


Avec le développement d'Internet, les entreprises peuvent obtenir de plus en plus de données. Ces données aident les entreprises à mieux comprendre les utilisateurs, appelés profils clients, et peuvent améliorer l'expérience utilisateur. Cependant, ces données peuvent contenir une grande quantité de données non étiquetées. Si toutes les données sont étiquetées manuellement, il y aura deux problèmes. Tout d’abord, l’étiquetage manuel prend du temps et est inefficace. À mesure que la quantité de données augmente, il faudra embaucher davantage de personnes, ce qui prendra plus de temps et coûtera plus cher. Deuxièmement, à mesure que le nombre d'utilisateurs augmente, il est difficile de suivre la croissance des données grâce à l'étiquetage manuel. Partie 01,
Qu'est-ce que l'apprentissage semi-supervisé
Partie 02. Hypothèses de l'apprentissage semi-supervisé 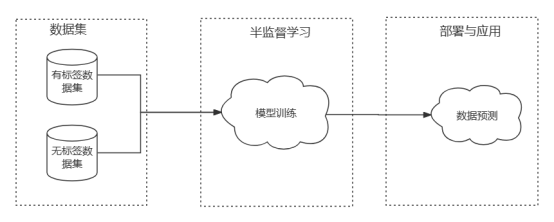
L'objectif principal de l'hypothèse ci-dessus est de montrer que les données étiquetées et les données non étiquetées proviennent de la même distribution de données.
Partie 03,
Classification des algorithmes d'apprentissage semi-superviséapprentissage transductif (apprentissage transductif) et apprentissage inductif (modèle inductif) , la différence entre les deux réside dans la sélection de l'ensemble de données de test utilisé pour l'évaluation du modèle. L'apprentissage semi-supervisé par poussée directe signifie que l'ensemble de données qui doit prédire l'étiquette est l'ensemble de données non étiquetées utilisé pour la formation. Le but de l'apprentissage est d'améliorer encore la précision des résultats de prédiction. L'apprentissage inductif prédit les étiquettes pour des ensembles de données complètement inconnus.
De plus, les étapes des algorithmes d'apprentissage semi-supervisé courants sont : la première étape consiste à entraîner un modèle sur des données étiquetées, puis à utiliser ce modèle pour étiqueter des données non étiquetées, puis à combiner les pseudo-étiquettes et le les données étiquetées sont combinées dans un nouvel ensemble de formation, un nouveau modèle est formé sur cet ensemble de formation et enfin le modèle est utilisé pour étiqueter l'ensemble de données de prédiction. 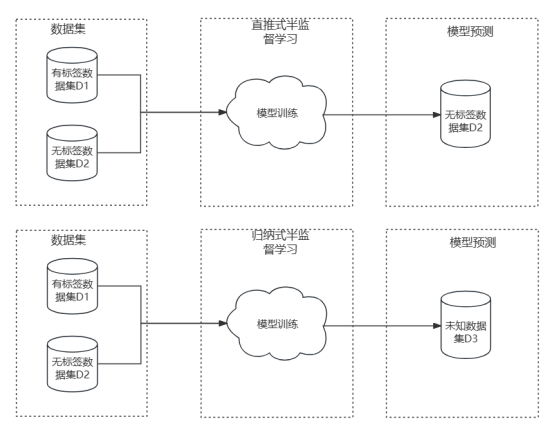
Partie 04, Résumé
Actuellement dans le domaine de l'apprentissage semi-supervisé, le PU-Learning (apprentissage par échantillons positifs et négatifs) est un algorithme populaire. Ce type d'algorithme est principalement appliqué aux ensembles de données contenant uniquement des échantillons positifs et des données non étiquetées. Son avantage est que dans certains scénarios, nous pouvons obtenir relativement facilement des ensembles de données d’échantillons positifs fiables et que la quantité de données est relativement importante. Par exemple, dans la détection du spam, nous pouvons facilement obtenir une grande quantité de données de courrier électronique normales
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Application de l'intelligence artificielle dans la vie
Application de l'intelligence artificielle dans la vie
 Quel est le concept de base de l'intelligence artificielle
Quel est le concept de base de l'intelligence artificielle
 Comment utiliser Redis comme serveur de cache
Quel est le concept de base de l'intelligence artificielle
Comment utiliser Redis comme serveur de cache
Quel est le concept de base de l'intelligence artificielle
 si qu'est-ce que ça veut dire
si qu'est-ce que ça veut dire
 Windows ultime
Windows ultime
 Le rôle des serveurs de noms de domaine
Le rôle des serveurs de noms de domaine
 Comment acheter du Ripple en Chine
Comment acheter du Ripple en Chine
 Touche de raccourci de veille
Touche de raccourci de veille








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



