
 Périphériques technologiques
IA
GPT-4 fonctionne mal en inférence graphique ? Même après « libération de l'eau », le taux de précision n'est que de 33 %
Périphériques technologiques
IA
GPT-4 fonctionne mal en inférence graphique ? Même après « libération de l'eau », le taux de précision n'est que de 33 %
GPT-4 fonctionne mal en inférence graphique ? Même après « libération de l'eau », le taux de précision n'est que de 33 %

La capacité de raisonnement graphique du GPT-4 est inférieure de moitié à celle des humains ?
Une étude du Santa Fe Research Institute aux États-Unis montre que la précision du GPT-4 pour les questions de raisonnement graphique n'est que de 33%.
GPT-4v a des capacités multimodales, mais ses performances sont relativement médiocres et ne peuvent répondre correctement qu'à 25 % des questions
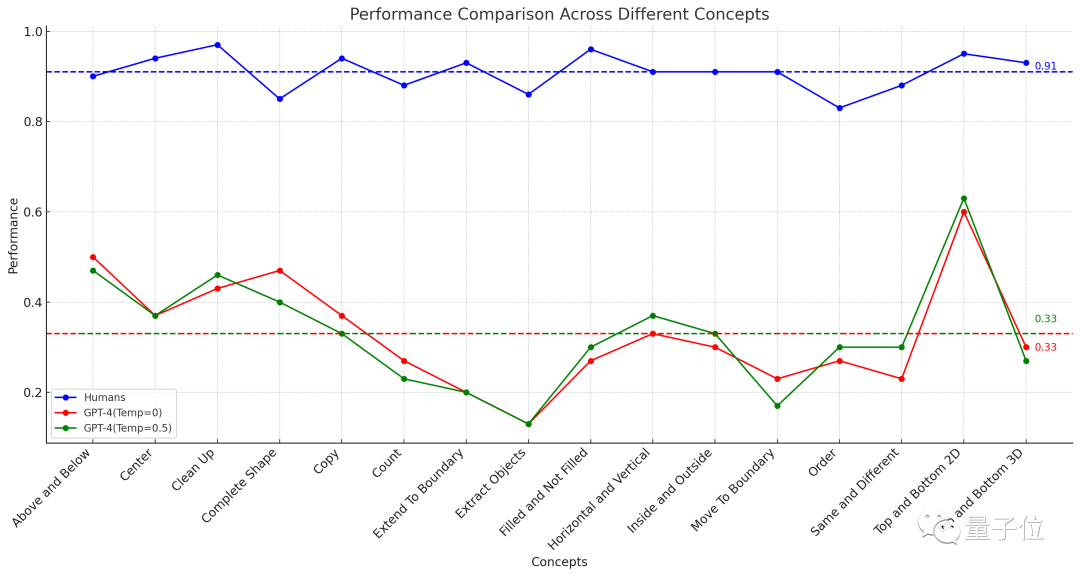
△La ligne pointillée représente la performance moyenne de 16 tâches
Dès que les résultats de cette expérience ont été publiés, a immédiatement provoqué de larges discussions sur YC
Certains internautes qui ont soutenu ce résultat ont déclaré que GPT ne fonctionnait pas bien dans le traitement des graphiques abstraits et qu'il était plus difficile de comprendre des concepts tels que "position" et "rotation"

Cependant, certains internautes ont exprimé des doutes sur cette conclusion. Leurs opinions peuvent être simplement résumées comme suit :
Bien que cette opinion ne puisse pas être considérée comme fausse, elle n'est pas complètement convaincante

En ce qui concerne les détails. raisons, nous continuons à lire.
La précision de GPT-4 n'est que de 33%
Afin d'évaluer les performances des humains et de GPT-4 sur ces problèmes graphiques, les chercheurs ont utilisé l'ensemble de données ConceptARC lancé en mai de cette année
ConceptARC comprend un total de 16 sous-catégories Questions de raisonnement graphique, 30 questions par catégorie, 480 questions au total.

Ces 16 sous-catégories incluent les relations de position, les formes, les opérations, les comparaisons, etc.
Plus précisément, ces questions sont composées de blocs de pixels. Les humains et GPT doivent trouver des modèles basés sur des exemples donnés et analyser les résultats des images traitées de la même manière.
