
 Périphériques technologiques
IA
S-LoRA : Il est possible d'exécuter des milliers de grands modèles sur un seul GPU
Périphériques technologiques
IA
S-LoRA : Il est possible d'exécuter des milliers de grands modèles sur un seul GPU
S-LoRA : Il est possible d'exécuter des milliers de grands modèles sur un seul GPU

De manière générale, le déploiement de grands modèles de langage adopte généralement la méthode du « pré-entraînement-réglage fin ». Cependant, lorsque l’on peaufine le modèle de base pour plusieurs tâches (telles que les assistants personnalisés), le coût de la formation et du service devient très élevé. L'adaptation LowRank (LoRA) est une méthode efficace de réglage fin des paramètres, qui est généralement utilisée pour adapter le modèle de base à plusieurs tâches, générant ainsi un grand nombre d'adaptateurs LoRA dérivés
Réécrit : L'inférence par lots offre de nombreuses opportunités pendant le service, et il a été démontré que ce modèle permet d'obtenir des performances comparables à un réglage fin complet en ajustant avec précision les poids des adaptateurs. Bien que cette approche permette une inférence à faible latence sur un seul adaptateur et une exécution en série sur plusieurs adaptateurs, elle réduit considérablement le débit global du service et augmente la latence globale lors du service simultané de plusieurs adaptateurs. Par conséquent, on ne sait toujours pas comment résoudre le problème de service à grande échelle de ces variantes affinées.
Récemment, des chercheurs de l'UC Berkeley, Stanford et d'autres universités ont proposé une nouvelle méthode de réglage fin appelée S-LoRA dans un article

- Adresse papier : https://arxiv.org/pdf/2311.03285.pdf
- Adresse du projet : https://github.com/S-LoRA/S-LoRA
S-LoRA est un système conçu pour le service évolutif de nombreux adaptateurs LoRA. Il stocke tous les adaptateurs dans la mémoire principale et récupère l'adaptateur utilisé par la requête en cours d'exécution dans la mémoire GPU.
