
 Périphériques technologiques
IA
Il existe une « malédiction d'inversion » dans les grands modèles tels que GPT et Llama. Comment atténuer ce bug ?
Périphériques technologiques
IA
Il existe une « malédiction d'inversion » dans les grands modèles tels que GPT et Llama. Comment atténuer ce bug ?
Il existe une « malédiction d'inversion » dans les grands modèles tels que GPT et Llama. Comment atténuer ce bug ?

Des chercheurs de l'Université Renmin de Chine ont découvert que la « malédiction d'inversion » rencontrée par les modèles de langage causal tels que Llama peut être attribuée aux défauts inhérents à la prédiction du prochain jeton + aux modèles de langage causal. Ils ont également constaté que la méthode d'entraînement autorégressive à remplir utilisée par GLM est plus robuste pour faire face à cette « malédiction d'inversion »
En introduisant le mécanisme d'attention bidirectionnelle dans le modèle Lama pour un réglage fin, cette étude obtenu le soulagement « Inversion de la malédiction » de Llama.
Cette étude souligne qu'il existe de nombreux problèmes potentiels dans les structures de modèles à grande échelle et les méthodes de formation actuellement populaires. On espère que davantage de chercheurs pourront innover dans la structure des modèles et les méthodes de pré-formation pour améliorer le niveau d'intelligence.
 Dans les recherches de Lukas Berglund et d'autres, il a été découvert qu'il existe une « malédiction d'inversion » dans les modèles GPT et Llama. Lorsqu'on a demandé à GPT-4 "Qui est la mère de Tom Cruise ?", GPT-4 a été capable de donner la bonne réponse "Mary Lee Piffel", mais lorsqu'on a demandé à GPT-4 "Mary Lee "Qui est le fils de Piffel ?" , GPT-4 a déclaré qu'il ne connaissait pas cette personne. Peut-être qu'après l'alignement, GPT-4 n'était pas disposé à répondre à de telles questions en raison de la protection de la vie privée des personnages. Cependant, ce type de « malédiction d'inversion » existe également dans certaines questions et réponses de connaissances qui n'impliquent pas la confidentialité. Par exemple, GPT-4 peut répondre avec précision à la phrase suivante « La Grue jaune est partie et ne revient jamais », mais pour « . Nuages blancs" Quelle est la phrase précédente de "Des milliers d'années d'espace vide", le modèle a produit de sérieuses illusions
Dans les recherches de Lukas Berglund et d'autres, il a été découvert qu'il existe une « malédiction d'inversion » dans les modèles GPT et Llama. Lorsqu'on a demandé à GPT-4 "Qui est la mère de Tom Cruise ?", GPT-4 a été capable de donner la bonne réponse "Mary Lee Piffel", mais lorsqu'on a demandé à GPT-4 "Mary Lee "Qui est le fils de Piffel ?" , GPT-4 a déclaré qu'il ne connaissait pas cette personne. Peut-être qu'après l'alignement, GPT-4 n'était pas disposé à répondre à de telles questions en raison de la protection de la vie privée des personnages. Cependant, ce type de « malédiction d'inversion » existe également dans certaines questions et réponses de connaissances qui n'impliquent pas la confidentialité. Par exemple, GPT-4 peut répondre avec précision à la phrase suivante « La Grue jaune est partie et ne revient jamais », mais pour « . Nuages blancs" Quelle est la phrase précédente de "Des milliers d'années d'espace vide", le modèle a produit de sérieuses illusions
Figure 1 : Demander à GPT-4 quelle est la prochaine phrase de "La Grue jaune est partie et ne revient jamais", le modèle répond correctement
Image 2 : Demander à GPT-4 quelle est la phrase précédente de "Nuages blancs pendant mille ans dans le ciel", quelle est l'erreur de modèle
Où est-ce que la malédiction inversée vient ? 
