
 Périphériques technologiques
IA
L'équipe PyTorch a réimplémenté le modèle « tout diviser » huit fois plus rapidement que l'implémentation d'origine.
Périphériques technologiques
IA
L'équipe PyTorch a réimplémenté le modèle « tout diviser » huit fois plus rapidement que l'implémentation d'origine.
L'équipe PyTorch a réimplémenté le modèle « tout diviser » huit fois plus rapidement que l'implémentation d'origine.

Depuis le début de l’année jusqu’à aujourd’hui, l’IA générative s’est développée rapidement. Mais souvent, nous sommes confrontés à un problème difficile : comment accélérer la formation, le raisonnement, etc. de l’IA générative, notamment lors de l’utilisation de PyTorch.
Dans cet article, les chercheurs de l'équipe PyTorch nous apportent une solution. L'article se concentre sur la façon d'utiliser PyTorch natif pur pour accélérer les modèles d'IA génératifs. Il présente également de nouvelles fonctionnalités de PyTorch et des exemples pratiques sur la façon de les combiner.
Quel a été le résultat ? L'équipe PyTorch a déclaré avoir réécrit le modèle « Split Everything » (SAM) de Meta, ce qui a abouti à un code 8 fois plus rapide que l'implémentation d'origine sans perte de précision, le tout optimisé à l'aide de PyTorch natif.

Adresse du blog : https://pytorch.org/blog/accelerating-generative-ai/
Après avoir lu cet article, vous obtiendrez la compréhension suivante :
- Torch compile. : Compilateur de modèles PyTorch, PyTorch 2.0 ajoute une nouvelle fonction appelée torch.compile (), qui peut accélérer les modèles existants avec une seule ligne de code
- Quantification GPU : accélère le modèle en réduisant la précision du calcul ; (Scaled Dot Product Attention) : une implémentation d'attention économe en mémoire ; } ensemble pour regrouper des données de taille non uniforme dans un seul tenseur, telles que des images de différentes tailles ;
- Opérations personnalisées Triton : utilisez Triton Python DSL pour écrire des opérations GPU et intégrez-les facilement dans divers composants de PyTorch via un opérateur personnalisé inscription.
- Les fonctionnalités natives de PyTorch apportent un débit accru et une réduction de la surcharge de mémoire.
- Pour plus d'informations sur cette recherche, veuillez vous référer au SAM proposé par Meta. Des articles détaillés peuvent être trouvés dans "Le CV n'existe plus ? Meta publie le modèle d'IA "Split Everything", le CV pourrait inaugurer le moment GPT-3"
Ensuite, nous présenterons le processus d'optimisation de SAM, y compris les performances Analyse, identification des goulots d'étranglement et comment intégrer ces nouvelles fonctionnalités dans PyTorch pour résoudre les problèmes rencontrés par SAM. De plus, nous présenterons également quelques nouvelles fonctionnalités de PyTorch, notamment torch.compile, SDPA, les noyaux Triton, Nested Tensor et la parcimonie semi-structurée (sparsité semi-structurée)
Le contenu sera approfondi couche par couche A la fin de cet article, nous présenterons la version rapide SAM. Pour les lecteurs intéressés, vous pouvez le télécharger depuis GitHub. De plus, ces données ont été visualisées à l'aide de Perfetto UI pour démontrer la valeur d'application de diverses fonctionnalités de PyTorch
Ce projet peut être trouvé à l'adresse GitHub : https://github.com/pytorch-labs/segment-anything-fast Le code source de 
réécrit le modèle divisé tout SAM
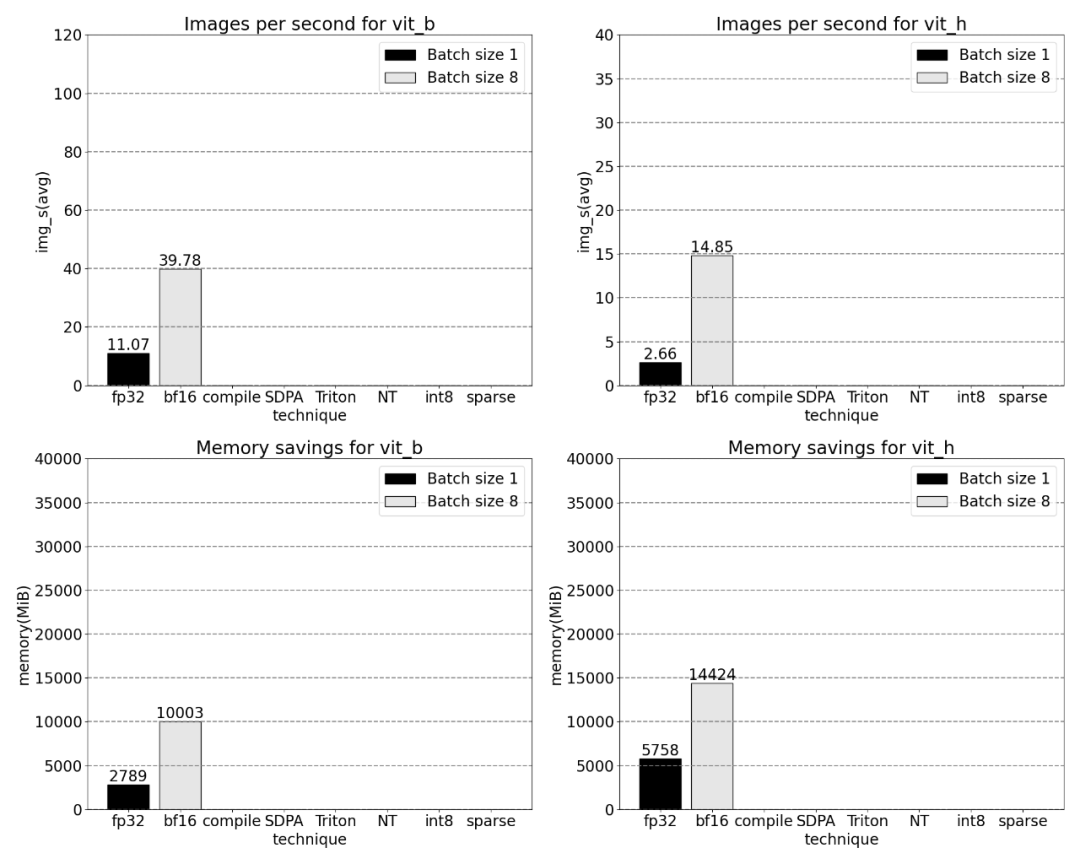
L'étude souligne que le type de données de base SAM utilisé dans cet article est de type float32, la taille du lot est de 1 et PyTorch Profiler est utilisé pour afficher le résultats du suivi de base Comme suit :
Cet article a révélé que SAM a deux emplacements qui peuvent être optimisés :
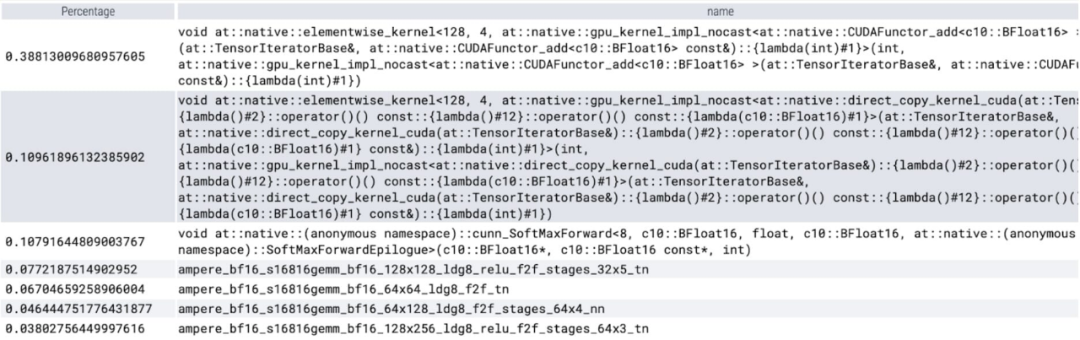
Le premier est le long appel à aten::index, qui est provoqué par le opération d'index tensoriel (telle que []) Causée par les appels sous-jacents générés. Cependant, le temps réel que le GPU passe sur aten::index est relativement faible. La raison en est que pendant le processus de démarrage de deux cœurs, aten::index bloque cudaStreamSynchronize entre les deux. Cela signifie que le CPU attend que le GPU termine le traitement jusqu'à ce que le deuxième cœur soit lancé. Par conséquent, afin d'optimiser SAM, cet article estime qu'il faut s'efforcer d'éliminer le blocage de la synchronisation GPU qui provoque des temps d'inactivité.
