
新标题:sparse4d v3:推进端到端的3d检测和跟踪技术
论文链接:https://arxiv.org/pdf/2311.11722.pdf
需要重新写的内容是:代码链接:https://github.com/linxuewu/Sparse4D
重新写的内容:作者所属单位为地平线公司

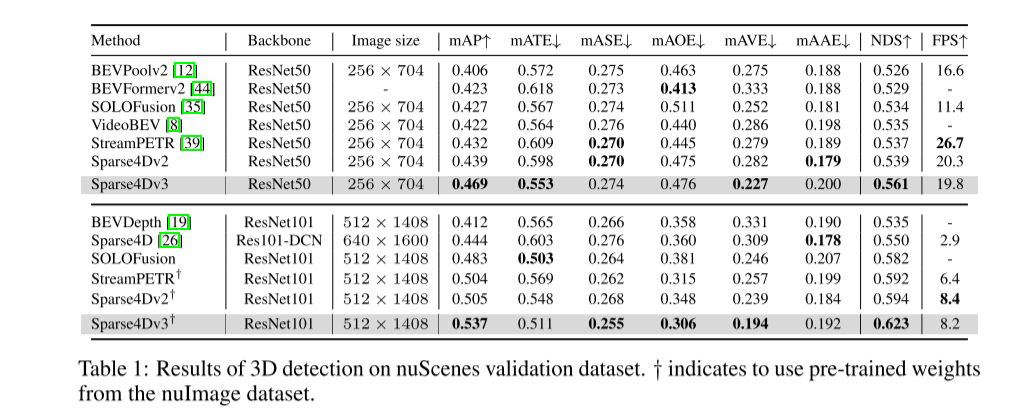
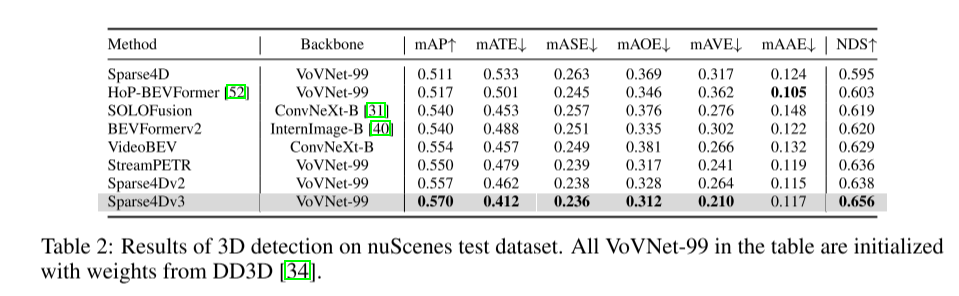
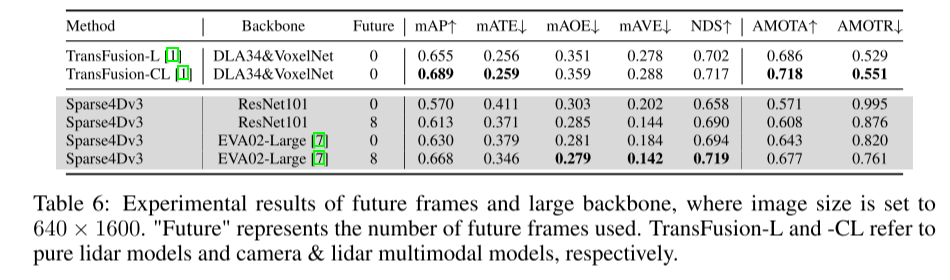
在自动驾驶感知系统中,3D检测和跟踪是两项基本任务。本文基于 Sparse4D 框架更深入地研究了该领域。本文引入了两个辅助训练任务(时序实例去噪-Temporal Instance Denoising和质量估计-Quality Estimation),并提出解耦注意力(decoupled attention)来进行结构改进,从而显着提高检测性能。此外,本文使用一种简单的方法将检测器扩展到跟踪器,该方法在推理过程中分配实例 ID,进一步突出了 query-based 算法的优势。在 nuScenes 基准上进行的大量实验验证了所提出的改进的有效性。以ResNet50为骨干,mAP、NDS和AMOTA分别提高了3.0%、2.2%和7.6%,分别达到46.9%、56.1%和49.0%。本文最好的模型在 nuScenes 测试集上实现了 71.9% NDS 和 67.7% AMOTA
Sparse4D-v3 是一个强大的 3D 感知框架,它提出了三种有效的策略:时序实例去噪、质量估计和解耦注意力
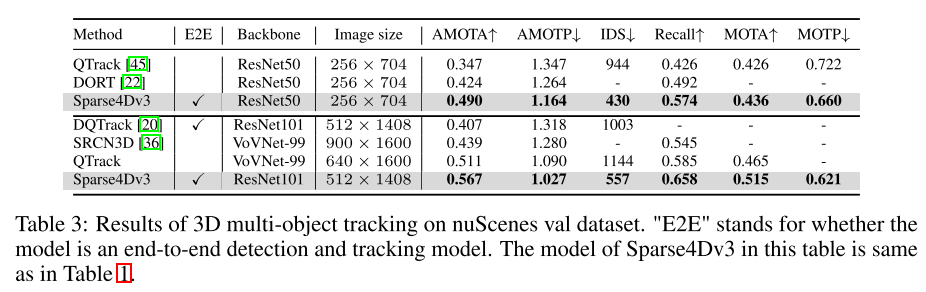
