
 Périphériques technologiques
IA
Annonce du nouveau brevet de Microsoft : utiliser l'apprentissage automatique pour créer des avatars réalistes qui « rougissent »
Périphériques technologiques
IA
Annonce du nouveau brevet de Microsoft : utiliser l'apprentissage automatique pour créer des avatars réalistes qui « rougissent »
Annonce du nouveau brevet de Microsoft : utiliser l'apprentissage automatique pour créer des avatars réalistes qui « rougissent »


16 novembre, un nouveau brevet de Microsoft a été divulgué mardi sur le site Web de l'Office américain des brevets et des marques. Il s'agit d'un nouveau brevet de modèle d'apprentissage automatique qui peut créer des images « plus vitales » pour les utilisateurs.
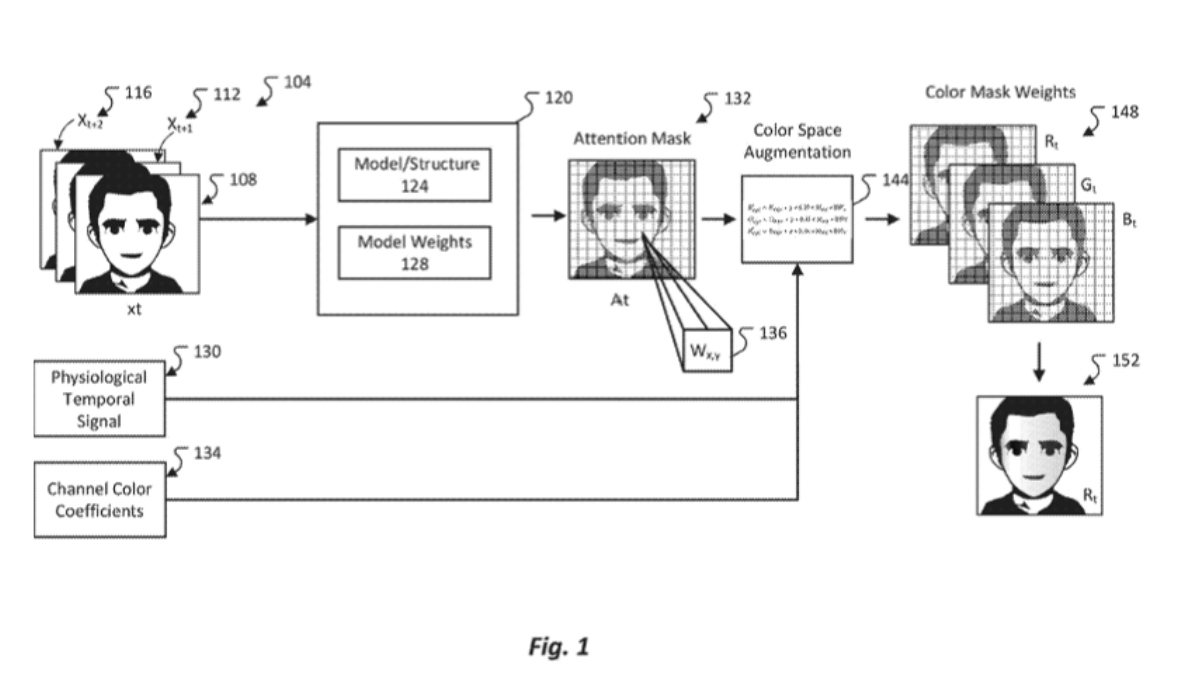
Selon les rapports, grâce au nouveau modèle d'apprentissage automatique, l'avatar ou la photo peut être ajusté pour les détails afin de rendre la photo plus naturelle. Microsoft utilisera des réseaux d'attention convolutionnelle pour améliorer la précision de la capture des expressions faciales et ajuster les détails de l'image en fonction de signaux physiologiques tels que la fréquence cardiaque, comme le flux sanguin ou le rougissement. Microsoft décrit en outre dans ce document de brevet que
Cet avatar « ultra-réaliste » peut non seulement simuler des clignements ou l'état de la tête, mais également simuler des changements subtils tels que le flux sanguin, la respiration ou des réactions émotionnelles.
