
{"SystemParams": {"pluginBaseUrl": "","vectorMaxProcess": 15,"qaMaxProcess": 15,"pgHNSWEfSearch": 100},"ChatModels": [{"model": "gpt-3.5-turbo-1106","name": "GPT35-1106","price": 0,"maxContext": 16000,"maxResponse": 4000,"quoteMaxToken": 2000,"maxTemperature": 1.2,"censor": false,"vision": false,"defaultSystemChatPrompt": ""},{"model": "gpt-3.5-turbo-16k","name": "GPT35-16k","maxContext": 16000,"maxResponse": 16000,"price": 0,"quoteMaxToken": 8000,"maxTemperature": 1.2,"censor": false,"vision": false,"defaultSystemChatPrompt": ""},{"model": "gpt-4","name": "GPT4-8k","maxContext": 8000,"maxResponse": 8000,"price": 0,"quoteMaxToken": 4000,"maxTemperature": 1.2,"censor": false,"vision": false,"defaultSystemChatPrompt": ""},{"model": "gpt-4-vision-preview","name": "GPT4-Vision","maxContext": 128000,"maxResponse": 4000,"price": 0,"quoteMaxToken": 100000,"maxTemperature": 1.2,"censor": false,"vision": true,"defaultSystemChatPrompt": ""}],"QAModels": [{"model": "gpt-3.5-turbo-16k","name": "GPT35-16k","maxContext": 16000,"maxResponse": 16000,"price": 0}],"CQModels": [{"model": "gpt-3.5-turbo-1106","name": "GPT35-1106","maxContext": 16000,"maxResponse": 4000,"price": 0,"functionCall": true,"functionPrompt": ""},{"model": "gpt-4","name": "GPT4-8k","maxContext": 8000,"maxResponse": 8000,"price": 0,"functionCall": true,"functionPrompt": ""}],"ExtractModels": [{"model": "gpt-3.5-turbo-1106","name": "GPT35-1106","maxContext": 16000,"maxResponse": 4000,"price": 0,"functionCall": true,"functionPrompt": ""}],"QGModels": [{"model": "gpt-3.5-turbo-1106","name": "GPT35-1106","maxContext": 1600,"maxResponse": 4000,"price": 0}],"VectorModels": [{"model": "text-embedding-ada-002","name": "Embedding-2","price": 0.2,"defaultToken": 700,"maxToken": 3000}],"AudioSpeechModels": [{"model": "tts-1","name": "OpenAI TTS1","price": 0,"voices": [{"label": "Alloy","value": "alloy","bufferId": "openai-Alloy"},{"label": "Echo","value": "echo","bufferId": "openai-Echo"},{"label": "Fable","value": "fable","bufferId": "openai-Fable"},{"label": "Onyx","value": "onyx","bufferId": "openai-Onyx"},{"label": "Nova","value": "nova","bufferId": "openai-Nova"},{"label": "Shimmer","value": "shimmer","bufferId": "openai-Shimmer"}]}],"WhisperModel": {"model": "whisper-1","name": "Whisper1","price": 0}} Périphériques technologiques
