
 Périphériques technologiques
IA
La diffusion vidéo stable est là, le poids du code est en ligne
Périphériques technologiques
IA
La diffusion vidéo stable est là, le poids du code est en ligne
La diffusion vidéo stable est là, le poids du code est en ligne

Stability AI, une société de dessin d'IA bien connue, est enfin entrée dans l'industrie de la vidéo générée par l'IA.
Ce mardi, Stable Video Diffusion, un modèle de génération vidéo basé sur une diffusion stable, a été lancé, et la communauté de l'IA a immédiatement lancé une discussion
Beaucoup de gens ont dit "Nous avons finalement attendu."
Lien du projet : https://github.com/Stability-AI/generative-models
Vous pouvez désormais utiliser des images statiques existantes pour générer quelques secondes de vidéo
basé sur la stabilité Le modèle graphique Stable Diffusion original d'AI, Stable Video Diffusion, est devenu l'un des rares modèles de génération vidéo dans les rangs open source ou commerciaux.


Mais il n'est pas encore accessible à tout le monde, Stable Video Diffusion a ouvert l'inscription des utilisateurs sur liste d'attente (https://stability.ai/contact).
Selon l'introduction, la propagation vidéo stable peut être facilement adaptée à une variété de tâches en aval, y compris la synthèse multi-vues à partir d'une seule image en affinant les ensembles de données multi-vues. Stable AI a déclaré que divers modèles sont prévus pour construire et étendre cette fondation, similaire à l'écosystème construit autour de la diffusion stable


via une vidéo stable, qui peut se propager de 3 à 30 fois par seconde Cadre personnalisable le taux d'images génère des vidéos de 14 et 25 images
Lors d'évaluations externes, Stability AI a confirmé que ces modèles surpassaient les principaux modèles fermés dans la recherche sur les préférences des utilisateurs :

Stability AI Il est souligné que Stable La diffusion vidéo n'est pas adaptée aux applications réelles ou commerciales directes à ce stade, et le modèle sera amélioré en fonction des informations et des commentaires des utilisateurs sur la sécurité et la qualité.

Adresse papier : https://stability.ai/research/stable-video-diffusion-scaling-latent-video-diffusion-models-to-large-datasets
La transmission vidéo stable est A membre de la famille de modèles open source AI stable. Il semble désormais que leurs produits couvrent de multiples modalités telles que les images, le langage, l'audio, la 3D et le code, ce qui prouve pleinement leur engagement à améliorer l'intelligence artificielle
Stable L'aspect technique de la diffusion vidéo
Stable Comme potentiel Modèle de diffusion pour les vidéos haute résolution, le modèle de diffusion vidéo a atteint le niveau SOTA de texte en vidéo ou d'image en vidéo. Récemment, des modèles de diffusion latente entraînés pour la synthèse d'images 2D ont été transformés en modèles vidéo génératifs en insérant des couches temporelles et en les affinant sur de petits ensembles de données vidéo de haute qualité. Cependant, les méthodes de formation varient considérablement dans la littérature, et le domaine n'a pas encore convenu d'une stratégie unifiée pour la curation des données vidéo
Dans l'article Stable Video Diffusion, Stability AI identifie et évalue trois étapes distinctes pour une formation réussie de la vidéo latente. modèles de diffusion : Pré-formation texte-image, pré-formation vidéo et mise au point vidéo haute qualité. Ils démontrent également l'importance d'ensembles de données de pré-formation soigneusement préparés pour générer des vidéos de haute qualité et décrivent un processus de curation systématique pour former un modèle de base solide, comprenant des sous-titres et des stratégies de filtrage.
Stability AI explore également dans l'article l'impact du réglage fin du modèle de base sur des données de haute qualité et forme un modèle texte-vidéo comparable à la génération de vidéo à source fermée. Le modèle fournit une représentation de mouvement puissante pour les tâches en aval telles que la génération d'image en vidéo et l'adaptabilité aux modules LoRA spécifiques au mouvement de la caméra. En outre, le modèle peut également fournir un puissant a priori 3D multi-vues, qui peut être utilisé comme base d'un modèle de diffusion multi-vues. Le modèle génère plusieurs vues d'un objet de manière anticipée, ne nécessitant qu'un petit calcul. exigences de puissance et performances Surclasse également les méthodes basées sur l'image .