Le deuxième problème est que SAM passe beaucoup de temps GPU dans la multiplication matricielle (partie vert foncé comme indiqué sur l'image), ce qui est très courant dans le modèle Transformers. Si nous pouvons réduire le temps GPU du modèle SAM sur la multiplication matricielle, alors nous pouvons améliorer considérablement la vitesse de SAM
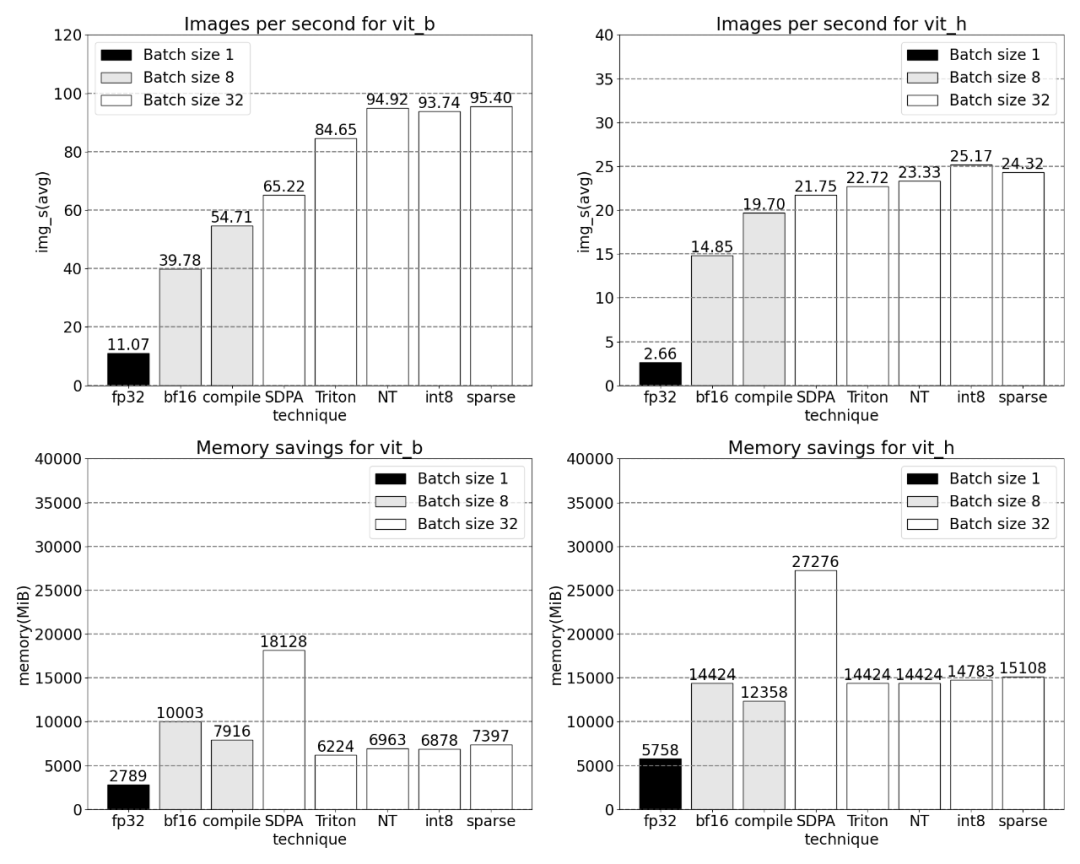
Ensuite, nous comparerons le débit (img/s) et la surcharge mémoire (GiB) de SAM Établir un ligne de base. Ensuite, il y a le processus d'optimisation
La phrase qui doit être réécrite est : Bfloat16 demi-précision (plus la synchronisation GPU et le traitement par lots)
Afin de résoudre le problème ci-dessus, cela c'est-à-dire réduire le nombre de multiplications matricielles nécessaires Temps, cet article se tourne vers bfloat16. bfloat16 est un type demi-précision couramment utilisé, qui peut économiser beaucoup de temps de calcul et de mémoire en réduisant la précision de chaque paramètre et activation

Remplacez le type de remplissage par bfloat16
In De plus, cet article a révélé qu'il existe deux endroits qui peuvent être optimisés pour supprimer la synchronisation GPU


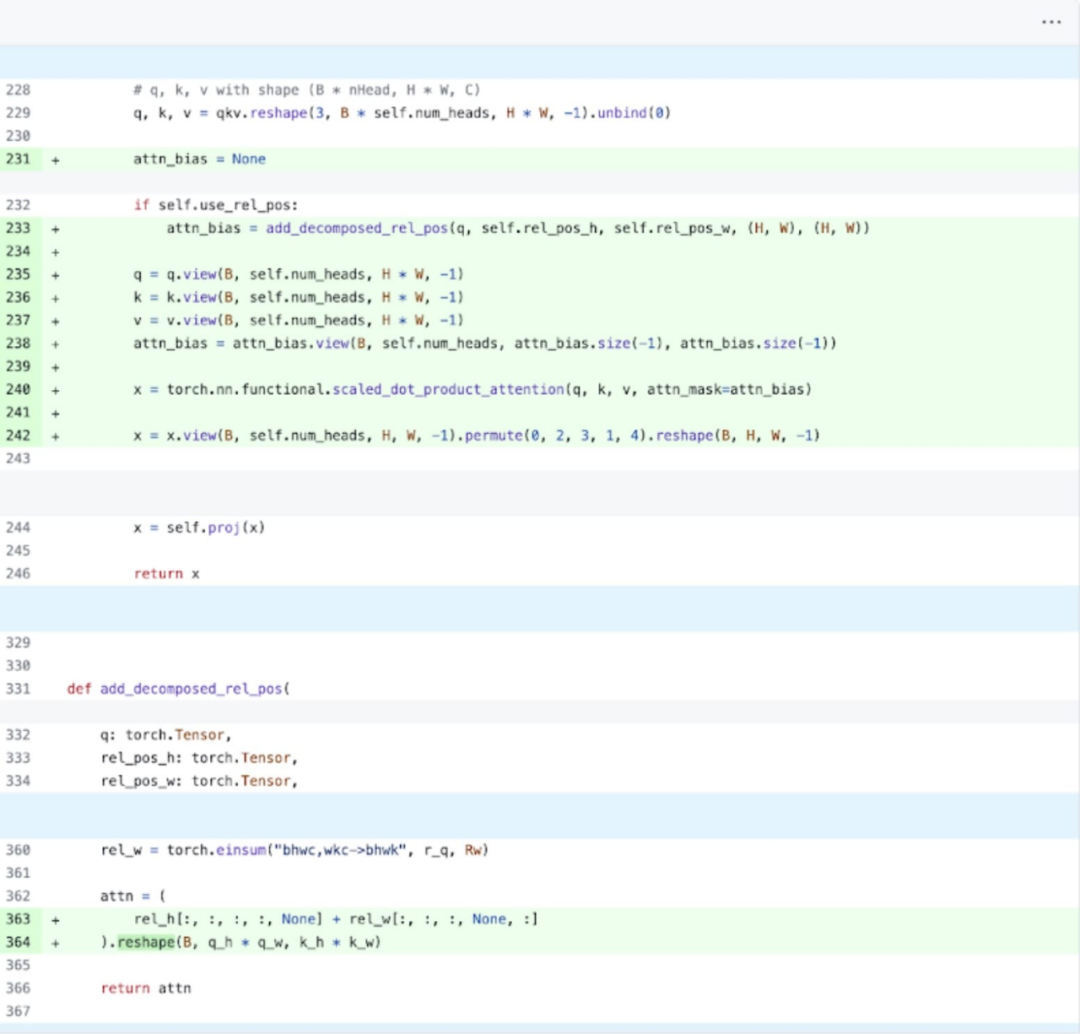
Plus précisément, il est plus facile à comprendre sur la base de l'image ci-dessus, l'étude a révélé que dans l'encodeur d'image de SAM. Il existe deux variables q_coords et k_coords qui agissent comme des scalers de coordonnées, et ces variables sont allouées et traitées sur le CPU. Cependant, une fois ces variables utilisées pour indexer dans rel_pos_resized, l'opération d'indexation déplace automatiquement ces variables vers le GPU, provoquant des problèmes de synchronisation GPU. Pour résoudre ce problème, la recherche a souligné que cette partie peut être résolue en la réécrivant à l'aide de la fonction torch.where comme indiqué ci-dessus
