
 Périphériques technologiques
IA
Comment utiliser LangChain et l'API OpenAI pour l'analyse de documents
Périphériques technologiques
IA
Comment utiliser LangChain et l'API OpenAI pour l'analyse de documents
Comment utiliser LangChain et l'API OpenAI pour l'analyse de documents

Le contenu qui doit être réécrit par le traducteur est :|Le contenu qui doit être réécrit est :Bugatti
Le contenu qui doit être réécrit par le réviseur est :|Le contenu qui doit à réécrire est : Chonglou
De Extraire des informationsà partir de documents et de données est essentiel pour vouspour prendre des décisions éclairées. Cependant, lorsqu'il s'agit d'informations sensibles, des problèmes de confidentialité peuvent survenir. L'utilisation combinée de LangChain et OpenAI doit être réécrite : API, vous pouvez analyser des documents locaux sans les télécharger sur Internet.
Ils font cela en conservant les données localement, en utilisant l'intégration et la vectorisation pour l'analyse et en exécutant des processus dans votre environnement. OpenAI n'utilise pas les données soumises par les clients via son API pour former des modèles ou améliorer le service.
Construireenvironnement
Créer un nouveauPythonenvironnement virtuel, Cela garantira qu'il n'y a pas de conflits de versions de bibliothèque. Exécutez ensuite les commandes de terminal suivantes pour installer les bibliothèques requises. pip需要改写的内容是:install需要改写的内容是:langchain需要改写的内容是:openai需要改写的内容是:tiktoken需要改写的内容是:faiss-cpu需要改写的内容是:pypdf
utiliser chaque bibliothèque :
- LangChain : Vous l'utiliserez pour créer et gérer les applications de traitement de texte et linguistique chaînes d’analyse. Il fournira des modules pour le chargement de documents, la segmentation de texte, l'intégration et le stockage de volumes. OpenAI
- : Vous l'utiliserez pour exécuter des requêtes , et obtenir des résultats à partir de modèles de langage. tiktoken
- : Vous l'utiliserez pour compter le nombre de token ( unité de texte ) dans un texte donné. Ce qui doit être réécrit afin de suivre le nombre de token lors de l'interaction avec OpenAI qui facture en fonction du le nombre de tokens que vous utilisez est : API . FAISS : Vous l'utiliserez pour créer et gérer des magasins de vecteurs, permettant une récupération rapide de vecteurs similaires basés sur des intégrations.
- PyPDF : Cette bibliothèque extrait le texte de
- PDF. Il aide à charger des fichiers PDF et à extraire leur texte , pour un traitement ultérieur. Après avoir installé toutes les bibliothèques, votre environnement est maintenant prêt
. Obtenir OpenAI Ce qui doit être réécrit est : API clé
Lorsque vous faites une demande à OpenAI Ce qui doit être réécrit est : API , vous devez ajoutez
APIKey dans le cadre de la demande. Cette clé permet au fournisseur API de vérifier que la demande provient d'une source légitime et que vous disposez les autorisations nécessaires pour accéder à ses fonctionnalités. Ce qui doit être réécrit pour obtenir OpenAI est : la clé API, entrez dans la Plateforme OpenAI.
en haut à droite, 
ViewAPIKey", apparaîtra APISecret page clé. Cliquez sur le bouton "Créer une nouvelle clé" .
