptiques sous-jacents à la classification des odeurs, au contrôle de la position et du mouvement des yeux et à la navigation.
Des efforts susceptibles de générer un connectome cérébral complet de souris sont en cours – bien qu’avec les méthodes actuelles, cela pourrait prendre une décennie ou plus. Le cerveau de la souris est près de 1 000 fois plus gros que celui de la Drosophila melanogaster, qui est composé d'environ 150 000 neurones.
En plus de toutes ces avancées en connectomique, les chercheurs exploitent la transcriptomique unicellulaire et spatiale pour capturer les modèles d’expression génique avec une précision et une spécificité toujours croissantes. Diverses techniques permettent également aux chercheurs d'enregistrer l'activité neuronale de l'ensemble du cerveau d'un animal vertébré pendant des heures. Dans le cas du cerveau larvaire du poisson zèbre, cela signifie enregistrer près de 100 000 neurones. Il s'agit notamment de protéines aux propriétés fluorescentes qui changent en réponse aux changements de tension ou de niveaux de calcium, ainsi que de techniques de microscopie permettant l'imagerie 3D de cerveaux vivants à une résolution unicellulaire. (L'enregistrement de l'activité neuronale de cette manière fournit une image moins précise que l'enregistrement électrophysiologique, mais bien meilleur que les méthodes non invasives telles que l'imagerie par résonance magnétique fonctionnelle.)
Mathématiques et physique
en essayant de modéliser l'activité cérébrale Lors de la modélisation , les scientifiques utilisent principalement des méthodes basées sur la physique. Cela nécessite de générer une simulation d'un système nerveux ou de parties d'un système nerveux à l'aide d'une description mathématique du comportement de vrais neurones ou de parties d'un système nerveux réel. Cela nécessite également de faire des suppositions éclairées sur des aspects du circuit qui n'ont pas été vérifiés par l'observation, tels que la connectivité du réseau.
Dans certains cas, les spéculations sont étendues (voir « Modèle mystère »), mais dans d’autres cas, les cartes anatomiques à résolution unicellulaire et monosynapse aident les chercheurs à réfuter et à générer des hypothèses.
Modèles mystérieux
En raison du manque de données, il est difficile d'évaluer si certains modèles de réseaux neuronaux capturent ce qui se passe dans des systèmes réels.
Le controversé projet européen sur le cerveau humain, qui s'est terminé en septembre, visait à l'origine à simuler informatiquement l'ensemble du cerveau humain. Bien que cet objectif ait été abandonné, le projet a simulé des parties du cerveau de rongeurs et d’humains, notamment des dizaines de milliers de neurones dans un modèle d’hippocampe de rongeur, sur la base de mesures biologiques limitées et de diverses procédures de génération de données synthétiques.
Un problème majeur avec cette approche est qu’en l’absence de diagrammes anatomiques ou fonctionnels détaillés, il est difficile d’évaluer avec quelle précision la simulation finale capture ce qui se passe dans le système biologique.
Depuis environ soixante-dix ans, les neuroscientifiques affinent les descriptions théoriques des circuits qui permettent le calcul du mouvement chez Drosophila melanogaster. Depuis son achèvement en 2013, le connectome du circuit de détection de mouvement, puis le connectome de vol plus grand, ont fourni des schémas de circuit détaillés qui confortent certaines hypothèses sur le fonctionnement du circuit.
Cependant, les données collectées à partir de réseaux de neurones réels mettent également en évidence les limites des méthodes basées sur l'anatomie.
Par exemple, un modèle de circuit neuronal réalisé dans les années 1990 comprenait une analyse détaillée de la connectivité et de la physiologie des quelque 30 neurones qui composent le ganglion orogastrique du crabe (Cancer borealis) (la structure qui contrôle le mouvement de l'estomac de l'animal). . En mesurant l'activité des neurones dans diverses conditions, les chercheurs ont découvert que même pour des ensembles de neurones relativement petits, des changements apparemment subtils, tels que l'introduction d'un neuromodulateur (une substance qui modifie les propriétés des neurones et des synapses), seront également complètement modifiés. modifier le comportement du circuit. Cela suggère que même avec les connectomes et autres ensembles de données riches pour guider et contraindre les hypothèses sur les circuits neuronaux, les données actuelles ne sont peut-être pas suffisamment détaillées pour que les modélisateurs puissent capturer ce qui se passe dans les systèmes biologiques.