Plus précisément, réussir la formation de ce modèle nécessite les trois étapes suivantes :
Phase 1 : Pré-formation de l'image. Cet article considère la pré-formation des images comme la première étape du pipeline de formation et construit le modèle initial sur Stable Diffusion 2.1, équipant ainsi le modèle vidéo d'une représentation visuelle puissante. Afin d'analyser l'effet du pré-entraînement d'image, cet article entraîne et compare également deux modèles vidéo identiques. Les résultats de la figure 3a montrent que le modèle d'image pré-entraîné est préféré en termes de qualité et de suivi des signaux.
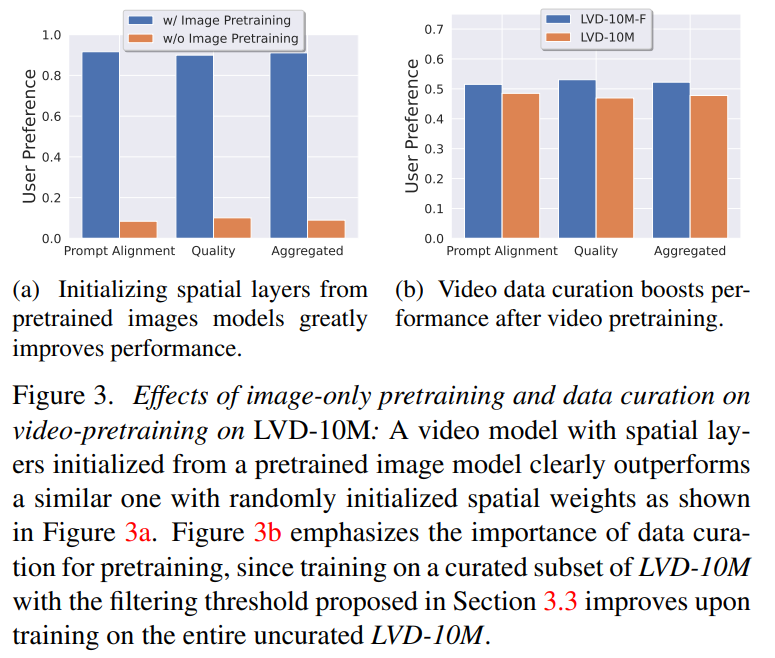
Phase 2 : Ensemble de données vidéo de pré-entraînement. Cet article s'appuie sur les préférences humaines comme signaux pour créer des ensembles de données de pré-entraînement appropriés. L'ensemble de données créé dans cet article est LVD (Large Video Dataset), qui se compose de 580 millions de paires de clips vidéo annotés.
Une enquête plus approfondie a révélé que l'ensemble de données généré contenait des exemples susceptibles de dégrader les performances du modèle vidéo final. Par conséquent, dans cet article, nous utilisons un flux optique dense pour annoter l'ensemble de données
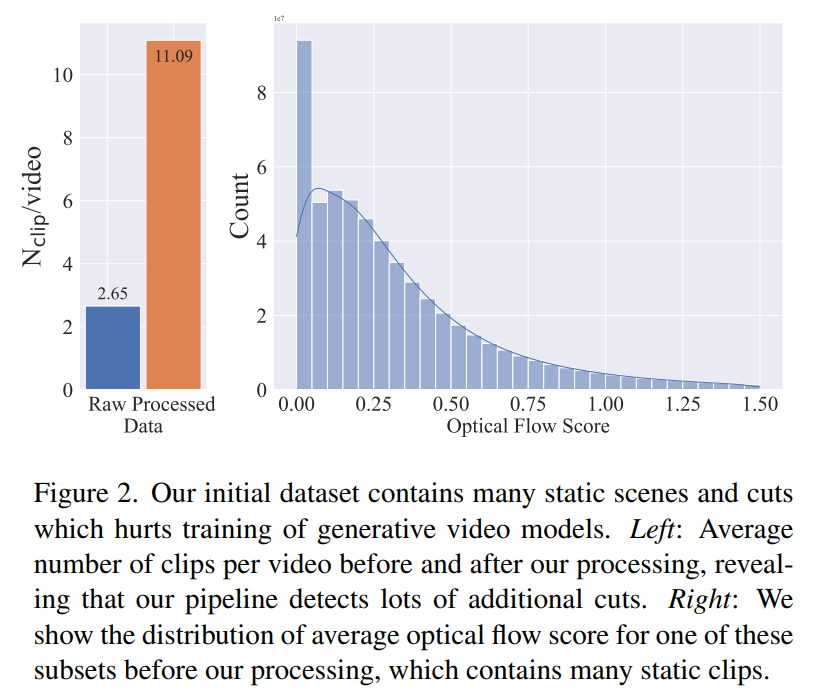
De plus, cet article applique également la reconnaissance optique de caractères pour nettoyer les clips contenant une grande quantité de texte. Enfin, nous utilisons les intégrations CLIP pour annoter les première, centrale et dernière images de chaque clip. Le tableau suivant fournit quelques statistiques sur l'ensemble de données LVD :
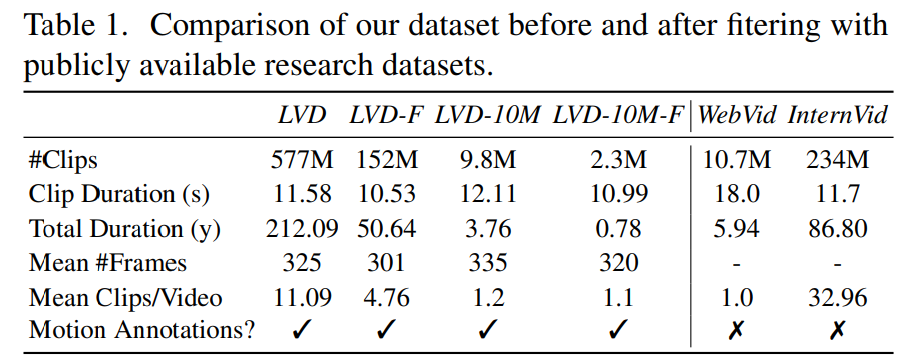
Phase 3 : Réglage fin de haute qualité. Pour analyser l'impact de la pré-formation vidéo sur l'étape finale, cet article affine trois modèles qui ne diffèrent que par l'initialisation. La figure 4e montre les résultats.