Nommez la clé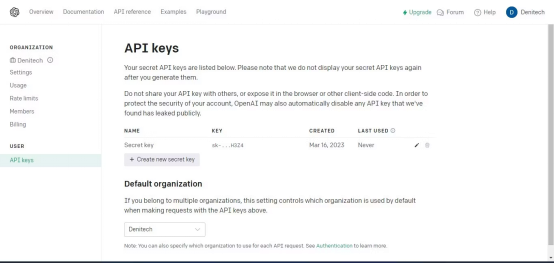
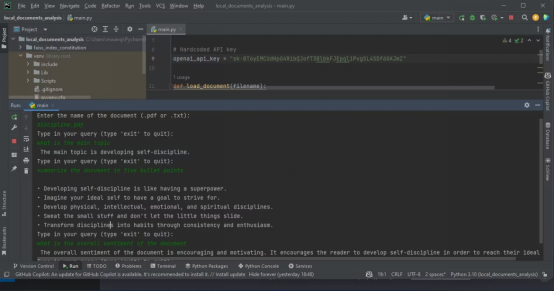
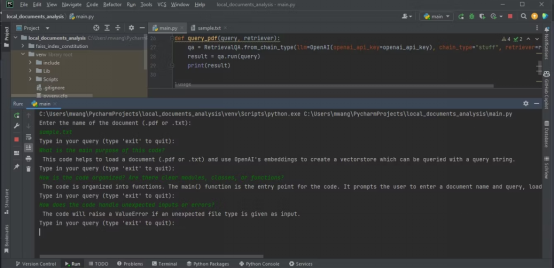
et cliquez sur "Créer une nouvelle clé". OpenAI générera une APIclé, que vous devrez copier et conserver dans un endroit sûr. Pour des raisons de sécurité, vous ne pourrez plus le consulter via votre compte OpenAI. Si vous perdez la clé, vous devez générer une nouvelle clé. 为了能够使用安装在虚拟环境中的库,您需要导入它们。 注意,您从LangChain导入了依赖项库,这让您可以使用LangChain框架的特定功能。 先创建一个含有API密钥的变量。稍后,您将在代码中使用该变量用于身份验证。 如果您打算与第三方共享您的代码,不建议对API密钥进行硬编码。对于打算分发的生产级代码,则改而使用环境变量。 接下来,创建一个加载文档的函数。该函数应该加载PDF或文本文件。如果文档既不是PDF文件,也不是文本文件,该函数会抛出值错误。 加载文档后,创建一个CharacterTextSplitter。该分割器将基于字符将已加载的文档分隔成更小的块。 需要改写的内容是: 分割文档可确保块的大小易于管理,仍与一些重叠的上下文相连接。这对于文本分析和信息检索之类的任务非常有用。 您需要一种方法来查询上传的文档,以便从中获得洞察力。为此,创建一个以查询字符串和检索器作为输入的函数。然后,它使用检索器和OpenAI语言模型的实例创建一个RetrievalQA实例。 该函数使用创建的QA实例来运行查询并输出结果。 主函数将控制整个程序流。它将接受用户输入的文档文件名并加载该文档。然后为文本嵌入创建OpenAIEmbeddings实例,并基于已加载的文档和文本嵌入构造一个向量存储。将该向量存储保存到本地文件。 接下来,从本地文件加载持久的向量存储。然后输入一个循环,用户可以在其中输入查询。主函数将这些查询与持久化向量存储的检索器一起传递给query_pdf函数。循环将继续,直到用户输入“exit”。 嵌入捕获词之间的语义关系。向量是一种可以表示一段文本的形式。 这段代码使用OpenAIEmbeddings生成的嵌入将文档中的文本数据转换成向量。然后使用FAISS对这些向量进行索引,以便高效地检索和比较相似的向量。这便于对上传的文档进行分析。 最后,如果用户独立运行程序,使用__name__需要改写的内容是:==需要改写的内容是:"__main__"构造函数来调用主函数: 这个应用程序是一个命令行应用程序。作为一个扩展,您可以使用Streamlit为该应用程序添加Web界面。 要执行文档分析,将所要分析的文档存储在项目所在的同一个文件夹中,然后运行该程序。它将询问所要分析的文档的名称。输入全名,然后输入查询,以便程序分析。 以下截图展示了对PDF进行分析的结果 Le résultat ci-dessous montre les résultats de l'analyse d'un fichier texte contenant avec le code source. Assurez-vous que le fichier que vous souhaitez analyser est au format PDF ou texte. Si vos documents sont dans d'autres formats , vous pouvez utiliser des outils en ligne pour les convertir au format PDF . Le code source complet est disponible dans le référentiel de code GitHub : https://github.com/makeuseofcode/Document-analysis-using-LangChain-and-OpenAI Titre original : Comment doit-il être être réécrit Le contenu à réécrire est : à Le contenu à réécrire est : Analyser Le contenu à réécrire est : Documents Le contenu à réécrire est : Avec Le contenu à réécrire est : LangChain Le contenu qui doit être réécrit est : et Le contenu qui doit être réécrit est : le contenu qui doit être réécrit est : le Le contenu est : OpenAI Le contenu qui doit être réécrit est : API , auteur : Denis Le contenu à réécrire est : Kuria Le contenu à réécrire est :
导入所需的库
from需要改写的内容是:langchain.document_loaders需要改写的内容是:import需要改写的内容是:PyPDFLoader,需要改写的内容是:TextLoaderfrom需要改写的内容是:langchain.text_splitter需要改写的内容是:import需要改写的内容是:CharacterTextSplitterfrom需要改写的内容是:langchain.embeddings.openai需要改写的内容是:import需要改写的内容是:OpenAIEmbeddingsfrom需要改写的内容是:langchain.vectorstores需要改写的内容是:import需要改写的内容是:FAISSfrom需要改写的内容是:langchain.chains需要改写的内容是:import需要改写的内容是:RetrievalQAfrom需要改写的内容是:langchain.llms需要改写的内容是:import需要改写的内容是:OpenAI
加载用于分析的文档
#需要改写的内容是:Hardcoded需要改写的内容是:API需要改写的内容是:keyopenai_api_key需要改写的内容是:=需要改写的内容是:"Your需要改写的内容是:API需要改写的内容是:key"
def需要改写的内容是:load_document(filename):if需要改写的内容是:filename.endswith(".pdf"):需要改写的内容是:loader需要改写的内容是:=需要改写的内容是:PyPDFLoader(filename)需要改写的内容是:documents需要改写的内容是:=需要改写的内容是:loader.load()需要改写的内容是:elif需要改写的内容是:filename.endswith(".txt"):需要改写的内容是:loader需要改写的内容是:=需要改写的内容是:TextLoader(filename)需要改写的内容是:documents需要改写的内容是:=需要改写的内容是:loader.load()需要改写的内容是:else:需要改写的内容是:raise需要改写的内容是:ValueError("Invalid需要改写的内容是:file需要改写的内容是:type")text_splitter需要改写的内容是:=需要改写的内容是:CharacterTextSplitter(chunk_size=1000,需要改写的内容是:需要改写的内容是:chunk_overlap=30,需要改写的内容是:separator="\n")需要改写的内容是:return需要改写的内容是:text_splitter.split_documents(documents=documents)