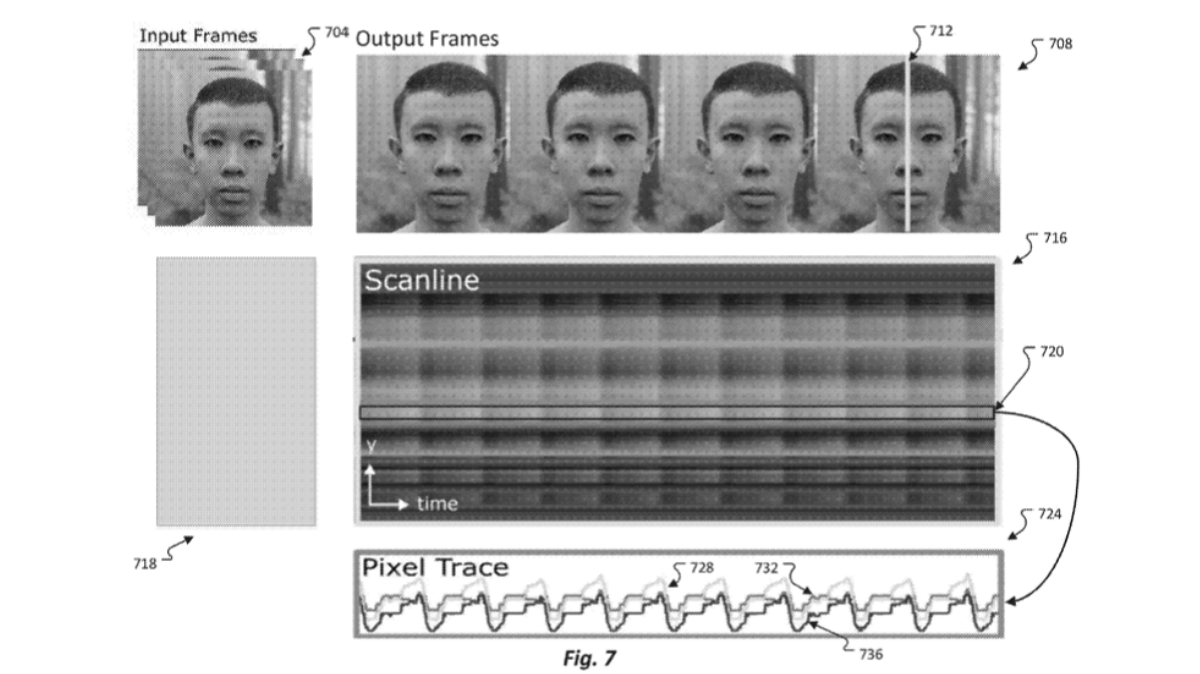 Les médias étrangers mspoweruser ont analysé que ce brevet pourrait être mis en œuvre dans des domaines tels que la création de personnages de jeux vidéo. Bien entendu,
Les médias étrangers mspoweruser ont analysé que ce brevet pourrait être mis en œuvre dans des domaines tels que la création de personnages de jeux vidéo. Bien entendu,
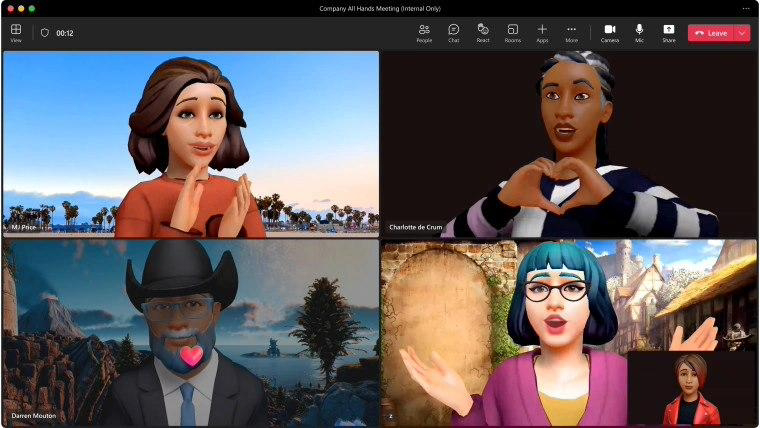
. Si ce brevet est finalement approuvé, il devrait « changer les règles du jeu » et changer complètement le regard des gens sur les avatars. En référence aux rapports précédents sur ce site, Microsoft a annoncé l'introduction d'une plate-forme Mesh pour l'application Microsoft Teams lors de la conférence des développeurs Build 2023, et les participants à la conférence peuvent utiliser des avatars 3D.