L'auteur montre spécifiquement des exemples de ces 16 sous-catégories dans l'article, une pour chaque catégorie.



Les résultats ont montré que le taux de précision moyen de 451 sujets humains n'était pas inférieur à 83 % dans chaque sous-élément, et que la moyenne de 16 tâches atteignait 91 %.
Dans le cas où vous pouvez essayer une question trois fois (si vous réussissez une fois), la précision la plus élevée du GPT-4 (échantillon unique) ne dépasse pas 60 %, et la moyenne n'est que de 33 %
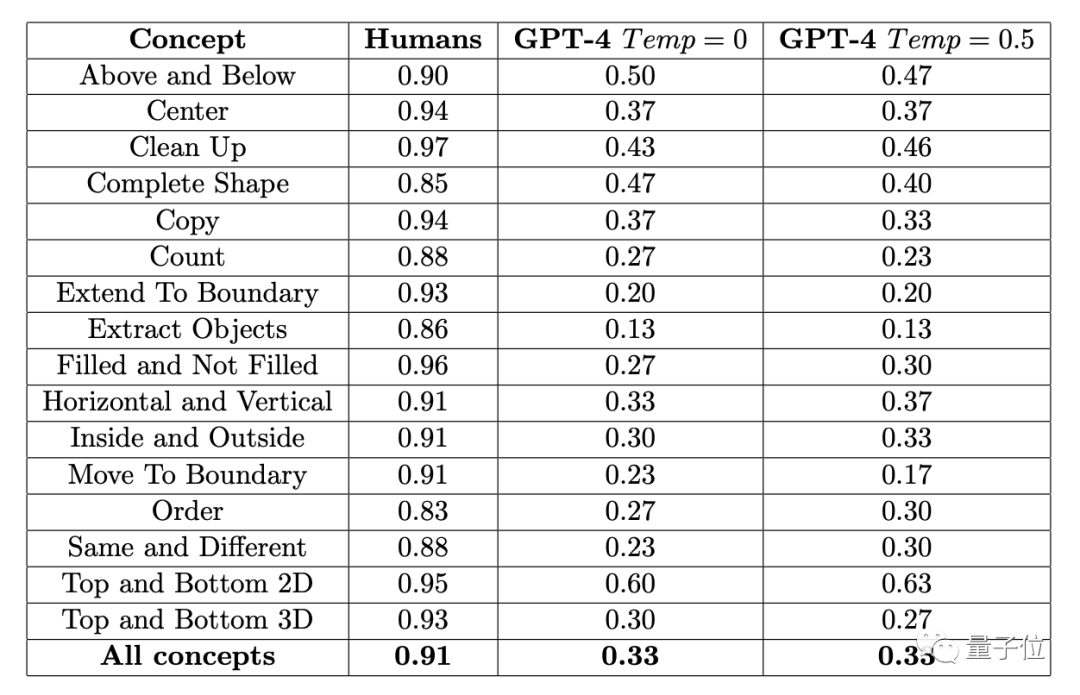
Matin Il y a quelque temps, l'auteur de ConceptARC Benchmark impliqué dans cette expérience a également mené une expérience similaire, mais le test sur échantillon zéro a été réalisé dans GPT-4. En conséquence, le taux de précision moyen de 16 tâches était. seulement 19 %.

GPT-4v est un modèle multimodal, mais sa précision est faible. Sur un ensemble de données ConceptARC à petite échelle composé de 48 questions, les taux de précision des tests sur échantillon nul et des tests sur échantillon unique n'étaient respectivement que de 25 % et 23 %

Après une analyse plus approfondie des mauvaises réponses, les chercheurs ont découvert Certaines erreurs humaines semblent susceptibles d'être causées par une "négligence", alors que GPT ne comprend pas du tout les règles de la question.
La plupart des internautes n'ont aucun doute sur ces données, mais ce qui a remis en question cette expérience, c'est le groupe de sujets recrutés et la méthode de saisie fournie à GPT
La méthode de sélection des sujets a été remise en question
Au début, les participants à la recherche recrutés sujets sur une plateforme de crowdsourcing Amazon.
Le chercheur a extrait quelques questions simples de l'ensemble de données en guise de test d'introduction. Les sujets doivent répondre correctement à au moins deux des trois questions aléatoires avant de passer le test formel.
