
 Périphériques technologiques
IA
L'équipe de recherche de l'Académie chinoise des sciences a publié deux articles importants : la publication du premier modèle à grande échelle des bases de la vie entre les espèces et la publication d'un nouveau modèle d'IA pour la prédiction du devenir des cellules.
Périphériques technologiques
IA
L'équipe de recherche de l'Académie chinoise des sciences a publié deux articles importants : la publication du premier modèle à grande échelle des bases de la vie entre les espèces et la publication d'un nouveau modèle d'IA pour la prédiction du devenir des cellules.
L'équipe de recherche de l'Académie chinoise des sciences a publié deux articles importants : la publication du premier modèle à grande échelle des bases de la vie entre les espèces et la publication d'un nouveau modèle d'IA pour la prédiction du devenir des cellules.

Auteur | Équipe de recherche multidisciplinaire, Académie chinoise des sciences
Éditeur | ScienceAI
Le projet du génome humain, connu comme l'un des trois projets scientifiques majeurs de l'humanité au 20e siècle, a lancé une analyse approfondie des mystères de la vie. Les processus vitaux étant multidimensionnels et hautement dynamiques, il est difficile pour les méthodes de recherche expérimentale traditionnelles de déchiffrer systématiquement et avec précision les lois communes sous-jacentes du code génétique. Il est urgent d’utiliser une technologie informatique puissante pour réaliser une modélisation des représentations et la découverte de connaissances génétiques. données.
Actuellement, la technologie de l'intelligence artificielle basée sur de grands modèles a déclenché des révolutions dans des domaines tels que la vision par ordinateur et la compréhension du langage naturel, démontrant une compréhension approfondie des données et des connaissances. Elle devrait être appliquée dans le domaine de la recherche en sciences de la vie. pour déchiffrer systématiquement et avec précision les gènes. Les lois communes sous-jacentes de la cryptographie
Récemment, le « Consortium Xcompass », composé d'une équipe de recherche interdisciplinaire multidisciplinaire de l'Académie chinoise des sciences, a réalisé avec succès des percées importantes dans l'intelligence artificielle renforçant la recherche en sciences de la vie. construire le premier grand modèle de base de sciences de la vie inter-espèces au monde - GeneCompass. Ce modèle intègre les données du transcriptome de plus de 126 millions de cellules uniques d'humains et de souris, et intègre quatre types de connaissances antérieures, notamment les séquences promotrices et les relations de co-expression des gènes. Le nombre de paramètres de base du modèle atteint 130 millions, réalisant le contrôle des gènes. L'apprentissage panoramique et la compréhension des lois de régulation soutiennent simultanément la prédiction des changements d'état cellulaire et l'analyse précise de divers processus vitaux, démontrant le grand potentiel de l'intelligence artificielle pour renforcer la recherche en sciences de la vie.
L'étude s'intitule « GeneCompass : Déchiffrer les mécanismes universels de régulation des gènes avec un modèle de fondation inter-espèces fondé sur la connaissance » et a été publiée sur bioRxiv.

Lien papier : https://www.biorxiv.org/content/10.1101/2023.09.26.559542v1
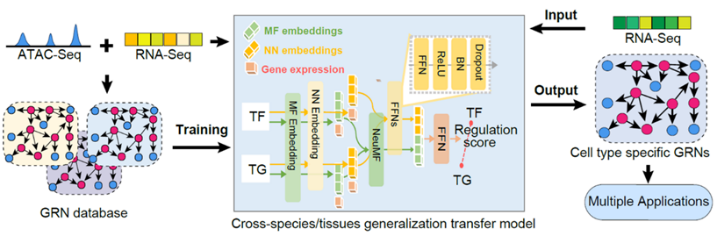
De plus, l'équipe a également publié simultanément un modèle de génération de réseau de régulation génique basé sur l'apprentissage par transfert, CellPolaris , ce modèle peut identifier avec précision les facteurs fondamentaux de la conversion du destin cellulaire et a la capacité de simuler les perturbations des facteurs de transcription.
