
 Périphériques technologiques
IA
Pour les questions pour lesquelles les humains peuvent obtenir 92 points, GPT-4 ne peut obtenir que 15 points. Une fois le test mis à niveau, tous les grands modèles apparaissent dans leur forme originale.
Périphériques technologiques
IA
Pour les questions pour lesquelles les humains peuvent obtenir 92 points, GPT-4 ne peut obtenir que 15 points. Une fois le test mis à niveau, tous les grands modèles apparaissent dans leur forme originale.
Pour les questions pour lesquelles les humains peuvent obtenir 92 points, GPT-4 ne peut obtenir que 15 points. Une fois le test mis à niveau, tous les grands modèles apparaissent dans leur forme originale.

GPT-4 est un « meilleur étudiant » depuis sa naissance, obtenant des scores élevés à divers examens (benchmarks). Mais maintenant, il n’a obtenu que 15 points dans un nouveau test, contre 92 pour les humains.
Cet ensemble de questions de test appelé "GAIA" a été produit par des équipes de Meta-FAIR, Meta-GenAI, HuggingFace et AutoGPT. Il pose des problèmes qui nécessitent une série de capacités de base pour être résolus, tels que le raisonnement, le multi-. modalité Capacités de traitement, de navigation Web et d'utilisation générale des outils. Ces problèmes sont très simples pour les humains mais extrêmement difficiles pour les IA les plus avancées. Si tous les problèmes qu’il contient peuvent être résolus, le modèle achevé deviendra une étape importante dans la recherche sur l’IA.

Le concept de conception de GAIA est différent de nombreux benchmarks actuels en matière d'IA, ces derniers ayant tendance à concevoir des tâches de plus en plus difficiles pour les humains. Cela reflète en fait les différences de compréhension de la communauté actuelle en matière d'AGI. L'équipe derrière GAIA estime que l'émergence de l'AGI dépend de la capacité du système à faire preuve d'une robustesse similaire à celle des gens ordinaires face aux problèmes « simples » mentionnés ci-dessus.

Le contenu réécrit est le suivant : Image 1 : Exemple de question GAIA. La réalisation de ces tâches nécessite de grands modèles dotés de certaines capacités de base telles que le raisonnement, la multimodalité ou l'utilisation d'outils. La réponse est sans ambiguïté et, de par sa conception, ne peut pas être trouvée dans le texte brut des données d'entraînement. Certains problèmes sont accompagnés de preuves supplémentaires, telles que des images, qui reflètent des cas d'utilisation réels et permettent un meilleur contrôle du problème.
Bien que les LLM puissent accomplir avec succès des tâches difficiles pour les humains, les performances des LLM les plus compétents sur GAIA Insatisfaisante . Même équipé des outils, GPT4 avait un taux de réussite ne dépassant pas 30 % sur les tâches les plus faciles et 0 % sur les tâches les plus difficiles. Pendant ce temps, le taux de réussite moyen des personnes interrogées était de 92 %.
Donc, si un système peut résoudre le problème dans GAIA, nous pouvons l'évaluer dans le système t-AGI. t-AGI est un système d'évaluation AGI détaillé construit par l'ingénieur OpenAI Richard Ngo, qui comprend 1 seconde AGI, 1 minute AGI, 1 heure AGI, etc. Il est utilisé pour examiner si un système d'IA peut fonctionner dans un temps limité. . Accomplissez des tâches que les humains peuvent généralement accomplir dans le même laps de temps. Les auteurs affirment que lors du test GAIA, les humains prennent généralement environ 6 minutes pour répondre aux questions les plus simples et environ 17 minutes pour répondre aux questions les plus complexes.