IA
Créez rapidement une grande base de connaissances sur l'IA en matière de modèles de langage en seulement trois minutes
Périphériques technologiques
IA
Créez rapidement une grande base de connaissances sur l'IA en matière de modèles de langage en seulement trois minutes
Créez rapidement une grande base de connaissances sur l'IA en matière de modèles de langage en seulement trois minutes

FastGPT
FastGPT est un système de questions et réponses de base de connaissances construit à l'aide du grand modèle de langage LLM, qui peut fournir des fonctions de traitement de données plug-and-play et d'appel de modèle. Dans le même temps, il prend également en charge l'orchestration visuelle du flux de travail Flow pour réaliser des scénarios de questions et réponses complexes.
Ici, nous utilisons Docker Compose pour effectuer rapidement un déploiement privatisé de FastGPT
1 Installez Docker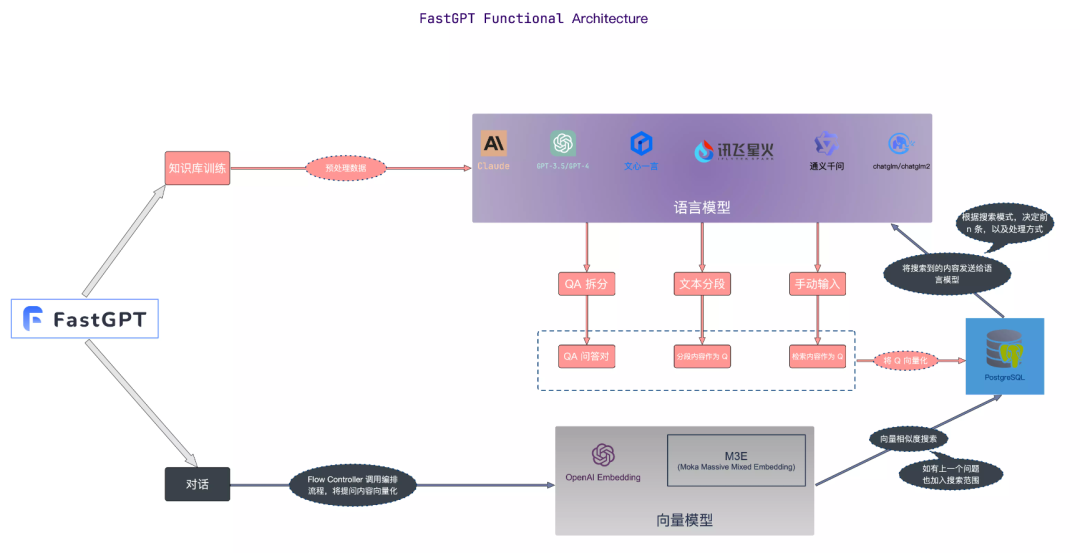
# 安装 Dockercurl -fsSL https://get.docker.com | bash -s docker --mirror Aliyunsystemctl enable --now docker# 安装 docker-composecurl -L https://github.com/docker/compose/releases/download/2.20.3/docker-compose-`uname -s`-`uname -m` -o /usr/local/bin/docker-composechmod +x /usr/local/bin/docker-compose# 验证安装docker -vdocker-compose -v
mkdir tinywan-fastgptcd tinywan-fastgpt
Le chemin du répertoire créé ci-dessus est /d/Tinywan/GPT/tinywan-fastgpt
Remarque : veuillez remplir la valeur correspondant à CHAT_API_KEY. fichier de configuration config.jsondocker-compose.yml fichier de configuration
version: '3.3'services:pg:image: registry.cn-hangzhou.aliyuncs.com/fastgpt/pgvector:v0.5.0 # 阿里云container_name: pgrestart: alwaysports: # 生产环境建议不要暴露- 5432:5432networks:- fastgptenvironment:# 这里的配置只有首次运行生效。修改后,重启镜像是不会生效的。需要把持久化数据删除再重启,才有效果- POSTGRES_USER=username- POSTGRES_PASSWORD=password- POSTGRES_DB=postgresvolumes:- ./pg/data:/var/lib/postgresql/datamongo:image: mongo:5.0.18# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/mongo:5.0.18 # 阿里云container_name: mongorestart: alwaysports: # 生产环境建议不要暴露- 27017:27017networks:- fastgptenvironment:# 这里的配置只有首次运行生效。