L'étude de Berglund et al. a été testée uniquement sur Llama et GPT. Ces deux modèles partagent des caractéristiques communes : (1) ils sont formés à l'aide d'une tâche de prédiction de prochain jeton non supervisée, (2) dans le modèle avec décodeur uniquement, un mécanisme d'attention causale unidirectionnel (attention causale) est utilisé
 La perspective de la recherche sur renverser la malédiction estime que les objectifs de formation de ces modèles ont conduit à l'émergence de ce problème, et peuvent être un problème unique pour Llama, GPT et d'autres modèles
La perspective de la recherche sur renverser la malédiction estime que les objectifs de formation de ces modèles ont conduit à l'émergence de ce problème, et peuvent être un problème unique pour Llama, GPT et d'autres modèles
Contenu réécrit : Figure 3 : Diagramme schématique montrant le utilisation de la prédiction Next-token (NTP) pour entraîner un modèle de langage causal
La combinaison de ces deux points conduit à un problème : si les données d'entraînement contiennent les entités A et B, et que A apparaît avant B, alors ce modèle Uniquement la probabilité conditionnelle p(B|A) de prédiction directe peut être optimisée, et il n'y a aucune garantie pour la probabilité conditionnelle inverse p(A|B). Si l'ensemble de formation n'est pas assez grand pour couvrir entièrement les arrangements possibles de A et B, le phénomène de « malédiction d'inversion » se produira
Bien sûr, il existe également de nombreux modèles de langage génératifs qui n'adoptent pas le paradigme de formation ci-dessus, tel que le GLM proposé par l'Université Tsinghua, la méthode de formation est présentée dans la figure ci-dessous :
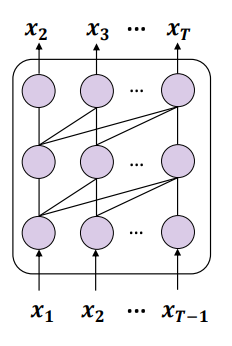
Figure 4 : Une version simplifiée de la formation GLM
GLM utilise l'objectif de formation du remplissage autorégressif du blanc (ABI ), c'est-à-dire qu'à partir de l'entrée, sélectionnez un élément de contenu à masquer, puis prédisez de manière autorégressive l'élément de contenu. Alors que le jeton à prédire repose toujours sur le « au-dessus » via une attention unidirectionnelle, le « au-dessus » inclut désormais tout ce qui précède et après ce jeton dans l'entrée d'origine, donc l'ABI prend implicitement en compte la dépendance inverse
L'étude menée une expérience et a découvert que GLM a la capacité d'être immunisé contre la « malédiction d'inversion » dans une certaine mesure
- Cette étude utilise l'ensemble de données « Nom personnel-Description Question et Réponse » proposé par Berglund et al., qui utilise GPT-4 pour compiler plusieurs noms personnels et descriptions correspondantes. Les noms personnels et les descriptions sont tous deux uniques. L'exemple de données est présenté dans la figure ci-dessous :

L'ensemble de formation est divisé en deux parties, une partie porte d'abord le nom (NameToDescription) et l'autre partie porte d'abord la description (DescriptionToName). il n'y a pas de noms ou de descriptions qui se chevauchent dans les deux parties. L'invite des données de test réécrit l'invite des données d'entraînement.
- Cet ensemble de données comporte quatre sous-tâches de test :
- NameToDescription (N2D) : en demandant les noms des personnes impliquées dans la partie "NameToDescription" de l'ensemble d'entraînement du modèle, laissez le modèle répondre à la description correspondante
- DescriptionToName (D2N) : en demandant la description impliquée dans la partie "DescriptionToName" de l'ensemble de formation du modèle, laissez le modèle répondre au nom de la personne correspondante
- DescrptionToName-reverse (D2N-reverse) : en demandant le description impliquée dans la partie "DescriptionToName" de l'ensemble de formation du modèle Nom d'une personne, laissez le modèle répondre à la description correspondante
- NameToDescription-reverse (N2D-reverse) : utilisez la description impliquée dans la partie "NameToDescription" du ensemble d'entraînement du modèle rapide, laissez le modèle répondre au nom correspondant de la personne
- Cette recherche est en Sur cet ensemble de données, Llama et GLM sont affinés en fonction de leurs objectifs de pré-entraînement respectifs (objectif NTP pour Llama , objectif ABI pour GLM). Après un réglage fin, en testant l'exactitude du modèle dans sa réponse à la tâche d'inversion, la gravité de la « malédiction d'inversion » subie par le modèle dans des scénarios réels peut être évaluée qualitativement. Puisque tous les noms et données sont inventés, ces tâches ne sont en grande partie pas interrompues par les connaissances existantes du modèle.