L'auteur a utilisé la méthode GAIA pour concevoir 466 questions et leurs réponses. Ils ont publié un ensemble de développeurs comprenant 166 questions et réponses, ainsi que 300 questions supplémentaires sans réponse. Ce benchmark est publié sous la forme d'un classement
- Adresse du classement : https://huggingface.co/spaces/gaia-benchmark/leaderboard
- Adresse papier : https:// arxiv... ? GAIA est une référence pour tester les systèmes d'intelligence artificielle sur le problème des assistants généraux, ont indiqué les chercheurs. GAIA tente de contourner les lacunes d'un grand nombre d'évaluations LLM précédentes. Ce benchmark est composé de 466 questions conçues et annotées par des humains. Les questions sont basées sur du texte et certaines sont accompagnées de fichiers (tels que des images ou des feuilles de calcul). Elles couvrent une variété de tâches de nature auxiliaire, notamment les tâches personnelles quotidiennes, les sciences et les connaissances générales, etc.
- Ces questions ont une réponse correcte courte, unique et facilement vérifiablePour utiliser GAIA, il suffit de demander au intelligence artificielle L'assistant pose des questions sur zéro échantillon et joint les preuves pertinentes (le cas échéant). Atteindre un score parfait au GAIA nécessite une gamme de capacités de base différentes. Les créateurs de ce projet ont fourni diverses questions et métadonnées dans leurs documents supplémentaires
GAIA est née à la fois de la nécessité d'améliorer les références en matière d'intelligence artificielle et des lacunes actuellement largement observées dans l'évaluation LLM.
Le premier principe de la conception de GAIA est de cibler des problèmes conceptuellement simples. Bien que ces problèmes puissent paraître fastidieux pour les humains, ils sont en constante évolution dans le monde réel et constituent un défi pour les systèmes d’intelligence artificielle actuels. Cela nous permet de nous concentrer sur des capacités fondamentales telles que l'adaptation rapide par le raisonnement, la compréhension multimodale et l'utilisation potentiellement diversifiée d'outils, plutôt que sur des compétences spécialisées.
Ces problèmes impliquent souvent de trouver et de transformer des données provenant de différentes sources telles que des documents ou un Web en constante évolution) pour produire des réponses précises. Pour répondre à l'exemple de question de la figure 1, un LLM doit généralement parcourir le Web pour rechercher des études, puis rechercher le lieu d'inscription correct. Ceci est contraire à la tendance des systèmes de référence précédents, qui étaient de plus en plus difficiles pour les humains et/ou fonctionnaient en texte brut ou dans des environnements artificiels.
Le deuxième principe de GAIA est l'interprétabilité. Nous avons soigneusement sélectionné un nombre limité de questions pour rendre le nouveau benchmark plus facile à utiliser qu'un nombre massif de questions. Le concept de cette tâche est simple (taux de réussite humaine de 92 %), permettant aux utilisateurs de comprendre facilement le processus d'inférence du modèle. Pour le problème de premier niveau de la figure 1, le processus de raisonnement consiste principalement à vérifier le bon site Web et à signaler le bon numéro. Ce processus est facile à vérifier
Le troisième principe de GAIA est la robustesse de la mémoire : l'objectif de GAIA est. avoir une probabilité de deviner plus faible que la plupart des références actuelles. Afin d’accomplir une tâche, le système doit planifier et réaliser avec succès un certain nombre d’étapes. Parce que, de par leur conception, les réponses obtenues ne sont pas générées sous forme de texte brut dans les données de pré-formation actuelles. Les améliorations de la précision reflètent les progrès réels du système. En raison de leur variété et de la taille de l’espace d’action, ces tâches ne peuvent pas être forcées sans tricher, par exemple en mémorisant des faits de base. Bien que la contamination des données puisse conduire à une précision supplémentaire, l'exactitude requise des réponses, l'absence de réponses dans les données de pré-formation et la possibilité d'examiner la trace d'inférence atténuent ce risque.
En revanche, les réponses à choix multiples rendent l'évaluation de la contamination difficile car des traces d'un raisonnement erroné peuvent encore conduire au bon choix. Si des problèmes de mémoire catastrophiques surviennent malgré ces mesures d’atténuation, il est facile de concevoir de nouveaux problèmes en utilisant les lignes directrices fournies par les auteurs dans l’article.