修改后,重启镜像是不会生效的。需要把持久化数据删除再重启,才有效果- MONGO_INITDB_ROOT_USERNAME=username- MONGO_INITDB_ROOT_PASSWORD=passwordvolumes:- ./mongo/data:/data/dbfastgpt:container_name: fastgptimage: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt:latest # 阿里云ports:- 3000:3000networks:- fastgptdepends_on:- mongo- pgrestart: alwaysenvironment:# root 密码,用户名为: root- DEFAULT_ROOT_PSW=123465# 中转地址,如果是用官方号,不需要管- OPENAI_BASE_URL=https://api.openai.com/v1- CHAT_API_KEY=sb-xxx- DB_MAX_LINK=5 # database max link- TOKEN_KEY=any- ROOT_KEY=root_key- FILE_TOKEN_KEY=filetoken# mongo 配置,不需要改. 如果连不上,可能需要去掉 ?authSource=admin- MONGODB_URI=mongodb://username:password@mongo:27017/fastgpt?authSource=admin# pg配置. 不需要改- PG_URL=postgresql://username:password@pg:5432/postgresvolumes:- ./config.json:/app/data/config.jsonnetworks:fastgpt:Copier après la connexion
{"SystemParams": {"pluginBaseUrl": "","vectorMaxProcess": 15,"qaMaxProcess": 15,"pgHNSWEfSearch": 100},"ChatModels": [{"model": "gpt-3.5-turbo-1106","name": "GPT35-1106","price": 0,"maxContext": 16000,"maxResponse": 4000,"quoteMaxToken": 2000,"maxTemperature": 1.2,"censor": false,"vision": false,"defaultSystemChatPrompt": ""},{"model": "gpt-3.5-turbo-16k","name": "GPT35-16k","maxContext": 16000,"maxResponse": 16000,"price": 0,"quoteMaxToken": 8000,"maxTemperature": 1.2,"censor": false,"vision": false,"defaultSystemChatPrompt": ""},{"model": "gpt-4","name": "GPT4-8k","maxContext": 8000,"maxResponse": 8000,"price": 0,"quoteMaxToken": 4000,"maxTemperature": 1.2,"censor": false,"vision": false,"defaultSystemChatPrompt": ""},{"model": "gpt-4-vision-preview","name": "GPT4-Vision","maxContext": 128000,"maxResponse": 4000,"price": 0,"quoteMaxToken": 100000,"maxTemperature": 1.2,"censor": false,"vision": true,"defaultSystemChatPrompt": ""}],"QAModels": [{"model": "gpt-3.5-turbo-16k","name": "GPT35-16k","maxContext": 16000,"maxResponse": 16000,"price": 0}],"CQModels": [{"model": "gpt-3.5-turbo-1106","name": "GPT35-1106","maxContext": 16000,"maxResponse": 4000,"price": 