C’est un domaine dans lequel l’apprentissage automatique peut ouvrir la voie à l’avenir.
En optimisant des milliers, voire des milliards de paramètres guidés par le connectome et d'autres données, les modèles d'apprentissage automatique peuvent être entraînés pour produire un comportement de réseau neuronal cohérent avec le comportement réel du réseau neuronal - mesuré à l'aide d'enregistrements fonctionnels à résolution cellulaire.
Ce modèle d'apprentissage automatique peut incorporer des informations provenant de techniques traditionnelles de modélisation du cerveau, telles que le modèle Hodgkin-Huxley, qui décrit les potentiels d'action (changements de tension transmembranaire) dans les neurones) sont initiés et propagés, et à l'aide de cartes de connectivité paramétriques optimisées, l'activité fonctionnelle enregistrements ou d’autres ensembles de données obtenus pour l’ensemble du cerveau. Alternativement, les modèles d’apprentissage automatique peuvent contenir des architectures de « boîte noire » qui contiennent peu de connaissances biologiques explicitement spécifiées mais contiennent des milliards ou des centaines de milliards de paramètres, tous optimisés de manière empirique.
Par exemple, les chercheurs peuvent évaluer de tels modèles en comparant les prédictions de l'activité neuronale d'un système avec les enregistrements de systèmes biologiques réels. Surtout, lorsque les programmes d'apprentissage automatique reçoivent des données non entraînées, ils évaluent la comparaison des prédictions du modèle, comme c'est la pratique courante lors de l'évaluation des systèmes d'apprentissage automatique.
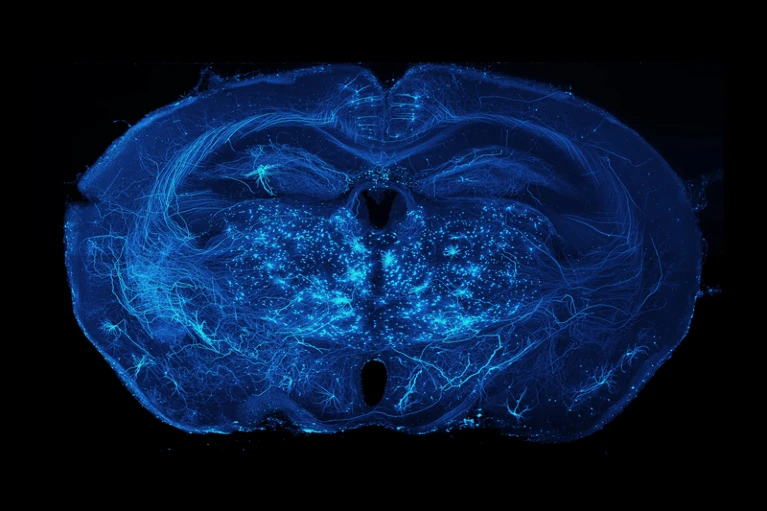
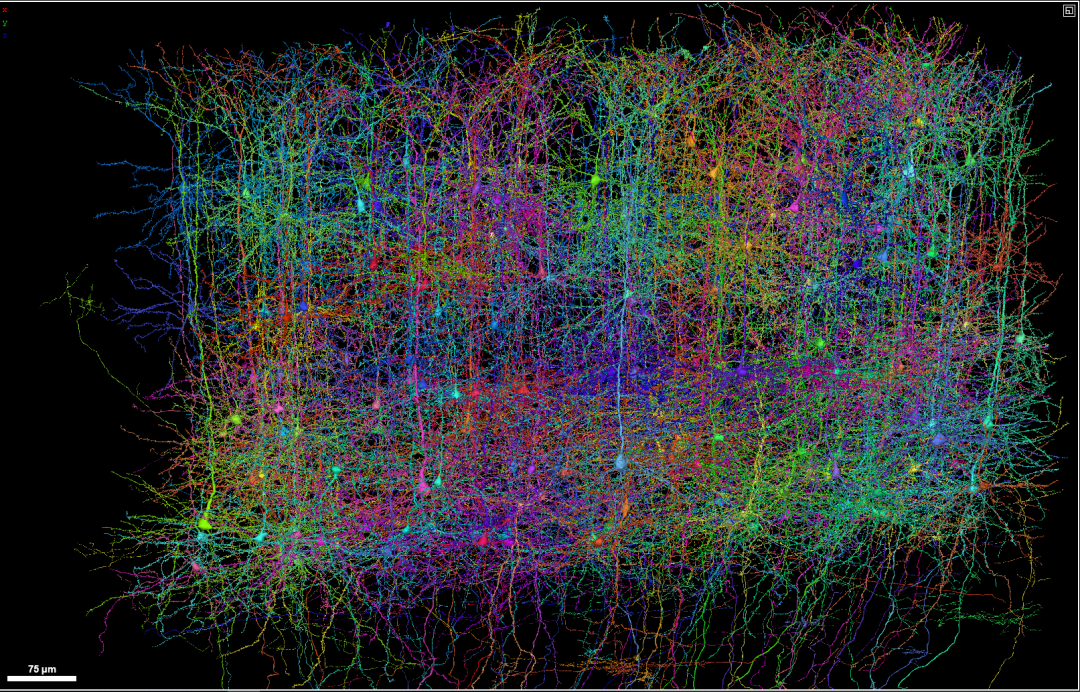
Projections axonales des neurones dans le cerveau de la souris. (Source : Adam Glaser, Jayaram Chandrashekar, Karel Svoboda, Allen Institute for Neurodynamics)
Cette approche permettra une modélisation plus rigoureuse de cerveaux contenant des milliers de neurones ou plus. Par exemple, les chercheurs pourront évaluer si des modèles plus simples et plus faciles à calculer simulent mieux les réseaux neuronaux que des modèles plus complexes qui fournissent des informations biophysiques plus détaillées, et vice versa.
