
 Périphériques technologiques
IA
Nouvelle technologie lancée, l'IDEA Research Institute a publié le modèle T-Rex, permettant aux utilisateurs de sélectionner les invites « Invite » directement sur l'image.
Périphériques technologiques
IA
Nouvelle technologie lancée, l'IDEA Research Institute a publié le modèle T-Rex, permettant aux utilisateurs de sélectionner les invites « Invite » directement sur l'image.
Nouvelle technologie lancée, l'IDEA Research Institute a publié le modèle T-Rex, permettant aux utilisateurs de sélectionner les invites « Invite » directement sur l'image.

Suite au populaire Grounded SAM, l'équipe de l'IDEA Research Instituteest de retour avec une nouvelle œuvre : une nouvelle invite visuelle (Visual Prompt) modèle T-Re x, utilisez des images pour reconnaître les images, dès la sortie de la boîte,  ouvre un nouveau monde de détection d'ensemble ouvert !
ouvre un nouveau monde de détection d'ensemble ouvert !
Tirez le cadre, vérifiez et complétez ! Lors de la conférence IDEA 2023 qui vient de se terminer, Shen Xiangyang, président fondateur de l'Institut de recherche IDEA et académicien étranger de l'Académie nationale d'ingénierie, a démontré une nouvelle expérience de détection de cibles basée sur des signaux visuels et a publié le laboratoire modèle (aire de jeux) du nouveau modèle d'indices visuels T-Rex ), Interactive Visual Prompt (iVP), a déclenché une vague d'essais culminants sur place.

