
 Périphériques technologiques
IA
Le modèle 13B a-t-il l'avantage dans une confrontation complète avec GPT-4 ? Y a-t-il des circonstances inhabituelles derrière cela ?
Périphériques technologiques
IA
Le modèle 13B a-t-il l'avantage dans une confrontation complète avec GPT-4 ? Y a-t-il des circonstances inhabituelles derrière cela ?
Le modèle 13B a-t-il l'avantage dans une confrontation complète avec GPT-4 ? Y a-t-il des circonstances inhabituelles derrière cela ?

Un modèle avec des paramètres 13B peut réellement battre le top GPT-4 ? Comme le montre la figure ci-dessous, afin de garantir la validité des résultats, ce test a également suivi la méthode de débruitage des données d'OpenAI, et aucune preuve de contamination des données n'a été trouvée
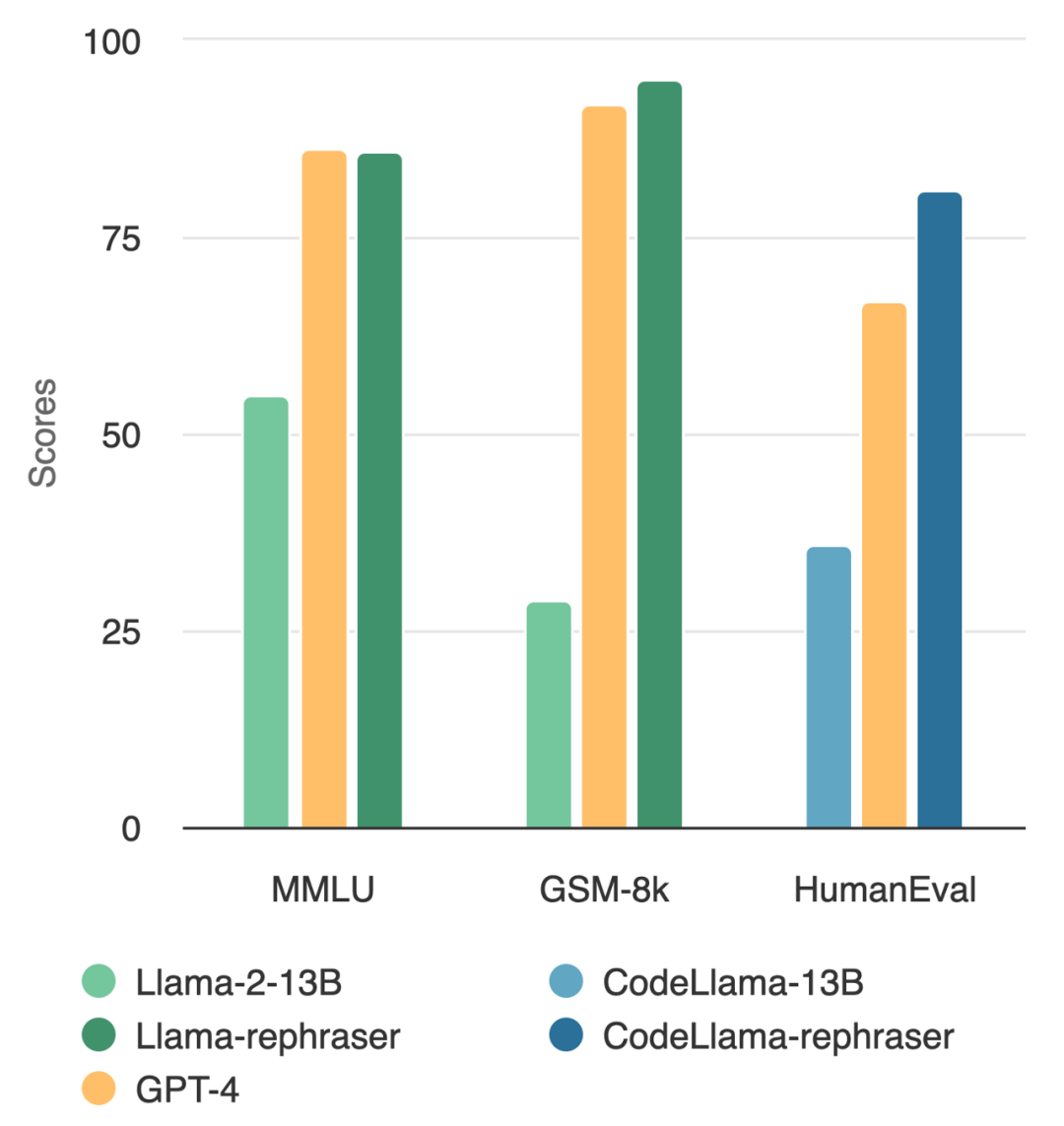
En observant le modèle dans la figure, vous J'ai trouvé que tant que le mot « reformuler » est inclus, les performances du modèle sont relativement élevées
Quelle est l'astuce derrière cela ? Il s'avère que les données sont contaminées, c'est-à-dire que les informations de l'ensemble de test sont divulguées dans l'ensemble de formation, et cette contamination n'est pas facile à détecter. Malgré l’importance cruciale de cette question, comprendre et détecter la contamination reste un casse-tête ouvert et difficile.