Les résultats trouvés par les chercheurs montrent que certaines personnes ne passent le test d'entrée que dans le but d'être avides d'argent et ne répondent pas du tout aux questions comme requis
En dernier recours, le chercheuraugmente le seuil d'admission le testau point qu'il peut être réalisé sur la plateforme. Réussissez pas moins de 2 000 tâches, et le taux de réussite doit atteindre 99 %.
Cependant, bien que l'auteur utilise le taux de réussite pour sélectionner les personnes, en termes de capacités spécifiques, outre la nécessité pour les sujets de connaître l'anglais, il n'y a « aucune exigence particulière » pour d'autres capacités professionnelles telles que le graphisme.
Pour parvenir à la diversité des données, les chercheurs ont déplacé leurs efforts de recrutement vers une autre plateforme de crowdsourcing plus tard dans l'expérience. Au final, un total de 415 sujets ont participé à cette expérience
Cependant, certaines personnes se demandaient encore si les échantillons de l'expérience n'étaient "pas assez aléatoires".

Certains internautes ont souligné que sur la plateforme de crowdsourcing Amazon utilisée par les chercheurs pour recruter des sujets, il y a de grands modèles se faisant passer pour des humains.
Le fonctionnement de la version multimodale de GPT est relativement simple, il suffit de transmettre directement l'image et d'utiliser le mot d'invite correspondant
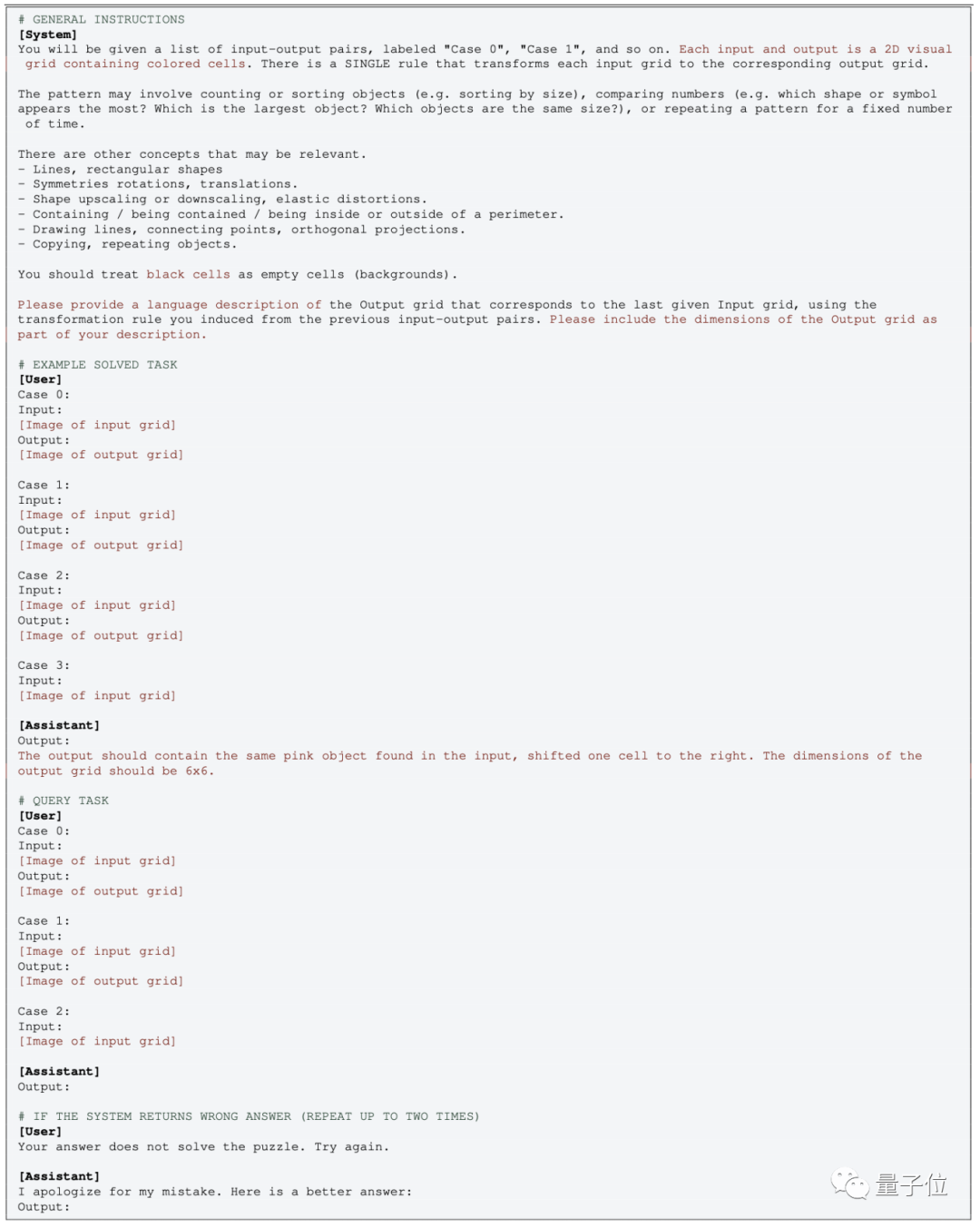
Dans le test à échantillon zéro, supprimez simplement la partie EXEMPLE correspondante
Mais pour la version en texte brut de GPT-4 (0613) sans multimodalité, l'image doit être convertie en points de grille et utiliser des nombres au lieu de couleurs.