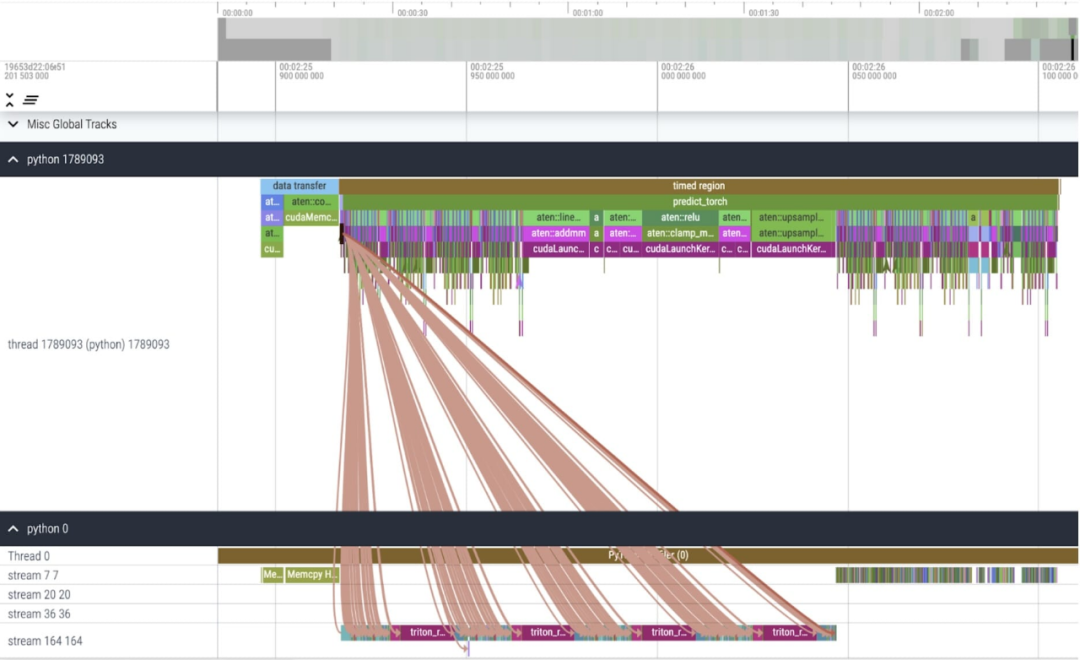
Core Tracking
Après avoir appliqué ces modifications, nous avons remarqué qu'il y a un notable intervalle de temps entre les appels individuels du noyau, en particulier avec de petits lots (ici 1). Pour mieux comprendre ce phénomène, nous avons commencé l'analyse des performances de l'inférence SAM avec une taille de lot de 8
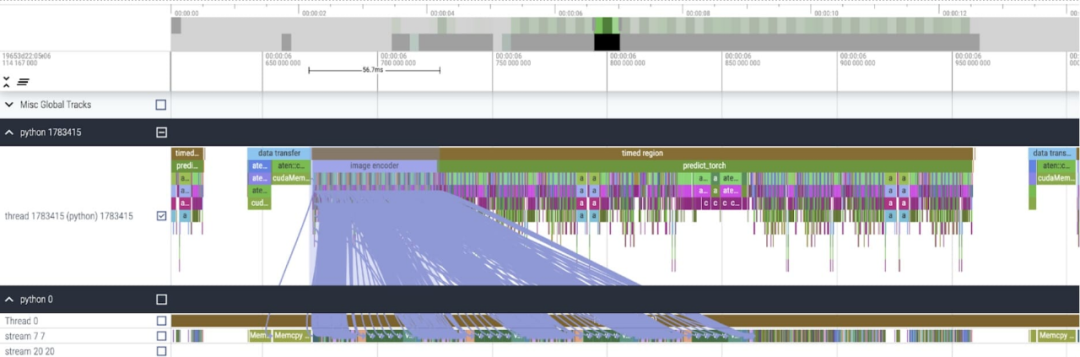
En analysant le temps passé par cœur, nous avons remarqué que la majorité des GPU pour SAM Time est dépensé en noyaux par éléments et en opérations softmax
Vous pouvez maintenant voir que la surcharge relative de la multiplication matricielle est beaucoup plus petite.
En combinant la synchronisation GPU et l'optimisation bfloat16, les performances SAM sont améliorées de 3 fois.
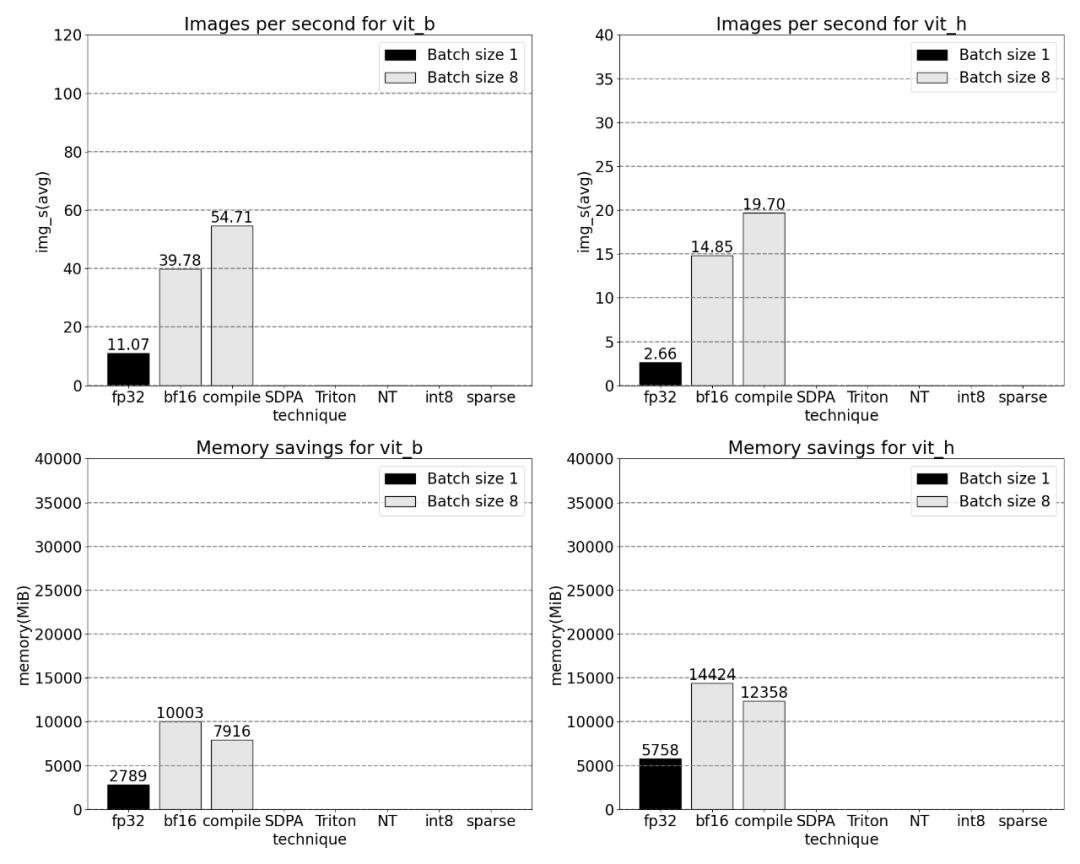
Torch.compile (+ ruptures de graphiques et graphiques CUDA)
J'ai découvert de nombreuses petites opérations lors de l'étude de SAM. Les chercheurs pensent que l'utilisation d'un compilateur pour consolider ces opérations est très bénéfique, c'est pourquoi PyTorch a apporté les optimisations suivantes à torch.compile
- Fusionner des séquences d'opérations telles que nn.LayerNorm ou nn.GELU dans un seul noyau GPU ;
- Fusionner les opérations immédiatement après le noyau de multiplication matricielle pour réduire le nombre d'appels au noyau GPU.