On dirait que c'est un bon début. Quand pourrons-nous utiliser l’IA pour générer directement un film ?
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 phpmyadmin crée un tableau de données
Apr 10, 2025 pm 11:00 PM
phpmyadmin crée un tableau de données
Apr 10, 2025 pm 11:00 PM
Pour créer un tableau de données à l'aide de PhpMyAdmin, les étapes suivantes sont essentielles: connectez-vous à la base de données et cliquez sur le nouvel onglet. Nommez le tableau et sélectionnez le moteur de stockage (InnODB recommandé). Ajouter les détails de la colonne en cliquant sur le bouton Ajouter une colonne, y compris le nom de la colonne, le type de données, s'il faut autoriser les valeurs nuls et d'autres propriétés. Sélectionnez une ou plusieurs colonnes comme clés principales. Cliquez sur le bouton Enregistrer pour créer des tables et des colonnes.
 Comment créer une base de données Oracle Comment créer une base de données Oracle
Apr 11, 2025 pm 02:33 PM
Comment créer une base de données Oracle Comment créer une base de données Oracle
Apr 11, 2025 pm 02:33 PM
La création d'une base de données Oracle n'est pas facile, vous devez comprendre le mécanisme sous-jacent. 1. Vous devez comprendre les concepts de la base de données et des SGBD Oracle; 2. Master les concepts de base tels que SID, CDB (base de données de conteneurs), PDB (base de données enfichable); 3. Utilisez SQL * Plus pour créer CDB, puis créer PDB, vous devez spécifier des paramètres tels que la taille, le nombre de fichiers de données et les chemins; 4. Les applications avancées doivent ajuster le jeu de caractères, la mémoire et d'autres paramètres et effectuer un réglage des performances; 5. Faites attention à l'espace disque, aux autorisations et aux paramètres des paramètres, et surveillez et optimisez en continu les performances de la base de données. Ce n'est qu'en le maîtrisant habilement une pratique continue que vous pouvez vraiment comprendre la création et la gestion des bases de données Oracle.
 Comment créer une base de données Oracle Comment créer une base de données Oracle
Apr 11, 2025 pm 02:36 PM
Comment créer une base de données Oracle Comment créer une base de données Oracle
Apr 11, 2025 pm 02:36 PM
Pour créer une base de données Oracle, la méthode commune consiste à utiliser l'outil graphique DBCA. Les étapes sont les suivantes: 1. Utilisez l'outil DBCA pour définir le nom DBN pour spécifier le nom de la base de données; 2. Définissez Syspassword et SystemPassword sur des mots de passe forts; 3. Définir les caractères et NationalCharacterset à Al32Utf8; 4. Définissez la taille de mémoire et les espaces de table pour s'ajuster en fonction des besoins réels; 5. Spécifiez le chemin du fichier log. Les méthodes avancées sont créées manuellement à l'aide de commandes SQL, mais sont plus complexes et sujets aux erreurs. Faites attention à la force du mot de passe, à la sélection du jeu de caractères, à la taille et à la mémoire de l'espace de table
 Comment rédiger des instructions de base de données Oracle
Apr 11, 2025 pm 02:42 PM
Comment rédiger des instructions de base de données Oracle
Apr 11, 2025 pm 02:42 PM
