

La conférence Microsoft Ignite 2023 commence aujourd'hui. NVIDIA a lancé un service d'atelier d'IA basé sur le cloud intelligent de Microsoft Microsoft Azure, visant à aider les entreprises et les startups à développer, optimiser et déployer des applications d'IA génératives personnalisées sur la plateforme Azure
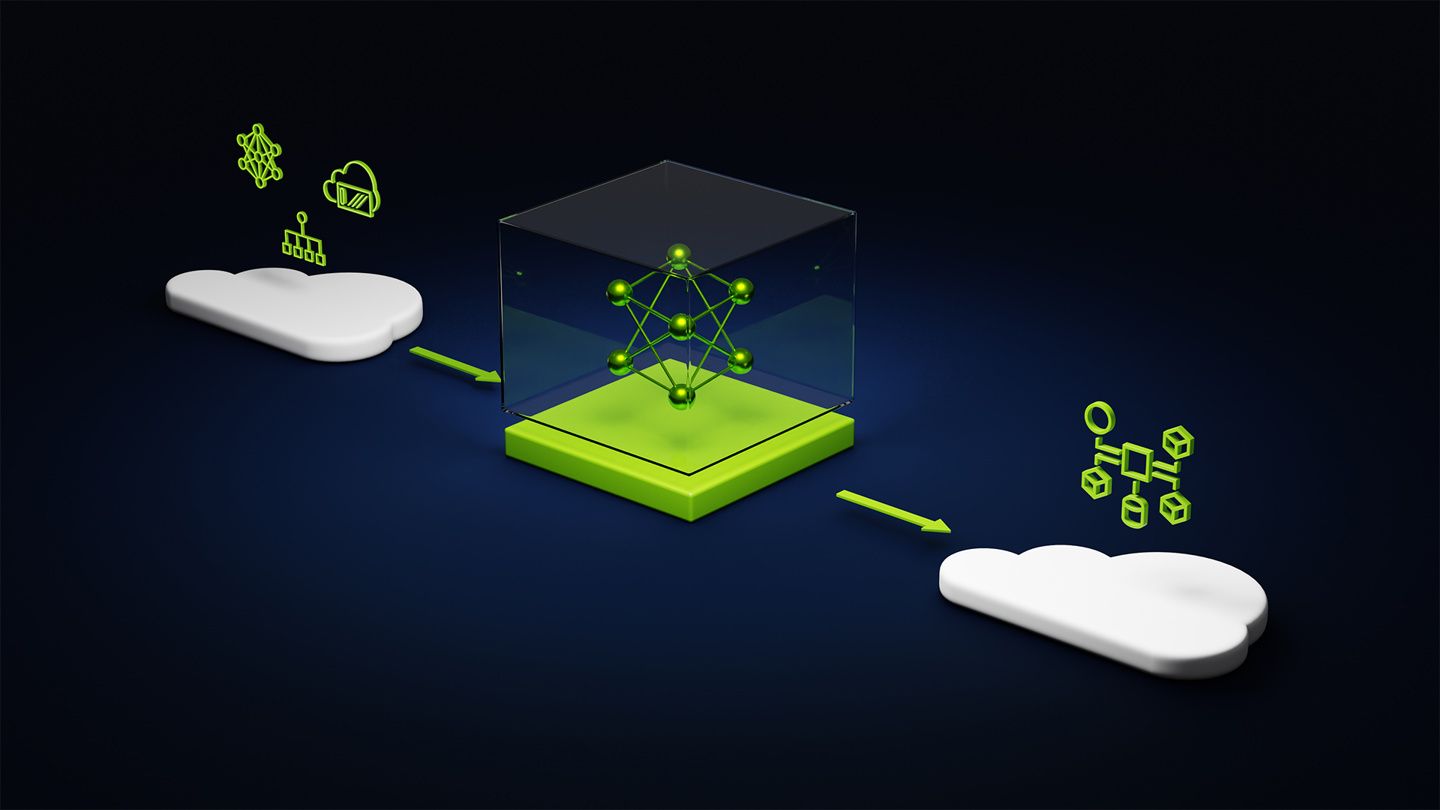
Selon les rapports, ce service de fonderie NVIDIA AI intègre trois éléments majeurs : les modèles NVIDIA AI Foundation, le framework et les outils NVIDIA NeMo et les services de supercalcul IA cloud NVIDIA DGX.
NVIDIA a déclaré pouvoir fournir aux entreprises des solutions de bout en bout pour créer des modèles d'intelligence artificielle générative personnalisés. En outre, ils aident également les entreprises à utiliser le logiciel NVIDIA AI Enterprise pour déployer ces modèles personnalisés afin de prendre en charge les applications d'intelligence artificielle générative, notamment la recherche intelligente, la synthèse et la génération de contenu. Actuellement, trois fournisseurs majeurs, SAP SE, Amdocs et Getty Images, ont pris le relais. le leader dans son utilisation. Utilisez ce service pour créer son modèle d’IA personnalisé.
NVIDIA a également annoncé quelques mises à jour. Tout d’abord, ils mettront à jour TensorRT-LLM pour prendre en charge l’API Chat d’OpenAI et améliorer les capacités DirectML. Ces améliorations amélioreront les performances des modèles d'IA tels que Llama 2 et Stable Diffusion. Des informations plus détaillées peuvent être trouvées dans les rapports précédents sur ce site
Lecture connexe :
"NVIDIA présente en avant-première la nouvelle version de TensorRT-LLM : la capacité d'inférence augmente 5 fois, les cartes graphiques de plus de 8 Go peuvent fonctionner localement, prend en charge l'API Chat d'OpenAI"
Déclaration publicitaire : les liens de saut externes (y compris, mais sans s'y limiter, les hyperliens, les codes QR, les mots de passe, etc.) contenus dans l'article sont utilisés pour transmettre plus d'informations et gagner du temps de sélection. Les résultats sont à titre de référence uniquement. contenir cette déclaration.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Que sont les logiciels d'accélération cdn ?
Que sont les logiciels d'accélération cdn ?
 Solution à l'échec de la connexion entre wsus et le serveur Microsoft
Solution à l'échec de la connexion entre wsus et le serveur Microsoft
 Avantages du système de contrôle PLC
Avantages du système de contrôle PLC
 Introduction aux périphériques de sortie dans les ordinateurs
Introduction aux périphériques de sortie dans les ordinateurs
 bloc de visualisation;
bloc de visualisation;
 supprimer un élément du tableau js
supprimer un élément du tableau js
 Introduction à la méthode d'imbrication des répéteurs
Introduction à la méthode d'imbrication des répéteurs
 Excel génère un code QR
Excel génère un code QR








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