S-LoRA propose la technologie "Unified Paging", qui utilise un pool de mémoire unifié pour gérer différents niveaux de poids d'adaptateur dynamiques et des tenseurs de cache KV de différentes longueurs de séquence. De plus, S-LoRA utilise une nouvelle stratégie de parallélisme tensoriel et des noyaux CUDA personnalisés hautement optimisés pour permettre le traitement par lots hétérogène des calculs LoRA.
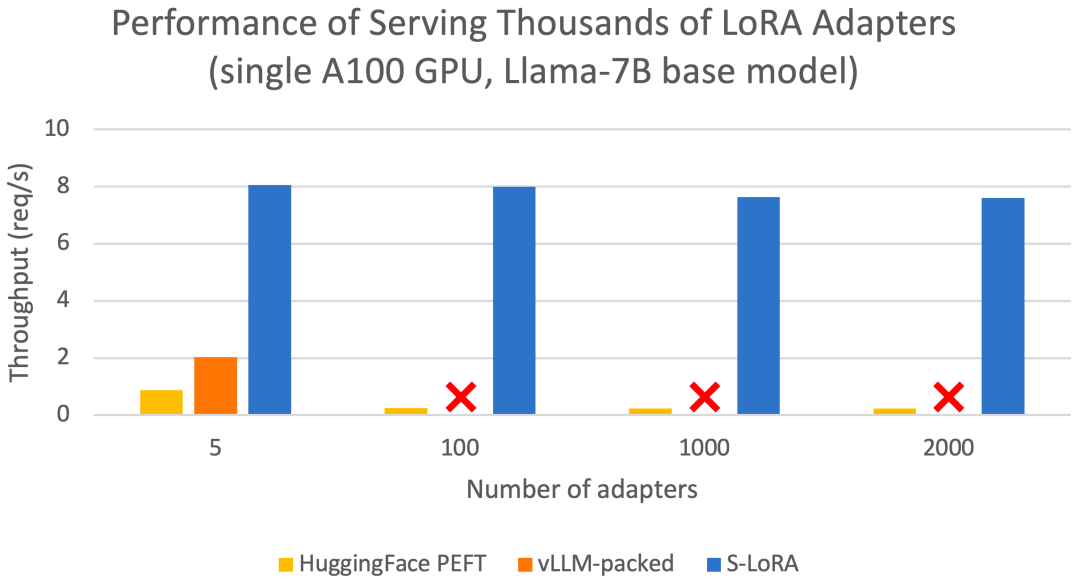
Ces fonctionnalités permettent à S-LoRA de servir des milliers d'adaptateurs LoRA sur un ou plusieurs GPU à une fraction du coût (desservant 2000 adaptateurs simultanément) et de minimiser les coûts de calcul LoRA supplémentaires. En comparaison, vLLM-packed doit conserver plusieurs copies de poids et ne peut servir que moins de 5 adaptateurs en raison des limitations de mémoire GPU
Par rapport aux technologies de pointe telles que HuggingFace PEFT et vLLM (prend uniquement en charge le service LoRA ) Par rapport à la bibliothèque, le débit de S-LoRA peut être augmenté jusqu'à 4 fois et le nombre d'adaptateurs servis peut être augmenté de plusieurs ordres de grandeur. Par conséquent, S-LoRA est en mesure de fournir des services évolutifs pour de nombreux modèles de réglage précis spécifiques à des tâches et offre le potentiel de personnalisation à grande échelle des services de réglage fin.
S-LoRA contient trois principales parties innovantes. La section 4 présente la stratégie de traitement par lots utilisée pour décomposer les calculs entre le modèle de base et l'adaptateur LoRA. En outre, les chercheurs ont également résolu les problèmes de planification de la demande, notamment des aspects tels que le regroupement d'adaptateurs et le contrôle d'admission. La possibilité de traiter par lots sur des adaptateurs simultanés pose de nouveaux défis en matière de gestion de la mémoire. Dans la cinquième