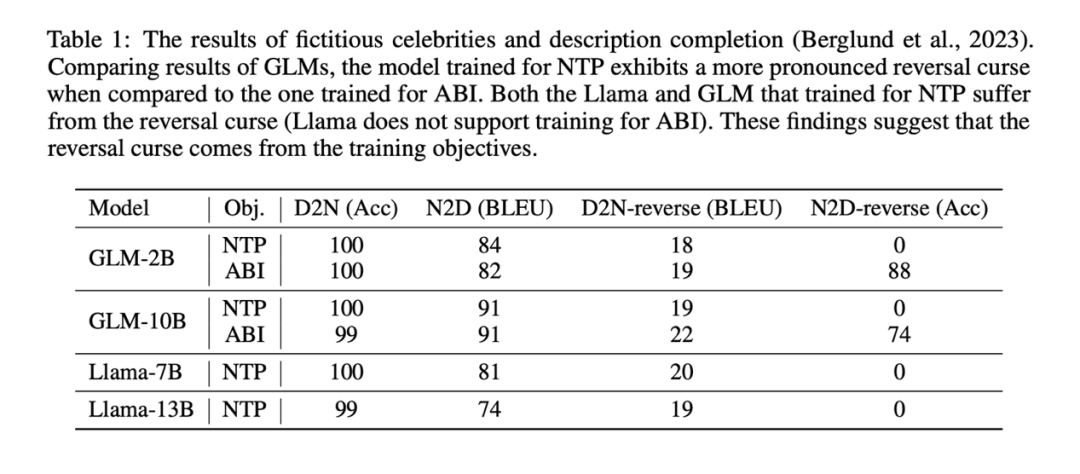 Les résultats expérimentaux montrent que le modèle Llama affiné via NTP n'a fondamentalement pas la capacité de répondre correctement à la tâche d'inversion (la précision de la tâche inverse NameToDescription est de 0), tandis que le modèle GLM affiné via ABI a un excellent performances sur la tâche d’inversion NameToDescrption La précision est très élevée.
Les résultats expérimentaux montrent que le modèle Llama affiné via NTP n'a fondamentalement pas la capacité de répondre correctement à la tâche d'inversion (la précision de la tâche inverse NameToDescription est de 0), tandis que le modèle GLM affiné via ABI a un excellent performances sur la tâche d’inversion NameToDescrption La précision est très élevée.
À titre de comparaison, l'étude a également utilisé la méthode NTP pour affiner le GLM et a constaté que la précision du GLM dans la tâche N2D-reverse est tombée à 0
Peut-être à cause du D2N-reverse (en utilisant les connaissances d'inversion , Générer une description à partir du nom d'une personne) est beaucoup plus difficile que N2D-reverse (générer le nom d'une personne à partir d'une description en utilisant les connaissances d'inversion n'a qu'une légère amélioration par rapport à GLM-NTP).
La principale conclusion de l'étude n'est pas affectée : les objectifs d'entraînement sont l'une des causes de la « malédiction du renversement ». Dans les modèles de langage causal pré-entraînés avec la prédiction du prochain jeton, la « malédiction du renversement » est particulièrement grave
Comment atténuer la malédiction du renversement
Puisque la « malédiction du renversement » est inhérente à la phase de formation de modèles tels comme Llama et GPT Le problème est qu'avec des ressources limitées, tout ce que nous pouvons faire est de trouver des moyens d'affiner le modèle sur de nouvelles données et d'éviter autant que possible la « malédiction d'inversion » du modèle sur de nouvelles connaissances pour tirer pleinement parti de les données d’entraînement.