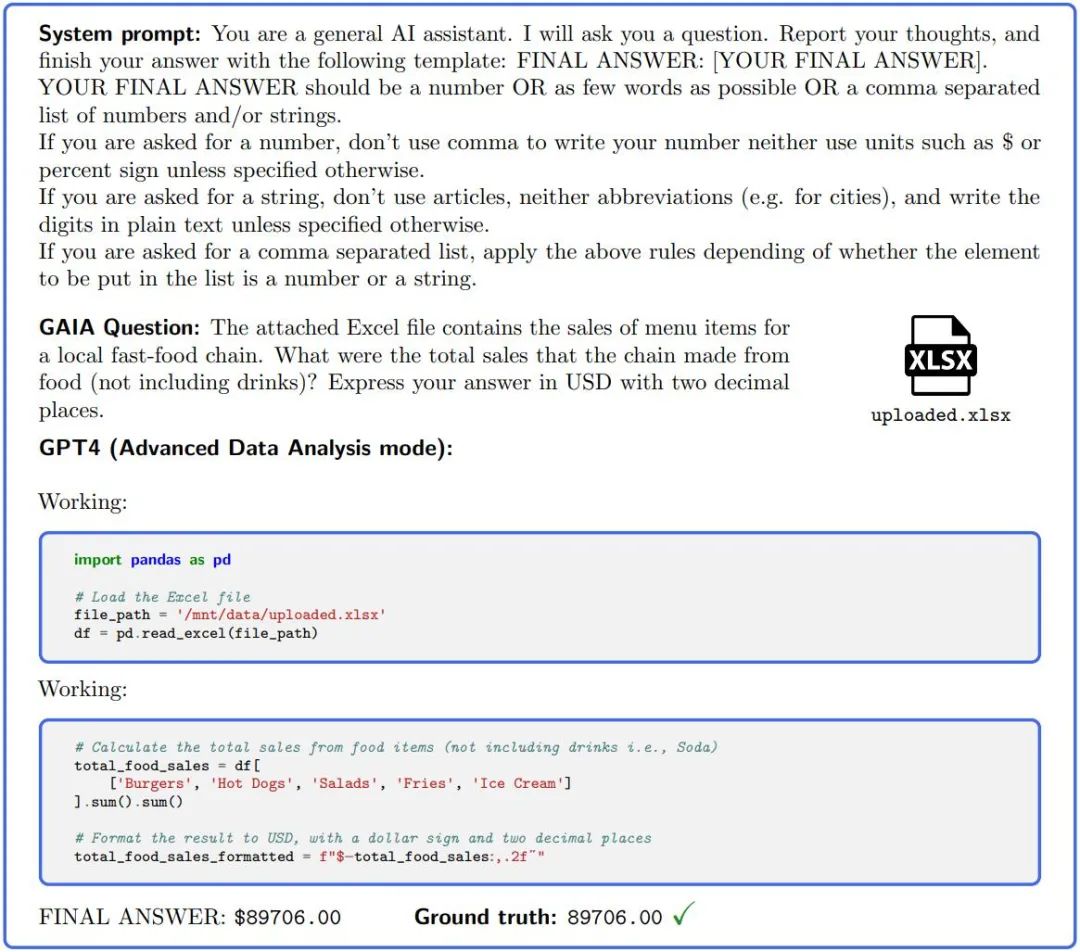
Figure 2. : Afin de répondre aux questions dans GAIA, un assistant IA tel que GPT4 (configuré avec un interpréteur de code) doit effectuer plusieurs étapes, qui peuvent nécessiter l'utilisation d'outils ou la lecture de fichiers.