partie, les chercheurs font la promotion de PagedAttention to Unfied Paging pour prendre en charge le chargement dynamique des adaptateurs LoRA. Cette approche utilise un pool de mémoire unifié pour stocker le cache KV et les poids de l'adaptateur de manière paginée, ce qui peut réduire la fragmentation et équilibrer les tailles changeantes dynamiquement du cache KV et des poids de l'adaptateur. Enfin, la partie 6 présente une nouvelle stratégie tensorielle parallèle qui peut découpler efficacement le modèle de base et l'adaptateur LoRA
Voici les points forts :
Traitement par lots
Pour un seul adaptateur, Hu et al. (2021) ont proposé une méthode recommandée, qui consiste à fusionner les poids de l'adaptateur avec les poids du modèle de base, ce qui donne lieu à un nouveau modèle (voir l'équation 1). L'avantage est qu'il n'y a pas de surcharge d'adaptateur supplémentaire pendant l'inférence puisque le nouveau modèle a le même nombre de paramètres que le modèle de base. En fait, il s'agissait également d'une caractéristique notable du travail LoRA original
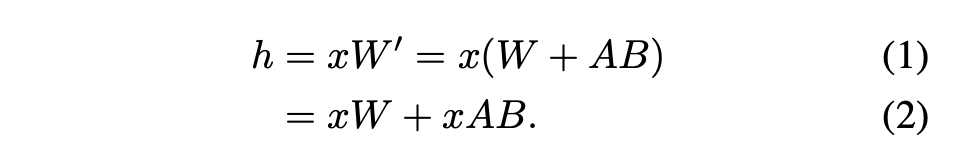
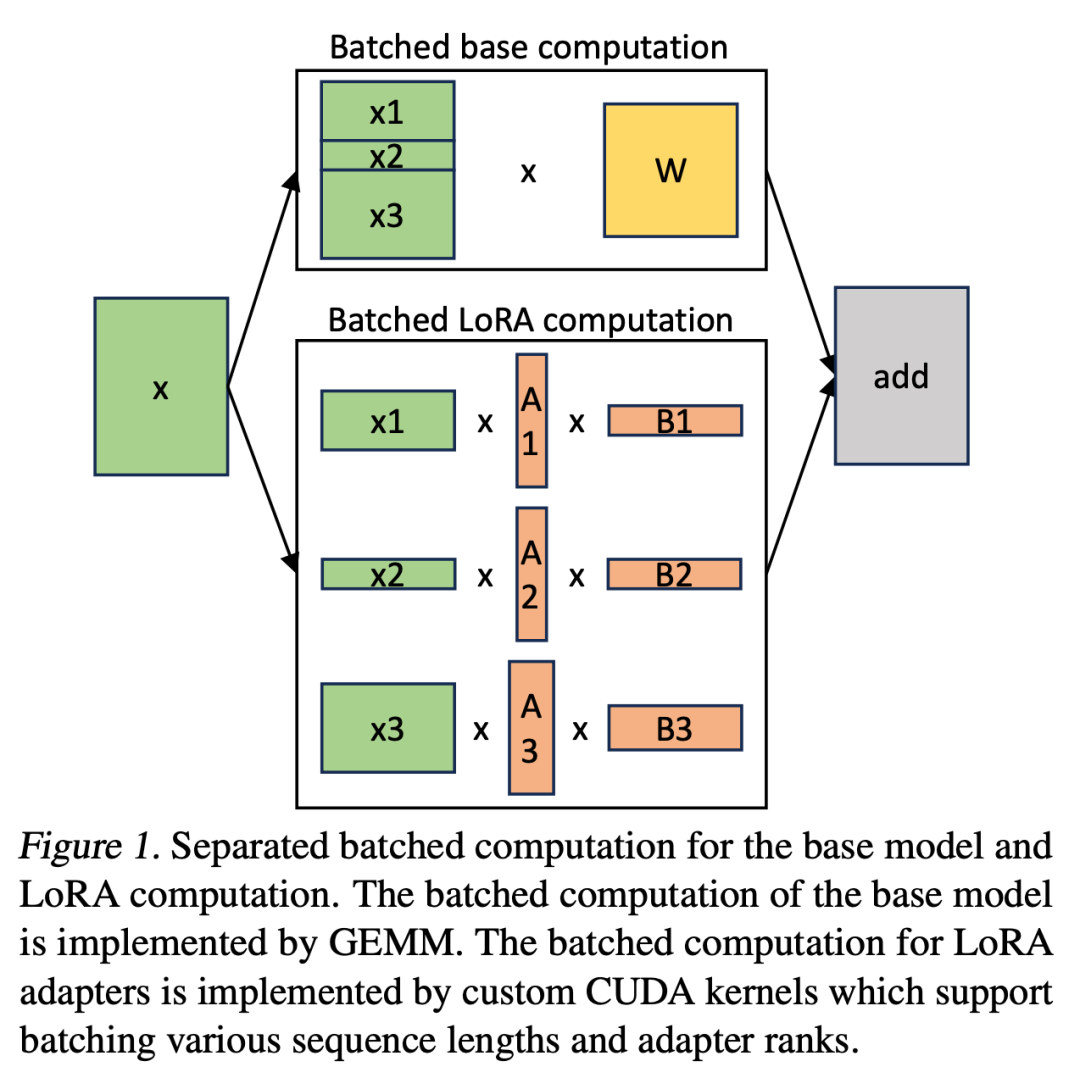
Cet article souligne que la fusion des adaptateurs LoRA dans le modèle de base est inefficace pour les configurations de services multi-LoRA à haut débit. Au lieu de cela, les chercheurs proposent de calculer LoRA en temps réel pour calculer xAB (comme le montre l’équation 2).
Dans S-LoRA, le calcul du modèle de base est effectué par lots, puis un xAB supplémentaire est effectué pour tous les adaptateurs individuellement à l'aide d'un noyau CUDA personnalisé. Ce processus est illustré à la figure 1. Au lieu d'utiliser le remplissage et les noyaux GEMM par lots de la bibliothèque BLAS pour calculer LoRA, nous avons implémenté un noyau CUDA personnalisé pour obtenir un calcul plus efficace sans remplissage. Les détails d'implémentation se trouvent dans la sous-section 5.3.