Le Machine Learning est déjà utilisé de cette manière pour améliorer la compréhension d’autres systèmes extrêmement complexes. Par exemple, depuis les années 1950, les systèmes de prévision météorologique s’appuient généralement sur des modèles mathématiques de phénomènes météorologiques soigneusement construits, et les systèmes modernes sont le résultat du perfectionnement itératif de ces modèles par des centaines de chercheurs. Cependant, au cours des cinq dernières années environ, les chercheurs ont développé plusieurs systèmes de prévision météorologique exploitant l’apprentissage automatique. Par exemple, celles-ci contiennent moins d’hypothèses sur la manière dont les gradients de pression déterminent les changements dans la vitesse du vent et sur la manière dont la vitesse du vent déplace l’humidité dans l’atmosphère. Au lieu de cela, des millions de paramètres sont optimisés grâce à l’apprentissage automatique pour produire un comportement météorologique simulé cohérent avec une base de données des modèles météorologiques passés.
Cette façon de faire les choses comporte certains défis. Même si un modèle fait des prédictions précises, il est difficile d’expliquer comment il le fait. De plus, les modèles ne parviennent souvent pas à prédire des scénarios qui ne sont pas inclus dans leurs données de formation. Un modèle météorologique formé pour prédire les prochains jours a du mal à extrapoler les prévisions à des semaines ou des mois dans le futur. Mais dans certains cas – pour prévoir les précipitations plusieurs heures à l’avance – les méthodes d’apprentissage automatique ont surpassé les méthodes traditionnelles. Les modèles d’apprentissage automatique présentent également des avantages pratiques. Ils utilisent un code sous-jacent plus simple et peuvent être utilisés par des scientifiques ayant des connaissances météorologiques moins spécialisées.
Pour la modélisation du cerveau, d’une part, cette approche pourrait aider à combler certaines lacunes des ensembles de données actuels et à réduire le besoin de mesures plus détaillées de composants biologiques individuels, tels que les neurones individuels. D’un autre côté, à mesure que des ensembles de données plus complets seront disponibles, l’intégration des données dans le modèle deviendra simple.