L'étude s'intitule « CellPolaris : Decoding Cell Fate through Generalization Transfer Learning of Gene Regulatory Networks » et a été publiée sur bioRxiv.

GeneCompass : Le premier modèle à grande échelle des bases de la vie à travers les espèces
Les individus mammifères contiennent généralement des dizaines de milliers à des dizaines de milliards de cellules. Bien que toutes les cellules d’un individu contiennent la même séquence génétique, le destin et la fonction de chaque cellule varient considérablement en raison de son contexte spatio-temporel unique. Ces processus vitaux sophistiqués sont contrôlés par des systèmes complexes de régulation de l'expression des gènes.
Afin d'améliorer notre compréhension des lois essentielles de la vie et d'innover dans le diagnostic et le traitement de diverses maladies majeures, il est nécessaire de mener une exploration approfondie de la régulation des gènes. mécanismes omniprésents dans la vie. Cependant, les méthodes de recherche traditionnelles ont un faible débit et sont limitées à un seul organisme modèle, et ne peuvent pas révéler des mécanismes complexes de régulation des gènes. Ces dernières années, les percées dans la technologie omique unicellulaire ont produit un grand nombre de données sur le profil d’expression génique de différents types de gènes. les cellules, fournissant une base pour l’interprétation des gènes. -Les interactions génétiques fournissent la base des données. Dans le même temps, le développement de l’apprentissage profond, en particulier l’émergence de grands modèles génératifs, peut résumer de manière exhaustive les mécanismes de régulation non linéaires de quantités massives de données dans différents états cellulaires, ouvrant ainsi des opportunités sans précédent à la recherche en sciences de la vie.
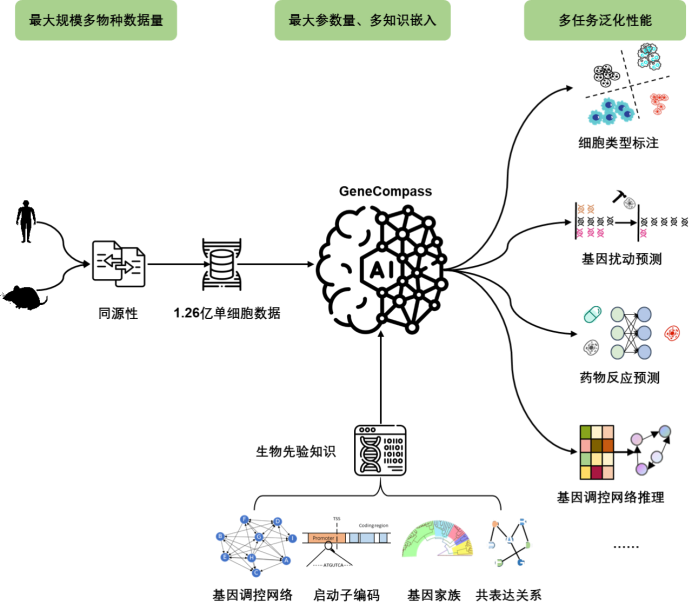
Un grand modèle des bases de la vie à travers les espèces, comprenant 120 millions de nombres de cellules et 130 millions de paramètresActuellement, l'échelle des données de transcriptome unicellulaire obtenues sur une seule espèce dans le monde n'est que de plusieurs dizaines de millions. , il est difficile de prendre pleinement en charge la formation de grands modèles de modèles de vie de base utilisés pour analyser des processus vitaux complexes.
L'équipe a collecté des données open source sur le transcriptome unicellulaire de différentes espèces et, après des processus de prétraitement tels que le criblage, le nettoyage et la normalisation, a établi les plus grandes données d'entraînement connues de haute qualité, comprenant plus de 126 millions de cellules chez la souris et l'homme. . Collection scCompass-126M ; adopte une architecture d'apprentissage en profondeur basée sur le mécanisme d'auto-attention du Transformer, qui peut capturer la corrélation dynamique à long terme entre différents gènes dans différents milieux cellulaires, et la taille des paramètres du modèle atteint 130 millions. Afin de parvenir à une caractérisation à haute résolution des processus vitaux, GeneCompass code pour la première fois les numéros de gènes et les niveaux d'expression, permettant une extraction efficace et sensible des corrélations entre les gènes. Cela permet à GeneCompass de fournir une analyse plus précise des interactions gène-gène dans diverses conditions spécifiques, telles que les types de cellules et les états de perturbation.
