

L'objectif principal de cet article est le concept et la théorie de RAG. Ensuite, nous montrerons comment utiliser LangChain, le modèle de langage OpenAI et la base de données vectorielles Weaviate pour implémenter un système d'orchestration RAG simple
Le concept de Retrieval Augmented Generation (RAG) fait référence à la fourniture d'informations supplémentaires au LLM via des sources de connaissances externes. Cela permet à LLM de générer des réponses plus précises et contextuelles tout en réduisant les hallucinations.
Lors de la réécriture du contenu, le texte original doit être réécrit en chinois sans la phrase originale
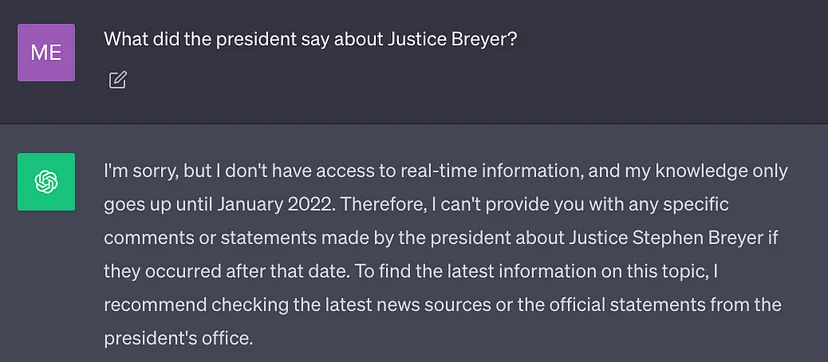
Le meilleur LLM actuel est formé à l'aide d'une grande quantité de données, de sorte que ses poids de réseau neuronal sont stockés dans A beaucoup de connaissances générales (mémoire de paramètres). Cependant, si l'invite demande à LLM de générer des résultats qui nécessitent des connaissances autres que ses données de formation (telles que de nouvelles informations, des données exclusives ou des informations spécifiques à un domaine), des inexactitudes factuelles peuvent survenir lors de la réécriture du contenu, vous devez le texte original. a été réécrit en chinois sans la phrase originale (illusion), comme le montre la capture d'écran ci-dessous :
Par conséquent, il est important de combiner les connaissances générales du LLM avec un contexte supplémentaire afin de générer des plus Résultats contextuels et hallucinations réduites
Solution
Traditionnellement, nous pouvons adapter les réseaux de neurones à des domaines spécifiques ou à des informations propriétaires en affinant le modèle. Bien que cette technique soit efficace, elle nécessite de grandes quantités de ressources informatiques, est coûteuse et nécessite le soutien d'experts techniques, ce qui rend difficile une adaptation rapide à l'évolution des informations
En 2020, l'article de Lewis et al. "Retrieval " -Augmented Generation for Knowledge-Intensive NLP Tasks" propose une technologie plus flexible : Retrieval Enhanced Generation (RAG). Dans cet article, les chercheurs combinent le modèle génératif avec un module de récupération pouvant fournir des informations supplémentaires à l’aide d’une source de connaissances externe plus facilement mise à jour.
Pour le dire en langue vernaculaire : RAG est au LLM ce que l'examen à livre ouvert est aux humains. Pour les examens à livre ouvert, les étudiants peuvent apporter du matériel de référence tel que des manuels et des notes où ils peuvent trouver des informations pertinentes pour répondre aux questions. L'idée derrière les examens à livre ouvert est que l'examen se concentre sur la capacité des étudiants à raisonner plutôt que sur leur capacité à mémoriser des informations spécifiques.
De même, les connaissances de facto sont distinctes des capacités d'inférence LLM et peuvent être stockées dans des sources de connaissances externes qui sont facilement accessibles et mises à jour