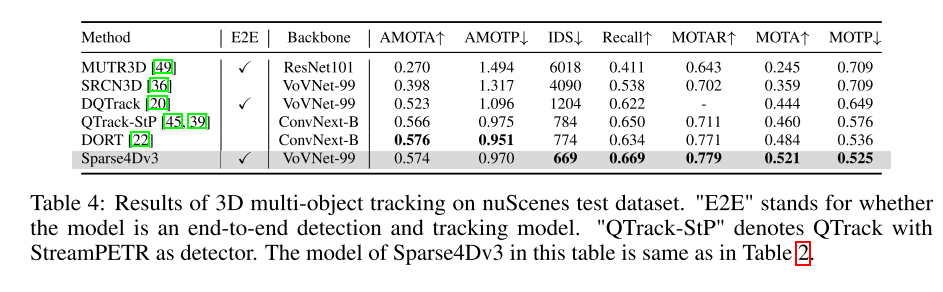
本文将 Sparse4D 扩展为端到端跟踪模型。
本文展示了 nuScenes 改进的有效性,在检测和跟踪任务中实现了最先进的性能。
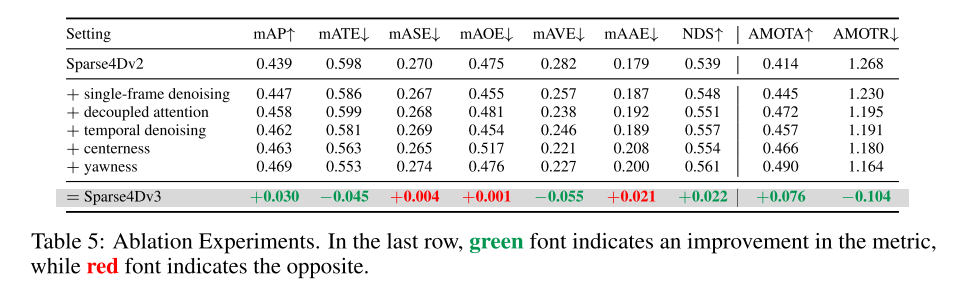
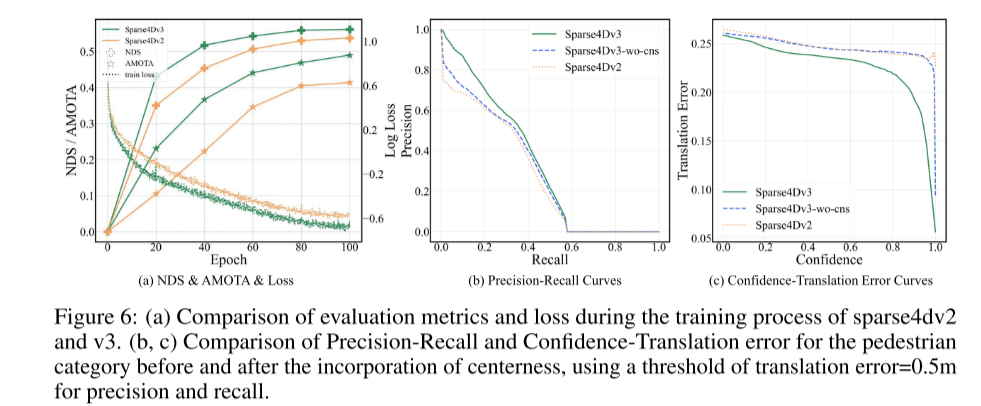
首先,观察到与稠密算法相比,稀疏算法在收敛方面面临更大的挑战,从而影响了最终性能。这个问题已经在2D检测领域得到了充分研究[17,48,53],主要原因是稀疏算法使用了一对一的正样本匹配。这种匹配方式在训练初期不稳定,而且与一对多匹配相比,正样本数量有限,从而降低了解码器训练的效率。此外,Sparse4D使用稀疏特征采样而不是全局交叉注意力,由于正样本稀缺,这进一步阻碍了编码器的收敛。在Sparse4Dv2中,引入了密集深度监督来部分缓解图像编码器面临的这些收敛问题。本文的主要目标是通过关注解码器训练的稳定性来增强模型性能。本文将去噪任务作为辅助监督,并将去噪技术从2D单帧检测扩展到3D时序检测。这不仅保证了稳定的正样本匹配,而且显著增加了正样本的数量。此外,本文还引入了质量评估任务作为辅助监督。这使得输出的置信度分数更加合理,提高了检测结果排名的准确性,从而获得更高的评估指标。此外,本文改进了Sparse4D中实例自注意力和时序交叉注意力模块的结构,引入了一种解耦注意力机制,旨在减少注意力权重计算过程中的特征干扰。通过将锚点嵌入和实例特征作为注意力计算的输入,可以减少注意力权重中存在异常值的实例。这样可以更准确地反映目标特征之间的相互关联,从而实现正确的特征聚合。本文使用连接而不是注意力机制来显著减少这种错误。这种增强方法与条件DETR有相似之处,但关键区别在于本文强调查询之间的注意力,而条件DETR则专注于查询和图像特征之间的交叉注意力。此外,本文还涉及独特的编码方法