0,"functionCall": true,"functionPrompt": ""},{"model": "gpt-4","name": "GPT4-8k","maxContext": 8000,"maxResponse": 8000,"price": 0,"functionCall": true,"functionPrompt": ""}],"ExtractModels": [{"model": "gpt-3.5-turbo-1106","name": "GPT35-1106","maxContext": 16000,"maxResponse": 4000,"price": 0,"functionCall": true,"functionPrompt": ""}],"QGModels": [{"model": "gpt-3.5-turbo-1106","name": "GPT35-1106","maxContext": 1600,"maxResponse": 4000,"price": 0}],"VectorModels": [{"model": "text-embedding-ada-002","name": "Embedding-2","price": 0.2,"defaultToken": 700,"maxToken": 3000}],"AudioSpeechModels": [{"model": "tts-1","name": "OpenAI TTS1","price": 0,"voices": [{"label": "Alloy","value": "alloy","bufferId": "openai-Alloy"},{"label": "Echo","value": "echo","bufferId": "openai-Echo"},{"label": "Fable","value": "fable","bufferId": "openai-Fable"},{"label": "Onyx","value": "onyx","bufferId": "openai-Onyx"},{"label": "Nova","value": "nova","bufferId": "openai-Nova"},{"label": "Shimmer","value": "shimmer","bufferId": "openai-Shimmer"}]}],"WhisperModel": {"model": "whisper-1","name": "Whisper1","price": 0}}Copier après la connexion
3. Démarrez le conteneur{"SystemParams": {"pluginBaseUrl": "","vectorMaxProcess": 15,"qaMaxProcess": 15,"pgHNSWEfSearch": 100},"ChatModels": [{"model": "gpt-3.5-turbo-1106","name": "GPT35-1106","price": 0,"maxContext": 16000,"maxResponse": 4000,"quoteMaxToken": 2000,"maxTemperature": 1.2,"censor": false,"vision": false,"defaultSystemChatPrompt": ""},{"model": "gpt-3.5-turbo-16k","name": "GPT35-16k","maxContext": 16000,"maxResponse": 16000,"price": 0,"quoteMaxToken": 8000,"maxTemperature": 1.2,"censor": false,"vision": false,"defaultSystemChatPrompt": ""},{"model": "gpt-4","name": "GPT4-8k","maxContext": 8000,"maxResponse": 8000,"price": 0,"quoteMaxToken": 4000,"maxTemperature": 1.2,"censor": false,"vision": false,"defaultSystemChatPrompt": ""},{"model": "gpt-4-vision-preview","name": "GPT4-Vision","maxContext": 128000,"maxResponse": 4000,"price": 0,"quoteMaxToken": 100000,"maxTemperature": 1.2,"censor": false,"vision": true,"defaultSystemChatPrompt": ""}],"QAModels": [{"model": "gpt-3.5-turbo-16k","name": "GPT35-16k","maxContext": 