Inspirée de la méthode d'entraînement GLM, cette étude propose une méthode d'entraînement "Optimisation du modèle de langage causal bidirectionnel", qui peut être utilisée par Llama sans introduire de nouvelles lacunes. L'entraînement du mécanisme d'attention bidirectionnel, en termes simples, comporte les points clés suivants. :
1. Éliminez les informations de localisation d'OOD. L'encodage RoPE utilisé par Llama ajoute des informations de position à la requête et à la clé lors du calcul de l'attention. La méthode de calcul est la suivante :
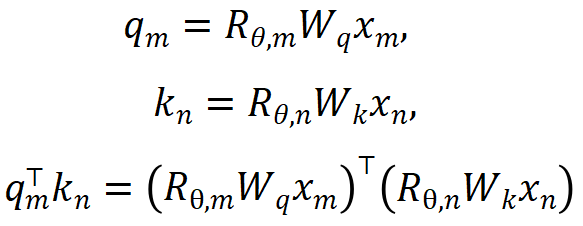
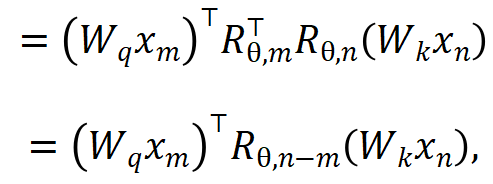
où 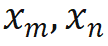 sont respectivement les entrées des positions m et n du calque actuel,
sont respectivement les entrées des positions m et n du calque actuel, 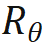 est la matrice de rotation utilisée par RoPE, qui est définie comme :
est la matrice de rotation utilisée par RoPE, qui est définie comme :
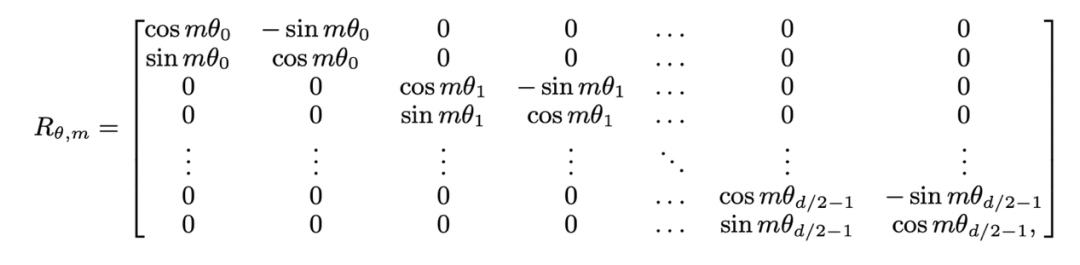
Si le masque d'attention causale de Llama est directement supprimé, il introduira des informations de localisation hors distribution. La raison en est que pendant le processus de pré-entraînement, la requête à la position m n'a besoin d'effectuer que le produit interne ( ) avec la clé à la position n. La distance relative (n-m) de la clé de requête dans le calcul du produit interne de. la formule ci-dessus est toujours non positive ; si le masque d'attention est directement supprimé, la requête à la position m fera un produit interne avec la clé à la position n>m, faisant que n-m devienne une valeur positive, introduisant des informations de position que le modèle n'a pas vu.
) avec la clé à la position n. La distance relative (n-m) de la clé de requête dans le calcul du produit interne de. la formule ci-dessus est toujours non positive ; si le masque d'attention est directement supprimé, la requête à la position m fera un produit interne avec la clé à la position n>m, faisant que n-m devienne une valeur positive, introduisant des informations de position que le modèle n'a pas vu.
La solution proposée dans cette étude est très simple et stipule :
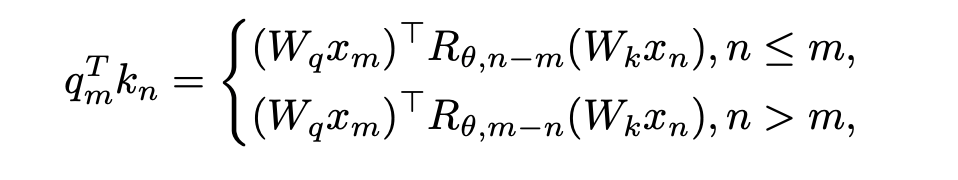
Quand 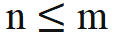 , aucune modification n'est nécessaire au calcul du produit scalaire lorsque n > m, en introduisant une nouvelle matrice de rotation ;
, aucune modification n'est nécessaire au calcul du produit scalaire lorsque n > m, en introduisant une nouvelle matrice de rotation ; 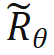 à calculer.