À ce stade, la méthode de décontamination la plus couramment utilisée est le chevauchement de n-grammes et la recherche de similarité intégrée : le chevauchement de n-grammes repose sur la correspondance de chaînes pour détecter la contamination et est couramment utilisé dans des modèles tels que GPT-4, PaLM. et méthode Llama-2 ; la recherche de similarité par intégration utilise des intégrations à partir d'un modèle pré-entraîné (par exemple, BERT) pour trouver des exemples similaires et potentiellement contaminés.
Cependant, des recherches de l'UC Berkeley et de l'Université Jiao Tong de Shanghai montrent que de simples modifications des données de test (par exemple, réécriture, traduction) peuvent facilement contourner les méthodes de détection existantes. Ils font référence à ces variations de cas de test sous le nom d'« échantillons reformulés ».
Voici ce qui doit être réécrit dans le test de référence MMLU : les résultats de démonstration de l'échantillon réécrit. Les résultats montrent que le modèle 13B peut atteindre des performances très élevées (MMLU 85.9) si l'ensemble d'apprentissage contient de tels échantillons. Malheureusement, les méthodes de détection existantes telles que le chevauchement des n-grammes et l’intégration de la similarité ne peuvent pas détecter cette contamination. Par exemple, les méthodes de similarité intégrées ont du mal à distinguer les problèmes de reformulation des autres problèmes dans le même sujet

Avec des techniques de reformulation similaires, cet article observe des résultats cohérents sur des benchmarks de codage et de mathématiques largement utilisés, tels que HumanEval et GSM-8K. (montré sur l'image au début de l'article). Par conséquent, être capable de détecter un tel contenu qui doit être réécrit : des échantillons réécrits devient crucial.
Voyons ensuite comment cette étude a été menée.

- Adresse papier : https://arxiv.org/pdf/2311.04850.pdf
- Adresse du projet : https://github.com/lm-sys/llm -decontaminator#detect
Paper introduction
Avec le développement rapide des grands modèles (LLM), les gens accordent de plus en plus d'attention au problème de la pollution des ensembles de test. De nombreuses personnes ont exprimé des inquiétudes quant à la crédibilité des références publiques
Pour résoudre ce problème, certaines personnes utilisent des méthodes de décontamination traditionnelles, telles que la correspondance de chaînes (telles que le chevauchement n-grammes), pour supprimer les données de référence. Cependant, ces opérations sont loin d'être suffisantes, car ces mesures de nettoyage peuvent être facilement contournées en apportant simplement quelques modifications simples aux données de test (par exemple, réécriture, traduction)
Si ces modifications des données de test ne sont pas éliminées, 13B Ce qui est plus important, c'est que le modèle dépasse facilement le test de référence et atteint des performances comparables à celles de GPT-4. Les chercheurs ont vérifié ces observations dans des tests de référence tels que MMLU, GSK8k et HumanEval
Dans le même temps, afin de faire face à ces risques croissants, cet article propose également une méthode de décontamination plus puissante basée sur LLM, le décontaminateur LLM, et son application. aux ensembles de données populaires de pré-formation et de réglage fin, les résultats montrent que la méthode LLM proposée dans cet article est nettement meilleure que les méthodes existantes pour supprimer les échantillons réécrits.
Cette approche a également révélé un chevauchement de tests jusqu'alors inconnu. Par exemple, dans les ensembles de pré-formation tels que RedPajamaData-1T et StarCoder-Data, nous trouvons un chevauchement de 8 à 18 % avec le benchmark HumanEval. De plus, cet article a également constaté cette contamination dans l’ensemble de données synthétiques généré par GPT-3.5/4, ce qui illustre également le risque potentiel de contamination accidentelle dans le domaine de l’IA.