Pensez grand
Afin de concrétiser cette idée, certains défis doivent être résolus.
Les programmes d'apprentissage automatique ne sont aussi bons que les données utilisées pour les former et les évaluer. Par conséquent, les neuroscientifiques devraient chercher à obtenir des ensembles de données provenant du cerveau entier d’un échantillon – ou même du corps entier, si cela devient plus réalisable. Bien qu'il soit plus facile de collecter des données sur certaines parties du cerveau, il est peu probable que l'utilisation de l'apprentissage automatique pour modéliser des systèmes hautement interconnectés, tels que les réseaux neuronaux, fournisse des informations utiles si de nombreuses parties du système ne sont pas présentes dans les données sous-jacentes.
Les chercheurs devraient également s’efforcer d’obtenir des cartes anatomiques des connexions neuronales et des enregistrements fonctionnels (et peut-être à l’avenir des cartes d’expression génique) de cerveaux entiers à partir du même échantillon. Actuellement, l’un ou l’autre groupe a tendance à se concentrer uniquement sur l’obtention de l’un ou de l’autre, plutôt que des deux.
Avec seulement 302 neurones, le système nerveux de C. elegans pourrait avoir suffisamment de câblage pour permettre aux chercheurs de supposer que la carte de connectivité obtenue à partir d'un échantillon sera la même pour n'importe quel autre échantillon - bien que certaines études suggèrent le contraire. Mais pour les systèmes nerveux plus importants, tels que ceux des larves de Drosophila melanogaster et de poisson zèbre, la variation du connectome entre les échantillons est significative, de sorte que les modèles cérébraux doivent être formés sur les données structurelles et fonctionnelles obtenues à partir du même échantillon.
Actuellement, cela n’est possible que dans deux organismes modèles courants. Les corps des larves de C. elegans et du poisson zèbre sont transparents, ce qui signifie que les chercheurs peuvent effectuer des enregistrements fonctionnels de l'ensemble du cerveau de l'organisme et identifier l'activité de neurones individuels. Suite à de tels enregistrements, les animaux peuvent être tués immédiatement, intégrés dans de la résine et sectionnés, et des mesures anatomiques des connexions neuronales peuvent être effectuées. À l'avenir, cependant, les chercheurs pourraient élargir la gamme d'organismes pour lesquels une telle acquisition de données combinées est possible, par exemple en développant de nouvelles méthodes non invasives, éventuellement utilisant des ultrasons, pour enregistrer l'activité neuronale à haute résolution.
L’obtention de tels ensembles de données multimodales dans le même échantillon nécessite une collaboration approfondie entre les chercheurs, un investissement dans de grandes équipes scientifiques et un soutien accru des agences de financement pour un effort plus complet. Mais il existe un précédent pour cette approche, comme le projet MICrONS du US Intelligence Advanced Research Program Activity, qui a obtenu des données fonctionnelles et anatomiques sur 1 millimètre cube de cerveau de souris entre 2016 et 2021.
En plus d'obtenir ces données, les neuroscientifiques doivent se mettre d'accord sur des objectifs de modélisation clés et des mesures quantitatives pour mesurer les progrès. L’objectif du modèle devrait-il être de prédire le comportement de neurones individuels sur la base d’états passés ou de l’ensemble du cerveau ? L’activité d’un seul neurone devrait-elle être la mesure clé, ou le pourcentage de centaines de milliers de neurones actifs ? De même, qu’est-ce qui constitue une représentation précise de l’activité neuronale dans un système biologique ? Des références formelles et convenues sont essentielles pour comparer les approches de modélisation et suivre les progrès au fil du temps.
Enfin, pour présenter les défis de la modélisation cérébrale à diverses communautés, notamment aux neuroscientifiques computationnels et aux experts en apprentissage automatique, les chercheurs doivent clarifier à la communauté scientifique au sens large quelles tâches de modélisation sont la plus haute priorité et quelles mesures doivent être utilisées pour évaluer les performances du modèle. WeatherBench, une plateforme en ligne qui fournit un cadre pour évaluer et comparer les modèles de prévisions météorologiques, fournit un modèle utile.