Sur iVP, les utilisateurs peuvent personnellement débloquer l'expérience d'invite "une image vaut mille mots" : marquez l'objet d'intérêt sur l'image, fournissez un exemple visuel au modèle, et le modèle détectera alors tout objets similaires dans l’image cible. L'ensemble du processus est interactif et peut être facilement réalisé en quelques étapes seulement.
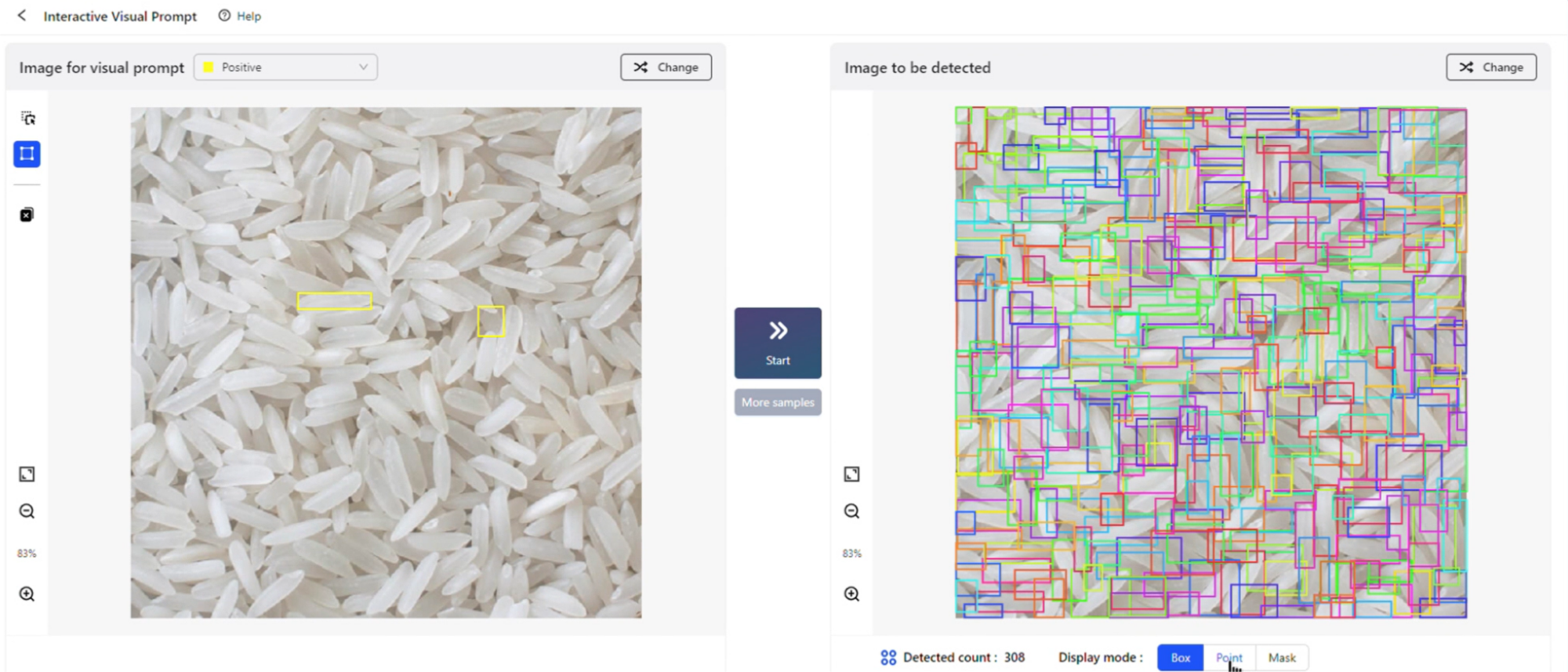
Grounded SAM (Grounding DINO + SAM), publié par IDEA Research Institute en avril, est devenu très populaire sur Github et a collecté jusqu'à présent 11 000 étoiles. Différent de Grounded SAM, qui ne prend en charge que les invites textuelles, le modèle T-Rex publié cette fois fournit une fonction d'invite visuelle qui se concentre sur la création d'une interaction forte.
T-Rex possède de puissantes fonctionnalités prêtes à l'emploi et peut détecter des objets que le modèle n'a jamais vu pendant la phase d'entraînement sans recyclage ni réglage fin. Ce modèle peut non seulement être appliqué à toutes les tâches de détection, y compris le comptage, mais fournit également de nouvelles solutions pour des scénarios d'annotation interactifs intelligents.