Le dernier principe de GAIA est la facilité d'utilisation. Les tâches sont de simples invites et peuvent être accompagnées d'un fichier supplémentaire. Plus important encore, les réponses à vos questions sont factuelles, concises et claires. Ces propriétés permettent une évaluation simple, rapide et réaliste. Les questions sont conçues pour tester les capacités zéro-shot, limitant ainsi l'impact de la configuration d'évaluation. En revanche, de nombreux benchmarks LLM nécessitent des évaluations sensibles au contexte expérimental, comme le nombre et la nature des indices ou la mise en œuvre du benchmark.
Benchmarking des modèles existants
GAIA est conçu pour rendre l'évaluation du niveau d'intelligence des grands modèles automatisée, rapide et réaliste. En fait, sauf indication contraire, chaque question nécessite une réponse, qui peut être une chaîne (un ou plusieurs mots), un nombre ou une liste de chaînes ou de flottants séparés par des virgules, mais il n'y a qu'une seule bonne réponse. Par conséquent, l'évaluation se fait par une correspondance quasi-exacte entre la réponse du modèle et la vérité terrain (jusqu'à une certaine normalisation liée au « type » de la vérité terrain). Des indices système (ou préfixe) sont utilisés pour informer le modèle du format requis, voir Figure 2.
En effet, les modèles avec niveau GPT4 se conforment facilement au format GAIA. GAIA a fourni des fonctions de notation et de classement
Actuellement, il n'a testé que le "benchmark" dans le domaine des grands modèles, la série GPT d'OpenAI. On voit que les scores sont très faibles quelle que soit la version et le score. du niveau 3 est souvent nul.
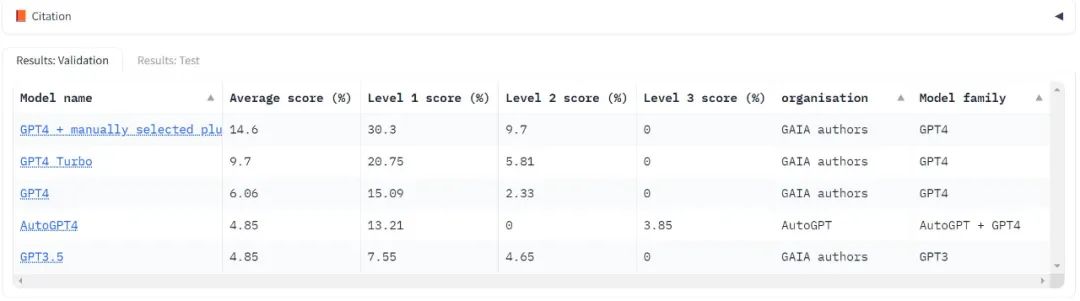
Pour utiliser GAIA pour évaluer LLM, il vous suffit de pouvoir inviter le modèle, c'est-à-dire d'avoir accès à l'API. Dans le test GPT4, les scores les plus élevés étaient le résultat d’une sélection manuelle humaine des plugins. Il convient de noter qu'AutoGPT est capable d'effectuer cette sélection automatiquement.