L'intégration de connaissances préalables pendant la pré-formation peut améliorer efficacement les performances du modèle
Le modèle ajoute des êtres humains en intégrant efficacement quatre connaissances biologiques préalables : la séquence du promoteur, le réseau de régulation des gènes connu, les informations sur la famille de gènes et la relation de co-expression des gènes. Informations d'annotation le codage améliore la compréhension des corrélations de caractéristiques complexes entre les données biologiques. Grâce à la formation et à l'intégration des données et des connaissances préalables sur différentes espèces, GeneCompass devrait améliorer l'efficacité et la précision de la recherche biologique traditionnelle et ouvrir de nouveaux points d'entrée à des problèmes complexes des sciences de la vie qui ne peuvent pas encore être résolus.
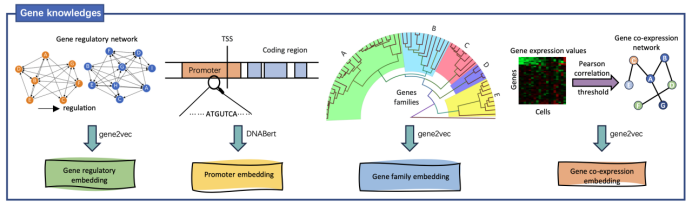
L'effet d'échelle incite l'entraînement du modèle à capturer les lois conservatrices de l'évolution biologique
L'équipe a constaté que le modèle pré-entraîné sur des données inter-espèces à grande échelle était conforme à la loi d'échelle sur la sous-tâche d'une seule espèce : c'est-à-dire que plus les données de pré-entraînement multi-espèces à grande échelle peuvent produire de meilleures représentations pré-entraînées et améliorer encore les performances sur les tâches en aval. Cette découverte montre qu'il existe des modèles de régulation génétique conservés entre les espèces et que ces modèles peuvent être appris et compris par des modèles pré-entraînés. Dans le même temps, cela signifie également qu'avec l'expansion des espèces et des données, les performances du modèle devraient continuer à s'améliorer
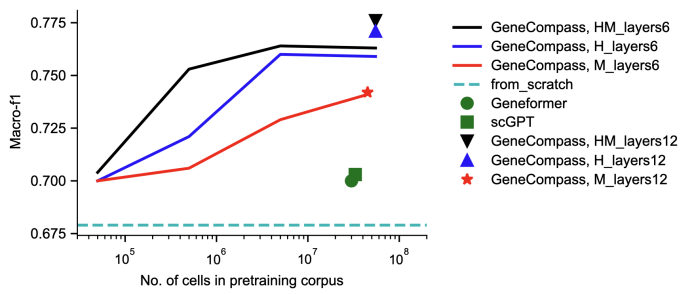
Avantages en termes de performances multitâches démontrer les puissantes capacités de généralisation des grands modèles de base
En tant que plus grand modèle de vie de base pré-entraîné inter-espèces avec intégration de connaissances à ce jour, GeneCompass peut mettre en œuvre l'apprentissage par transfert pour plusieurs tâches en aval inter-espèces et peut être utilisé dans le type de cellule annotation, prédiction quantitative des perturbations génétiques, analyse de sensibilité aux médicaments, etc. En termes de performances, elle atteint de meilleures performances que les méthodes existantes. Cela démontre pleinement les avantages stratégiques de la pré-formation basée sur des mégadonnées multi-espèces non étiquetées, puis de l'utilisation de différentes données de sous-tâches pour affiner le modèle. Elle devrait devenir une solution universelle pour analyser et prédire divers problèmes biologiques liés aux gènes. -caractéristiques des cellules.