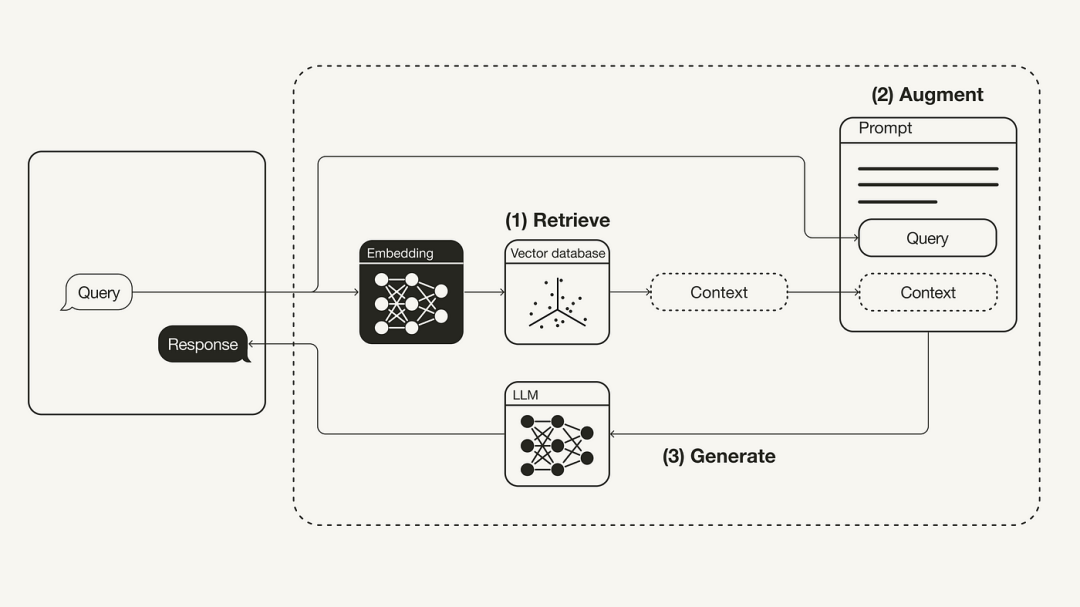
Le diagramme suivant montre le flux de travail RAG le plus basique :
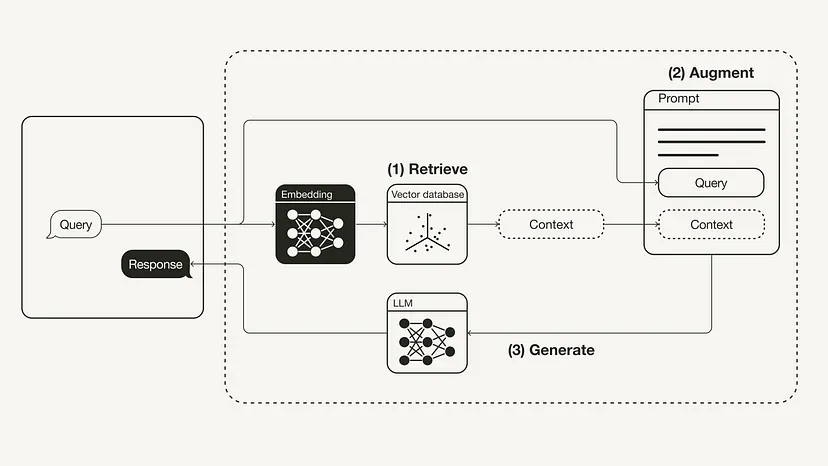
Contenu réécrit : reconstruction du flux de travail de génération augmentée de récupération (RAG)
Ce qui suit présentera comment implémenter le flux de travail RAG via Python, qui utilisera la base de données vectorielles OpenAI LLM et Weaviate et un modèle d'intégration OpenAI. Le rôle de LangChain est l’orchestration.
Veuillez reformuler : Prérequis requis
Veuillez vous assurer que les packages Python requis sont installés :
#!pip install langchain openai weaviate-client
De plus, utilisez un fichier .env dans le répertoire racine pour définir les variables d'environnement pertinentes. Vous avez besoin d'un compte OpenAI pour obtenir la clé API OpenAI, puis de "Créer une nouvelle clé" dans Clés API (https://platform.openai.com/account/api-keys).
OPENAI_API_KEY="<your_openai_api_key>"</your_openai_api_key>
Ensuite, exécutez la commande suivante pour charger les variables d'environnement pertinentes.
import dotenvdotenv.load_dotenv()
Préparation
Dans la phase de préparation, vous devez préparer une base de données vectorielles en tant que source de connaissances externe pour enregistrer toutes les informations supplémentaires. La construction de cette base de données vectorielles comprend les étapes suivantes :
Le contenu réécrit : Tout d'abord, il nous faut pour collecter et charger les données. À titre d’exemple, si nous souhaitons utiliser le discours sur l’état de l’Union 2022 du président Biden comme contexte supplémentaire, le référentiel GitHub de LangChain fournit le document texte original de ce fichier. Afin de charger ces données, nous pouvons profiter des différents outils de chargement de documents intégrés de LangChain. Un document est un dictionnaire composé de texte et de métadonnées. Pour charger du texte, vous pouvez utiliser l'outil TextLoader de LangChain
Adresse originale du document : https://raw.githubusercontent.com/langchain-ai/langchain/master/docs/docs/modules/state_of_the_union.txt
import requestsfrom langchain.document_loaders import TextLoaderurl = "https://raw.githubusercontent.com/langchain-ai/langchain/master/docs/docs/modules/state_of_the_union.txt"res = requests.get(url)with open("state_of_the_union.txt", "w") as f:f.write(res.text)loader = TextLoader('./state_of_the_union.txt')documents = loader.load()Ensuite, divisez le document en morceaux. Étant donné que l'état original du document est trop long pour tenir dans la fenêtre contextuelle de LLM, il doit être divisé en morceaux de texte plus petits. LangChain dispose également de nombreux outils de fractionnement intégrés. Pour cet exemple simple, nous pouvons utiliser un CharacterTextSplitter avec chunk_size défini sur 500 et chunk_overlap défini sur 50, qui maintient la continuité du texte entre les morceaux de texte.