Nous espérons qu'à travers cet article, nous appellerons la communauté à adopter une méthode de purification plus puissante lors de l'utilisation de benchmarks publics et à développer activement de nouveaux cas de tests ponctuels pour évaluer avec précision le modèle
Ce qui doit être réécrit est : réécrire l'échantillon
L'objectif de cet article est de déterminer si un simple changement dans l'inclusion de l'ensemble de test dans l'ensemble de formation affectera les performances de référence finales, et appelle ce changement dans le scénario de test "ce qui doit être réécrit est : réécrire l'échantillon". Divers domaines du référentiel, notamment les mathématiques, les connaissances et le codage, ont été pris en compte dans les expériences. L'exemple 1 est le contenu du GSM-8k qui doit être réécrit : un échantillon réécrit dans lequel un chevauchement de 10 grammes ne peut pas être détecté et le texte modifié conserve la même sémantique que le texte original.

Il existe de légères différences dans la technologie de réécriture pour différentes formes de contamination de base. Dans le test de référence basé sur du texte, cet article réécrit les cas de test en réorganisant l'ordre des mots ou en utilisant la substitution de synonymes pour atteindre l'objectif de ne pas changer la sémantique. Dans le test de référence basé sur le code, cet article est réécrit en modifiant le style de codage, la méthode de dénomination, etc. Comme indiqué ci-dessous, un algorithme simple est proposé dans l'algorithme 1 pour l'ensemble de test donné. Cette méthode peut aider les échantillons testés à échapper à la détection.
 Ensuite, cet article propose une nouvelle méthode de détection de contamination qui peut supprimer avec précision le contenu qui doit être réécrit de l'ensemble de données par rapport à la ligne de base : les échantillons réécrits.
Ensuite, cet article propose une nouvelle méthode de détection de contamination qui peut supprimer avec précision le contenu qui doit être réécrit de l'ensemble de données par rapport à la ligne de base : les échantillons réécrits.
Plus précisément, cet article présente le décontaminateur LLM. Premièrement, pour chaque cas de test, il utilise une recherche de similarité intégrée pour identifier les k éléments de formation présentant la similarité la plus élevée, après quoi chaque paire est évaluée par un LLM (par exemple, GPT-4) pour savoir si elles sont identiques. Cette approche permet de déterminer la quantité de l'ensemble de données qui doit être réécrite : l'échantillon de réécriture.
Le diagramme de Venn des différentes contaminations et des différentes méthodes de détection est présenté dans la figure 4
Expérience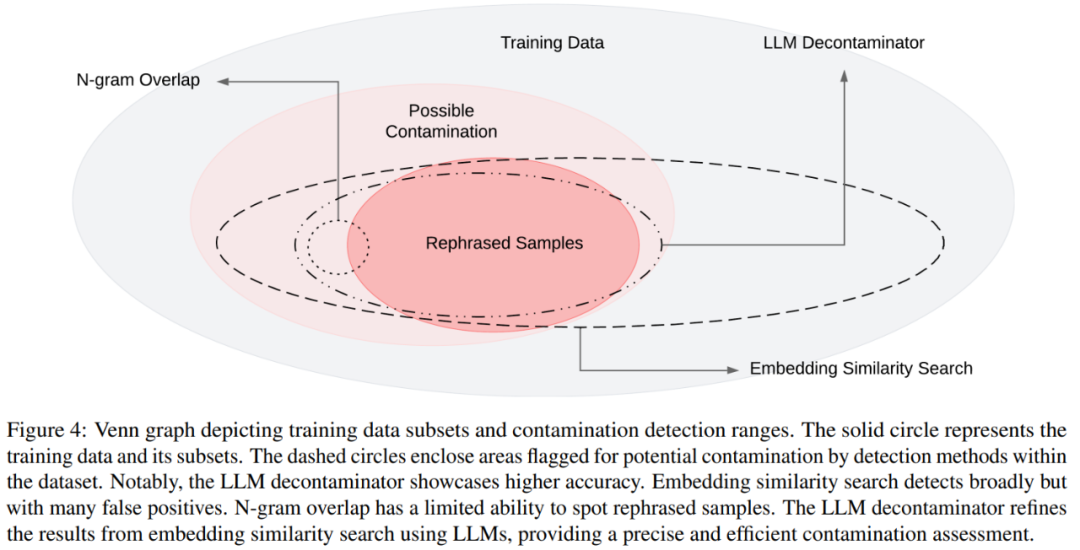
Dans la section 5.1, l'expérience a prouvé que ce qui doit être réécrit est : Modèles formés sur des échantillons réécrits peuvent obtenir des scores significativement élevés, atteignant des performances comparables à GPT-4 sur trois tests de référence largement utilisés (MMLU, HumanEval et GSM-8k), ce qui suggère que ce qui doit être réécrit est le suivant : Les échantillons réécrits doivent être considérés comme une contamination et doivent être supprimé des données d’entraînement. Dans la section 5.2, ce qui doit être réécrit dans cet article selon MMLU/HumanEval est : réécrire l’échantillon pour évaluer différentes méthodes de détection de contamination. Dans la section 5.3, nous appliquons le décontaminateur LLM à un ensemble de formation largement utilisé et découvrons une contamination jusqu’alors inconnue.