Polarisation cellulaire : l'apprentissage par transfert décode les réseaux de régulation génique et prédit les changements du destin cellulaire
Utilisation de l'apprentissage par transfert pour générer des réseaux de régulation génique spécifiques aux cellules
L'équipe a également développé un ensemble d'apprentissage par transfert généralisé basé sur Le réseau de régulation génétique construit un modèle d’IA appelé CellPolaris. Le modèle trie d'abord des centaines d'ensembles de données d'accessibilité du transcriptome et de la chromatine dans des scénarios cellulaires correspondants pour créer un réseau de régulation génique de haute qualité, puis utilise le modèle d'apprentissage par transfert généralisé pour générer davantage de gènes dans des scénarios cellulaires en utilisant uniquement les données du transcriptome. . Ensuite, en utilisant le réseau de régulation génique de haute confiance généré, nous avons développé un outil pour identifier les principaux facteurs de transcription pour les transitions du destin cellulaire et un outil de simulation de perturbation des facteurs de transcription basé sur un modèle graphique probabiliste. Ce modèle peut identifier efficacement les facteurs fondamentaux de la conversion du destin cellulaire et réaliser la simulation de la perturbation des facteurs de transcription. Il présente une valeur d'application importante dans l'analyse des mécanismes de régulation des gènes et la découverte de gènes responsables de maladies.
Le réseau de régulation génique généré par le modèle CellPolaris fournit une richesse de molécules Les informations sur les interactions peuvent être utilisées comme connaissances préalables pour les grands modèles d’apprentissage profond. Les vecteurs d'intégration de faible dimension générés par les grands modèles d'apprentissage profond fourniront des informations importantes pour l'analyse des mécanismes de régulation des gènes et la découverte de gènes responsables de maladies.
Les deux études ci-dessus ont été réalisées par l'équipe "Compass Alliance". L'équipe "Compass Alliance" est actuellement principalement composée du Centre commun d'information sur les réseaux informatiques de l'Institut de zoologie, de l'Académie chinoise des sciences, de l'Institut d'automatisation, de l'Institut de zoologie. Institute of Computing Technology, Institute of Mathematics and Systems Science, etc. , l'objectif de l'alliance est d'établir un nouveau paradigme de recherche en sciences de la vie piloté par l'intelligence numérique et d'analyser les lois essentielles de la vie.
Intelligence Artificielle × [Biologie Neurosciences Mathématiques Physique Chimie Matériaux]
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Un didacticiel sur le modèle de diffusion qui vaut votre temps, de l'Université Purdue
Apr 07, 2024 am 09:01 AM
Un didacticiel sur le modèle de diffusion qui vaut votre temps, de l'Université Purdue
Apr 07, 2024 am 09:01 AM
La diffusion permet non seulement de mieux imiter, mais aussi de « créer ». Le modèle de diffusion (DiffusionModel) est un modèle de génération d'images. Par rapport aux algorithmes bien connus tels que GAN et VAE dans le domaine de l’IA, le modèle de diffusion adopte une approche différente. Son idée principale est un processus consistant à ajouter d’abord du bruit à l’image, puis à la débruiter progressivement. Comment débruiter et restaurer l’image originale est la partie centrale de l’algorithme. L'algorithme final est capable de générer une image à partir d'une image bruitée aléatoirement. Ces dernières années, la croissance phénoménale de l’IA générative a permis de nombreuses applications passionnantes dans la génération de texte en image, la génération de vidéos, et bien plus encore. Le principe de base de ces outils génératifs est le concept de diffusion, un mécanisme d'échantillonnage spécial qui surmonte les limites des méthodes précédentes.