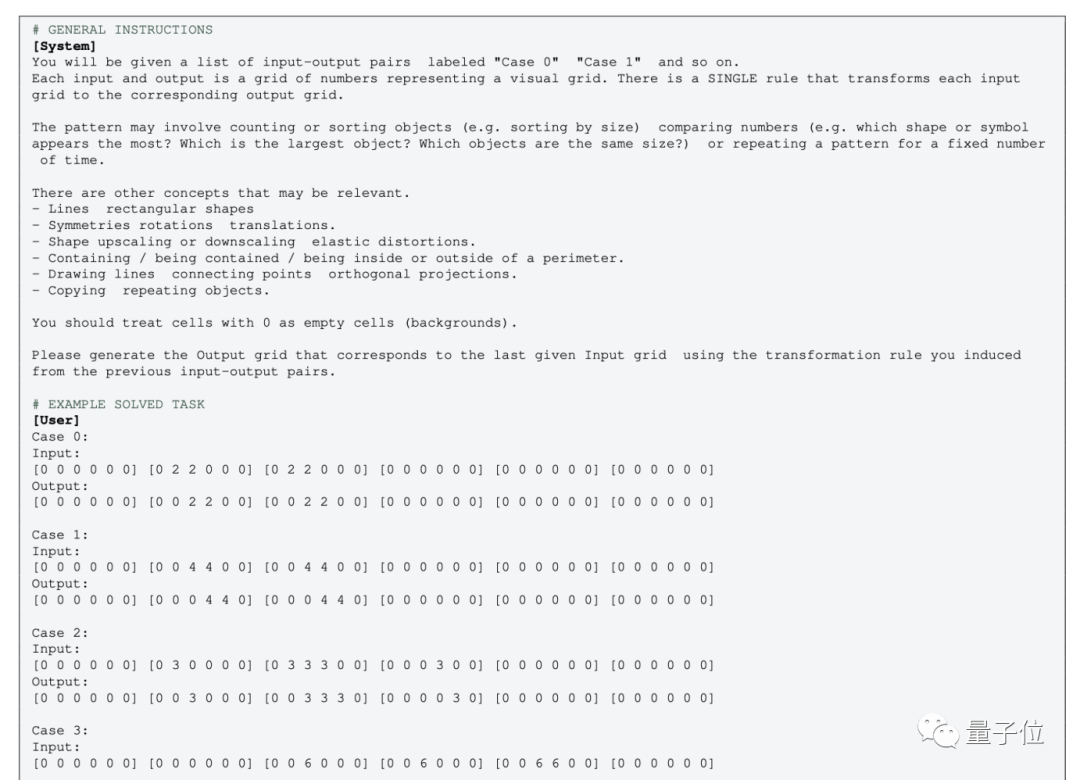
Certaines personnes ne sont pas d'accord avec cette opération :
Après avoir converti l'image en matrice numérique, le concept a complètement changé Même les humains, en regardant des "graphiques" représentés par des nombres, puis-je ne pas le faire. comprenez-le non plus

Encore une chose
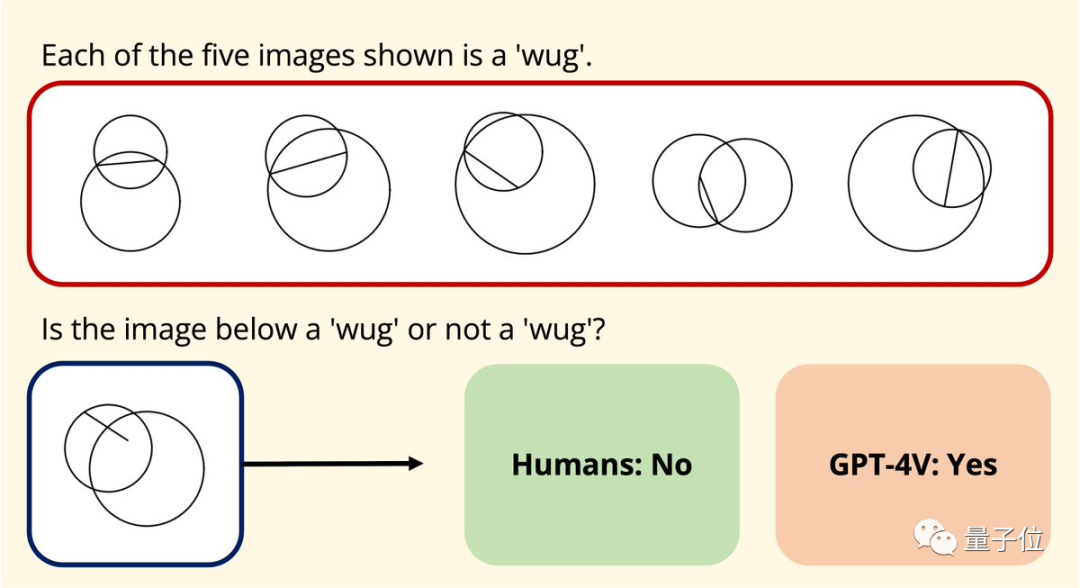
Par coïncidence, Joy Hsu, une doctorante chinoise à l'Université de Stanford, a également testé la capacité de compréhension graphique de GPT-4v sur un ensemble de données géométriques
L'année dernière, un ensemble de données a été publié visant à tester votre compréhension de la géométrie euclidienne avec de grands modèles. Après l'ouverture de GPT-4v, Hsu a utilisé l'ensemble de données pour le tester à nouveau
et a découvert que la façon dont GPT-4v comprend les graphiques semble être "complètement différente de celle des humains".
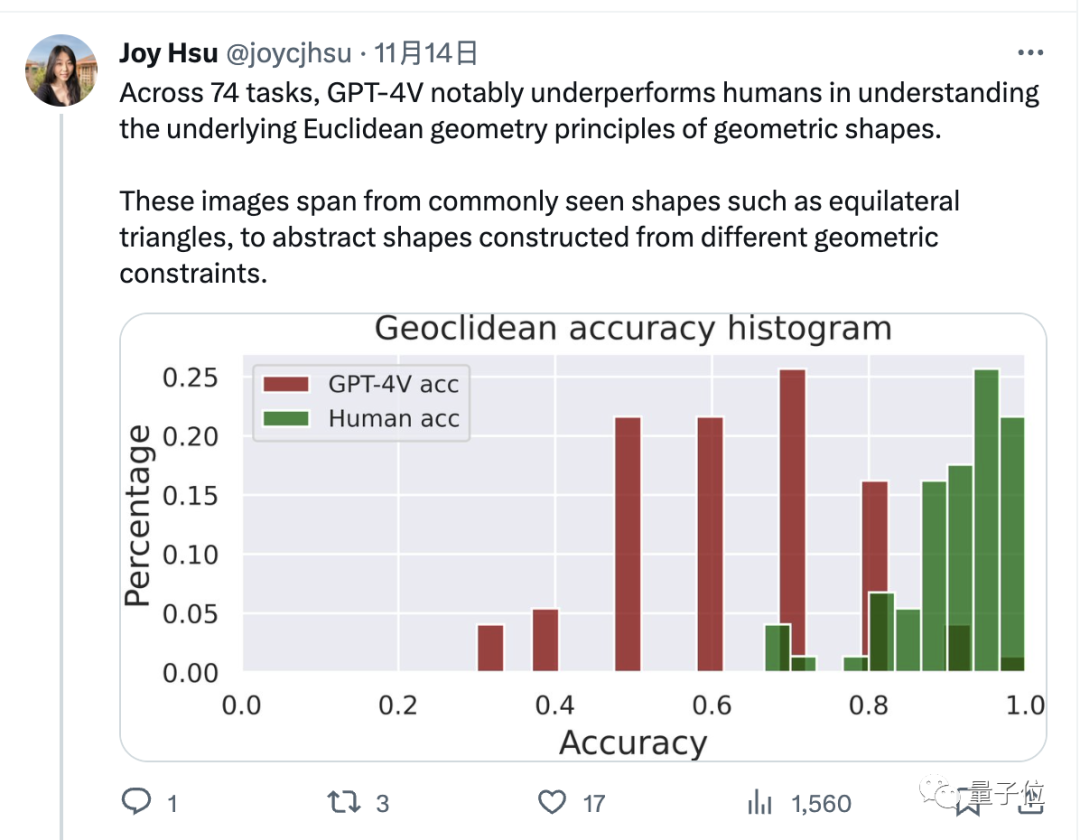
En termes de données, GPT-4v est évidemment inférieur aux humains pour répondre à ces questions géométriques
Adresse papier :
[1]https://arxiv.org/abs/2305.07141
[2 ]https://arxiv.org/abs/2311.09247
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.
Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment implémenter le tri des fichiers par Debian Readdir
Apr 13, 2025 am 09:06 AM
Comment implémenter le tri des fichiers par Debian Readdir
Apr 13, 2025 am 09:06 AM
Dans Debian Systems, la fonction ReadDir est utilisée pour lire le contenu du répertoire, mais l'ordre dans lequel il revient n'est pas prédéfini. Pour trier les fichiers dans un répertoire, vous devez d'abord lire tous les fichiers, puis les trier à l'aide de la fonction QSORT. Le code suivant montre comment trier les fichiers de répertoire à l'aide de ReadDir et QSort dans Debian System: # include # include # include # include # include // Fonction de comparaison personnalisée, utilisée pour qsortintCompare (constvoid * a, constvoid * b) {returnstrcmp (* (