Microsoft avait déclaré à l'époque que
Les utilisateurs des applications Windows et macOS Teams pouvaient créer des avatars 3D d'eux-mêmeset utiliser ces avatars 3D lors de réunions sans caméra ni webcam.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Cet article vous amènera à comprendre SHAP : explication du modèle pour l'apprentissage automatique
Jun 01, 2024 am 10:58 AM
Cet article vous amènera à comprendre SHAP : explication du modèle pour l'apprentissage automatique
Jun 01, 2024 am 10:58 AM
Dans les domaines de l’apprentissage automatique et de la science des données, l’interprétabilité des modèles a toujours été au centre des préoccupations des chercheurs et des praticiens. Avec l'application généralisée de modèles complexes tels que l'apprentissage profond et les méthodes d'ensemble, la compréhension du processus décisionnel du modèle est devenue particulièrement importante. Explainable AI|XAI contribue à renforcer la confiance dans les modèles d'apprentissage automatique en augmentant la transparence du modèle. L'amélioration de la transparence des modèles peut être obtenue grâce à des méthodes telles que l'utilisation généralisée de plusieurs modèles complexes, ainsi que les processus décisionnels utilisés pour expliquer les modèles. Ces méthodes incluent l'analyse de l'importance des caractéristiques, l'estimation de l'intervalle de prédiction du modèle, les algorithmes d'interprétabilité locale, etc. L'analyse de l'importance des fonctionnalités peut expliquer le processus de prise de décision du modèle en évaluant le degré d'influence du modèle sur les fonctionnalités d'entrée. Estimation de l’intervalle de prédiction du modèle
 Implémentation d'algorithmes d'apprentissage automatique en C++ : défis et solutions courants
Jun 03, 2024 pm 01:25 PM
Implémentation d'algorithmes d'apprentissage automatique en C++ : défis et solutions courants
Jun 03, 2024 pm 01:25 PM
Les défis courants rencontrés par les algorithmes d'apprentissage automatique en C++ incluent la gestion de la mémoire, le multithread, l'optimisation des performances et la maintenabilité. Les solutions incluent l'utilisation de pointeurs intelligents, de bibliothèques de threads modernes, d'instructions SIMD et de bibliothèques tierces, ainsi que le respect des directives de style de codage et l'utilisation d'outils d'automatisation. Des cas pratiques montrent comment utiliser la bibliothèque Eigen pour implémenter des algorithmes de régression linéaire, gérer efficacement la mémoire et utiliser des opérations matricielles hautes performances.
 Microsoft publie la mise à jour cumulative Win11 août : amélioration de la sécurité, optimisation de l'écran de verrouillage, etc.
Aug 14, 2024 am 10:39 AM
Microsoft publie la mise à jour cumulative Win11 août : amélioration de la sécurité, optimisation de l'écran de verrouillage, etc.
Aug 14, 2024 am 10:39 AM
Selon les informations de ce site du 14 août, lors de la journée d'événement Patch Tuesday d'aujourd'hui, Microsoft a publié des mises à jour cumulatives pour les systèmes Windows 11, notamment la mise à jour KB5041585 pour 22H2 et 23H2 et la mise à jour KB5041592 pour 21H2. Après l'installation de l'équipement mentionné ci-dessus avec la mise à jour cumulative d'août, les changements de numéro de version attachés à ce site sont les suivants : Après l'installation de l'équipement 21H2, le numéro de version est passé à Build22000.314722H2. le numéro de version est passé à Build22621.403723H2. Après l'installation de l'équipement, le numéro de version est passé à Build22631.4037. Le contenu principal de la mise à jour KB5041585 pour Windows 1121H2 est le suivant : Amélioration : Amélioré.
 La fenêtre contextuelle plein écran de Microsoft exhorte les utilisateurs de Windows 10 à se dépêcher et à passer à Windows 11
Jun 06, 2024 am 11:35 AM
La fenêtre contextuelle plein écran de Microsoft exhorte les utilisateurs de Windows 10 à se dépêcher et à passer à Windows 11
Jun 06, 2024 am 11:35 AM
Selon l'actualité du 3 juin, Microsoft envoie activement des notifications en plein écran à tous les utilisateurs de Windows 10 pour les encourager à passer au système d'exploitation Windows 11. Ce déplacement concerne les appareils dont les configurations matérielles ne prennent pas en charge le nouveau système. Depuis 2015, Windows 10 occupe près de 70 % des parts de marché, établissant ainsi sa domination en tant que système d'exploitation Windows. Cependant, la part de marché dépasse largement la part de marché de 82 %, et la part de marché dépasse largement celle de Windows 11, qui sortira en 2021. Même si Windows 11 est lancé depuis près de trois ans, sa pénétration sur le marché est encore lente. Microsoft a annoncé qu'il mettrait fin au support technique de Windows 10 après le 14 octobre 2025 afin de se concentrer davantage sur
 Cinq écoles d'apprentissage automatique que vous ne connaissez pas
Jun 05, 2024 pm 08:51 PM
Cinq écoles d'apprentissage automatique que vous ne connaissez pas
Jun 05, 2024 pm 08:51 PM
L'apprentissage automatique est une branche importante de l'intelligence artificielle qui donne aux ordinateurs la possibilité d'apprendre à partir de données et d'améliorer leurs capacités sans être explicitement programmés. L'apprentissage automatique a un large éventail d'applications dans divers domaines, de la reconnaissance d'images et du traitement du langage naturel aux systèmes de recommandation et à la détection des fraudes, et il change notre façon de vivre. Il existe de nombreuses méthodes et théories différentes dans le domaine de l'apprentissage automatique, parmi lesquelles les cinq méthodes les plus influentes sont appelées les « Cinq écoles d'apprentissage automatique ». Les cinq grandes écoles sont l’école symbolique, l’école connexionniste, l’école évolutionniste, l’école bayésienne et l’école analogique. 1. Le symbolisme, également connu sous le nom de symbolisme, met l'accent sur l'utilisation de symboles pour le raisonnement logique et l'expression des connaissances. Cette école de pensée estime que l'apprentissage est un processus de déduction inversée, à travers les connaissances existantes.