16000,"maxResponse": 16000,"price": 0}],"CQModels": [{"model": "gpt-3.5-turbo-1106","name": "GPT35-1106","maxContext": 16000,"maxResponse": 4000,"price": 0,"functionCall": true,"functionPrompt": ""},{"model": "gpt-4","name": "GPT4-8k","maxContext": 8000,"maxResponse": 8000,"price": 0,"functionCall": true,"functionPrompt": ""}],"ExtractModels": [{"model": "gpt-3.5-turbo-1106","name": "GPT35-1106","maxContext": 16000,"maxResponse": 4000,"price": 0,"functionCall": true,"functionPrompt": ""}],"QGModels": [{"model": "gpt-3.5-turbo-1106","name": "GPT35-1106","maxContext": 1600,"maxResponse": 4000,"price": 0}],"VectorModels": [{"model": "text-embedding-ada-002","name": "Embedding-2","price": 0.2,"defaultToken": 700,"maxToken": 3000}],"AudioSpeechModels": [{"model": "tts-1","name": "OpenAI TTS1","price": 0,"voices": [{"label": "Alloy","value": "alloy","bufferId": "openai-Alloy"},{"label": "Echo","value": "echo","bufferId": "openai-Echo"},{"label": "Fable","value": "fable","bufferId": "openai-Fable"},{"label": "Onyx","value": "onyx","bufferId": "openai-Onyx"},{"label": "Nova","value": "nova","bufferId": "openai-Nova"},{"label": "Shimmer","value": "shimmer","bufferId": "openai-Shimmer"}]}],"WhisperModel": {"model": "whisper-1","name": "Whisper1","price": 0}}Obtenez la version mise à jour de l'image via la commande docker-compose pullpicture Démarrez le conteneur via la commande docker- composer up -d
Pictures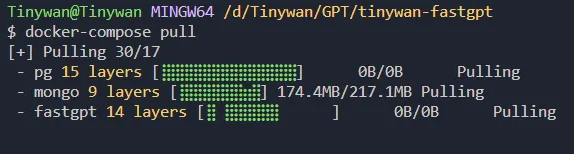
Pictures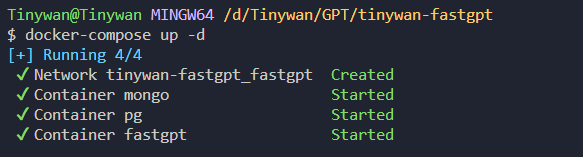 4. L'accès à FastGPT
4. L'accès à FastGPT
est actuellement accessible directement via ip:3000. Il s'agit d'un déploiement local, vous pouvez donc y accéder directement via http://127.0.0.1:3000.Le déploiement est réussi et vous pouvez accéder à la page suivante :
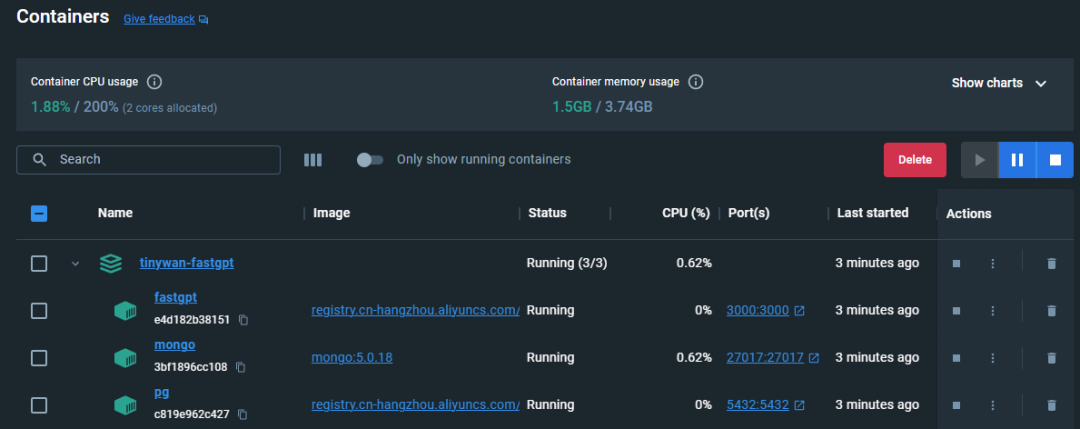
Le nom d'utilisateur de connexion est root et le mot de passe est DEFAULT_ROOT_PSW défini dans la variable d'environnement docker-compose.yml.
Après une connexion réussie, vous serez redirigé vers la page suivante :
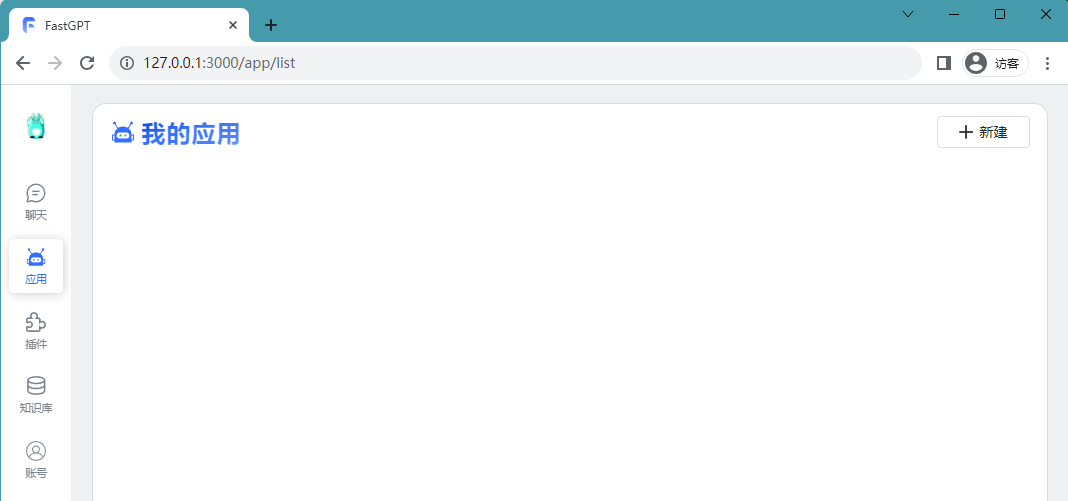
Images 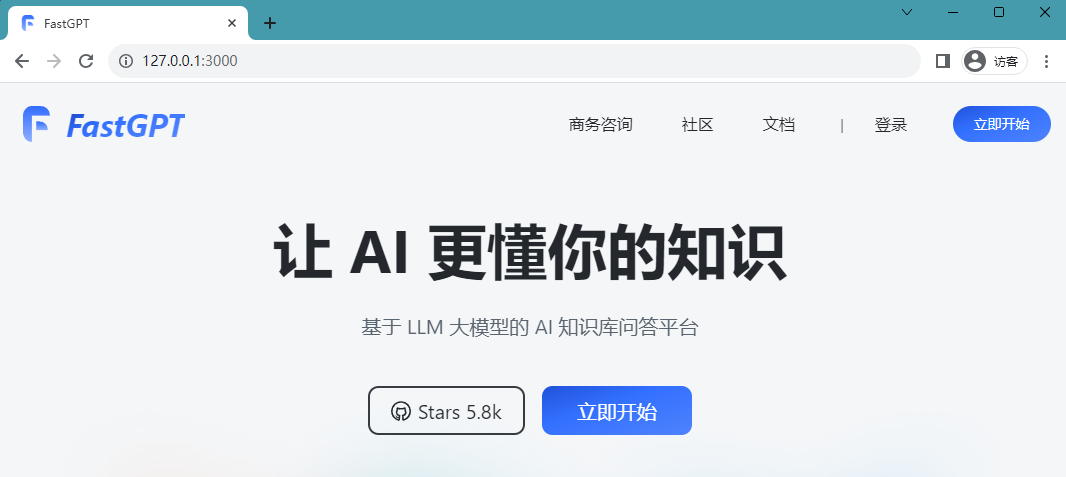 Créer une base de connaissances