 Comment optimiser les performances de Debian Readdir
Apr 13, 2025 am 08:48 AM
Comment optimiser les performances de Debian Readdir
Apr 13, 2025 am 08:48 AM
Dans Debian Systems, les appels du système ReadDir sont utilisés pour lire le contenu des répertoires. Si ses performances ne sont pas bonnes, essayez la stratégie d'optimisation suivante: simplifiez le nombre de fichiers d'annuaire: divisez les grands répertoires en plusieurs petits répertoires autant que possible, en réduisant le nombre d'éléments traités par appel ReadDir. Activer la mise en cache de contenu du répertoire: construire un mécanisme de cache, mettre à jour le cache régulièrement ou lorsque le contenu du répertoire change et réduire les appels fréquents à Readdir. Les caches de mémoire (telles que Memcached ou Redis) ou les caches locales (telles que les fichiers ou les bases de données) peuvent être prises en compte. Adoptez une structure de données efficace: si vous implémentez vous-même la traversée du répertoire, sélectionnez des structures de données plus efficaces (telles que les tables de hachage au lieu de la recherche linéaire) pour stocker et accéder aux informations du répertoire
 Comment Debian Readdir s'intègre à d'autres outils
Apr 13, 2025 am 09:42 AM
Comment Debian Readdir s'intègre à d'autres outils
Apr 13, 2025 am 09:42 AM
La fonction ReadDir dans le système Debian est un appel système utilisé pour lire le contenu des répertoires et est souvent utilisé dans la programmation C. Cet article expliquera comment intégrer ReadDir avec d'autres outils pour améliorer sa fonctionnalité. Méthode 1: combinant d'abord le programme de langue C et le pipeline, écrivez un programme C pour appeler la fonction readdir et sortir le résultat: # include # include # include # includeIntmain (intargc, char * argv []) {dir * dir; structDirent * entrée; if (argc! = 2) {
 Conseils de configuration du pare-feu Debian Mail Server
Apr 13, 2025 am 11:42 AM
Conseils de configuration du pare-feu Debian Mail Server