为了提高感知系统的端到端能力,本文研究了将3D多目标跟踪任务集成到Sparse4D框架中的方法,以直接输出目标的运动轨迹。与基于检测的跟踪方法不同,本文通过消除数据关联和过滤的需求,将所有跟踪功能整合到检测器中。此外,与现有的联合检测和跟踪方法不同,本文的跟踪器在训练过程中无需进行修改或调整损失函数。它不需要提供ground truth IDs,而是实现了预定义的实例到跟踪的回归。本文的跟踪实现充分融合了检测器和跟踪器,无需修改检测器的训练过程,也无需额外微调
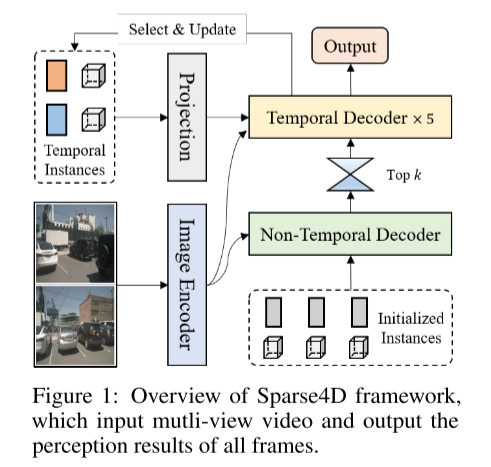
这是一个关于Sparse4D框架概述的图1,输入是多视图视频,输出是所有帧的感知结果
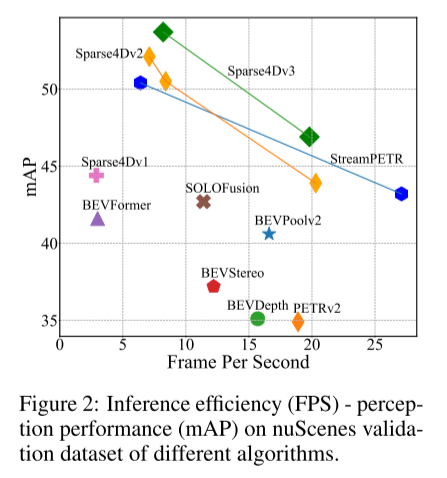
图 2:不同算法的 nuScenes 验证数据集上的推理效率 (FPS) - 感知性能 (mAP)。

图 3:实例自注意力中的注意力权重的可视化:1)第一行显示了普通自注意力中的注意力权重,其中红色圆圈中的行人显示出与目标车辆(绿色框)的意外相关性。2)第二行显示了解耦注意力中的注意力权重,有效解决了该问题。
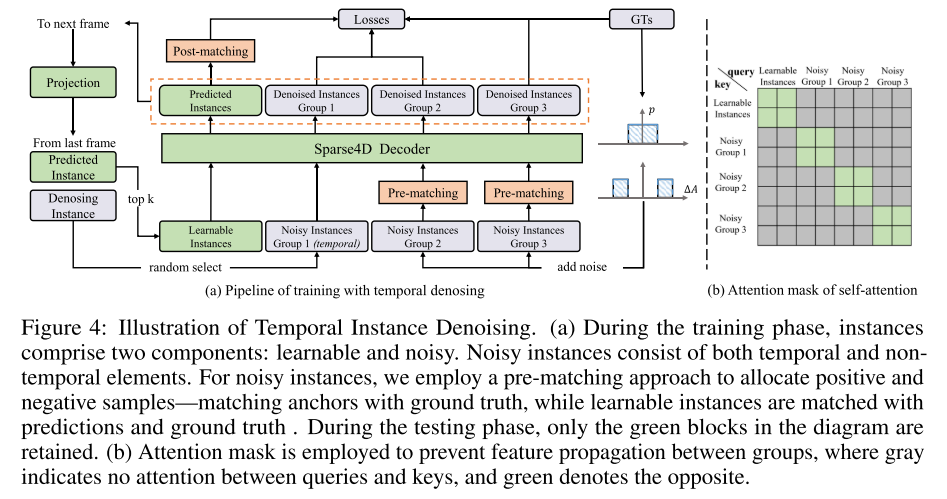
第四张图展示了时序实例去噪的示例。在训练阶段,实例包括两个部分:可学习的和噪声的。噪声实例由时间和非时间元素组成。本文采用预匹配方法来分配正样本和负样本,即将 anchors 与 ground truth 进行匹配,而可学习实例则与预测和 ground truth 进行匹配。在测试阶段,只保留绿色块。为防止特征在 groups 之间传播,采用了 Attention mask,灰色表示 queries 和 keys 之间没有注意力,绿色表示相反