查询文档
def需要改写的内容是:query_pdf(query,需要改写的内容是:retriever):qa需要改写的内容是:=需要改写的内容是:RetrievalQA.from_chain_type(llm=OpenAI(openai_api_key=openai_api_key),需要改写的内容是:chain_type="stuff",需要改写的内容是:retriever=retriever)result需要改写的内容是:=需要改写的内容是:qa.run(query)需要改写的内容是:print(result)
创建主函数
def需要改写的内容是:main():需要改写的内容是:filename需要改写的内容是:=需要改写的内容是:input("Enter需要改写的内容是:the需要改写的内容是:name需要改写的内容是:of需要改写的内容是:the需要改写的内容是:document需要改写的内容是:(.pdf需要改写的内容是:or需要改写的内容是:.txt):\n")docs需要改写的内容是:=需要改写的内容是:load_document(filename)embeddings需要改写的内容是:=需要改写的内容是:OpenAIEmbeddings(openai_api_key=openai_api_key)vectorstore需要改写的内容是:=需要改写的内容是:FAISS.from_documents(docs,需要改写的内容是:embeddings)需要改写的内容是:vectorstore.save_local("faiss_index_constitution")persisted_vectorstore需要改写的内容是:=需要改写的内容是:FAISS.load_local("faiss_index_constitution",需要改写的内容是:embeddings)query需要改写的内容是:=需要改写的内容是:input("Type需要改写的内容是:in需要改写的内容是:your需要改写的内容是:query需要改写的内容是:(type需要改写的内容是:'exit'需要改写的内容是:to需要改写的内容是:quit):\n")while需要改写的内容是:query需要改写的内容是:!=需要改写的内容是:"exit":query_pdf(query,需要改写的内容是:persisted_vectorstore.as_retriever())query需要改写的内容是:=需要改写的内容是:input("Type需要改写的内容是:in需要改写的内容是:your需要改写的内容是:query需要改写的内容是:(type需要改写的内容是:'exit'需要改写的内容是:to需要改写的内容是:quit):\n")if需要改写的内容是:__name__需要改写的内容是:==需要改写的内容是:"__main__":需要改写的内容是:main()
执行文件分析
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Choisir le modèle d'intégration qui correspond le mieux à vos données : un test comparatif des intégrations multilingues OpenAI et open source
Feb 26, 2024 pm 06:10 PM
Choisir le modèle d'intégration qui correspond le mieux à vos données : un test comparatif des intégrations multilingues OpenAI et open source
Feb 26, 2024 pm 06:10 PM
OpenAI a récemment annoncé le lancement de son modèle d'intégration de dernière génération, embeddingv3, qui, selon eux, est le modèle d'intégration le plus performant avec des performances multilingues plus élevées. Ce lot de modèles est divisé en deux types : les plus petits text-embeddings-3-small et les plus puissants et plus grands text-embeddings-3-large. Peu d'informations sont divulguées sur la façon dont ces modèles sont conçus et formés, et les modèles ne sont accessibles que via des API payantes. Il existe donc de nombreux modèles d'intégration open source. Mais comment ces modèles open source se comparent-ils au modèle open source open source ? Cet article comparera empiriquement les performances de ces nouveaux modèles avec des modèles open source. Nous prévoyons de créer une donnée
 Un nouveau paradigme de programmation, quand Spring Boot rencontre OpenAI
Feb 01, 2024 pm 09:18 PM
Un nouveau paradigme de programmation, quand Spring Boot rencontre OpenAI
Feb 01, 2024 pm 09:18 PM
En 2023, la technologie de l’IA est devenue un sujet brûlant et a un impact énorme sur diverses industries, notamment dans le domaine de la programmation. Les gens sont de plus en plus conscients de l’importance de la technologie de l’IA, et la communauté Spring ne fait pas exception. Avec l’évolution continue de la technologie GenAI (Intelligence Artificielle Générale), il est devenu crucial et urgent de simplifier la création d’applications dotées de fonctions d’IA. Dans ce contexte, « SpringAI » a émergé, visant à simplifier le processus de développement d'applications fonctionnelles d'IA, en le rendant simple et intuitif et en évitant une complexité inutile. Grâce à « SpringAI », les développeurs peuvent plus facilement créer des applications dotées de fonctions d'IA, ce qui les rend plus faciles à utiliser et à exploiter.