Créer une base de connaissances
Créer une base de connaissances
Après une connexion réussie, nous pouvons créer une nouvelle base de connaissances et la nommer technologie open source Xiaozhan
 Images
Images
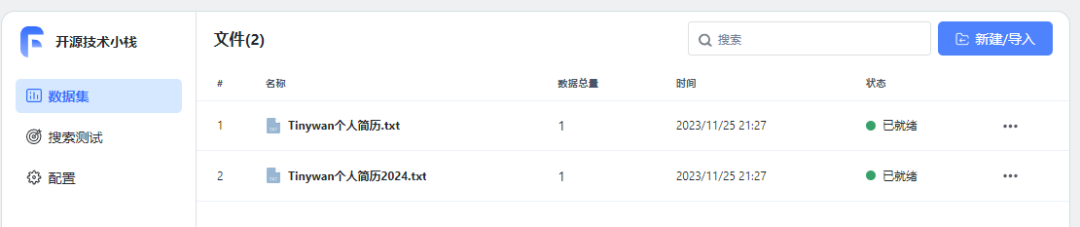
La façon d'importer des expériences personnelles dans la base de connaissances se fait via des fichiers
Le contenu qui doit être réécrit est : [Nouveau/Importer] [Importer un fichier]. Contenu réécrit : [Créer/Importer] [Importer un fichier]
Images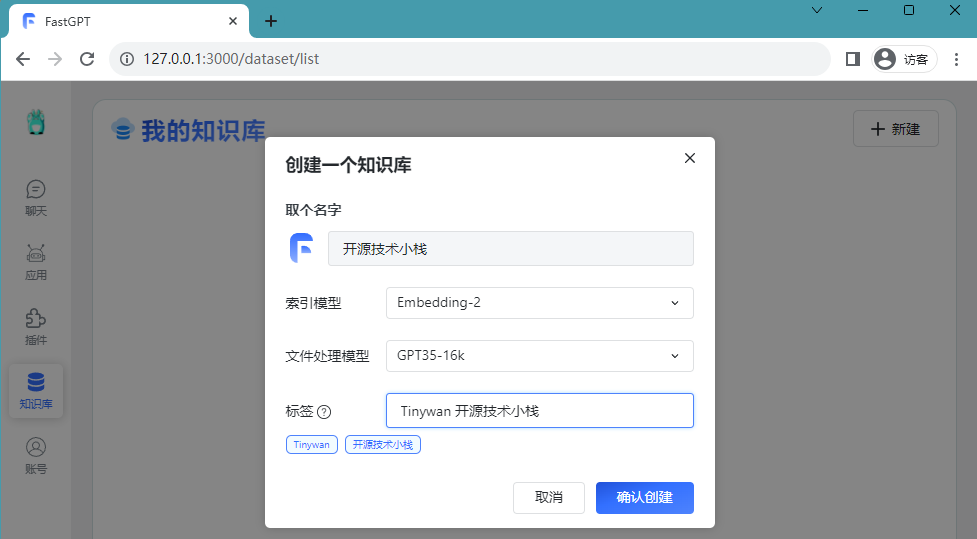 Après confirmation, commencez à convertir les données actuelles en données vectorielles
Après confirmation, commencez à convertir les données actuelles en données vectorielles
Images
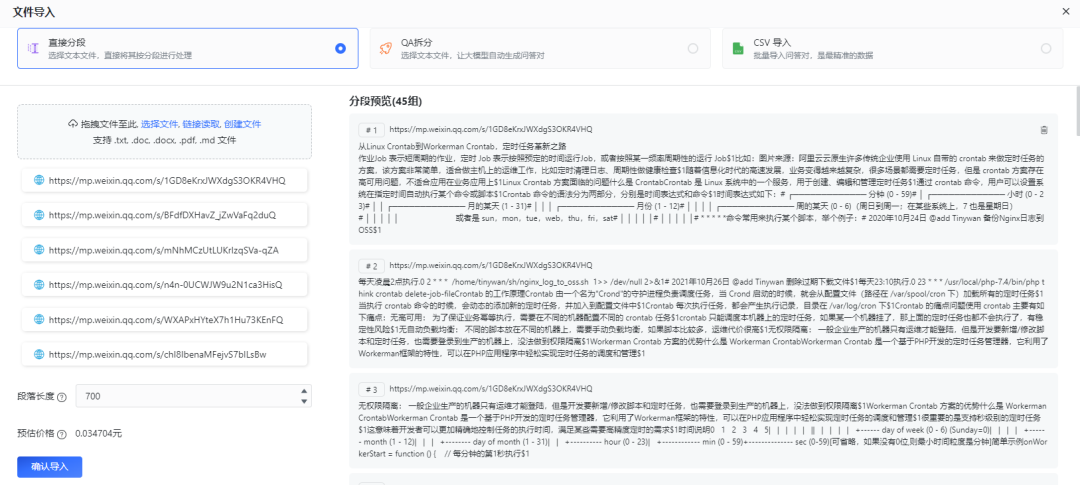
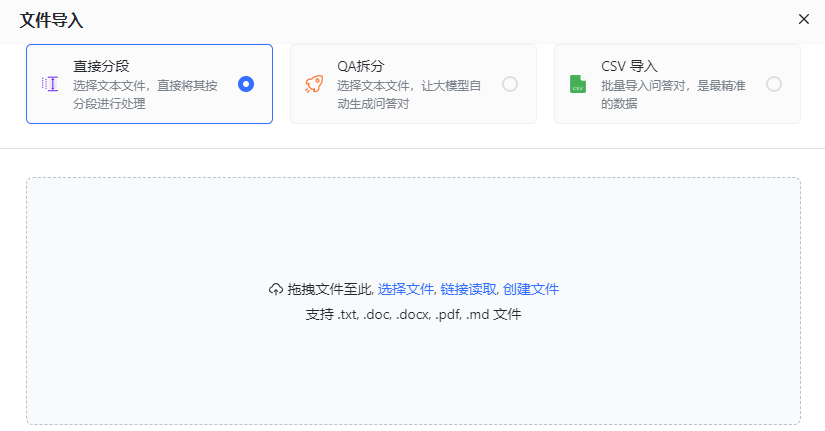 Lors de la sélection d'un fichier à importer, vous pouvez choisir de directement Plan de segmentation. La segmentation directe utilisera le segmenteur de phrases pour diviser le texte à une certaine longueur, et enfin le diviser en plusieurs groupes de q. Si vous choisissez la solution de segmentation directe, il est recommandé d'utiliser un modèle général lors de la définition des mots d'invite de citation dans l'application. Il n'est pas nécessaire de sélectionner un modèle de questions et réponses Importation réussie
Lors de la sélection d'un fichier à importer, vous pouvez choisir de directement Plan de segmentation. La segmentation directe utilisera le segmenteur de phrases pour diviser le texte à une certaine longueur, et enfin le diviser en plusieurs groupes de q. Si vous choisissez la solution de segmentation directe, il est recommandé d'utiliser un modèle général lors de la définition des mots d'invite de citation dans l'application. Il n'est pas nécessaire de sélectionner un modèle de questions et réponses Importation réussie
 图片
图片
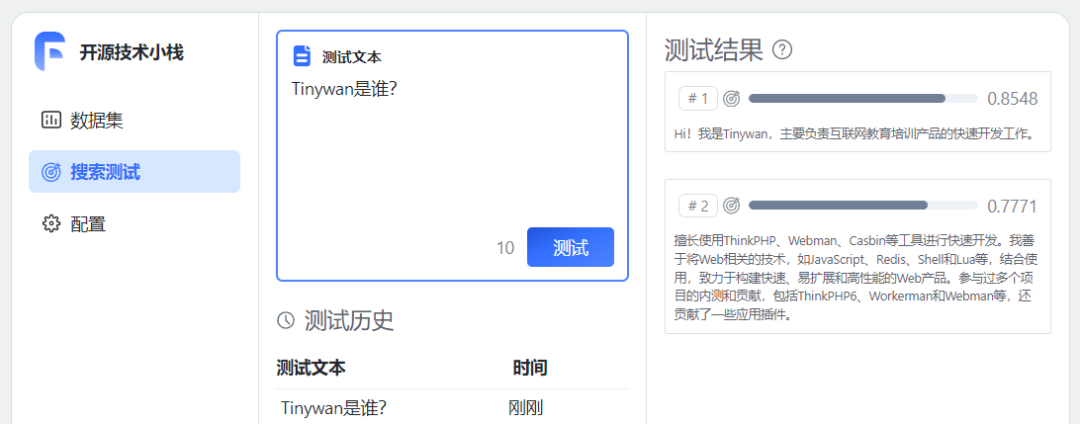
至此,个人知识库已经建好了。尝试进行测试问答
 图片
图片
重新书写后的内容:重新连接训练数据
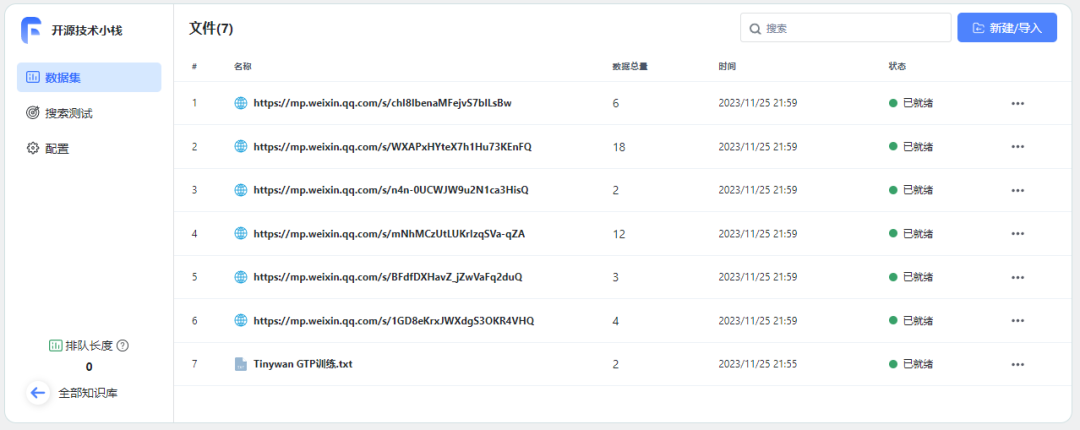
https://mp.weixin.qq.com/s/1GD8eKrxJWXdgS3OKR4VHQhttps://mp.weixin.qq.com/s/BFdfDXHavZ_jZwVaFq2duQhttps://mp.weixin.qq.com/s/mNhMCzUtLUKrIzqSVa-qZAhttps://mp.weixin.qq.com/s/n4n-0UCWJW9u2N1ca3HisQhttps://mp.weixin.qq.com/s/WXAPxHYteX7h1Hu73KEnFQhttps://mp.weixin.qq.com/s/chI8IbenaMFejvS7blLsBw