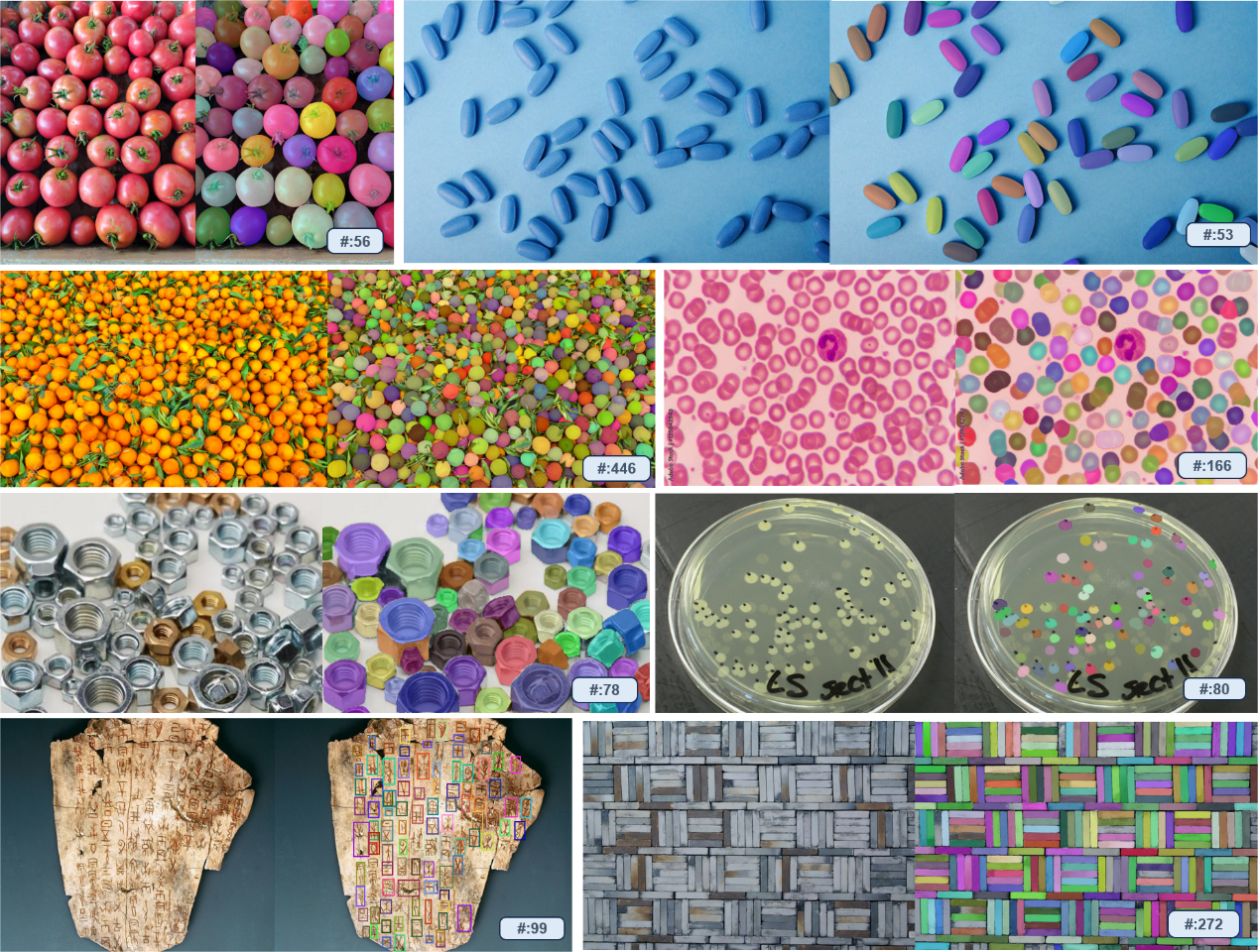
L'équipe a révélé que le développement de la technologie d'invite visuelle était dérivé de l'observation de points douloureux dans des scènes réelles. Certains partenaires espèrent utiliser des modèles visuels pour compter le nombre de marchandises dans les camions. Cependant, le modèle ne peut pas identifier individuellement chaque marchandise au moyen d'invites textuelles uniquement. La raison en est que les objets des scènes industrielles sont rares dans la vie quotidienne et difficiles à décrire avec des mots. Dans ce cas, les repères visuels constituent clairement une approche plus efficace. Dans le même temps, un retour visuel intuitif et une forte interactivité contribuent également à améliorer l’efficacité et la précision de la détection.
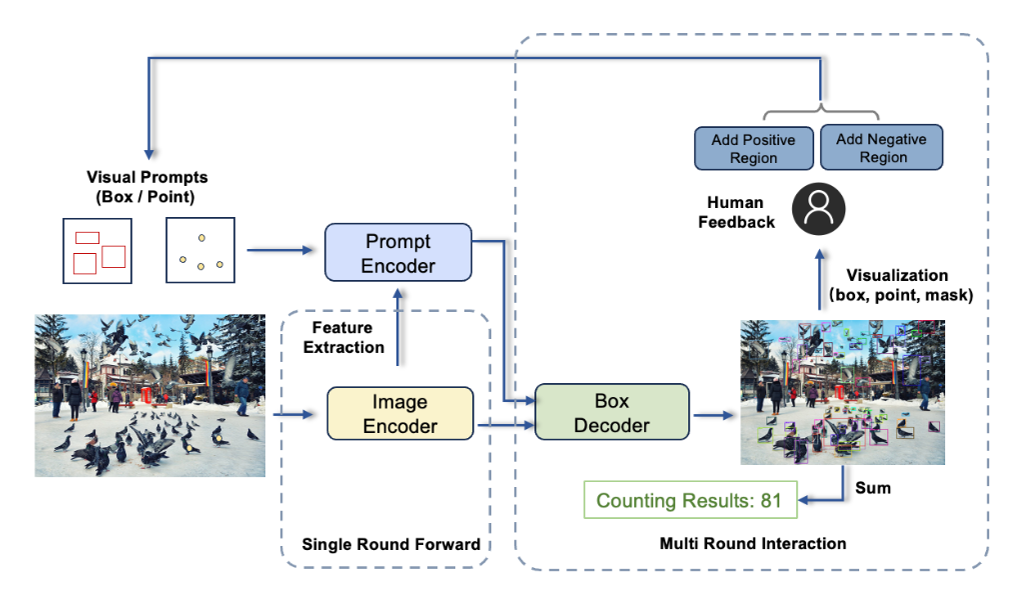
Sur la base d'informations sur les exigences d'utilisation réelles, l'équipe a conçu le T-Rex comme un modèle capable d'accepter plusieurs signaux visuels et d'afficher des invites à travers les images. En plus du mode d'invite à un tour le plus basique, le modèle actuel prend également en charge les trois modes avancés suivants

- Mode positif à plusieurs tours : convient aux scénarios dans lesquels les invites visuelles ne sont pas assez précises et provoquent des détections manquées .