 Générez du PPT en un seul clic ! Kimi : Que les « travailleurs migrants PPT » deviennent d'abord populaires
Aug 01, 2024 pm 03:28 PM
Générez du PPT en un seul clic ! Kimi : Que les « travailleurs migrants PPT » deviennent d'abord populaires
Aug 01, 2024 pm 03:28 PM
Kimi : En une seule phrase, un PPT est prêt en seulement dix secondes. PPT est tellement ennuyeux ! Pour tenir une réunion, vous devez avoir un PPT ; pour rédiger un rapport hebdomadaire, vous devez avoir un PPT ; pour solliciter des investissements, vous devez présenter un PPT ; même pour accuser quelqu'un de tricherie, vous devez envoyer un PPT ; L'université ressemble plus à une spécialisation PPT. Vous regardez le PPT en classe et faites le PPT après les cours. Peut-être que lorsque Dennis Austin a inventé le PPT il y a 37 ans, il ne s'attendait pas à ce qu'un jour le PPT devienne aussi répandu. Parler de notre dure expérience de création de PPT nous fait monter les larmes aux yeux. "Il m'a fallu trois mois pour réaliser un PPT de plus de 20 pages, et je l'ai révisé des dizaines de fois. J'avais envie de vomir quand j'ai vu le PPT." "À mon apogée, je faisais cinq PPT par jour, et même ma respiration." était PPT." Si vous avez une réunion impromptue, vous devriez le faire
 Tous les prix CVPR 2024 annoncés ! Près de 10 000 personnes ont assisté à la conférence hors ligne et un chercheur chinois de Google a remporté le prix du meilleur article.
Jun 20, 2024 pm 05:43 PM
Tous les prix CVPR 2024 annoncés ! Près de 10 000 personnes ont assisté à la conférence hors ligne et un chercheur chinois de Google a remporté le prix du meilleur article.
Jun 20, 2024 pm 05:43 PM
Tôt le matin du 20 juin, heure de Pékin, CVPR2024, la plus grande conférence internationale sur la vision par ordinateur qui s'est tenue à Seattle, a officiellement annoncé le meilleur article et d'autres récompenses. Cette année, un total de 10 articles ont remporté des prix, dont 2 meilleurs articles et 2 meilleurs articles étudiants. De plus, il y a eu 2 nominations pour les meilleurs articles et 4 nominations pour les meilleurs articles étudiants. La conférence la plus importante dans le domaine de la vision par ordinateur (CV) est la CVPR, qui attire chaque année un grand nombre d'instituts de recherche et d'universités. Selon les statistiques, un total de 11 532 articles ont été soumis cette année, dont 2 719 ont été acceptés, avec un taux d'acceptation de 23,6 %. Selon l'analyse statistique des données CVPR2024 du Georgia Institute of Technology, du point de vue des sujets de recherche, le plus grand nombre d'articles est la synthèse et la génération d'images et de vidéos (Imageandvideosyn
 Du bare metal au grand modèle avec 70 milliards de paramètres, voici un tutoriel et des scripts prêts à l'emploi
Jul 24, 2024 pm 08:13 PM
Du bare metal au grand modèle avec 70 milliards de paramètres, voici un tutoriel et des scripts prêts à l'emploi
Jul 24, 2024 pm 08:13 PM
Nous savons que le LLM est formé sur des clusters informatiques à grande échelle utilisant des données massives. Ce site a présenté de nombreuses méthodes et technologies utilisées pour aider et améliorer le processus de formation LLM. Aujourd'hui, ce que nous souhaitons partager est un article qui approfondit la technologie sous-jacente et présente comment transformer un ensemble de « bare metals » sans même un système d'exploitation en un cluster informatique pour la formation LLM. Cet article provient d'Imbue, une startup d'IA qui s'efforce d'atteindre une intelligence générale en comprenant comment les machines pensent. Bien sûr, transformer un tas de « bare metal » sans système d'exploitation en un cluster informatique pour la formation LLM n'est pas un processus facile, plein d'exploration et d'essais et d'erreurs, mais Imbue a finalement réussi à former un LLM avec 70 milliards de paramètres et dans. le processus s'accumule
 Cinq logiciels de programmation pour débuter l'apprentissage du langage C