Complexité des techniques clés
Certains se demanderont – et à juste titre – si les approches d'apprentissage automatique pour la modélisation du cerveau sont scientifiquement utiles. Le problème de la compréhension du fonctionnement du cerveau pourrait-il simplement être remplacé par le problème de la compréhension du fonctionnement des grands réseaux artificiels ?
Cependant, il est encourageant de voir des approches similaires utilisées dans des branches des neurosciences impliquées dans la détermination de la manière dont le cerveau traite et code les stimuli sensoriels tels que la vue et l'odorat. Les chercheurs utilisent de plus en plus des réseaux neuronaux modélisés classiquement, dans lesquels certains détails biologiques sont spécifiés, combinés à des systèmes d'apprentissage automatique. Ces derniers sont entraînés sur de larges ensembles de données visuelles ou audio pour reproduire les capacités visuelles ou auditives du système neuronal, comme la reconnaissance d'images. Le réseau résultant présentait des similitudes frappantes avec les réseaux biologiques, mais était plus facile à analyser et à interroger que les véritables réseaux neuronaux.
Pour l’instant, il s’agit peut-être simplement de se demander si les données des atlas cérébraux actuels et d’autres travaux peuvent entraîner des modèles d’apprentissage automatique pour reproduire une activité neuronale qui correspond à ce qui est observé dans les systèmes biologiques. Ici, même l’échec peut être amusant – ce qui suggère que la recherche cartographique doit être approfondie.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Repoussant les limites de la détection de défauts traditionnelle, « Defect Spectrum » permet pour la première fois une détection de défauts industriels d'une ultra haute précision et d'une sémantique riche.
Jul 26, 2024 pm 05:38 PM
Repoussant les limites de la détection de défauts traditionnelle, « Defect Spectrum » permet pour la première fois une détection de défauts industriels d'une ultra haute précision et d'une sémantique riche.
Jul 26, 2024 pm 05:38 PM
Dans la fabrication moderne, une détection précise des défauts est non seulement la clé pour garantir la qualité des produits, mais également la clé de l’amélioration de l’efficacité de la production. Cependant, les ensembles de données de détection de défauts existants manquent souvent de précision et de richesse sémantique requises pour les applications pratiques, ce qui rend les modèles incapables d'identifier des catégories ou des emplacements de défauts spécifiques. Afin de résoudre ce problème, une équipe de recherche de premier plan composée de l'Université des sciences et technologies de Hong Kong, Guangzhou et de Simou Technology a développé de manière innovante l'ensemble de données « DefectSpectrum », qui fournit une annotation à grande échelle détaillée et sémantiquement riche des défauts industriels. Comme le montre le tableau 1, par rapport à d'autres ensembles de données industrielles, l'ensemble de données « DefectSpectrum » fournit le plus grand nombre d'annotations de défauts (5 438 échantillons de défauts) et la classification de défauts la plus détaillée (125 catégories de défauts).
 Le modèle de dialogue NVIDIA ChatQA a évolué vers la version 2.0, avec la longueur du contexte mentionnée à 128 Ko
Jul 26, 2024 am 08:40 AM
Le modèle de dialogue NVIDIA ChatQA a évolué vers la version 2.0, avec la longueur du contexte mentionnée à 128 Ko
Jul 26, 2024 am 08:40 AM
La communauté ouverte LLM est une époque où une centaine de fleurs fleurissent et s'affrontent. Vous pouvez voir Llama-3-70B-Instruct, QWen2-72B-Instruct, Nemotron-4-340B-Instruct, Mixtral-8x22BInstruct-v0.1 et bien d'autres. excellents interprètes. Cependant, par rapport aux grands modèles propriétaires représentés par le GPT-4-Turbo, les modèles ouverts présentent encore des lacunes importantes dans de nombreux domaines. En plus des modèles généraux, certains modèles ouverts spécialisés dans des domaines clés ont été développés, tels que DeepSeek-Coder-V2 pour la programmation et les mathématiques, et InternVL pour les tâches de langage visuel.