- Mode positif+négatif : convient aux scénarios dans lesquels les signaux visuels sont ambigus et provoquent de fausses détections
- Mode images croisées : convient aux scénarios dans lesquels une seule image de référence provoque la détection d'autres images
Dans le rapport technique publié en même temps À cette époque, l'équipe a résumé T -Quatre caractéristiques principales du modèle Rex :
- Ensemble ouvert : non limité par des catégories prédéfinies, avec la possibilité de détecter tous les objets
- Invites visuelles : utilisez des exemples visuels pour spécifier les cibles de détection à surmonter la difficulté d'utiliser des objets rares et complexes Les questions entièrement exprimées dans le texte améliorent l'efficacité rapide
- Retour visuel intuitif : fournissez un retour visuel intuitif tel que des cadres de délimitation pour aider les utilisateurs à évaluer efficacement les résultats de détection
- Interactivité : les utilisateurs peuvent facilement participer au processus de détection et corriger les résultats du modèle
L'équipe de recherche a souligné que dans les scénarios de détection de cibles, l'ajout d'indices visuels peut compenser certaines des lacunes des indices textuels. À l’avenir, la combinaison des deux permettra de libérer davantage le potentiel de la technologie CV dans des domaines plus verticaux.
Pour les détails techniques du modèle T-Rex, veuillez vous référer au rapport technique publié en même temps.
iVPLaboratoire de modèles : https://deepdataspace.com/playground/ivp
Lien Github : trex-counting.github.io
Ce travail provient du Centre de recherche en vision par ordinateur et robotique de l'Institut IDEA. Le modèle de détection de cible précédemment open source de l'équipe, DINO, a été le premier modèle DETR à atteindre la première place dans le classement de détection de cible COCO ; le très populaire détecteur de tir zéro Grounding DINO sur Github et le DINO peuvent également détecter et segmenter n'importe quel objet Grounded SAM. le travail de cette équipe
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Un didacticiel sur le modèle de diffusion qui vaut votre temps, de l'Université Purdue
Apr 07, 2024 am 09:01 AM
Un didacticiel sur le modèle de diffusion qui vaut votre temps, de l'Université Purdue
Apr 07, 2024 am 09:01 AM
La diffusion permet non seulement de mieux imiter, mais aussi de « créer ». Le modèle de diffusion (DiffusionModel) est un modèle de génération d'images. Par rapport aux algorithmes bien connus tels que GAN et VAE dans le domaine de l’IA, le modèle de diffusion adopte une approche différente. Son idée principale est un processus consistant à ajouter d’abord du bruit à l’image, puis à la débruiter progressivement. Comment débruiter et restaurer l’image originale est la partie centrale de l’algorithme. L'algorithme final est capable de générer une image à partir d'une image bruitée aléatoirement. Ces dernières années, la croissance phénoménale de l’IA générative a permis de nombreuses applications passionnantes dans la génération de texte en image, la génération de vidéos, et bien plus encore. Le principe de base de ces outils génératifs est le concept de diffusion, un mécanisme d'échantillonnage spécial qui surmonte les limites des méthodes précédentes.