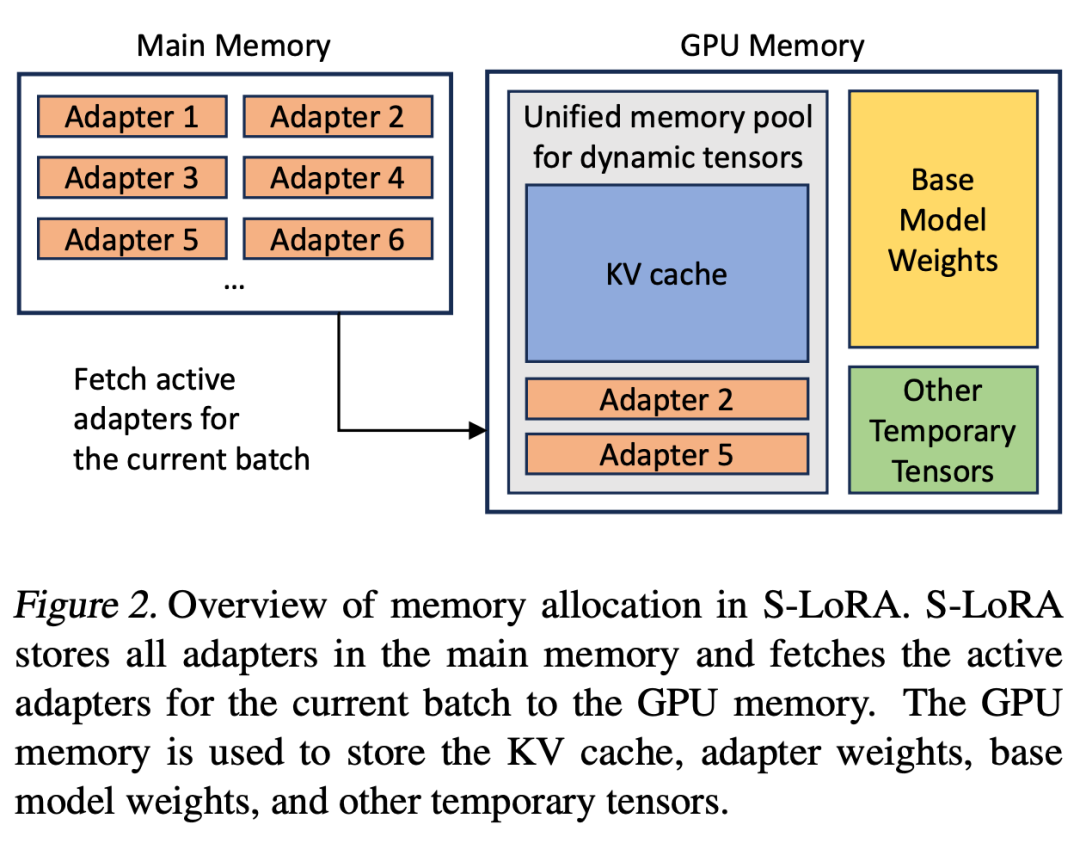
Le nombre d'adaptateurs LoRA pourrait être important s'ils étaient stockés dans la mémoire principale, mais actuellement, le nombre d'adaptateurs LoRA requis pour exécuter un lot est contrôlable car la taille du lot est limitée par la mémoire GPU. Pour en profiter, nous stockons tous les adaptateurs LoRA dans la mémoire principale et, lors de l'inférence pour le lot en cours d'exécution, récupérons uniquement les adaptateurs LoRA requis pour ce lot dans la RAM GPU. Dans ce cas, le nombre maximum d'adaptateurs réparables est limité par la taille de la mémoire principale. La figure 2 illustre ce processus. La section 5 aborde également les techniques de gestion efficace de la mémoire
Gestion de la mémoire
Par rapport à la gestion d'un modèle de base unique, la gestion simultanée de plusieurs cartes adaptateurs LoRA apportera de nouveaux défis en matière de gestion de la mémoire. Pour prendre en charge plusieurs adaptateurs, S-LoRA les stocke dans la mémoire principale et charge dynamiquement les poids d'adaptateur requis pour le lot en cours d'exécution dans la RAM GPU.