 IA explicable : Expliquer les modèles IA/ML complexes
Jun 03, 2024 pm 10:08 PM
IA explicable : Expliquer les modèles IA/ML complexes
Jun 03, 2024 pm 10:08 PM
Traducteur | Revu par Li Rui | Chonglou Les modèles d'intelligence artificielle (IA) et d'apprentissage automatique (ML) deviennent aujourd'hui de plus en plus complexes, et le résultat produit par ces modèles est une boîte noire – impossible à expliquer aux parties prenantes. L'IA explicable (XAI) vise à résoudre ce problème en permettant aux parties prenantes de comprendre comment fonctionnent ces modèles, en s'assurant qu'elles comprennent comment ces modèles prennent réellement des décisions et en garantissant la transparence des systèmes d'IA, la confiance et la responsabilité pour résoudre ce problème. Cet article explore diverses techniques d'intelligence artificielle explicable (XAI) pour illustrer leurs principes sous-jacents. Plusieurs raisons pour lesquelles l’IA explicable est cruciale Confiance et transparence : pour que les systèmes d’IA soient largement acceptés et fiables, les utilisateurs doivent comprendre comment les décisions sont prises
 Flash Attention est-il stable ? Meta et Harvard ont constaté que les écarts de poids de leur modèle fluctuaient de plusieurs ordres de grandeur.
May 30, 2024 pm 01:24 PM
Flash Attention est-il stable ? Meta et Harvard ont constaté que les écarts de poids de leur modèle fluctuaient de plusieurs ordres de grandeur.
May 30, 2024 pm 01:24 PM
MetaFAIR s'est associé à Harvard pour fournir un nouveau cadre de recherche permettant d'optimiser le biais de données généré lors de l'apprentissage automatique à grande échelle. On sait que la formation de grands modèles de langage prend souvent des mois et utilise des centaines, voire des milliers de GPU. En prenant comme exemple le modèle LLaMA270B, sa formation nécessite un total de 1 720 320 heures GPU. La formation de grands modèles présente des défis systémiques uniques en raison de l’ampleur et de la complexité de ces charges de travail. Récemment, de nombreuses institutions ont signalé une instabilité dans le processus de formation lors de la formation des modèles d'IA générative SOTA. Elles apparaissent généralement sous la forme de pics de pertes. Par exemple, le modèle PaLM de Google a connu jusqu'à 20 pics de pertes au cours du processus de formation. Le biais numérique est à l'origine de cette imprécision de la formation,
 Apprentissage automatique en C++ : un guide pour la mise en œuvre d'algorithmes d'apprentissage automatique courants en C++
Jun 03, 2024 pm 07:33 PM
Apprentissage automatique en C++ : un guide pour la mise en œuvre d'algorithmes d'apprentissage automatique courants en C++
Jun 03, 2024 pm 07:33 PM
En C++, la mise en œuvre d'algorithmes d'apprentissage automatique comprend : Régression linéaire : utilisée pour prédire des variables continues. Les étapes comprennent le chargement des données, le calcul des poids et des biais, la mise à jour des paramètres et la prédiction. Régression logistique : utilisée pour prédire des variables discrètes. Le processus est similaire à la régression linéaire, mais utilise la fonction sigmoïde pour la prédiction. Machine à vecteurs de support : un puissant algorithme de classification et de régression qui implique le calcul de vecteurs de support et la prédiction d'étiquettes.