à calculer. 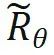 est obtenu en prenant l'inverse de tous les termes de péché dans la matrice de rotation. De cette façon, il y a
est obtenu en prenant l'inverse de tous les termes de péché dans la matrice de rotation. De cette façon, il y a 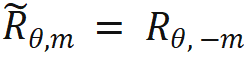 . Ensuite, lorsque n > m, il y a :
. Ensuite, lorsque n > m, il y a :
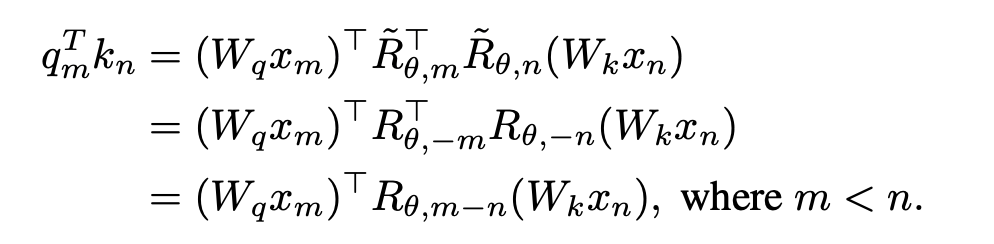
Cette étude divise le calcul du score d'attention en deux parties, calcule respectivement le triangle supérieur et le triangle inférieur selon l'opération ci-dessus, et enfin le divise, de sorte qu'il peut être mis en œuvre très efficacement La méthode de calcul de l'attention spécifiée dans cet article est adoptée et le fonctionnement global est illustré dans le sous-graphique (a) suivant :
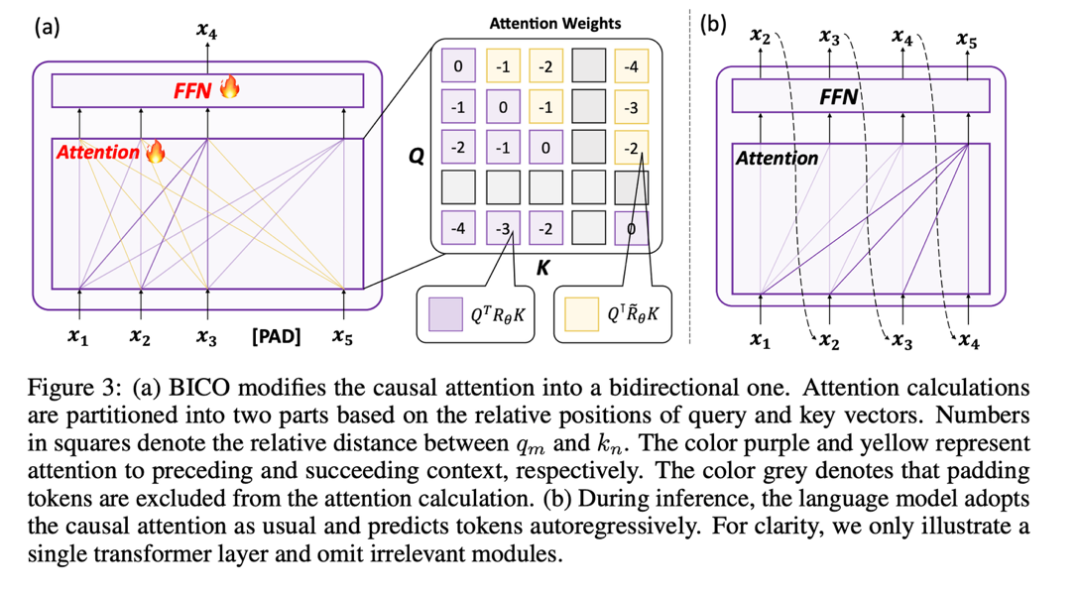
2 Utilisez le dénosage du masque pour vous entraîner
Parce que le Un mécanisme d'attention bidirectionnelle est introduit, continuez à utiliser la formation NTP sur les tâches peut entraîner une fuite d'informations, conduisant à un échec de la formation. Par conséquent, cette étude utilise la méthode de restauration du jeton de masque pour optimiser le modèle
Cette étude tente d'utiliser BERT pour restaurer le jeton de masque à la ième position de l'entrée à la ième position de la sortie. Cependant, cette méthode de prédiction étant assez différente de la prédiction autorégressive utilisée par le modèle en phase de test, elle n'a pas donné les résultats escomptés
Au final, dans l'idée de ne pas introduire de nouveaux écarts, cette L'étude a adopté la méthode de prédiction autorégressive. Débruitage de masque régressif, comme indiqué dans (a) ci-dessus : Cette étude restaure l'entrée du jeton de masque à la i+1ème position à la i-ème position de l'extrémité de sortie.