Dans ce processus, il y a deux défis évidents. Le premier est le problème de fragmentation de la mémoire, provoqué par le chargement et le déchargement dynamiques de poids d'adaptateur de différentes tailles. Le second est la surcharge de latence provoquée par le chargement et le déchargement de l’adaptateur. Afin de résoudre efficacement ces problèmes, les chercheurs ont proposé le concept de « pagination unifiée » et ont implémenté le chevauchement des E/S et des calculs en prélevant les poids des adaptateurs
Unified Paging
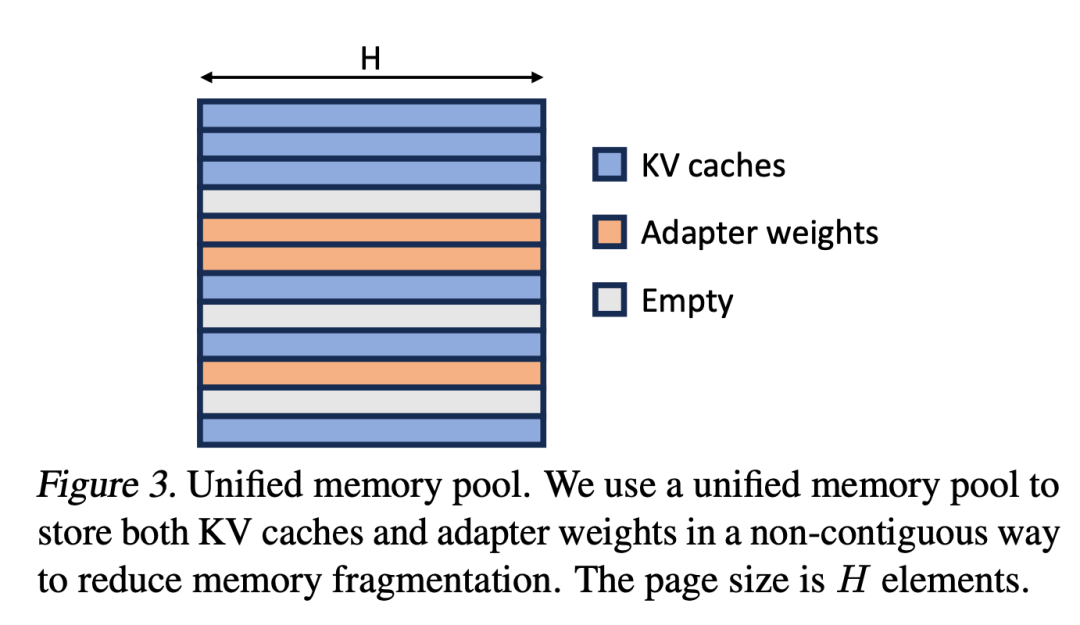
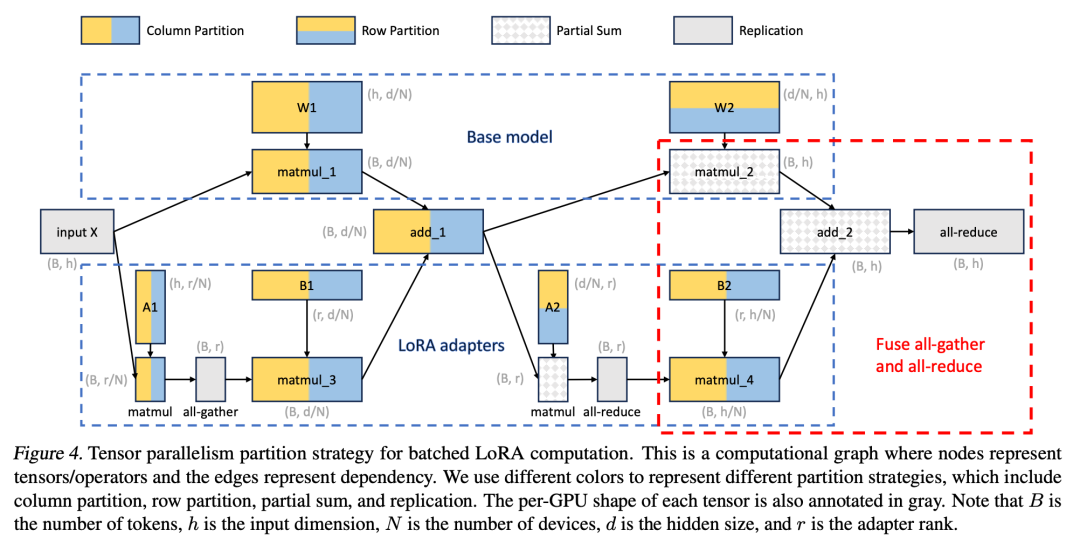
Chercheur Étendre le concept de PagedAttention à la pagination unifiée. La pagination unifiée est utilisée non seulement pour gérer le cache KV, mais également pour gérer les poids des adaptateurs. La pagination unifiée utilise un pool de mémoire unifié pour gérer conjointement le cache KV et les poids des adaptateurs. Pour y parvenir, ils allouent d’abord statiquement un grand tampon au pool de mémoire, qui utilise tout l’espace disponible, à l’exception de l’espace utilisé pour stocker les poids du modèle de base et les tenseurs d’activation temporaires. Le cache KV et les poids de l'adaptateur sont stockés dans le pool de mémoire de manière paginée, et chaque page correspond à un vecteur H. Par conséquent, un tenseur de cache KV avec une longueur de séquence S occupe S pages, tandis qu'un tenseur de poids LoRA de niveau R occupe R pages. La figure 3 montre la disposition du pool de mémoire, dans lequel le cache KV et les poids de l'adaptateur sont stockés de manière entrelacée et non contiguë. Cette approche réduit considérablement la fragmentation et garantit que différents niveaux de poids d'adaptateur peuvent coexister avec le cache KV dynamique de manière structurée et systématique. La stratégie tenseur parallèle est conçue pour prendre en charge l'inférence multi-GPU de grands modèles de transformateurs. Le parallélisme tensoriel est l'approche parallèle la plus largement utilisée car son paradigme à programme unique et données multiples simplifie sa mise en œuvre et son intégration avec les systèmes existants. Le parallélisme tensoriel peut réduire l'utilisation de la mémoire et la latence par GPU lors de la diffusion de modèles volumineux. Dans ce contexte, des adaptateurs LoRA supplémentaires introduisent de nouvelles matrices de poids et multiplications matricielles, qui nécessitent de nouvelles stratégies de partitionnement pour ces ajouts.