Grâce à ces optimisations, la recherche réduit le nombre d'allers-retours dans la mémoire globale du GPU, accélérant ainsi l'inférence. Nous pouvons maintenant essayer torch.compile sur l’encodeur d’image de SAM. Pour maximiser les performances, cet article utilise des techniques de compilation avancées :

Core tracking
Selon les résultats, torch.compile fonctionne très bien
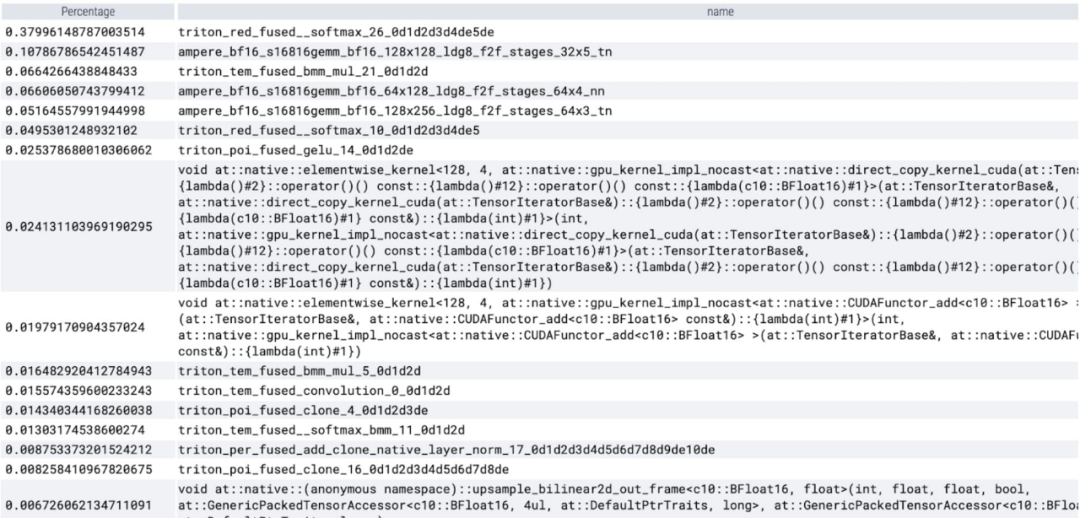
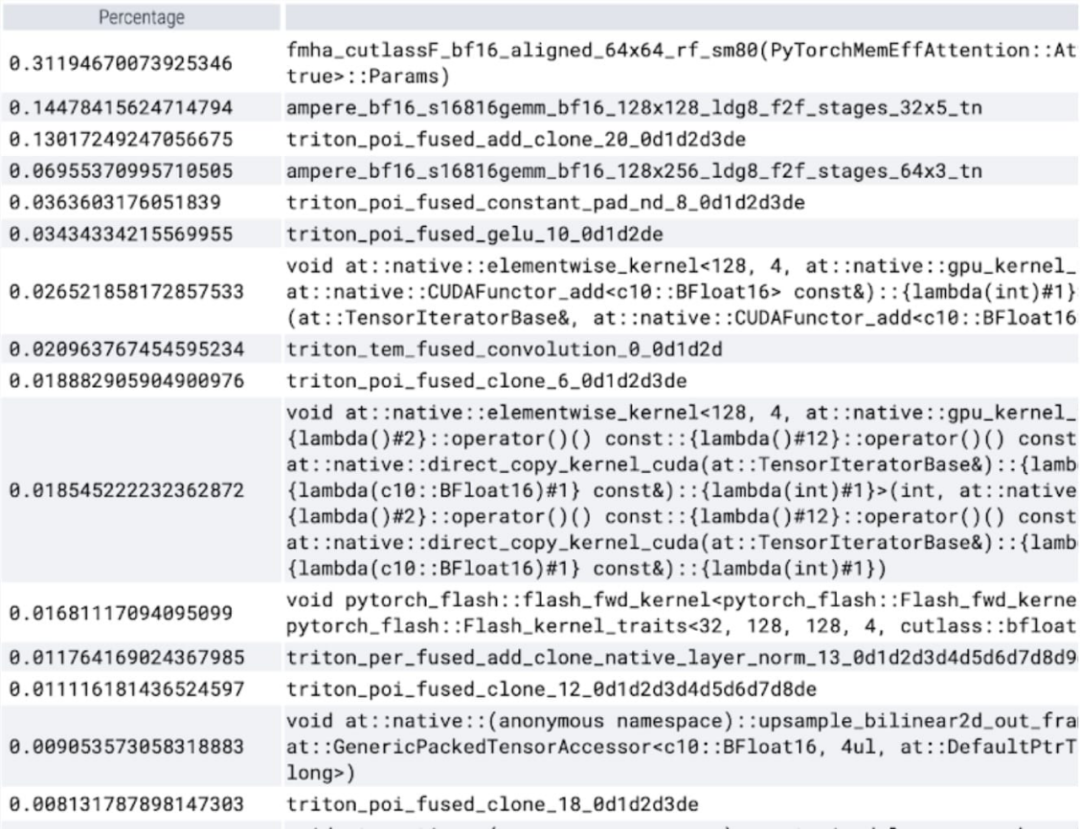
On peut observer que softmax occupe une grande partie de le temps , puis chaque variante GEMM. Les mesures suivantes concernent des lots de 8 et plus.
SDPA : scaled_dot_product_attention
Ensuite, cet article a mené des expériences sur SDPA (scaled_dot_product_attention), en se concentrant sur le mécanisme d'attention. En général, les mécanismes d’attention natifs évoluent quadratiquement avec la longueur de la séquence en temps et en mémoire. Les opérations SDPA de PyTorch reposent sur les principes d'attention économes en mémoire de Flash Attention, FlashAttentionV2 et xFormer, qui peuvent accélérer considérablement l'attention du GPU. Combinée avec torch.compile, cette opération permet d'exprimer et de fusionner un motif commun dans des variantes de MultiheadAttention. Après un petit changement, le modèle peut désormais utiliser scaled_dot_product_attention.