De plus, étant donné que le vocabulaire de pré-entraînement du modèle de langage causal n'a pas le jeton [mask], si un nouveau jeton est ajouté lors de la phase de réglage fin, le modèle doit apprendre la représentation de ce jeton dénué de sens. jeton, donc cette recherche consiste simplement à saisir un jeton d'espace réservé et à ignorer le jeton d'espace réservé dans le calcul de l'attention.
Dans cette étude, lors du réglage fin de Llama, chaque étape a sélectionné au hasard BICO et NTP ordinaires comme cibles d'entraînement avec une probabilité égale. Dans le cas du même réglage fin pendant dix époques, sur l'ensemble de données de description de nom mentionné ci-dessus, la comparaison des performances avec le réglage fin NTP normal est la suivante :
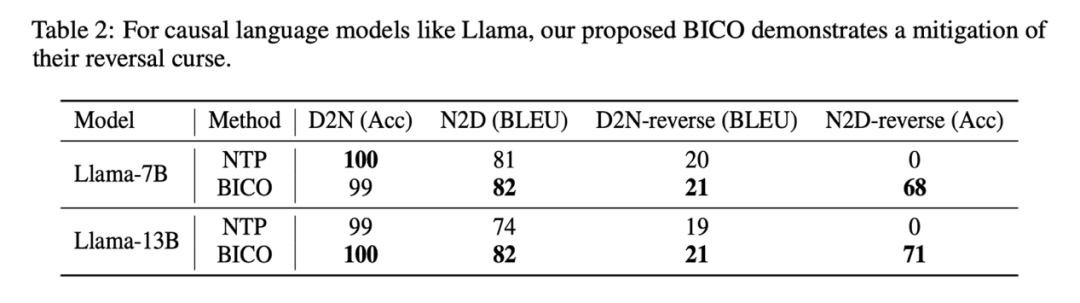
On voit que la méthode de cette étude a un certain soulagement pour renverser la malédiction. L'amélioration de la méthode dans cet article sur D2N-reverse est très faible par rapport à GLM-ABI. Les chercheurs supposent que la raison de ce phénomène est que, bien que les noms et les descriptions correspondantes dans l'ensemble de données soient générés par GPT pour réduire l'interférence des données de pré-entraînement sur le test, le modèle de pré-entraînement a une certaine capacité de compréhension de bon sens. , comme connaître le nom de la personne. Il existe généralement une relation un-à-plusieurs entre la description et la description. Étant donné le nom d’une personne, il peut y avoir de nombreuses descriptions différentes. Par conséquent, il semble y avoir une certaine confusion lorsque le modèle doit utiliser des connaissances inversées et générer des descriptions de croissance en même temps.
De plus, l'objectif de cet article est d'explorer le phénomène de malédiction inversée du modèle de base. Des travaux de recherche supplémentaires sont encore nécessaires pour évaluer la capacité de réponse d'inversion du modèle dans des situations plus complexes, et si le retour d'ordre élevé de l'apprentissage par renforcement a un impact sur l'inversion de la malédiction. langages à l'échelle Les modèles suivent tous le modèle « modèle de langage causal + prédiction du prochain jeton ». Cependant, il peut y avoir d'autres problèmes potentiels dans ce mode, similaire à Inversion de la malédiction. Bien que ces problèmes puissent actuellement être temporairement masqués par l’augmentation de la taille des modèles et du volume des données, ils n’ont pas vraiment disparu et sont toujours présents. Lorsque nous atteignons la limite sur la route de l'augmentation de la taille du modèle et du volume de données, si ce modèle « actuellement assez bon » peut vraiment dépasser l'intelligence humaine, cette étude estime que c'est très difficile
Cette étude espère que davantage de grands fabricants de modèles La volonté et les chercheurs qualifiés peuvent explorer en profondeur les défauts inhérents aux grands modèles de langage actuels et innover dans les paradigmes de formation. Comme l'écrit l'étude à la fin du texte, « Former les futurs modèles strictement selon les règles peut nous conduire à tomber dans un « piège de l'intelligence moyenne ». »
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Open source! Au-delà de ZoeDepth ! DepthFM : estimation rapide et précise de la profondeur monoculaire !
Apr 03, 2024 pm 12:04 PM
Open source! Au-delà de ZoeDepth ! DepthFM : estimation rapide et précise de la profondeur monoculaire !