Feb 19, 2024 pm 04:51 PM
Cinq logiciels de programmation pour débuter l'apprentissage du langage C
Feb 19, 2024 pm 04:51 PM
En tant que langage de programmation largement utilisé, le langage C est l'un des langages de base qui doivent être appris pour ceux qui souhaitent se lancer dans la programmation informatique. Cependant, pour les débutants, l’apprentissage d’un nouveau langage de programmation peut s’avérer quelque peu difficile, notamment en raison du manque d’outils d’apprentissage et de matériel pédagogique pertinents. Dans cet article, je présenterai cinq logiciels de programmation pour aider les débutants à démarrer avec le langage C et vous aider à démarrer rapidement. Le premier logiciel de programmation était Code :: Blocks. Code::Blocks est un environnement de développement intégré (IDE) gratuit et open source pour
 Guide d'installation de PyCharm Community Edition : maîtrisez rapidement toutes les étapes
Jan 27, 2024 am 09:10 AM
Guide d'installation de PyCharm Community Edition : maîtrisez rapidement toutes les étapes
Jan 27, 2024 am 09:10 AM
Démarrage rapide avec PyCharm Community Edition : Tutoriel d'installation détaillé Analyse complète Introduction : PyCharm est un puissant environnement de développement intégré (IDE) Python qui fournit un ensemble complet d'outils pour aider les développeurs à écrire du code Python plus efficacement. Cet article présentera en détail comment installer PyCharm Community Edition et fournira des exemples de code spécifiques pour aider les débutants à démarrer rapidement. Étape 1 : Téléchargez et installez PyCharm Community Edition Pour utiliser PyCharm, vous devez d'abord le télécharger depuis son site officiel
 A lire absolument pour les débutants en technique : Analyse des niveaux de difficulté du langage C et Python
Mar 22, 2024 am 10:21 AM
A lire absolument pour les débutants en technique : Analyse des niveaux de difficulté du langage C et Python
Mar 22, 2024 am 10:21 AM
Titre : Une lecture incontournable pour les débutants en technique : Analyse des difficultés du langage C et de Python, nécessitant des exemples de code spécifiques. À l'ère numérique d'aujourd'hui, la technologie de programmation est devenue une capacité de plus en plus importante. Que vous souhaitiez travailler dans des domaines tels que le développement de logiciels, l'analyse de données, l'intelligence artificielle ou simplement apprendre la programmation par intérêt, choisir un langage de programmation adapté est la première étape. Parmi les nombreux langages de programmation, le langage C et Python sont deux langages de programmation largement utilisés, chacun ayant ses propres caractéristiques. Cet article analysera les niveaux de difficulté du langage C et Python
 L'IA utilisée | L'IA a créé un vlog sur la vie d'une fille vivant seule, qui a reçu des dizaines de milliers de likes en 3 jours
Aug 07, 2024 pm 10:53 PM
L'IA utilisée | L'IA a créé un vlog sur la vie d'une fille vivant seule, qui a reçu des dizaines de milliers de likes en 3 jours
Aug 07, 2024 pm 10:53 PM
Rédacteur du Machine Power Report : Yang Wen La vague d’intelligence artificielle représentée par les grands modèles et l’AIGC a discrètement changé notre façon de vivre et de travailler, mais la plupart des gens ne savent toujours pas comment l’utiliser. C'est pourquoi nous avons lancé la rubrique « AI in Use » pour présenter en détail comment utiliser l'IA à travers des cas d'utilisation de l'intelligence artificielle intuitifs, intéressants et concis et stimuler la réflexion de chacun. Nous invitons également les lecteurs à soumettre des cas d'utilisation innovants et pratiques. Lien vidéo : https://mp.weixin.qq.com/s/2hX_i7li3RqdE4u016yGhQ Récemment, le vlog de la vie d'une fille vivant seule est devenu populaire sur Xiaohongshu. Une animation de style illustration, associée à quelques mots de guérison, peut être facilement récupérée en quelques jours seulement.