from langchain.text_splitter import CharacterTextSplittertext_splitter = CharacterTextSplitter(chunk_size=500, chunk_overlap=50)chunks = text_splitter.split_documents(documents)
Enfin, intégrez le bloc de texte et enregistrez-le. Pour que la recherche sémantique soit effectuée dans les blocs de texte, des intégrations vectorielles doivent être générées pour chaque bloc de texte et enregistrées avec leurs intégrations. Pour générer des intégrations vectorielles, utilisez le modèle d'intégration OpenAI ; pour le stockage, utilisez la base de données vectorielles Weaviate. Des blocs de texte peuvent être automatiquement renseignés dans une base de données vectorielles en appelant .from_documents().
from langchain.embeddings import OpenAIEmbeddingsfrom langchain.vectorstores import Weaviateimport weaviatefrom weaviate.embedded import EmbeddedOptionsclient = weaviate.Client(embedded_options = EmbeddedOptions())vectorstore = Weaviate.from_documents(client = client,documents = chunks,embedding = OpenAIEmbeddings(),by_text = False)
Étape 1 : Récupérer
Après avoir rempli la base de données vectorielle, nous pouvons la définir comme un composant de récupération qui peut être récupéré en fonction de la similarité sémantique entre la requête utilisateur et le bloc intégré. Contexte supplémentaire
retriever = vectorstore.as_retriever()
Étape 2 : Améliorer
from langchain.prompts import ChatPromptTemplatetemplate = """You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.Question: {question} Context: {context} Answer:"""prompt = ChatPromptTemplate.from_template(template)print(prompt)Ensuite, afin d'améliorer l'invite avec un contexte supplémentaire, vous devez préparer un modèle d'invite. Comme indiqué ci-dessous, l'invite peut être facilement personnalisée à l'aide d'un modèle d'invite.
Étape 3 : Générer
Enfin, nous pouvons créer une chaîne de pensée pour ce processus RAG qui relie le récupérateur, le modèle d'invite et le LLM. Une fois la chaîne RAG définie, elle peut être appelée
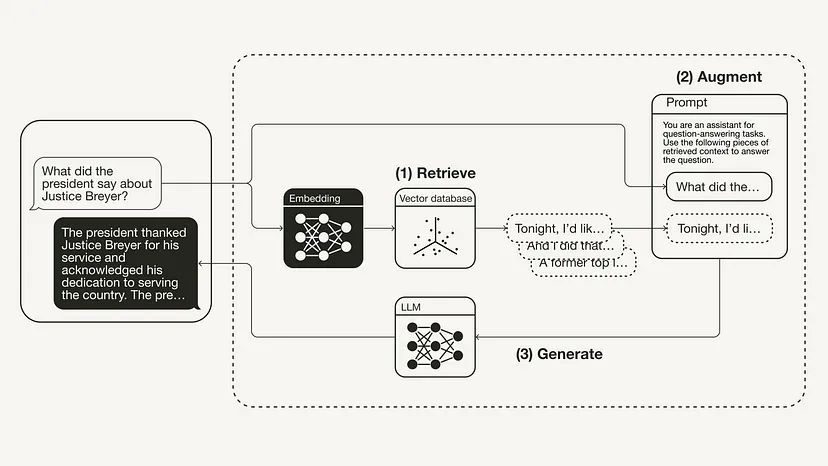
from langchain.chat_models import ChatOpenAIfrom langchain.schema.runnable import RunnablePassthroughfrom langchain.schema.output_parser import StrOutputParserllm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)rag_chain = ({"context": retriever,"question": RunnablePassthrough()} | prompt | llm| StrOutputParser() )query = "What did the president say about Justice Breyer"rag_chain.invoke(query)"The president thanked Justice Breyer for his service and acknowledged his dedication to serving the country. The president also mentioned that he nominated Judge Ketanji Brown Jackson as a successor to continue Justice Breyer's legacy of excellence."La figure suivante montre le processus RAG pour cet exemple spécifique :
Cet article présente le concept de RAG, qui provient à l'origine de l'article de 2020 « Génération augmentée de récupération pour les tâches PNL à forte intensité de connaissances ». Après avoir présenté la théorie derrière RAG, y compris la motivation et les solutions, cet article montre comment l'implémenter en Python. Cet article montre comment implémenter un workflow RAG à l'aide d'OpenAI LLM couplé à la base de données vectorielles Weaviate et au modèle d'intégration OpenAI. Le rôle de LangChain est l’orchestration.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment acheter et vendre du Bitcoin sur la plateforme Ouyi
Comment acheter et vendre du Bitcoin sur la plateforme Ouyi
 utilisation de la fonction informix
utilisation de la fonction informix
 Comment utiliser la fonction max
Comment utiliser la fonction max
 Il existe plusieurs façons de positionner la position CSS
Il existe plusieurs façons de positionner la position CSS
 Comment utiliser la recherche magnétique BTbook
Comment utiliser la recherche magnétique BTbook
 Comment ouvrir les fichiers psd
Comment ouvrir les fichiers psd
 Tutoriel sur la structure des données et l'algorithme
Tutoriel sur la structure des données et l'algorithme
 Comment mettre à jour le pilote de la carte graphique
Comment mettre à jour le pilote de la carte graphique
 suffixe de boîte aux lettres Google
suffixe de boîte aux lettres Google








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