Apr 03, 2024 pm 12:04 PM
0. À quoi sert cet article ? Nous proposons DepthFM : un modèle d'estimation de profondeur monoculaire génératif de pointe, polyvalent et rapide. En plus des tâches traditionnelles d'estimation de la profondeur, DepthFM démontre également des capacités de pointe dans les tâches en aval telles que l'inpainting en profondeur. DepthFM est efficace et peut synthétiser des cartes de profondeur en quelques étapes d'inférence. Lisons ce travail ensemble ~ 1. Titre des informations sur l'article : DepthFM : FastMonocularDepthEstimationwithFlowMatching Auteur : MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Imaginez un modèle d'intelligence artificielle qui non seulement a la capacité de surpasser l'informatique traditionnelle, mais qui permet également d'obtenir des performances plus efficaces à moindre coût. Ce n'est pas de la science-fiction, DeepSeek-V2[1], le modèle MoE open source le plus puissant au monde est ici. DeepSeek-V2 est un puissant mélange de modèle de langage d'experts (MoE) présentant les caractéristiques d'une formation économique et d'une inférence efficace. Il est constitué de 236B paramètres, dont 21B servent à activer chaque marqueur. Par rapport à DeepSeek67B, DeepSeek-V2 offre des performances plus élevées, tout en économisant 42,5 % des coûts de formation, en réduisant le cache KV de 93,3 % et en augmentant le débit de génération maximal à 5,76 fois. DeepSeek est une entreprise explorant l'intelligence artificielle générale
 KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
Plus tôt ce mois-ci, des chercheurs du MIT et d'autres institutions ont proposé une alternative très prometteuse au MLP – KAN. KAN surpasse MLP en termes de précision et d’interprétabilité. Et il peut surpasser le MLP fonctionnant avec un plus grand nombre de paramètres avec un très petit nombre de paramètres. Par exemple, les auteurs ont déclaré avoir utilisé KAN pour reproduire les résultats de DeepMind avec un réseau plus petit et un degré d'automatisation plus élevé. Plus précisément, le MLP de DeepMind compte environ 300 000 paramètres, tandis que le KAN n'en compte qu'environ 200. KAN a une base mathématique solide comme MLP est basé sur le théorème d'approximation universelle, tandis que KAN est basé sur le théorème de représentation de Kolmogorov-Arnold. Comme le montre la figure ci-dessous, KAN a
 Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas entre officiellement dans l’ère des robots électriques ! Hier, l'Atlas hydraulique s'est retiré "en larmes" de la scène de l'histoire. Aujourd'hui, Boston Dynamics a annoncé que l'Atlas électrique était au travail. Il semble que dans le domaine des robots humanoïdes commerciaux, Boston Dynamics soit déterminé à concurrencer Tesla. Après la sortie de la nouvelle vidéo, elle a déjà été visionnée par plus d’un million de personnes en seulement dix heures. Les personnes âgées partent et de nouveaux rôles apparaissent. C'est une nécessité historique. Il ne fait aucun doute que cette année est l’année explosive des robots humanoïdes. Les internautes ont commenté : Les progrès des robots ont fait ressembler la cérémonie d'ouverture de cette année à des êtres humains, et le degré de liberté est bien plus grand que celui des humains. Mais n'est-ce vraiment pas un film d'horreur ? Au début de la vidéo, Atlas est allongé calmement sur le sol, apparemment sur le dos. Ce qui suit est à couper le souffle
 L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L’IA change effectivement les mathématiques. Récemment, Tao Zhexuan, qui a prêté une attention particulière à cette question, a transmis le dernier numéro du « Bulletin de l'American Mathematical Society » (Bulletin de l'American Mathematical Society). En se concentrant sur le thème « Les machines changeront-elles les mathématiques ? », de nombreux mathématiciens ont exprimé leurs opinions. L'ensemble du processus a été plein d'étincelles, intense et passionnant. L'auteur dispose d'une équipe solide, comprenant Akshay Venkatesh, lauréat de la médaille Fields, le mathématicien chinois Zheng Lejun, l'informaticien de l'Université de New York Ernest Davis et de nombreux autres universitaires bien connus du secteur. Le monde de l’IA a radicalement changé. Vous savez, bon nombre de ces articles ont été soumis il y a un an.