Évaluation
Enfin, les chercheurs ont évalué S-LoRA en servant Llama-7B/13B/30B/70B
Les résultats ont montré que S-LoRA peut être utilisé dans un Servez des milliers d'adaptateurs LoRA sur un GPU ou plusieurs GPU avec peu de frais généraux. S-LoRA atteint un débit jusqu'à 30 fois supérieur à celui de Huggingface PEFT, une bibliothèque de réglage fin de pointe et efficace en termes de paramètres. S-LoRA augmente le débit de 4 fois et augmente le nombre d'adaptateurs de service de plusieurs ordres de grandeur par rapport à l'utilisation d'un système de service à haut débit vLLM qui prend en charge les services LoRA.
Pour plus de détails sur la recherche, veuillez vous référer à l'article original.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Utilisez ddrescue pour récupérer des données sous Linux
Mar 20, 2024 pm 01:37 PM
Utilisez ddrescue pour récupérer des données sous Linux
Mar 20, 2024 pm 01:37 PM
DDREASE est un outil permettant de récupérer des données à partir de périphériques de fichiers ou de blocs tels que des disques durs, des SSD, des disques RAM, des CD, des DVD et des périphériques de stockage USB. Il copie les données d'un périphérique bloc à un autre, laissant derrière lui les blocs corrompus et ne déplaçant que les bons blocs. ddreasue est un puissant outil de récupération entièrement automatisé car il ne nécessite aucune interruption pendant les opérations de récupération. De plus, grâce au fichier map ddasue, il peut être arrêté et repris à tout moment. Les autres fonctionnalités clés de DDREASE sont les suivantes : Il n'écrase pas les données récupérées mais comble les lacunes en cas de récupération itérative. Cependant, il peut être tronqué si l'outil est invité à le faire explicitement. Récupérer les données de plusieurs fichiers ou blocs en un seul
 Open source! Au-delà de ZoeDepth ! DepthFM : estimation rapide et précise de la profondeur monoculaire !