 Google AI a remporté la médaille d'argent de l'Olympiade mathématique de l'OMI, le modèle de raisonnement mathématique AlphaProof a été lancé et l'apprentissage par renforcement est de retour.
Jul 26, 2024 pm 02:40 PM
Google AI a remporté la médaille d'argent de l'Olympiade mathématique de l'OMI, le modèle de raisonnement mathématique AlphaProof a été lancé et l'apprentissage par renforcement est de retour.
Jul 26, 2024 pm 02:40 PM
Pour l’IA, l’Olympiade mathématique n’est plus un problème. Jeudi, l'intelligence artificielle de Google DeepMind a réalisé un exploit : utiliser l'IA pour résoudre la vraie question de l'Olympiade mathématique internationale de cette année, l'OMI, et elle n'était qu'à un pas de remporter la médaille d'or. Le concours de l'OMI qui vient de se terminer la semaine dernière comportait six questions portant sur l'algèbre, la combinatoire, la géométrie et la théorie des nombres. Le système d'IA hybride proposé par Google a répondu correctement à quatre questions et a marqué 28 points, atteignant le niveau de la médaille d'argent. Plus tôt ce mois-ci, le professeur titulaire de l'UCLA, Terence Tao, venait de promouvoir l'Olympiade mathématique de l'IA (AIMO Progress Award) avec un prix d'un million de dollars. De manière inattendue, le niveau de résolution de problèmes d'IA s'était amélioré à ce niveau avant juillet. Posez les questions simultanément sur l'OMI. La chose la plus difficile à faire correctement est l'OMI, qui a la plus longue histoire, la plus grande échelle et la plus négative.
 Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
L'ensemble de données ScienceAI Question Answering (QA) joue un rôle essentiel dans la promotion de la recherche sur le traitement du langage naturel (NLP). Des ensembles de données d'assurance qualité de haute qualité peuvent non seulement être utilisés pour affiner les modèles, mais également évaluer efficacement les capacités des grands modèles linguistiques (LLM), en particulier la capacité à comprendre et à raisonner sur les connaissances scientifiques. Bien qu’il existe actuellement de nombreux ensembles de données scientifiques d’assurance qualité couvrant la médecine, la chimie, la biologie et d’autres domaines, ces ensembles de données présentent encore certaines lacunes. Premièrement, le formulaire de données est relativement simple, et la plupart sont des questions à choix multiples. Elles sont faciles à évaluer, mais limitent la plage de sélection des réponses du modèle et ne peuvent pas tester pleinement la capacité du modèle à répondre aux questions scientifiques. En revanche, les questions et réponses ouvertes
 Formation avec des millions de données cristallines pour résoudre le problème de la phase cristallographique, la méthode d'apprentissage profond PhAI est publiée dans Science
Aug 08, 2024 pm 09:22 PM
Formation avec des millions de données cristallines pour résoudre le problème de la phase cristallographique, la méthode d'apprentissage profond PhAI est publiée dans Science
Aug 08, 2024 pm 09:22 PM
Editeur | KX À ce jour, les détails structurels et la précision déterminés par cristallographie, des métaux simples aux grandes protéines membranaires, sont inégalés par aucune autre méthode. Cependant, le plus grand défi, appelé problème de phase, reste la récupération des informations de phase à partir d'amplitudes déterminées expérimentalement. Des chercheurs de l'Université de Copenhague au Danemark ont développé une méthode d'apprentissage en profondeur appelée PhAI pour résoudre les problèmes de phase cristalline. Un réseau neuronal d'apprentissage en profondeur formé à l'aide de millions de structures cristallines artificielles et de leurs données de diffraction synthétique correspondantes peut générer des cartes précises de densité électronique. L'étude montre que cette méthode de solution structurelle ab initio basée sur l'apprentissage profond peut résoudre le problème de phase avec une résolution de seulement 2 Angströms, ce qui équivaut à seulement 10 à 20 % des données disponibles à la résolution atomique, alors que le calcul ab initio traditionnel
 Le point de vue de la nature : les tests de l'intelligence artificielle en médecine sont dans le chaos. Que faut-il faire ?