Tant que l'API est disponible, le modèle est exécuté trois fois pendant les tests et les résultats moyens sont rapportés
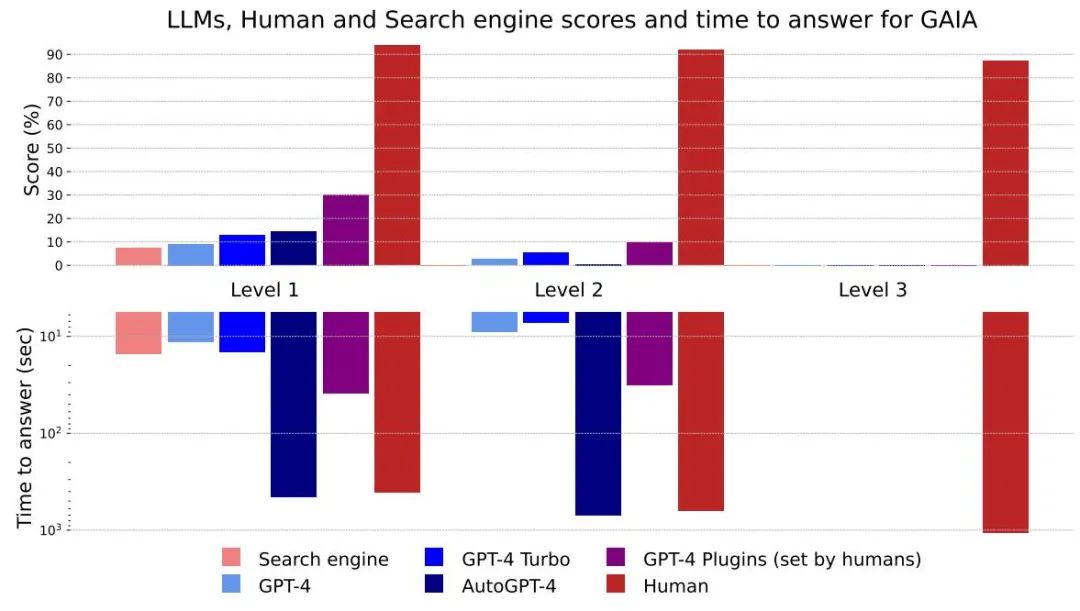
Figure 4 : scores et temps de réponse pour différentes méthodes et niveaux
Dans l'ensemble, les humains sont meilleurs aux questions-réponses et fonctionnent bien à tous les niveaux, mais le meilleur grand modèle actuel est clairement sous-performant. Les auteurs estiment que GAIA peut fournir un classement clair des assistants IA compétents tout en laissant une marge d’amélioration significative dans les mois, voire les années à venir.
À en juger par le temps qu'il faut pour répondre, les grands modèles comme GPT-4 ont le potentiel de remplacer les moteurs de recherche existants
La différence entre les résultats GPT4 sans plugins et les autres résultats montre que via l'outil API ou en accédant au Un réseau pour améliorer le LLM peut améliorer l'exactitude des réponses et débloquer de nombreux nouveaux cas d'utilisation, confirmant le grand potentiel de cette direction de recherche.
AutoGPT-4 permet à GPT-4 d'utiliser automatiquement des outils, mais les résultats au niveau 2 et même au niveau 1 sont décevants par rapport à GPT-4 sans plugins. Cette différence peut provenir de la façon dont AutoGPT-4 s'appuie sur l'API GPT-4 (indices et paramètres de construction) et nécessitera une nouvelle évaluation dans un avenir proche. AutoGPT-4 est également lent par rapport aux autres LLM. Globalement, la collaboration entre les humains et GPT-4 avec des plugins semble être la plus performante