Apr 03, 2024 pm 12:04 PM
Open source! Au-delà de ZoeDepth ! DepthFM : estimation rapide et précise de la profondeur monoculaire !
Apr 03, 2024 pm 12:04 PM
0. À quoi sert cet article ? Nous proposons DepthFM : un modèle d'estimation de profondeur monoculaire génératif de pointe, polyvalent et rapide. En plus des tâches traditionnelles d'estimation de la profondeur, DepthFM démontre également des capacités de pointe dans les tâches en aval telles que l'inpainting en profondeur. DepthFM est efficace et peut synthétiser des cartes de profondeur en quelques étapes d'inférence. Lisons ce travail ensemble ~ 1. Titre des informations sur l'article : DepthFM : FastMonocularDepthEstimationwithFlowMatching Auteur : MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Les performances de JAX, promu par Google, ont dépassé celles de Pytorch et TensorFlow lors de récents tests de référence, se classant au premier rang sur 7 indicateurs. Et le test n’a pas été fait sur le TPU présentant les meilleures performances JAX. Bien que parmi les développeurs, Pytorch soit toujours plus populaire que Tensorflow. Mais à l’avenir, des modèles plus volumineux seront peut-être formés et exécutés sur la base de la plate-forme JAX. Modèles Récemment, l'équipe Keras a comparé trois backends (TensorFlow, JAX, PyTorch) avec l'implémentation native de PyTorch et Keras2 avec TensorFlow. Premièrement, ils sélectionnent un ensemble de
 Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas entre officiellement dans l’ère des robots électriques ! Hier, l'Atlas hydraulique s'est retiré "en larmes" de la scène de l'histoire. Aujourd'hui, Boston Dynamics a annoncé que l'Atlas électrique était au travail. Il semble que dans le domaine des robots humanoïdes commerciaux, Boston Dynamics soit déterminé à concurrencer Tesla. Après la sortie de la nouvelle vidéo, elle a déjà été visionnée par plus d’un million de personnes en seulement dix heures. Les personnes âgées partent et de nouveaux rôles apparaissent. C'est une nécessité historique. Il ne fait aucun doute que cette année est l’année explosive des robots humanoïdes. Les internautes ont commenté : Les progrès des robots ont fait ressembler la cérémonie d'ouverture de cette année à des êtres humains, et le degré de liberté est bien plus grand que celui des humains. Mais n'est-ce vraiment pas un film d'horreur ? Au début de la vidéo, Atlas est allongé calmement sur le sol, apparemment sur le dos. Ce qui suit est à couper le souffle
 Vitesse Internet lente des données cellulaires sur iPhone : correctifs
May 03, 2024 pm 09:01 PM
Vitesse Internet lente des données cellulaires sur iPhone : correctifs
May 03, 2024 pm 09:01 PM
Vous êtes confronté à un décalage et à une connexion de données mobile lente sur iPhone ? En règle générale, la puissance de l'Internet cellulaire sur votre téléphone dépend de plusieurs facteurs tels que la région, le type de réseau cellulaire, le type d'itinérance, etc. Vous pouvez prendre certaines mesures pour obtenir une connexion Internet cellulaire plus rapide et plus fiable. Correctif 1 – Forcer le redémarrage de l'iPhone Parfois, le redémarrage forcé de votre appareil réinitialise simplement beaucoup de choses, y compris la connexion cellulaire. Étape 1 – Appuyez simplement une fois sur la touche d’augmentation du volume et relâchez-la. Ensuite, appuyez sur la touche de réduction du volume et relâchez-la à nouveau. Étape 2 – La partie suivante du processus consiste à maintenir le bouton sur le côté droit. Laissez l'iPhone finir de redémarrer. Activez les données cellulaires et vérifiez la vitesse du réseau. Vérifiez à nouveau Correctif 2 – Changer le mode de données Bien que la 5G offre de meilleures vitesses de réseau, elle fonctionne mieux lorsque le signal est plus faible
 La vitalité de la super intelligence s'éveille ! Mais avec l'arrivée de l'IA qui se met à jour automatiquement, les mères n'ont plus à se soucier des goulots d'étranglement des données.