Core Tracking
Vous pouvez maintenant voir le noyau d'attention efficace en mémoire prenant beaucoup de temps de calcul sur le GPU :
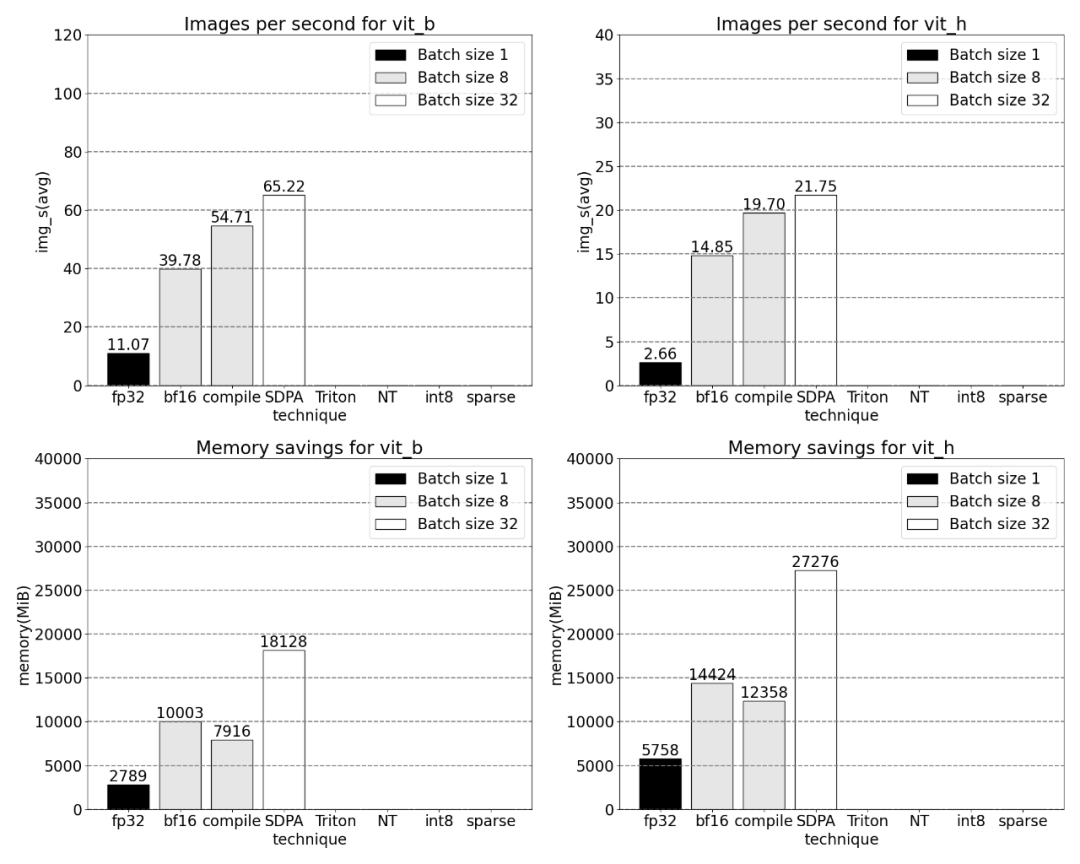
Utilisation du natif de PyTorch scaled_dot _product_attention, oui Augmente considérablement la taille du lot. Le graphique ci-dessous montre les changements pour les tailles de lots de 32 et plus.
Ensuite, l'étude a mené des expériences sur Triton, NestedTensor, batch Predict_torch, la quantification int8, la parcimonie semi-structurée (2:4) et d'autres opérations
Par exemple, cet article utilise un positionnel personnalisé pour le noyau Triton, des mesures avec une taille de lot de 32 ont été observées.
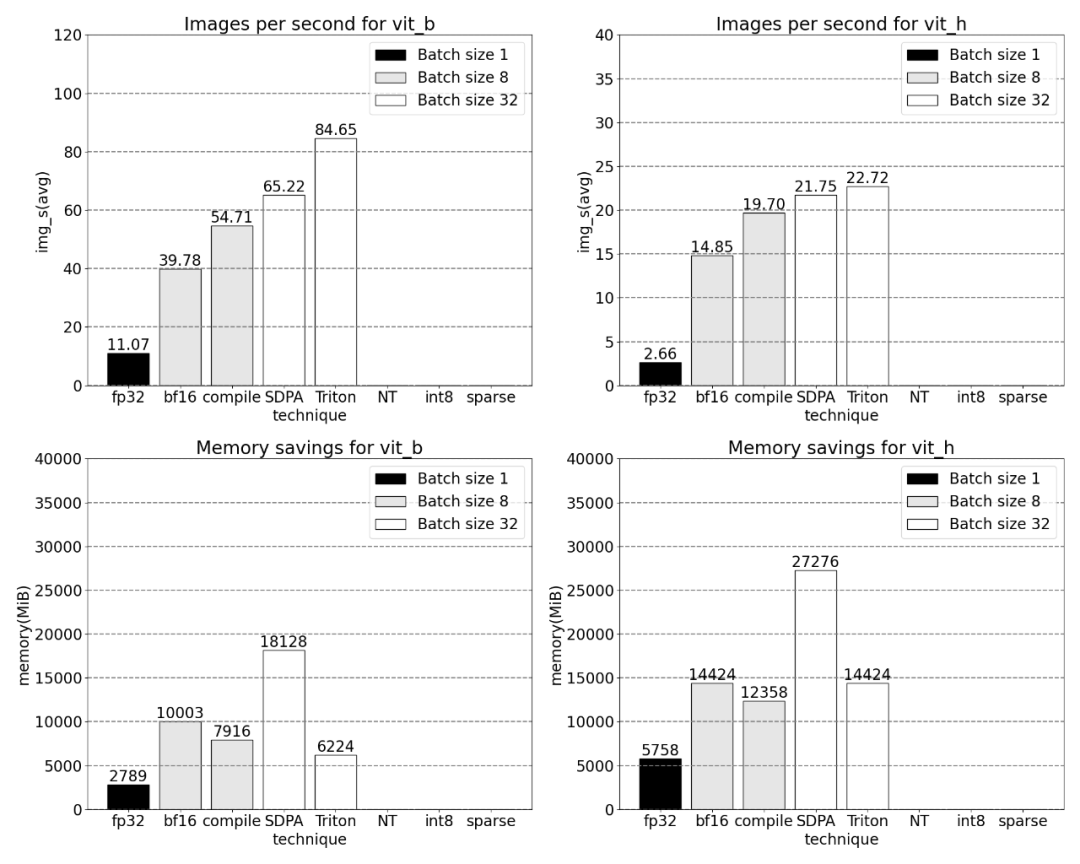
Utilisation de la technologie Nested Tensor et ajustement de la taille du lot à 32 et plus
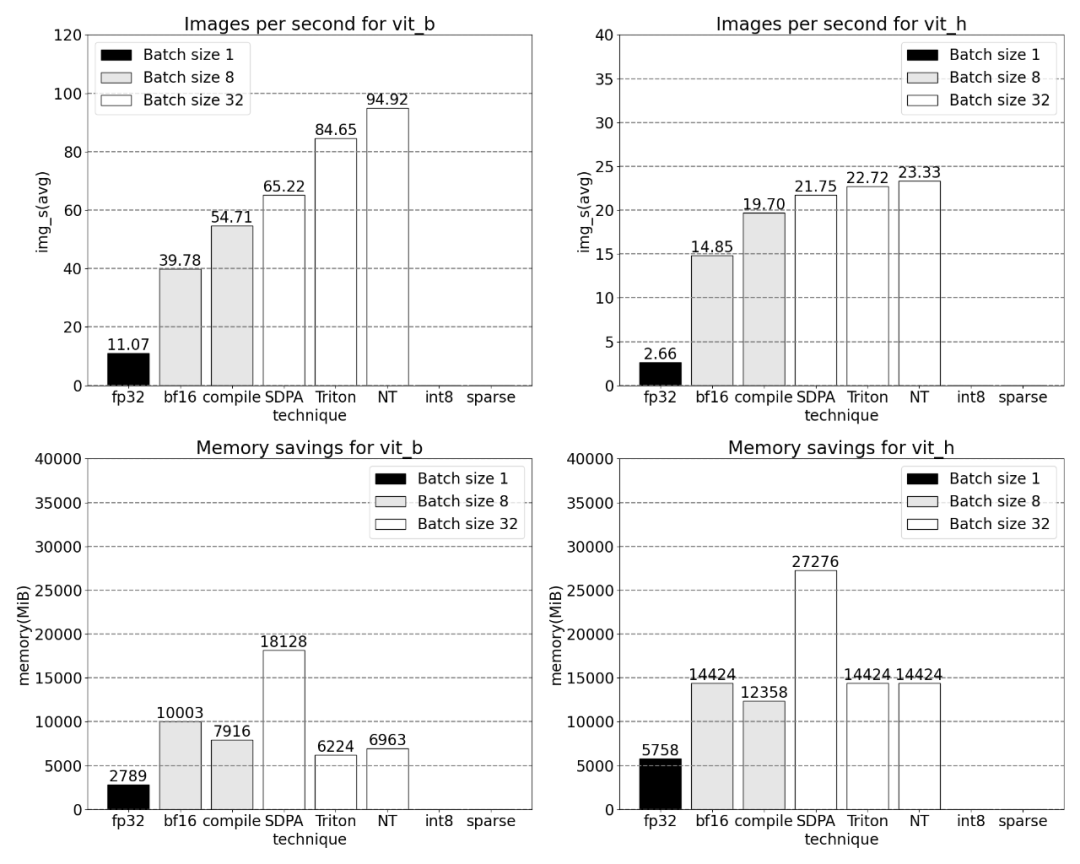
Après l'ajout de la quantification, les résultats de mesure de la taille du lot changent de 32 et plus.