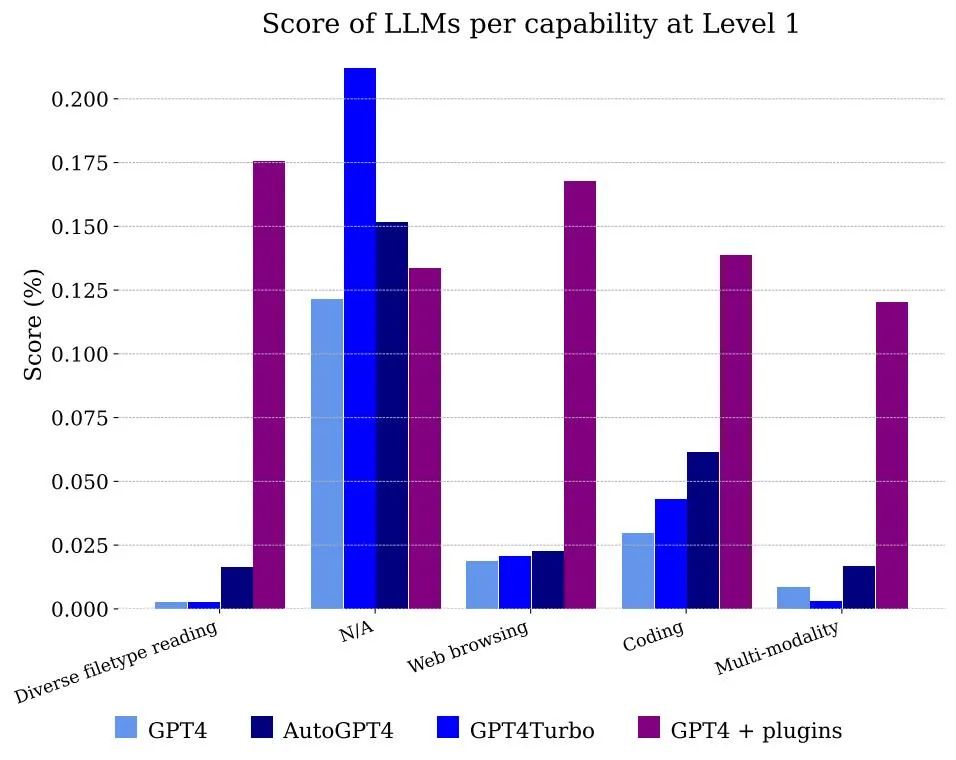
La figure 5 montre les scores obtenus par les modèles classés par fonctionnalité. Évidemment, l'utilisation de GPT-4 à elle seule ne peut pas gérer les fichiers et la multimodalité, mais elle est capable de résoudre le problème des annotateurs utilisant la navigation Web, principalement parce qu'elle peut mémoriser correctement les informations qui doivent être combinées pour obtenir la réponse
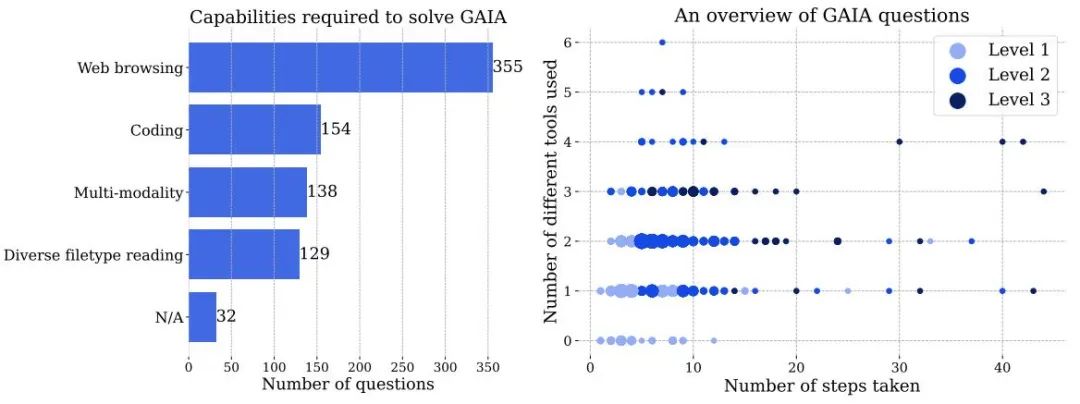
Figure 3 à gauche : Le nombre de capacités nécessaires pour résoudre des problèmes dans GAIA. À droite : Chaque point correspond à une question GAIA. La taille des points est proportionnelle au nombre de questions à un endroit donné, et seuls les niveaux comportant le plus grand nombre de questions sont affichés. Les deux chiffres sont basés sur les informations rapportées par des annotateurs humains lorsqu’ils répondent aux questions et peuvent être traités différemment par les systèmes d’IA.
Pour obtenir un score parfait sur GAIA, il faut une IA dotée d'un raisonnement avancé, d'une compréhension multimodale, de capacités de codage et d'une utilisation générale d'outils, tels que la navigation Web. L’IA implique également la nécessité de traiter diverses modalités de données, telles que des PDF, des feuilles de calcul, des images, des vidéos ou de l’audio.