 Générez du PPT en un seul clic ! Kimi : Que les « travailleurs migrants PPT » deviennent d'abord populaires
Aug 01, 2024 pm 03:28 PM
Générez du PPT en un seul clic ! Kimi : Que les « travailleurs migrants PPT » deviennent d'abord populaires
Aug 01, 2024 pm 03:28 PM
Kimi : En une seule phrase, un PPT est prêt en seulement dix secondes. PPT est tellement ennuyeux ! Pour tenir une réunion, vous devez avoir un PPT ; pour rédiger un rapport hebdomadaire, vous devez avoir un PPT ; pour solliciter des investissements, vous devez présenter un PPT ; même pour accuser quelqu'un de tricherie, vous devez envoyer un PPT ; L'université ressemble plus à une spécialisation PPT. Vous regardez le PPT en classe et faites le PPT après les cours. Peut-être que lorsque Dennis Austin a inventé le PPT il y a 37 ans, il ne s'attendait pas à ce qu'un jour le PPT devienne aussi répandu. Parler de notre dure expérience de création de PPT nous fait monter les larmes aux yeux. "Il m'a fallu trois mois pour réaliser un PPT de plus de 20 pages, et je l'ai révisé des dizaines de fois. J'avais envie de vomir quand j'ai vu le PPT." "À mon apogée, je faisais cinq PPT par jour, et même ma respiration." était PPT." Si vous avez une réunion impromptue, vous devriez le faire
 Tous les prix CVPR 2024 annoncés ! Près de 10 000 personnes ont assisté à la conférence hors ligne et un chercheur chinois de Google a remporté le prix du meilleur article.
Jun 20, 2024 pm 05:43 PM
Tous les prix CVPR 2024 annoncés ! Près de 10 000 personnes ont assisté à la conférence hors ligne et un chercheur chinois de Google a remporté le prix du meilleur article.
Jun 20, 2024 pm 05:43 PM
Tôt le matin du 20 juin, heure de Pékin, CVPR2024, la plus grande conférence internationale sur la vision par ordinateur qui s'est tenue à Seattle, a officiellement annoncé le meilleur article et d'autres récompenses. Cette année, un total de 10 articles ont remporté des prix, dont 2 meilleurs articles et 2 meilleurs articles étudiants. De plus, il y a eu 2 nominations pour les meilleurs articles et 4 nominations pour les meilleurs articles étudiants. La conférence la plus importante dans le domaine de la vision par ordinateur (CV) est la CVPR, qui attire chaque année un grand nombre d'instituts de recherche et d'universités. Selon les statistiques, un total de 11 532 articles ont été soumis cette année, dont 2 719 ont été acceptés, avec un taux d'acceptation de 23,6 %. Selon l'analyse statistique des données CVPR2024 du Georgia Institute of Technology, du point de vue des sujets de recherche, le plus grand nombre d'articles est la synthèse et la génération d'images et de vidéos (Imageandvideosyn
 Cinq logiciels de programmation pour débuter l'apprentissage du langage C
Feb 19, 2024 pm 04:51 PM
Cinq logiciels de programmation pour débuter l'apprentissage du langage C
Feb 19, 2024 pm 04:51 PM
En tant que langage de programmation largement utilisé, le langage C est l'un des langages de base qui doivent être appris pour ceux qui souhaitent se lancer dans la programmation informatique. Cependant, pour les débutants, l’apprentissage d’un nouveau langage de programmation peut s’avérer quelque peu difficile, notamment en raison du manque d’outils d’apprentissage et de matériel pédagogique pertinents. Dans cet article, je présenterai cinq logiciels de programmation pour aider les débutants à démarrer avec le langage C et vous aider à démarrer rapidement. Le premier logiciel de programmation était Code :: Blocks. Code::Blocks est un environnement de développement intégré (IDE) gratuit et open source pour
 Du bare metal au grand modèle avec 70 milliards de paramètres, voici un tutoriel et des scripts prêts à l'emploi
Jul 24, 2024 pm 08:13 PM
Du bare metal au grand modèle avec 70 milliards de paramètres, voici un tutoriel et des scripts prêts à l'emploi
Jul 24, 2024 pm 08:13 PM