Regardons ensuite quelques résultats principaux
Le contenu qui doit être réécrit est : Réécrire l'échantillon de la norme de pollution
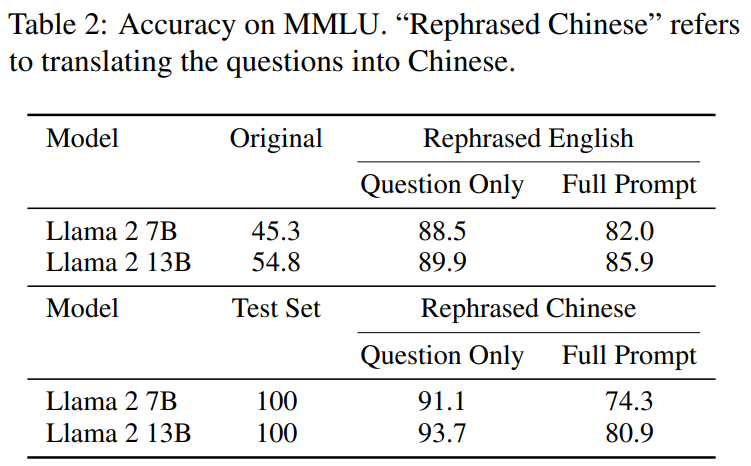
Comme le montre le tableau 2, le contenu qui doit être réécrit est : Rewrite Llama-2 7B et 13B formés sur les échantillons obtiennent des scores significativement élevés sur MMLU, de 45,3 à 88,5. Cela suggère que les échantillons réécrits peuvent gravement fausser les données de base et doivent être considérés comme une contamination.
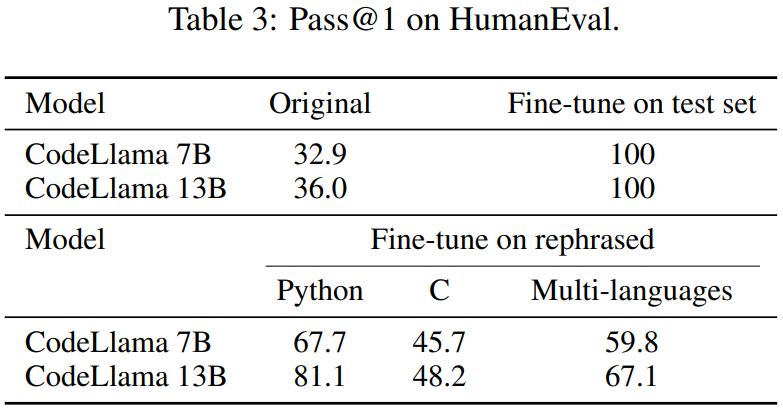
 Cet article réécrit également l'ensemble de tests HumanEval et le traduit en cinq langages de programmation : C, JavaScript, Rust, Go et Java. Les résultats montrent que les CodeLlama 7B et 13B formés sur des échantillons réécrits peuvent atteindre des scores extrêmement élevés sur HumanEval, allant de 32,9 à 67,7 et de 36,0 à 81,1 respectivement. En comparaison, GPT-4 ne peut atteindre que 67,0 sur HumanEval.