 图片
图片
等待所有数据准备就绪
 图片
图片
使用知识库
创建应用
使用知识库必须要创建一个应用
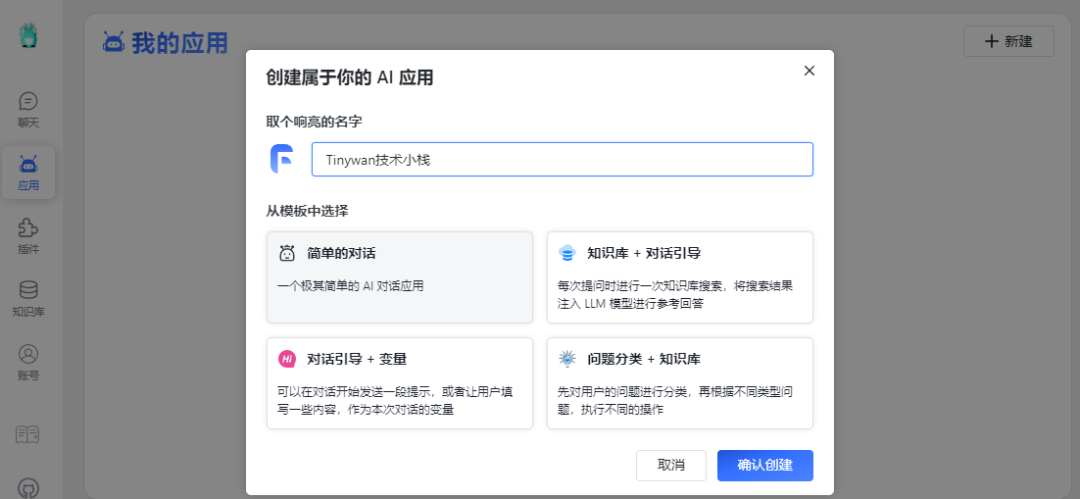 图片
图片
关联知识库
已添加开场白并选择绑定相应的知识库开源技术堆栈
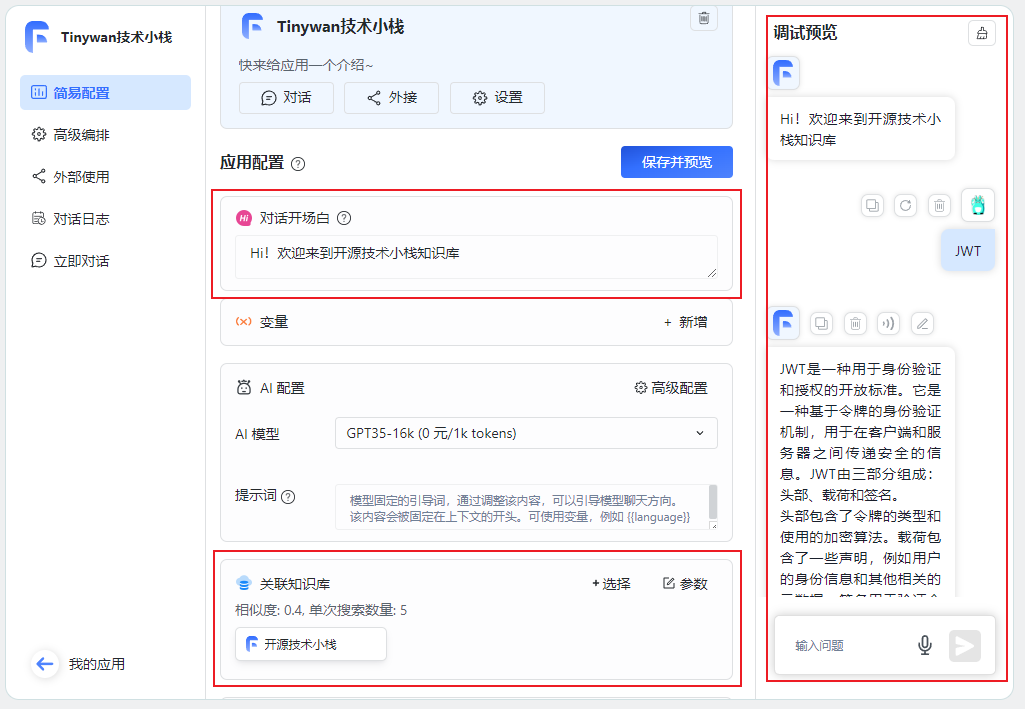 图片
图片
点击保存预留后,可以直接在右边调试预览框预览对话进行文档内容测试。
开始对话
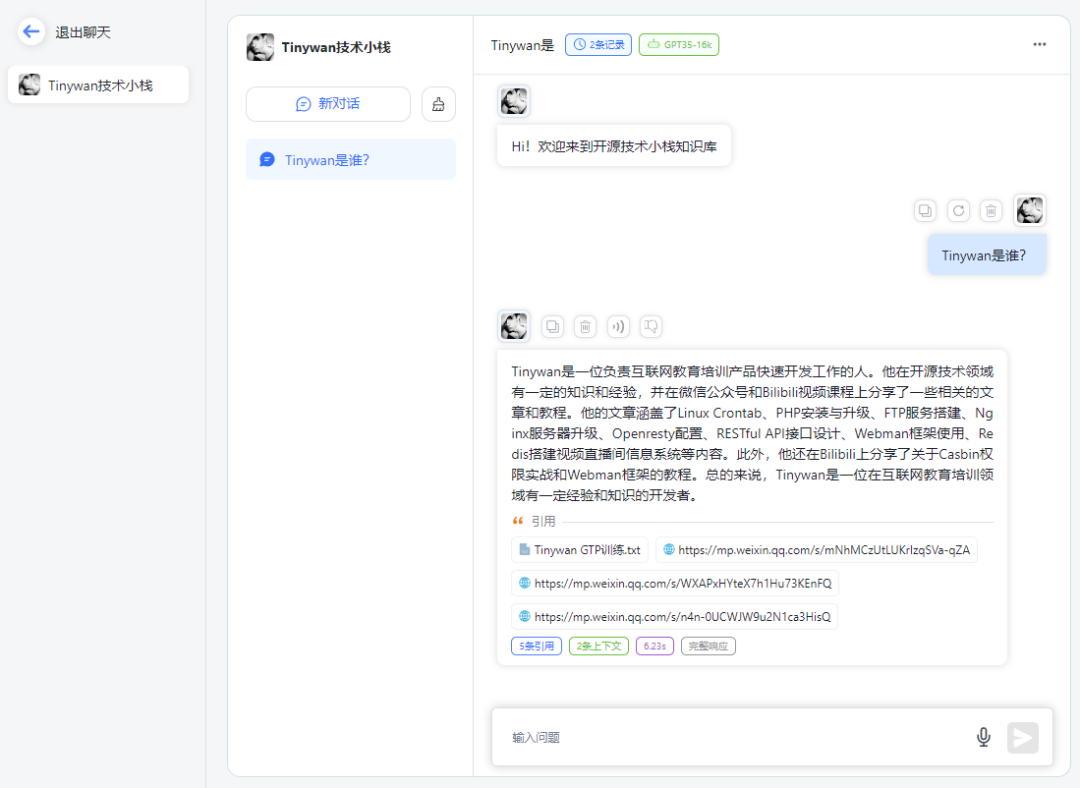 图片
图片
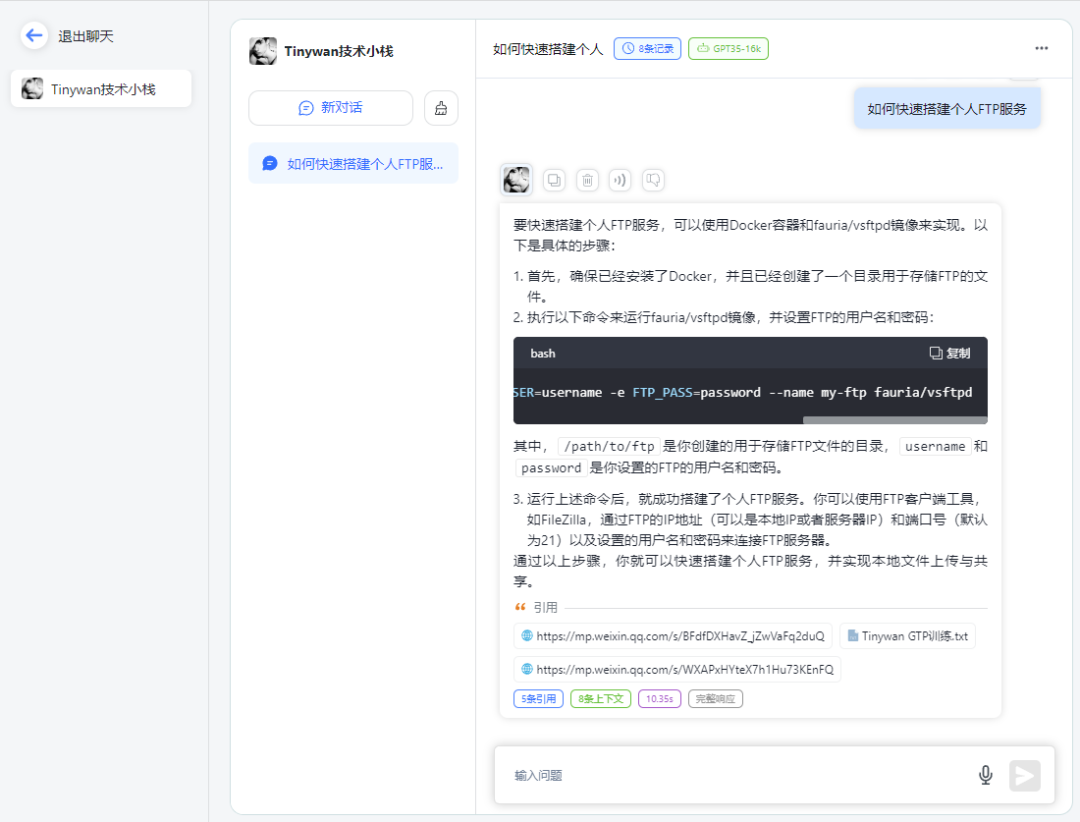 图片
图片
请点击链接查看知识库引用
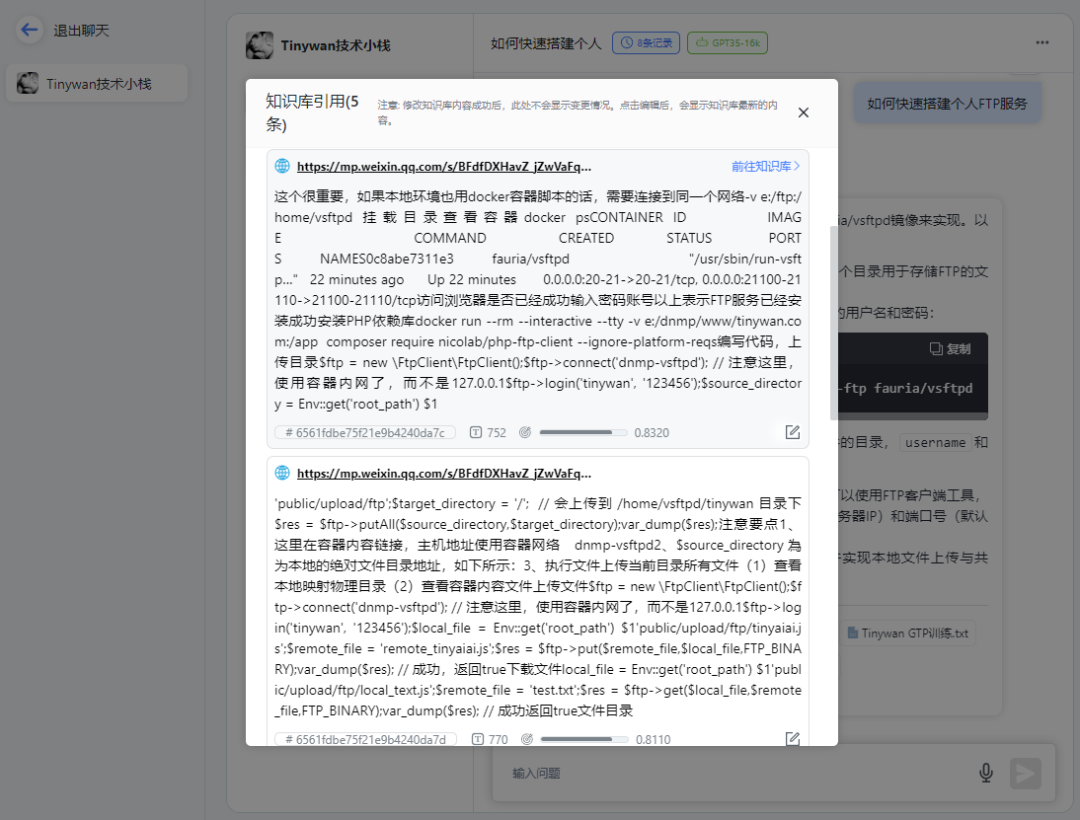 图片
图片
打开对应链接可以直接跳转到微信公众号文章地址
总结
构建私有数据训练服务,针对问题提供精准回答。可以通过AI服务训练自有数据,形成AI知识库,然后创建不同的机器人针对用户问题提供精准回答。并且可以通过API接口很方便整合到自己的产品服务中。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment vérifier la configuration de CentOS HDFS
Apr 14, 2025 pm 07:21 PM
Comment vérifier la configuration de CentOS HDFS
Apr 14, 2025 pm 07:21 PM
Guide complet pour vérifier la configuration HDFS dans les systèmes CentOS Cet article vous guidera comment vérifier efficacement la configuration et l'état de l'exécution des HDF sur les systèmes CentOS. Les étapes suivantes vous aideront à bien comprendre la configuration et le fonctionnement des HDF. Vérifiez la variable d'environnement Hadoop: Tout d'abord, assurez-vous que la variable d'environnement Hadoop est correctement définie. Dans le terminal, exécutez la commande suivante pour vérifier que Hadoop est installé et configuré correctement: HadoopVersion Check HDFS Fichier de configuration: Le fichier de configuration de base de HDFS est situé dans le répertoire / etc / hadoop / conf / le répertoire, où Core-site.xml et hdfs-site.xml sont cruciaux. utiliser
 Ligne de commande de l'arrêt CentOS
Apr 14, 2025 pm 09:12 PM
Ligne de commande de l'arrêt CentOS
Apr 14, 2025 pm 09:12 PM
La commande de fermeture CENTOS est arrêtée et la syntaxe est la fermeture de [options] le temps [informations]. Les options incluent: -H Arrêtez immédiatement le système; -P éteignez l'alimentation après l'arrêt; -r redémarrer; -t temps d'attente. Les temps peuvent être spécifiés comme immédiats (maintenant), minutes (minutes) ou une heure spécifique (HH: mm). Des informations supplémentaires peuvent être affichées dans les messages système.