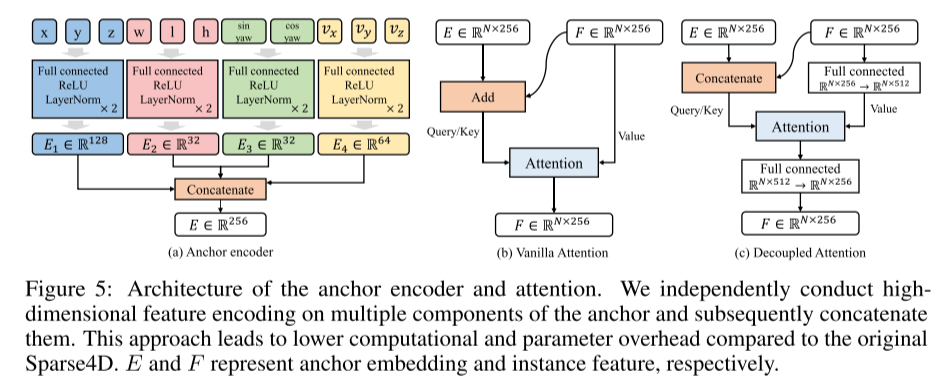
请看图5:锚点编码器和注意力的架构。本文独立地对锚点的多个组件进行了高维特征编码,然后将它们连接起来。与原始的Sparse4D相比,这种方法可以减少计算和参数的开销。E和F分别表示锚点嵌入和实例特征

本文首先提出了增强 Sparse4D 检测性能的方法。这一增强主要包括三个方面:时序实例去噪、质量估计和解耦注意力。随后,本文说明了将 Sparse4D 扩展为端到端跟踪模型的过程。本文在 nuScenes 上的实验表明,这些增强功能显着提高了性能,使 Sparse4Dv3 处于该领域的前沿。
Lin, X., Pei, Z., Lin, T., Huang, L., & Su, Z. (2023). Sparse4D v3: Advancing End-to-End 3D Detection and Tracking. ArXiv. /abs/2311.11722
以上就是Sparse4D v3来了!推进端到端3D检测和跟踪的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告![ThinkPHP5快速开发企业站点[全程实录]](https://img.php.cn/upload/course/000/000/068/6253d918a3ce7278.png)


Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号




 736
736