Nous savons que le LLM est formé sur des clusters informatiques à grande échelle utilisant des données massives. Ce site a présenté de nombreuses méthodes et technologies utilisées pour aider et améliorer le processus de formation LLM. Aujourd'hui, ce que nous souhaitons partager est un article qui approfondit la technologie sous-jacente et présente comment transformer un ensemble de « bare metals » sans même un système d'exploitation en un cluster informatique pour la formation LLM. Cet article provient d'Imbue, une startup d'IA qui s'efforce d'atteindre une intelligence générale en comprenant comment les machines pensent. Bien sûr, transformer un tas de « bare metal » sans système d'exploitation en un cluster informatique pour la formation LLM n'est pas un processus facile, plein d'exploration et d'essais et d'erreurs, mais Imbue a finalement réussi à former un LLM avec 70 milliards de paramètres et dans. le processus s'accumule
 Guide d'installation de PyCharm Community Edition : maîtrisez rapidement toutes les étapes
Jan 27, 2024 am 09:10 AM
Guide d'installation de PyCharm Community Edition : maîtrisez rapidement toutes les étapes
Jan 27, 2024 am 09:10 AM
Démarrage rapide avec PyCharm Community Edition : Tutoriel d'installation détaillé Analyse complète Introduction : PyCharm est un puissant environnement de développement intégré (IDE) Python qui fournit un ensemble complet d'outils pour aider les développeurs à écrire du code Python plus efficacement. Cet article présentera en détail comment installer PyCharm Community Edition et fournira des exemples de code spécifiques pour aider les débutants à démarrer rapidement. Étape 1 : Téléchargez et installez PyCharm Community Edition Pour utiliser PyCharm, vous devez d'abord le télécharger depuis son site officiel
 L'IA utilisée | L'IA a créé un vlog sur la vie d'une fille vivant seule, qui a reçu des dizaines de milliers de likes en 3 jours
Aug 07, 2024 pm 10:53 PM
L'IA utilisée | L'IA a créé un vlog sur la vie d'une fille vivant seule, qui a reçu des dizaines de milliers de likes en 3 jours
Aug 07, 2024 pm 10:53 PM
Rédacteur du Machine Power Report : Yang Wen La vague d’intelligence artificielle représentée par les grands modèles et l’AIGC a discrètement changé notre façon de vivre et de travailler, mais la plupart des gens ne savent toujours pas comment l’utiliser. C'est pourquoi nous avons lancé la rubrique « AI in Use » pour présenter en détail comment utiliser l'IA à travers des cas d'utilisation de l'intelligence artificielle intuitifs, intéressants et concis et stimuler la réflexion de chacun. Nous invitons également les lecteurs à soumettre des cas d'utilisation innovants et pratiques. Lien vidéo : https://mp.weixin.qq.com/s/2hX_i7li3RqdE4u016yGhQ Récemment, le vlog de la vie d'une fille vivant seule est devenu populaire sur Xiaohongshu. Une animation de style illustration, associée à quelques mots de guérison, peut être facilement récupérée en quelques jours seulement.
 A lire absolument pour les débutants en technique : Analyse des niveaux de difficulté du langage C et Python
Mar 22, 2024 am 10:21 AM
A lire absolument pour les débutants en technique : Analyse des niveaux de difficulté du langage C et Python
Mar 22, 2024 am 10:21 AM
Titre : Une lecture incontournable pour les débutants en technique : Analyse des difficultés du langage C et de Python, nécessitant des exemples de code spécifiques. À l'ère numérique d'aujourd'hui, la technologie de programmation est devenue une capacité de plus en plus importante. Que vous souhaitiez travailler dans des domaines tels que le développement de logiciels, l'analyse de données, l'intelligence artificielle ou simplement apprendre la programmation par intérêt, choisir un langage de programmation adapté est la première étape. Parmi les nombreux langages de programmation, le langage C et Python sont deux langages de programmation largement utilisés, chacun ayant ses propres caractéristiques. Cet article analysera les niveaux de difficulté du langage C et Python