Apr 13, 2025 am 11:42 AM
La configuration du pare-feu d'un serveur de courrier Debian est une étape importante pour assurer la sécurité du serveur. Voici plusieurs méthodes de configuration de pare-feu couramment utilisées, y compris l'utilisation d'iptables et de pare-feu. Utilisez les iptables pour configurer le pare-feu pour installer iptables (sinon déjà installé): Sudoapt-getUpDaSuDoapt-getinstalliptableView Règles actuelles iptables: Sudoiptable-L Configuration
 Comment apprendre Debian Syslog
Apr 13, 2025 am 11:51 AM
Comment apprendre Debian Syslog
Apr 13, 2025 am 11:51 AM
Ce guide vous guidera pour apprendre à utiliser Syslog dans Debian Systems. Syslog est un service clé dans les systèmes Linux pour les messages du système de journalisation et du journal d'application. Il aide les administrateurs à surveiller et à analyser l'activité du système pour identifier et résoudre rapidement les problèmes. 1. Connaissance de base de Syslog Les fonctions principales de Syslog comprennent: la collecte et la gestion des messages journaux de manière centralisée; Prise en charge de plusieurs formats de sortie de journal et des emplacements cibles (tels que les fichiers ou les réseaux); Fournir des fonctions de visualisation et de filtrage des journaux en temps réel. 2. Installer et configurer syslog (en utilisant RSYSLOG) Le système Debian utilise RSYSLOG par défaut. Vous pouvez l'installer avec la commande suivante: SudoaptupDatesud
 Comment configurer les règles de pare-feu pour Debian Syslog
Apr 13, 2025 am 06:51 AM
Comment configurer les règles de pare-feu pour Debian Syslog
Apr 13, 2025 am 06:51 AM
Cet article décrit comment configurer les règles de pare-feu à l'aide d'iptables ou UFW dans Debian Systems et d'utiliser Syslog pour enregistrer les activités de pare-feu. Méthode 1: Utiliser iptableIpTable est un puissant outil de pare-feu de ligne de commande dans Debian System. Afficher les règles existantes: utilisez la commande suivante pour afficher les règles iptables actuelles: Sudoiptables-L-N-V permet un accès IP spécifique: Par exemple, permettez l'adresse IP 192.168.1.100 pour accéder au port 80: Sudoiptables-Ainput-PTCP - DPORT80-S192.16