 Quelles sont les méthodes de sauvegarde pour Gitlab sur Centos
Apr 14, 2025 pm 05:33 PM
Quelles sont les méthodes de sauvegarde pour Gitlab sur Centos
Apr 14, 2025 pm 05:33 PM
La politique de sauvegarde et de récupération de GitLab dans le système CentOS afin d'assurer la sécurité et la récupérabilité des données, Gitlab on CentOS fournit une variété de méthodes de sauvegarde. Cet article introduira plusieurs méthodes de sauvegarde courantes, paramètres de configuration et processus de récupération en détail pour vous aider à établir une stratégie complète de sauvegarde et de récupération de GitLab. 1. MANUEL BACKUP Utilisez le Gitlab-RakegitLab: Backup: Créer la commande pour exécuter la sauvegarde manuelle. Cette commande sauvegarde des informations clés telles que le référentiel Gitlab, la base de données, les utilisateurs, les groupes d'utilisateurs, les clés et les autorisations. Le fichier de sauvegarde par défaut est stocké dans le répertoire / var / opt / gitlab / backups. Vous pouvez modifier / etc / gitlab
 CentOS installe MySQL
Apr 14, 2025 pm 08:09 PM
CentOS installe MySQL
Apr 14, 2025 pm 08:09 PM
L'installation de MySQL sur CENTOS implique les étapes suivantes: Ajout de la source MySQL YUM appropriée. Exécutez la commande YUM Install MySQL-Server pour installer le serveur MySQL. Utilisez la commande mysql_secure_installation pour créer des paramètres de sécurité, tels que la définition du mot de passe de l'utilisateur racine. Personnalisez le fichier de configuration MySQL selon les besoins. Écoutez les paramètres MySQL et optimisez les bases de données pour les performances.
 Comment afficher les journaux Gitlab sous Centos
Apr 14, 2025 pm 06:18 PM
Comment afficher les journaux Gitlab sous Centos
Apr 14, 2025 pm 06:18 PM
Un guide complet pour consulter les journaux GitLab sous Centos System Cet article vous guidera comment afficher divers journaux GitLab dans le système CentOS, y compris les journaux principaux, les journaux d'exception et d'autres journaux connexes. Veuillez noter que le chemin du fichier journal peut varier en fonction de la version Gitlab et de la méthode d'installation. Si le chemin suivant n'existe pas, veuillez vérifier le répertoire d'installation et les fichiers de configuration de GitLab. 1. Afficher le journal GitLab principal Utilisez la commande suivante pour afficher le fichier journal principal de l'application GitLabRails: Commande: sudocat / var / log / gitlab / gitlab-rails / production.log Cette commande affichera le produit
 Comment faire fonctionner la formation distribuée de Pytorch sur CentOS
Apr 14, 2025 pm 06:36 PM
Comment faire fonctionner la formation distribuée de Pytorch sur CentOS
Apr 14, 2025 pm 06:36 PM
La formation distribuée par Pytorch sur le système CentOS nécessite les étapes suivantes: Installation de Pytorch: La prémisse est que Python et PIP sont installés dans le système CentOS. Selon votre version CUDA, obtenez la commande d'installation appropriée sur le site officiel de Pytorch. Pour la formation du processeur uniquement, vous pouvez utiliser la commande suivante: pipinstalltorchtorchVisionTorChaudio Si vous avez besoin d'une prise en charge du GPU, assurez-vous que la version correspondante de CUDA et CUDNN est installée et utilise la version Pytorch correspondante pour l'installation. Configuration de l'environnement distribué: la formation distribuée nécessite généralement plusieurs machines ou des GPU multiples uniques. Lieu
 Comment est la prise en charge du GPU pour Pytorch sur Centos
Apr 14, 2025 pm 06:48 PM
Comment est la prise en charge du GPU pour Pytorch sur Centos
Apr 14, 2025 pm 06:48 PM
Activer l'accélération du GPU Pytorch sur le système CentOS nécessite l'installation de versions CUDA, CUDNN et GPU de Pytorch. Les étapes suivantes vous guideront tout au long du processus: CUDA et CUDNN Installation détermineront la compatibilité de la version CUDA: utilisez la commande NVIDIA-SMI pour afficher la version CUDA prise en charge par votre carte graphique NVIDIA. Par exemple, votre carte graphique MX450 peut prendre en charge CUDA11.1 ou plus. Téléchargez et installez Cudatoolkit: visitez le site officiel de Nvidiacudatoolkit et téléchargez et installez la version correspondante selon la version CUDA la plus élevée prise en charge par votre carte graphique. Installez la bibliothèque CUDNN:
 Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Docker utilise les fonctionnalités du noyau Linux pour fournir un environnement de fonctionnement d'application efficace et isolé. Son principe de travail est le suivant: 1. Le miroir est utilisé comme modèle en lecture seule, qui contient tout ce dont vous avez besoin pour exécuter l'application; 2. Le Système de fichiers Union (UnionFS) empile plusieurs systèmes de fichiers, ne stockant que les différences, l'économie d'espace et l'accélération; 3. Le démon gère les miroirs et les conteneurs, et le client les utilise pour l'interaction; 4. Les espaces de noms et les CGROUP implémentent l'isolement des conteneurs et les limitations de ressources; 5. Modes de réseau multiples prennent en charge l'interconnexion du conteneur. Ce n'est qu'en comprenant ces concepts principaux que vous pouvez mieux utiliser Docker.