 Travail posthume de l'équipe OpenAI Super Alignment : deux grands modèles jouent à un jeu et le résultat devient plus compréhensible
Jul 19, 2024 am 01:29 AM
Travail posthume de l'équipe OpenAI Super Alignment : deux grands modèles jouent à un jeu et le résultat devient plus compréhensible
Jul 19, 2024 am 01:29 AM
Si la réponse donnée par le modèle d’IA est incompréhensible du tout, oseriez-vous l’utiliser ? À mesure que les systèmes d’apprentissage automatique sont utilisés dans des domaines de plus en plus importants, il devient de plus en plus important de démontrer pourquoi nous pouvons faire confiance à leurs résultats, et quand ne pas leur faire confiance. Une façon possible de gagner confiance dans le résultat d'un système complexe est d'exiger que le système produise une interprétation de son résultat qui soit lisible par un humain ou un autre système de confiance, c'est-à-dire entièrement compréhensible au point que toute erreur possible puisse être trouvé. Par exemple, pour renforcer la confiance dans le système judiciaire, nous exigeons que les tribunaux fournissent des avis écrits clairs et lisibles qui expliquent et soutiennent leurs décisions. Pour les grands modèles de langage, nous pouvons également adopter une approche similaire. Cependant, lorsque vous adoptez cette approche, assurez-vous que le modèle de langage génère
 L'éditeur Zed basé sur Rust est open source, avec prise en charge intégrée d'OpenAI et GitHub Copilot
Feb 01, 2024 pm 02:51 PM
L'éditeur Zed basé sur Rust est open source, avec prise en charge intégrée d'OpenAI et GitHub Copilot
Feb 01, 2024 pm 02:51 PM
Auteur丨Compilé par TimAnderson丨Produit par Noah|51CTO Technology Stack (WeChat ID : blog51cto) Le projet d'éditeur Zed est encore en phase de pré-version et a été open source sous licences AGPL, GPL et Apache. L'éditeur offre des performances élevées et plusieurs options assistées par l'IA, mais n'est actuellement disponible que sur la plate-forme Mac. Nathan Sobo a expliqué dans un article que dans la base de code du projet Zed sur GitHub, la partie éditeur est sous licence GPL, les composants côté serveur sont sous licence AGPL et la partie GPUI (GPU Accelerated User) l'interface) adopte la Licence Apache2.0. GPUI est un produit développé par l'équipe Zed
 N'attendez pas OpenAI, attendez qu'Open-Sora soit entièrement open source
Mar 18, 2024 pm 08:40 PM
N'attendez pas OpenAI, attendez qu'Open-Sora soit entièrement open source
Mar 18, 2024 pm 08:40 PM
Il n'y a pas si longtemps, OpenAISora est rapidement devenu populaire grâce à ses étonnants effets de génération vidéo. Il s'est démarqué parmi la foule de modèles vidéo littéraires et est devenu le centre d'attention mondiale. Suite au lancement du processus de reproduction d'inférence de formation Sora avec une réduction des coûts de 46 % il y a 2 semaines, l'équipe Colossal-AI a entièrement open source le premier modèle de génération vidéo d'architecture de type Sora au monde "Open-Sora1.0", couvrant l'ensemble processus de formation, y compris le traitement des données, tous les détails de la formation et les poids des modèles, et joignez-vous aux passionnés mondiaux de l'IA pour promouvoir une nouvelle ère de création vidéo. Pour un aperçu, jetons un œil à une vidéo d'une ville animée générée par le modèle « Open-Sora1.0 » publié par l'équipe Colossal-AI. Ouvrir-Sora1.0
 Les performances d'exécution locale du service Embedding dépassent celles d'OpenAI Text-Embedding-Ada-002, ce qui est très pratique !