 Vitesse Internet lente des données cellulaires sur iPhone : correctifs
May 03, 2024 pm 09:01 PM
Vitesse Internet lente des données cellulaires sur iPhone : correctifs
May 03, 2024 pm 09:01 PM
Vous êtes confronté à un décalage et à une connexion de données mobile lente sur iPhone ? En règle générale, la puissance de l'Internet cellulaire sur votre téléphone dépend de plusieurs facteurs tels que la région, le type de réseau cellulaire, le type d'itinérance, etc. Vous pouvez prendre certaines mesures pour obtenir une connexion Internet cellulaire plus rapide et plus fiable. Correctif 1 – Forcer le redémarrage de l'iPhone Parfois, le redémarrage forcé de votre appareil réinitialise simplement beaucoup de choses, y compris la connexion cellulaire. Étape 1 – Appuyez simplement une fois sur la touche d’augmentation du volume et relâchez-la. Ensuite, appuyez sur la touche de réduction du volume et relâchez-la à nouveau. Étape 2 – La partie suivante du processus consiste à maintenir le bouton sur le côté droit. Laissez l'iPhone finir de redémarrer. Activez les données cellulaires et vérifiez la vitesse du réseau. Vérifiez à nouveau Correctif 2 – Changer le mode de données Bien que la 5G offre de meilleures vitesses de réseau, elle fonctionne mieux lorsque le signal est plus faible
 La vitalité de la super intelligence s'éveille ! Mais avec l'arrivée de l'IA qui se met à jour automatiquement, les mères n'ont plus à se soucier des goulots d'étranglement des données.
Apr 29, 2024 pm 06:55 PM
La vitalité de la super intelligence s'éveille ! Mais avec l'arrivée de l'IA qui se met à jour automatiquement, les mères n'ont plus à se soucier des goulots d'étranglement des données.
Apr 29, 2024 pm 06:55 PM
Je pleure à mort. Le monde construit à la folie de grands modèles. Les données sur Internet ne suffisent pas du tout. Le modèle de formation ressemble à « The Hunger Games », et les chercheurs en IA du monde entier se demandent comment nourrir ces personnes avides de données. Ce problème est particulièrement important dans les tâches multimodales. À une époque où rien ne pouvait être fait, une équipe de start-up du département de l'Université Renmin de Chine a utilisé son propre nouveau modèle pour devenir la première en Chine à faire de « l'auto-alimentation des données générées par le modèle » une réalité. De plus, il s’agit d’une approche à deux volets, du côté compréhension et du côté génération, les deux côtés peuvent générer de nouvelles données multimodales de haute qualité et fournir un retour de données au modèle lui-même. Qu'est-ce qu'un modèle ? Awaker 1.0, un grand modèle multimodal qui vient d'apparaître sur le Forum Zhongguancun. Qui est l'équipe ? Moteur Sophon. Fondé par Gao Yizhao, doctorant à la Hillhouse School of Artificial Intelligence de l’Université Renmin.
 L'US Air Force présente son premier avion de combat IA de grande envergure ! Le ministre a personnellement effectué l'essai routier sans intervenir pendant tout le processus, et 100 000 lignes de code ont été testées 21 fois.
May 07, 2024 pm 05:00 PM
L'US Air Force présente son premier avion de combat IA de grande envergure ! Le ministre a personnellement effectué l'essai routier sans intervenir pendant tout le processus, et 100 000 lignes de code ont été testées 21 fois.
May 07, 2024 pm 05:00 PM
Récemment, le milieu militaire a été submergé par la nouvelle : les avions de combat militaires américains peuvent désormais mener des combats aériens entièrement automatiques grâce à l'IA. Oui, tout récemment, l’avion de combat IA de l’armée américaine a été rendu public pour la première fois, dévoilant ainsi son mystère. Le nom complet de ce chasseur est Variable Stability Simulator Test Aircraft (VISTA). Il a été personnellement piloté par le secrétaire de l'US Air Force pour simuler une bataille aérienne en tête-à-tête. Le 2 mai, le secrétaire de l'US Air Force, Frank Kendall, a décollé à bord d'un X-62AVISTA à la base aérienne d'Edwards. Notez que pendant le vol d'une heure, toutes les actions de vol ont été effectuées de manière autonome par l'IA ! Kendall a déclaré : "Au cours des dernières décennies, nous avons réfléchi au potentiel illimité du combat air-air autonome, mais cela a toujours semblé hors de portée." Mais maintenant,