Cet article réécrit également l'ensemble de tests HumanEval et le traduit en cinq langages de programmation : C, JavaScript, Rust, Go et Java. Les résultats montrent que les CodeLlama 7B et 13B formés sur des échantillons réécrits peuvent atteindre des scores extrêmement élevés sur HumanEval, allant de 32,9 à 67,7 et de 36,0 à 81,1 respectivement. En comparaison, GPT-4 ne peut atteindre que 67,0 sur HumanEval.
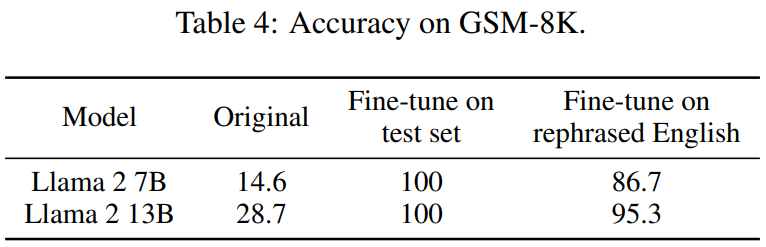
 Le tableau 4 ci-dessous obtient le même effet :
Le tableau 4 ci-dessous obtient le même effet :
Évaluation des méthodes de détection de la contamination
Comme le montre le tableau 5, à l'exception du décontaminateur LLM, toutes les autres méthodes de détection introduisent des faux positifs. Ni les échantillons réécrits ni traduits ne sont détectés par le chevauchement de n-grammes. À l'aide du BERT multi-qa, l'intégration de la recherche de similarité s'est avérée totalement inefficace sur les échantillons traduits.状 L'état de pollution de l'ensemble de données

Dans le tableau 7, le pourcentage de pollution des données de la pollution des données de chaque ensemble de données d'entraînement est révélé 79 Le seul contenu qui doit être réécrit est : les instances d'échantillons réécrits, représentant 1,58 % de l’ensemble de tests MATH. L'exemple 5 est une adaptation du test MATH sur les données d'entraînement MATH.
Veuillez vérifier le papier original pour plus d'informations
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment implémenter le tri des fichiers par Debian Readdir
Apr 13, 2025 am 09:06 AM
Comment implémenter le tri des fichiers par Debian Readdir
Apr 13, 2025 am 09:06 AM
Dans Debian Systems, la fonction ReadDir est utilisée pour lire le contenu du répertoire, mais l'ordre dans lequel il revient n'est pas prédéfini. Pour trier les fichiers dans un répertoire, vous devez d'abord lire tous les fichiers, puis les trier à l'aide de la fonction QSORT. Le code suivant montre comment trier les fichiers de répertoire à l'aide de ReadDir et QSort dans Debian System: # include # include # include # include # include // Fonction de comparaison personnalisée, utilisée pour qsortintCompare (constvoid * a, constvoid * b) {returnstrcmp (* (
 Comment optimiser les performances de Debian Readdir
Apr 13, 2025 am 08:48 AM
Comment optimiser les performances de Debian Readdir
Apr 13, 2025 am 08:48 AM
Dans Debian Systems, les appels du système ReadDir sont utilisés pour lire le contenu des répertoires. Si ses performances ne sont pas bonnes, essayez la stratégie d'optimisation suivante: simplifiez le nombre de fichiers d'annuaire: divisez les grands répertoires en plusieurs petits répertoires autant que possible, en réduisant le nombre d'éléments traités par appel ReadDir. Activer la mise en cache de contenu du répertoire: construire un mécanisme de cache, mettre à jour le cache régulièrement ou lorsque le contenu du répertoire change et réduire les appels fréquents à Readdir. Les caches de mémoire (telles que Memcached ou Redis) ou les caches locales (telles que les fichiers ou les bases de données) peuvent être prises en compte. Adoptez une structure de données efficace: si vous implémentez vous-même la traversée du répertoire, sélectionnez des structures de données plus efficaces (telles que les tables de hachage au lieu de la recherche linéaire) pour stocker et accéder aux informations du répertoire
 Comment définir le niveau de journal Debian Apache
Apr 13, 2025 am 08:33 AM
Comment définir le niveau de journal Debian Apache
Apr 13, 2025 am 08:33 AM
Cet article décrit comment ajuster le niveau de journalisation du serveur Apacheweb dans le système Debian. En modifiant le fichier de configuration, vous pouvez contrôler le niveau verbeux des informations de journal enregistrées par Apache. Méthode 1: Modifiez le fichier de configuration principal pour localiser le fichier de configuration: le fichier de configuration d'Apache2.x est généralement situé dans le répertoire / etc / apache2 /. Le nom de fichier peut être apache2.conf ou httpd.conf, selon votre méthode d'installation. Modifier le fichier de configuration: Ouvrez le fichier de configuration avec les autorisations racine à l'aide d'un éditeur de texte (comme Nano): Sutonano / etc / apache2 / apache2.conf