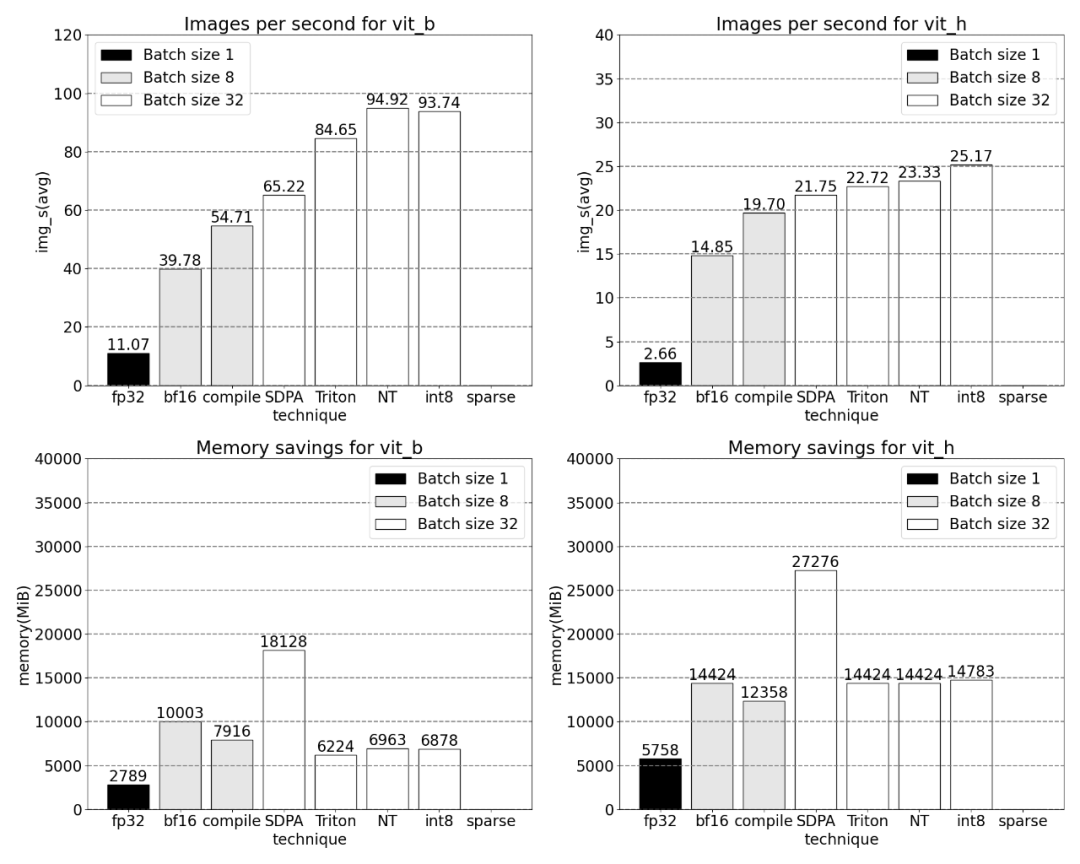
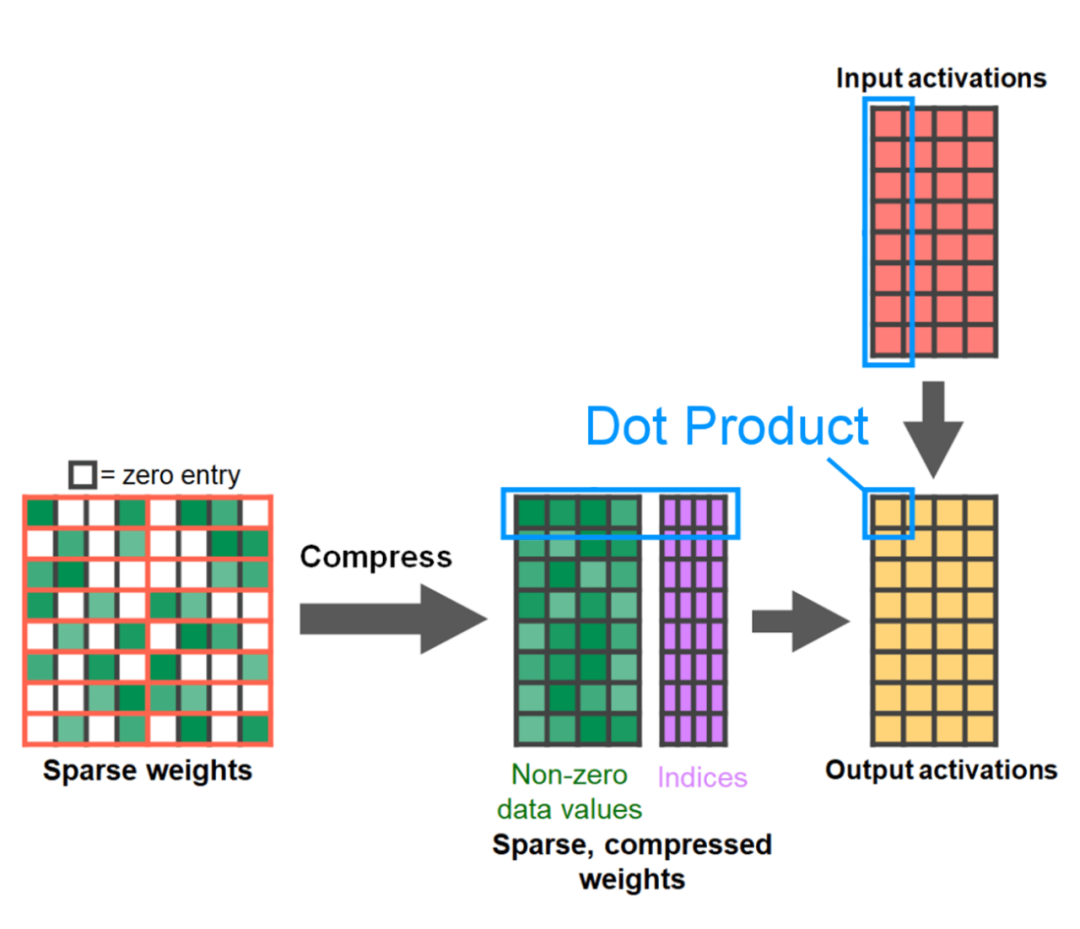
La fin de l'article est la parcimonie semi-structurée. L’étude montre que la multiplication matricielle reste un goulot d’étranglement auquel il faut faire face. La solution consiste à utiliser la sparsification pour approximer la multiplication matricielle. Grâce à des matrices clairsemées (c'est-à-dire en mettant à zéro les valeurs), moins de bits peuvent être utilisés pour stocker les poids et les tenseurs d'activation. Le processus de définition des poids dans un tenseur qui sont mis à zéro est appelé élagage. La suppression de poids plus petits peut potentiellement réduire la taille du modèle sans perte significative de précision.