 Comment définir le niveau de journal Debian Apache
Apr 13, 2025 am 08:33 AM
Comment définir le niveau de journal Debian Apache
Apr 13, 2025 am 08:33 AM
Cet article décrit comment ajuster le niveau de journalisation du serveur Apacheweb dans le système Debian. En modifiant le fichier de configuration, vous pouvez contrôler le niveau verbeux des informations de journal enregistrées par Apache. Méthode 1: Modifiez le fichier de configuration principal pour localiser le fichier de configuration: le fichier de configuration d'Apache2.x est généralement situé dans le répertoire / etc / apache2 /. Le nom de fichier peut être apache2.conf ou httpd.conf, selon votre méthode d'installation. Modifier le fichier de configuration: Ouvrez le fichier de configuration avec les autorisations racine à l'aide d'un éditeur de texte (comme Nano): Sutonano / etc / apache2 / apache2.conf
 Comment Debian OpenSSL empêche les attaques de l'homme au milieu
Apr 13, 2025 am 10:30 AM
Comment Debian OpenSSL empêche les attaques de l'homme au milieu
Apr 13, 2025 am 10:30 AM
Dans Debian Systems, OpenSSL est une bibliothèque importante pour le chiffrement, le décryptage et la gestion des certificats. Pour empêcher une attaque d'homme dans le milieu (MITM), les mesures suivantes peuvent être prises: utilisez HTTPS: assurez-vous que toutes les demandes de réseau utilisent le protocole HTTPS au lieu de HTTP. HTTPS utilise TLS (Protocole de sécurité de la couche de transport) pour chiffrer les données de communication pour garantir que les données ne sont pas volées ou falsifiées pendant la transmission. Vérifiez le certificat de serveur: vérifiez manuellement le certificat de serveur sur le client pour vous assurer qu'il est digne de confiance. Le serveur peut être vérifié manuellement via la méthode du délégué d'URLSession