Le cœur des instructions Oracle SQL est sélectionné, insérer, mettre à jour et supprimer, ainsi que l'application flexible de diverses clauses. Il est crucial de comprendre le mécanisme d'exécution derrière l'instruction, tel que l'optimisation de l'indice. Les usages avancés comprennent des sous-requêtes, des requêtes de connexion, des fonctions d'analyse et PL / SQL. Les erreurs courantes incluent les erreurs de syntaxe, les problèmes de performances et les problèmes de cohérence des données. Les meilleures pratiques d'optimisation des performances impliquent d'utiliser des index appropriés, d'éviter la sélection *, d'optimiser les clauses et d'utiliser des variables liées. La maîtrise d'Oracle SQL nécessite de la pratique, y compris l'écriture de code, le débogage, la réflexion et la compréhension des mécanismes sous-jacents.
 Comment ajouter, modifier et supprimer le guide de fonctionnement du champ de table de données MySQL
Apr 11, 2025 pm 05:42 PM
Comment ajouter, modifier et supprimer le guide de fonctionnement du champ de table de données MySQL
Apr 11, 2025 pm 05:42 PM
Guide de fonctionnement du champ dans MySQL: Ajouter, modifier et supprimer les champs. Ajouter un champ: alter table table_name Ajouter Column_name data_type [pas null] [Default default_value] [Clé primaire] [Auto_increment] Modifier le champ: alter table table_name modifie Column_name data_type [pas null] [default default_value] [clé primaire]
 Explication détaillée des instances de requête imbriquées dans la base de données MySQL
Apr 11, 2025 pm 05:48 PM
Explication détaillée des instances de requête imbriquées dans la base de données MySQL
Apr 11, 2025 pm 05:48 PM
Les requêtes imbriquées sont un moyen d'inclure une autre requête dans une requête. Ils sont principalement utilisés pour récupérer des données qui remplissent des conditions complexes, associer plusieurs tables et calculer des valeurs de résumé ou des informations statistiques. Les exemples incluent la recherche de salaires supérieurs aux employés, la recherche de commandes pour une catégorie spécifique et le calcul du volume des commandes totales pour chaque produit. Lorsque vous écrivez des requêtes imbriquées, vous devez suivre: écrire des sous-requêtes, écrire leurs résultats sur les requêtes extérieures (référencées avec des alias ou en tant que clauses) et optimiser les performances de la requête (en utilisant des index).
 Quelles sont les contraintes d'intégrité des tables de base de données Oracle?
Apr 11, 2025 pm 03:42 PM
Quelles sont les contraintes d'intégrité des tables de base de données Oracle?
Apr 11, 2025 pm 03:42 PM
Les contraintes d'intégrité des bases de données Oracle peuvent garantir la précision des données, notamment: Not Null: les valeurs nulles sont interdites; Unique: garantie l'unicité, permettant une seule valeur nulle; Clé primaire: contrainte de clé primaire, renforcer unique et interdire les valeurs nulles; Clé étrangère: maintenir les relations entre les tableaux, les clés étrangères se réfèrent aux clés primaires primaires; Vérifiez: limitez les valeurs de colonne en fonction des conditions.
 Que fait Oracle
Apr 11, 2025 pm 06:06 PM
Que fait Oracle
Apr 11, 2025 pm 06:06 PM
Oracle est la plus grande société de logiciels de gestion de base de données au monde (SGBD). Ses principaux produits incluent les fonctions suivantes: Outils de développement du système de gestion de la base de données relationnels (Oracle Database) (Oracle Apex, Oracle Visual Builder) Middleware (Oracle Weblogic Server, Oracle Soa Suite) Cloud Service (Oracle Cloud Infrastructure) Analyse et Oracle Blockchain Pla Intelligence (Oracle Analytic