Apr 15, 2024 am 09:01 AM
Les performances d'exécution locale du service Embedding dépassent celles d'OpenAI Text-Embedding-Ada-002, ce qui est très pratique !
Apr 15, 2024 am 09:01 AM
Ollama est un outil super pratique qui vous permet d'exécuter facilement des modèles open source tels que Llama2, Mistral et Gemma localement. Dans cet article, je vais vous présenter comment utiliser Ollama pour vectoriser du texte. Si vous n'avez pas installé Ollama localement, vous pouvez lire cet article. Dans cet article, nous utiliserons le modèle nomic-embed-text[2]. Il s'agit d'un encodeur de texte qui surpasse OpenAI text-embedding-ada-002 et text-embedding-3-small sur les tâches à contexte court et à contexte long. Démarrez le service nomic-embed-text lorsque vous avez installé avec succès o
 Microsoft et OpenAI prévoient d'investir 100 millions de dollars dans des robots humanoïdes ! Les internautes appellent Musk
Feb 01, 2024 am 11:18 AM
Microsoft et OpenAI prévoient d'investir 100 millions de dollars dans des robots humanoïdes ! Les internautes appellent Musk
Feb 01, 2024 am 11:18 AM
Il a été révélé que Microsoft et OpenAI investissaient de grosses sommes d’argent dans une start-up de robots humanoïdes au début de l’année. Parmi eux, Microsoft prévoit d'investir 95 millions de dollars et OpenAI investira 5 millions de dollars. Selon Bloomberg, la société devrait lever un total de 500 millions de dollars au cours de ce cycle, et sa valorisation pré-monétaire pourrait atteindre 1,9 milliard de dollars. Qu'est-ce qui les attire ? Jetons d’abord un coup d’œil aux réalisations de cette entreprise en matière de robotique. Ce robot est tout argenté et noir, et son apparence ressemble à l'image d'un robot dans un blockbuster de science-fiction hollywoodien : maintenant, il met une capsule de café dans la machine à café : si elle n'est pas placée correctement, elle s'ajustera sans aucun problème. télécommande humaine : Cependant, après un certain temps, une tasse de café peut être emportée et dégustée : Avez-vous des membres de votre famille qui l'ont reconnu ? Oui, ce robot a été créé il y a quelque temps.
 Soudain! OpenAI licencie un allié d'Ilya pour fuite d'informations présumée
Apr 15, 2024 am 09:01 AM
Soudain! OpenAI licencie un allié d'Ilya pour fuite d'informations présumée
Apr 15, 2024 am 09:01 AM
Soudain! OpenAI a licencié des gens, la raison : une fuite d'informations suspectée. L’un d’eux est Léopold Aschenbrenner, un allié du scientifique en chef disparu Ilya et un membre principal de l’équipe Superalignment. L'autre personne n'est pas simple non plus : il s'agit de Pavel Izmailov, chercheur au sein de l'équipe d'inférence du LLM, qui a également travaillé dans l'équipe de super alignement. On ne sait pas exactement quelles informations les deux hommes ont divulguées. Après que la nouvelle ait été révélée, de nombreux internautes se sont dits « assez choqués » : j'ai vu le message d'Aschenbrenner il n'y a pas longtemps et j'ai senti qu'il était en pleine ascension dans sa carrière. Certains internautes sur la photo pensent : OpenAI a perdu Aschenbrenner, je