Apr 29, 2024 pm 06:55 PM
La vitalité de la super intelligence s'éveille ! Mais avec l'arrivée de l'IA qui se met à jour automatiquement, les mères n'ont plus à se soucier des goulots d'étranglement des données.
Apr 29, 2024 pm 06:55 PM
Je pleure à mort. Le monde construit à la folie de grands modèles. Les données sur Internet ne suffisent pas du tout. Le modèle de formation ressemble à « The Hunger Games », et les chercheurs en IA du monde entier se demandent comment nourrir ces personnes avides de données. Ce problème est particulièrement important dans les tâches multimodales. À une époque où rien ne pouvait être fait, une équipe de start-up du département de l'Université Renmin de Chine a utilisé son propre nouveau modèle pour devenir la première en Chine à faire de « l'auto-alimentation des données générées par le modèle » une réalité. De plus, il s’agit d’une approche à deux volets, du côté compréhension et du côté génération, les deux côtés peuvent générer de nouvelles données multimodales de haute qualité et fournir un retour de données au modèle lui-même. Qu'est-ce qu'un modèle ? Awaker 1.0, un grand modèle multimodal qui vient d'apparaître sur le Forum Zhongguancun. Qui est l'équipe ? Moteur Sophon. Fondé par Gao Yizhao, doctorant à la Hillhouse School of Artificial Intelligence de l’Université Renmin.
 Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
La dernière vidéo du robot Optimus de Tesla est sortie, et il peut déjà fonctionner en usine. À vitesse normale, il trie les batteries (les batteries 4680 de Tesla) comme ceci : Le responsable a également publié à quoi cela ressemble à une vitesse 20 fois supérieure - sur un petit "poste de travail", en sélectionnant et en sélectionnant et en sélectionnant : Cette fois, il est publié L'un des points forts de la vidéo est qu'Optimus réalise ce travail en usine, de manière totalement autonome, sans intervention humaine tout au long du processus. Et du point de vue d'Optimus, il peut également récupérer et placer la batterie tordue, en se concentrant sur la correction automatique des erreurs : concernant la main d'Optimus, le scientifique de NVIDIA Jim Fan a donné une évaluation élevée : la main d'Optimus est l'un des robots à cinq doigts du monde. le plus adroit. Ses mains ne sont pas seulement tactiles
 La version Kuaishou de Sora 'Ke Ling' est ouverte aux tests : génère plus de 120 s de vidéo, comprend mieux la physique et peut modéliser avec précision des mouvements complexes
Jun 11, 2024 am 09:51 AM
La version Kuaishou de Sora 'Ke Ling' est ouverte aux tests : génère plus de 120 s de vidéo, comprend mieux la physique et peut modéliser avec précision des mouvements complexes
Jun 11, 2024 am 09:51 AM
Quoi? Zootopie est-elle concrétisée par l’IA domestique ? Avec la vidéo est exposé un nouveau modèle de génération vidéo domestique à grande échelle appelé « Keling ». Sora utilise une voie technique similaire et combine un certain nombre d'innovations technologiques auto-développées pour produire des vidéos qui comportent non seulement des mouvements larges et raisonnables, mais qui simulent également les caractéristiques du monde physique et possèdent de fortes capacités de combinaison conceptuelle et d'imagination. Selon les données, Keling prend en charge la génération de vidéos ultra-longues allant jusqu'à 2 minutes à 30 ips, avec des résolutions allant jusqu'à 1080p, et prend en charge plusieurs formats d'image. Un autre point important est que Keling n'est pas une démo ou une démonstration de résultats vidéo publiée par le laboratoire, mais une application au niveau produit lancée par Kuaishou, un acteur leader dans le domaine de la vidéo courte. De plus, l'objectif principal est d'être pragmatique, de ne pas faire de chèques en blanc et de se mettre en ligne dès sa sortie. Le grand modèle de Ke Ling est déjà sorti à Kuaiying.