Il existe de nombreuses méthodes de taille, allant de complètement non structurée à très structurée. Bien que l'élagage non structuré ait théoriquement un impact minime sur la précision, dans le cas clairsemé, le GPU peut subir une dégradation significative des performances, bien qu'il soit très efficace lors de grandes multiplications de matrices denses. Une méthode d'élagage récemment prise en charge par PyTorch est la parcimonie semi-structurée (ou 2:4), qui vise à trouver un équilibre. Cette méthode de stockage clairsemé réduit le tenseur d'origine de 50 % tout en produisant une sortie de tenseur dense. Veuillez vous référer à la figure ci-dessous pour une explication
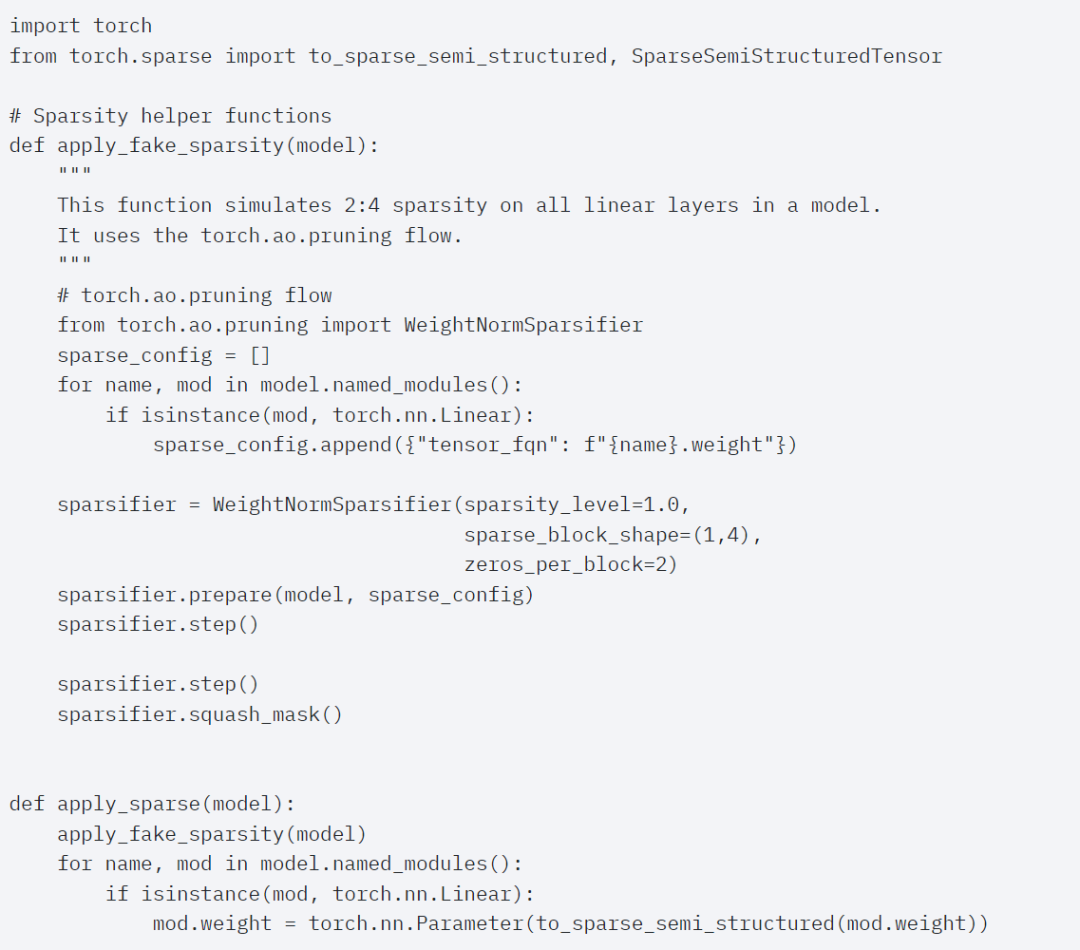
Afin d'utiliser ce format de stockage clairsemé et le noyau rapide associé, la prochaine chose à faire est d'élaguer les poids. Cet article sélectionne les deux plus petits poids pour l'élagage avec une parcimonie de 2:4. Il est facile de changer les poids de la disposition PyTorch (« stried ») par défaut vers cette nouvelle disposition clairsemée semi-structurée. Pour implémenter apply_sparse (modèle), seules 32 lignes de code Python sont requises :
Avec une parcimonie de 2:4, nous observons des performances maximales de SAM avec vit_b et une taille de lot de 32
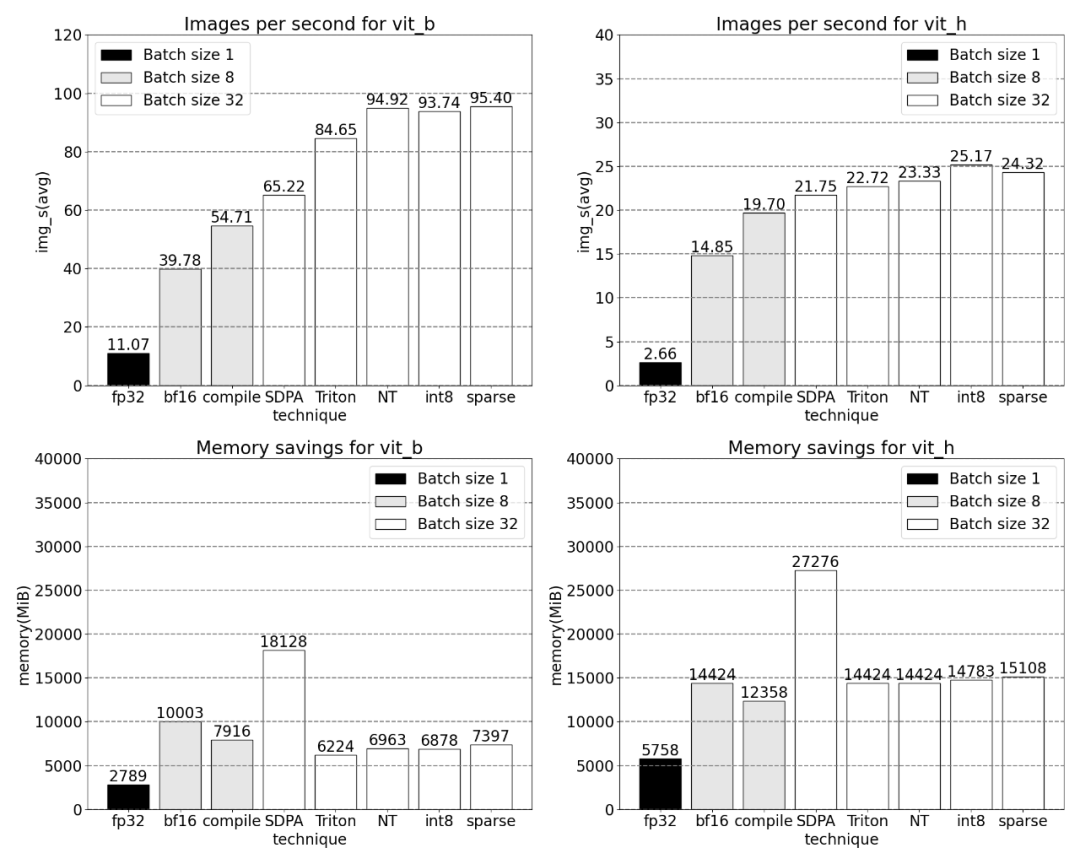
Enfin , le résumé de cet article est le suivant : Cet article présente le moyen le plus rapide d'implémenter Segment Anything sur PyTorch jusqu'à présent. Avec l'aide d'une série de nouvelles fonctionnalités officiellement publiées, cet article réécrit le SAM original en PyTorch pur, et il y a. aucune perte de précision
Pour les lecteurs intéressés, vous pouvez consulter le blog original pour plus d'informations
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Imaginez un modèle d'intelligence artificielle qui non seulement a la capacité de surpasser l'informatique traditionnelle, mais qui permet également d'obtenir des performances plus efficaces à moindre coût. Ce n'est pas de la science-fiction, DeepSeek-V2[1], le modèle MoE open source le plus puissant au monde est ici. DeepSeek-V2 est un puissant mélange de modèle de langage d'experts (MoE) présentant les caractéristiques d'une formation économique et d'une inférence efficace. Il est constitué de 236B paramètres, dont 21B servent à activer chaque marqueur. Par rapport à DeepSeek67B, DeepSeek-V2 offre des performances plus élevées, tout en économisant 42,5 % des coûts de formation, en réduisant le cache KV de 93,3 % et en augmentant le débit de génération maximal à 5,76 fois. DeepSeek est une entreprise explorant l'intelligence artificielle générale
 KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
Plus tôt ce mois-ci, des chercheurs du MIT et d'autres institutions ont proposé une alternative très prometteuse au MLP – KAN. KAN surpasse MLP en termes de précision et d’interprétabilité. Et il peut surpasser le MLP fonctionnant avec un plus grand nombre de paramètres avec un très petit nombre de paramètres. Par exemple, les auteurs ont déclaré avoir utilisé KAN pour reproduire les résultats de DeepMind avec un réseau plus petit et un degré d'automatisation plus élevé. Plus précisément, le MLP de DeepMind compte environ 300 000 paramètres, tandis que le KAN n'en compte qu'environ 200. KAN a une base mathématique solide comme MLP est basé sur le théorème d'approximation universelle, tandis que KAN est basé sur le théorème de représentation de Kolmogorov-Arnold. Comme le montre la figure ci-dessous, KAN a
 Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas entre officiellement dans l’ère des robots électriques ! Hier, l'Atlas hydraulique s'est retiré "en larmes" de la scène de l'histoire. Aujourd'hui, Boston Dynamics a annoncé que l'Atlas électrique était au travail. Il semble que dans le domaine des robots humanoïdes commerciaux, Boston Dynamics soit déterminé à concurrencer Tesla. Après la sortie de la nouvelle vidéo, elle a déjà été visionnée par plus d’un million de personnes en seulement dix heures. Les personnes âgées partent et de nouveaux rôles apparaissent. C'est une nécessité historique. Il ne fait aucun doute que cette année est l’année explosive des robots humanoïdes. Les internautes ont commenté : Les progrès des robots ont fait ressembler la cérémonie d'ouverture de cette année à des êtres humains, et le degré de liberté est bien plus grand que celui des humains. Mais n'est-ce vraiment pas un film d'horreur ? Au début de la vidéo, Atlas est allongé calmement sur le sol, apparemment sur le dos. Ce qui suit est à couper le souffle
 Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