Bien que la navigation sur le Web soit un élément clé de GAIA, nous n'avons pas besoin d'assistants IA pour effectuer des actions sur le site Web autres que des « clics », comme télécharger des fichiers, publier des commentaires ou réserver des réunions. Tester ces fonctionnalités dans un environnement réel tout en évitant de créer du spam nécessite de la prudence, et cette direction sera laissée pour des travaux futurs.
Questions de difficulté croissante : en fonction des étapes nécessaires pour résoudre le problème et du nombre d'outils différents requis pour répondre à la question, la question peut être divisée en trois niveaux de difficulté croissante. Il n'y a pas de définition unique de ces étapes ou outils, il peut y avoir plusieurs chemins pour répondre à une question donnée
- Les questions de niveau 1 ne nécessitent généralement aucun outil, ou au plus un outil mais pas plus de 5 étapes.
- Les questions de niveau 2 impliquent généralement plus d'étapes, entre 5 et 10, et nécessitent une combinaison de différents outils.
- Le niveau 3 est un problème pour un assistant universel presque parfait, nécessitant des séquences d'actions arbitrairement longues, utilisant un certain nombre d'outils et ayant accès au monde réel.
GAIA cible les problèmes de conception d'assistants IA du monde réel, y compris les tâches destinées aux personnes handicapées, telles que la recherche d'informations dans de petits fichiers audio. Enfin, le benchmark fait de son mieux pour couvrir une variété de domaines et de cultures, bien que la langue de l'ensemble de données soit limitée à l'anglais.
Veuillez vous référer au document original pour plus de détails
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Quelle méthode est utilisée pour convertir les chaînes en objets dans vue.js?
Apr 07, 2025 pm 09:39 PM
Quelle méthode est utilisée pour convertir les chaînes en objets dans vue.js?
Apr 07, 2025 pm 09:39 PM
Lors de la conversion des chaînes en objets dans vue.js, JSON.Parse () est préféré pour les chaînes JSON standard. Pour les chaînes JSON non standard, la chaîne peut être traitée en utilisant des expressions régulières et réduisez les méthodes en fonction du format ou du codé décodé par URL. Sélectionnez la méthode appropriée en fonction du format de chaîne et faites attention aux problèmes de sécurité et d'encodage pour éviter les bogues.
 Vue et Element-UI Cascade déroulante Boîte en V Mode en V
Apr 07, 2025 pm 08:06 PM
Vue et Element-UI Cascade déroulante Boîte en V Mode en V
Apr 07, 2025 pm 08:06 PM
Vue et Element-UI Boîtes déroulantes en cascade Points de fosse de liaison V-model: V-model lie un tableau représentant les valeurs sélectionnées à chaque niveau de la boîte de sélection en cascade, pas une chaîne; La valeur initiale de SelectOptions doit être un tableau vide, non nul ou non défini; Le chargement dynamique des données nécessite l'utilisation de compétences de programmation asynchrones pour gérer les mises à jour des données en asynchrone; Pour les énormes ensembles de données, les techniques d'optimisation des performances telles que le défilement virtuel et le chargement paresseux doivent être prises en compte.
 Vue.js Comment convertir un tableau de type de chaîne en un tableau d'objets?
Apr 07, 2025 pm 09:36 PM
Vue.js Comment convertir un tableau de type de chaîne en un tableau d'objets?
Apr 07, 2025 pm 09:36 PM
Résumé: Il existe les méthodes suivantes pour convertir les tableaux de chaîne Vue.js en tableaux d'objets: Méthode de base: utilisez la fonction de carte pour convenir à des données formatées régulières. Gameplay avancé: l'utilisation d'expressions régulières peut gérer des formats complexes, mais ils doivent être soigneusement écrits et considérés. Optimisation des performances: Considérant la grande quantité de données, des opérations asynchrones ou des bibliothèques efficaces de traitement des données peuvent être utilisées. MEILLEUR PRATIQUE: Effacer le style de code, utilisez des noms de variables significatifs et des commentaires pour garder le code concis.