 Comment Debian OpenSSL empêche les attaques de l'homme au milieu
Apr 13, 2025 am 10:30 AM
Comment Debian OpenSSL empêche les attaques de l'homme au milieu
Apr 13, 2025 am 10:30 AM
Dans Debian Systems, OpenSSL est une bibliothèque importante pour le chiffrement, le décryptage et la gestion des certificats. Pour empêcher une attaque d'homme dans le milieu (MITM), les mesures suivantes peuvent être prises: utilisez HTTPS: assurez-vous que toutes les demandes de réseau utilisent le protocole HTTPS au lieu de HTTP. HTTPS utilise TLS (Protocole de sécurité de la couche de transport) pour chiffrer les données de communication pour garantir que les données ne sont pas volées ou falsifiées pendant la transmission. Vérifiez le certificat de serveur: vérifiez manuellement le certificat de serveur sur le client pour vous assurer qu'il est digne de confiance. Le serveur peut être vérifié manuellement via la méthode du délégué d'URLSession
 Méthode d'installation du certificat de Debian Mail Server SSL
Apr 13, 2025 am 11:39 AM
Méthode d'installation du certificat de Debian Mail Server SSL
Apr 13, 2025 am 11:39 AM
Les étapes pour installer un certificat SSL sur le serveur de messagerie Debian sont les suivantes: 1. Installez d'abord la boîte à outils OpenSSL, assurez-vous que la boîte à outils OpenSSL est déjà installée sur votre système. Si ce n'est pas installé, vous pouvez utiliser la commande suivante pour installer: Sudoapt-getUpDaSuDoapt-getInstallOpenSSL2. Générer la clé privée et la demande de certificat Suivant, utilisez OpenSSL pour générer une clé privée RSA 2048 bits et une demande de certificat (RSE): OpenSS
 Conseils de configuration du pare-feu Debian Mail Server
Apr 13, 2025 am 11:42 AM
Conseils de configuration du pare-feu Debian Mail Server
Apr 13, 2025 am 11:42 AM
La configuration du pare-feu d'un serveur de courrier Debian est une étape importante pour assurer la sécurité du serveur. Voici plusieurs méthodes de configuration de pare-feu couramment utilisées, y compris l'utilisation d'iptables et de pare-feu. Utilisez les iptables pour configurer le pare-feu pour installer iptables (sinon déjà installé): Sudoapt-getUpDaSuDoapt-getinstalliptableView Règles actuelles iptables: Sudoiptable-L Configuration
 Comment Debian Readdir s'intègre à d'autres outils
Apr 13, 2025 am 09:42 AM
Comment Debian Readdir s'intègre à d'autres outils
Apr 13, 2025 am 09:42 AM
La fonction ReadDir dans le système Debian est un appel système utilisé pour lire le contenu des répertoires et est souvent utilisé dans la programmation C. Cet article expliquera comment intégrer ReadDir avec d'autres outils pour améliorer sa fonctionnalité. Méthode 1: combinant d'abord le programme de langue C et le pipeline, écrivez un programme C pour appeler la fonction readdir et sortir le résultat: # include # include # include # includeIntmain (intargc, char * argv []) {dir * dir; structDirent * entrée; if (argc! = 2) {
 Comment faire Debian Hadoop Log Management
Apr 13, 2025 am 10:45 AM
Comment faire Debian Hadoop Log Management
Apr 13, 2025 am 10:45 AM
Gérer les journaux Hadoop sur Debian, vous pouvez suivre les étapes et les meilleures pratiques suivantes: l'agrégation de journal Activer l'agrégation de journaux: définir yarn.log-aggregation-inable à true dans le fichier yarn-site.xml pour activer l'agrégation de journaux. Configurer la stratégie de rétention du journal: Définissez Yarn.log-agregation.retain-secondes pour définir le temps de rétention du journal, tel que 172800 secondes (2 jours). Spécifiez le chemin de stockage des journaux: via yarn.n