La dernière vidéo du robot Optimus de Tesla est sortie, et il peut déjà fonctionner en usine. À vitesse normale, il trie les batteries (les batteries 4680 de Tesla) comme ceci : Le responsable a également publié à quoi cela ressemble à une vitesse 20 fois supérieure - sur un petit "poste de travail", en sélectionnant et en sélectionnant et en sélectionnant : Cette fois, il est publié L'un des points forts de la vidéo est qu'Optimus réalise ce travail en usine, de manière totalement autonome, sans intervention humaine tout au long du processus. Et du point de vue d'Optimus, il peut également récupérer et placer la batterie tordue, en se concentrant sur la correction automatique des erreurs : concernant la main d'Optimus, le scientifique de NVIDIA Jim Fan a donné une évaluation élevée : la main d'Optimus est l'un des robots à cinq doigts du monde. le plus adroit. Ses mains ne sont pas seulement tactiles
 FisheyeDetNet : le premier algorithme de détection de cible basé sur une caméra fisheye
Apr 26, 2024 am 11:37 AM
FisheyeDetNet : le premier algorithme de détection de cible basé sur une caméra fisheye
Apr 26, 2024 am 11:37 AM
La détection de cibles est un problème relativement mature dans les systèmes de conduite autonome, parmi lesquels la détection des piétons est l'un des premiers algorithmes à être déployés. Des recherches très complètes ont été menées dans la plupart des articles. Cependant, la perception de la distance à l’aide de caméras fisheye pour une vue panoramique est relativement moins étudiée. En raison de la distorsion radiale importante, la représentation standard du cadre de délimitation est difficile à mettre en œuvre dans les caméras fisheye. Pour alléger la description ci-dessus, nous explorons les conceptions étendues de boîtes englobantes, d'ellipses et de polygones généraux dans des représentations polaires/angulaires et définissons une métrique de segmentation d'instance mIOU pour analyser ces représentations. Le modèle fisheyeDetNet proposé avec une forme polygonale surpasse les autres modèles et atteint simultanément 49,5 % de mAP sur l'ensemble de données de la caméra fisheye Valeo pour la conduite autonome.
 Un nouveau casque VR Meta Quest 3S abordable apparaît sur FCC, suggérant un lancement imminent
Sep 04, 2024 am 06:51 AM
Un nouveau casque VR Meta Quest 3S abordable apparaît sur FCC, suggérant un lancement imminent
Sep 04, 2024 am 06:51 AM
L'événement Meta Connect 2024 est prévu du 25 au 26 septembre et lors de cet événement, la société devrait dévoiler un nouveau casque de réalité virtuelle abordable. Selon la rumeur, il s'agirait du Meta Quest 3S, le casque VR serait apparemment apparu sur la liste FCC. Cela suggère
 Le premier modèle open source à dépasser le niveau GPT4o ! Llama 3.1 fuite : 405 milliards de paramètres, liens de téléchargement et cartes de modèles sont disponibles
Jul 23, 2024 pm 08:51 PM
Le premier modèle open source à dépasser le niveau GPT4o ! Llama 3.1 fuite : 405 milliards de paramètres, liens de téléchargement et cartes de modèles sont disponibles
Jul 23, 2024 pm 08:51 PM
Préparez votre GPU ! Llama3.1 est finalement apparu, mais la source n'est pas officielle de Meta. Aujourd'hui, la nouvelle divulguée du nouveau grand modèle Llama est devenue virale sur Reddit. En plus du modèle de base, elle comprend également des résultats de référence de 8B, 70B et le paramètre maximum de 405B. La figure ci-dessous montre les résultats de comparaison de chaque version de Llama3.1 avec OpenAIGPT-4o et Llama38B/70B. On peut voir que même la version 70B dépasse GPT-4o sur plusieurs benchmarks. Source de l'image : https://x.com/mattshumer_/status/1815444612414087294 Évidemment, version 3.1 de 8B et 70
 Une seule carte exécute Llama 70B plus rapidement que deux cartes, Microsoft vient de mettre le FP6 dans l'Open source A100 |
Apr 29, 2024 pm 04:55 PM
Une seule carte exécute Llama 70B plus rapidement que deux cartes, Microsoft vient de mettre le FP6 dans l'Open source A100 |
Apr 29, 2024 pm 04:55 PM
Le FP8 et la précision de quantification inférieure en virgule flottante ne sont plus le « brevet » du H100 ! Lao Huang voulait que tout le monde utilise INT8/INT4, et l'équipe Microsoft DeepSpeed a commencé à exécuter FP6 sur A100 sans le soutien officiel de NVIDIA. Les résultats des tests montrent que la quantification FP6 de la nouvelle méthode TC-FPx sur A100 est proche ou parfois plus rapide que celle de INT4, et a une précision supérieure à celle de cette dernière. En plus de cela, il existe également une prise en charge de bout en bout des grands modèles, qui ont été open source et intégrés dans des cadres d'inférence d'apprentissage profond tels que DeepSpeed. Ce résultat a également un effet immédiat sur l'accélération des grands modèles : dans ce cadre, en utilisant une seule carte pour exécuter Llama, le débit est 2,65 fois supérieur à celui des cartes doubles. un