 Comment définir le délai de Vue Axios
Apr 07, 2025 pm 10:03 PM
Comment définir le délai de Vue Axios
Apr 07, 2025 pm 10:03 PM
Afin de définir le délai d'expiration de Vue Axios, nous pouvons créer une instance AxiOS et spécifier l'option Timeout: dans les paramètres globaux: vue.prototype. $ Axios = axios.create ({timeout: 5000}); Dans une seule demande: ce. $ axios.get ('/ api / utilisateurs', {timeout: 10000}).
 Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Traiter efficacement 7 millions d'enregistrements et créer des cartes interactives avec la technologie géospatiale. Cet article explore comment traiter efficacement plus de 7 millions d'enregistrements en utilisant Laravel et MySQL et les convertir en visualisations de cartes interactives. Exigences initiales du projet de défi: extraire des informations précieuses en utilisant 7 millions d'enregistrements dans la base de données MySQL. Beaucoup de gens considèrent d'abord les langages de programmation, mais ignorent la base de données elle-même: peut-il répondre aux besoins? La migration des données ou l'ajustement structurel est-il requis? MySQL peut-il résister à une charge de données aussi importante? Analyse préliminaire: les filtres et les propriétés clés doivent être identifiés. Après analyse, il a été constaté que seuls quelques attributs étaient liés à la solution. Nous avons vérifié la faisabilité du filtre et établi certaines restrictions pour optimiser la recherche. Recherche de cartes basée sur la ville
 Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Ingénieur backend à distance Emploi Vacant Société: Emplacement du cercle: Bureau à distance Type d'emploi: Salaire à temps plein: 130 000 $ - 140 000 $ Description du poste Participez à la recherche et au développement des applications mobiles Circle et des fonctionnalités publiques liées à l'API couvrant l'intégralité du cycle de vie de développement logiciel. Les principales responsabilités complètent indépendamment les travaux de développement basés sur RubyOnRails et collaborent avec l'équipe frontale React / Redux / Relay. Créez les fonctionnalités de base et les améliorations des applications Web et travaillez en étroite collaboration avec les concepteurs et le leadership tout au long du processus de conception fonctionnelle. Promouvoir les processus de développement positifs et hiérarchiser la vitesse d'itération. Nécessite plus de 6 ans de backend d'applications Web complexe
 Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Il existe de nombreuses raisons pour lesquelles la startup MySQL échoue, et elle peut être diagnostiquée en vérifiant le journal des erreurs. Les causes courantes incluent les conflits de port (vérifier l'occupation du port et la configuration de modification), les problèmes d'autorisation (vérifier le service exécutant les autorisations des utilisateurs), les erreurs de fichier de configuration (vérifier les paramètres des paramètres), la corruption du répertoire de données (restaurer les données ou reconstruire l'espace de la table), les problèmes d'espace de la table InNODB (vérifier les fichiers IBDATA1), la défaillance du chargement du plug-in (vérification du journal des erreurs). Lors de la résolution de problèmes, vous devez les analyser en fonction du journal d'erreur, trouver la cause profonde du problème et développer l'habitude de sauvegarder régulièrement les données pour prévenir et résoudre des problèmes.
 Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
L'article présente le fonctionnement de la base de données MySQL. Tout d'abord, vous devez installer un client MySQL, tel que MySQLWorkBench ou le client de ligne de commande. 1. Utilisez la commande MySQL-UROot-P pour vous connecter au serveur et connecter avec le mot de passe du compte racine; 2. Utilisez Createdatabase pour créer une base de données et utilisez Sélectionner une base de données; 3. Utilisez CreateTable pour créer une table, définissez des champs et des types de données; 4. Utilisez InsertInto pour insérer des données, remettre en question les données, mettre à jour les données par mise à jour et supprimer les données par Supprimer. Ce n'est qu'en maîtrisant ces étapes, en apprenant à faire face à des problèmes courants et à l'optimisation des performances de la base de données que vous pouvez utiliser efficacement MySQL.