Aug 22, 2024 pm 04:37 PM
Le point de vue de la nature : les tests de l'intelligence artificielle en médecine sont dans le chaos. Que faut-il faire ?
Aug 22, 2024 pm 04:37 PM
Editeur | ScienceAI Sur la base de données cliniques limitées, des centaines d'algorithmes médicaux ont été approuvés. Les scientifiques se demandent qui devrait tester les outils et comment le faire au mieux. Devin Singh a vu un patient pédiatrique aux urgences subir un arrêt cardiaque alors qu'il attendait un traitement pendant une longue période, ce qui l'a incité à explorer l'application de l'IA pour réduire les temps d'attente. À l’aide des données de triage des salles d’urgence de SickKids, Singh et ses collègues ont construit une série de modèles d’IA pour fournir des diagnostics potentiels et recommander des tests. Une étude a montré que ces modèles peuvent accélérer les visites chez le médecin de 22,3 %, accélérant ainsi le traitement des résultats de près de 3 heures par patient nécessitant un examen médical. Cependant, le succès des algorithmes d’intelligence artificielle dans la recherche ne fait que le vérifier.
 Les performances de SOTA, la méthode d'IA de prédiction d'affinité protéine-ligand multimodale de Xiamen, combinent pour la première fois des informations sur la surface moléculaire
Jul 17, 2024 pm 06:37 PM
Les performances de SOTA, la méthode d'IA de prédiction d'affinité protéine-ligand multimodale de Xiamen, combinent pour la première fois des informations sur la surface moléculaire
Jul 17, 2024 pm 06:37 PM
Editeur | KX Dans le domaine de la recherche et du développement de médicaments, il est crucial de prédire avec précision et efficacité l'affinité de liaison des protéines et des ligands pour le criblage et l'optimisation des médicaments. Cependant, les études actuelles ne prennent pas en compte le rôle important des informations sur la surface moléculaire dans les interactions protéine-ligand. Sur cette base, des chercheurs de l'Université de Xiamen ont proposé un nouveau cadre d'extraction de caractéristiques multimodales (MFE), qui combine pour la première fois des informations sur la surface des protéines, la structure et la séquence 3D, et utilise un mécanisme d'attention croisée pour comparer différentes modalités. alignement. Les résultats expérimentaux démontrent que cette méthode atteint des performances de pointe dans la prédiction des affinités de liaison protéine-ligand. De plus, les études d’ablation démontrent l’efficacité et la nécessité des informations sur la surface des protéines et de l’alignement des caractéristiques multimodales dans ce cadre. Les recherches connexes commencent par "S
 Couvrant les tâches de texte, de positionnement et de segmentation, Zhiyuan et les Chinois de Hong Kong ont proposé conjointement le premier grand modèle médical multimodal 3D multifonctionnel
Jun 22, 2024 am 07:16 AM
Couvrant les tâches de texte, de positionnement et de segmentation, Zhiyuan et les Chinois de Hong Kong ont proposé conjointement le premier grand modèle médical multimodal 3D multifonctionnel
Jun 22, 2024 am 07:16 AM
Auteur | Rédacteur Bai Fan, Université chinoise de Hong Kong | ScienceAI Récemment, l'Université chinoise de Hong Kong et Zhiyuan ont proposé conjointement la série de travaux M3D, comprenant M3D-Data, M3D-LaMed et M3D-Bench, pour promouvoir les images médicales 3D. de tous les aspects des ensembles de données, des modèles et des évaluations. Développement d'analyses. (1) M3D-Data est actuellement le plus grand ensemble de données d'images médicales 3D, comprenant M3D-Cap (120 000 paires d'images et de textes 3D), M3D-VQA (510 000 paires de questions et réponses), M3D-Seg (150 000 paires de masques 3D), M3D-RefSeg ( Segmentation d'inférence 3K) au total quatre sous-ensembles de données. (2) M3D-LaMed est actuellement le grand modèle médical multimodal 3D le plus polyvalent pouvant
