

L'introduction du modèle de diffusion 2D a considérablement simplifié le processus de création de contenu d'image et apporté l'innovation à l'industrie de la conception 2D. Ces dernières années, ce modèle de diffusion s'est étendu à la création 3D, réduisant ainsi les coûts de main-d'œuvre dans des applications telles que la réalité virtuelle, la réalité augmentée, la robotique et les jeux. De nombreuses études ont commencé à explorer l'utilisation de modèles de diffusion 2D pré-entraînés, ainsi que des méthodes NeRF utilisant la perte d'échantillonnage par distillation notée (SDS). Cependant, les méthodes basées sur SDS nécessitent généralement des heures d'optimisation des ressources et provoquent souvent des problèmes géométriques dans les graphiques, tels que le problème Janus aux multiples facettes. D'un autre côté, les chercheurs peuvent y parvenir sans passer beaucoup de temps à optimiser chaque ressource. Diverses tentatives ont également été faites pour diversifier les modèles de diffusion 3D générés. Ces méthodes nécessitent généralement l'obtention de modèles 3D/nuages de points contenant des données réelles pour la formation. Cependant, pour des images réelles, de telles données d’entraînement sont difficiles à obtenir. Étant donné que les méthodes de diffusion 3D actuelles sont généralement basées sur un entraînement en deux étapes, cela se traduit par un espace latent flou et difficile à débruiter sur des ensembles de données 3D non classifiés et très divers, ce qui rend le rendu de haute qualité un défi urgent.
Afin de résoudre ce problème, certains chercheurs ont proposé des modèles à une seule étape, mais la plupart de ces modèles ne ciblent que des catégories simples spécifiques et ont une mauvaise généralisation. Par conséquent, l'objectif des chercheurs dans cet article est d'atteindre rapidement, Génération 3D réaliste et polyvalente. Pour cela, ils ont proposé DMV3D. DMV3D est un nouveau modèle de diffusion toutes catégories en une seule étape qui peut générer du NeRF 3D directement sur la base de la saisie du texte du modèle ou d'une seule image. En seulement 30 secondes sur un seul GPU A100, DMV3D peut générer une variété d'images 3D haute fidélité.
Plus précisément, DMV3D est un modèle de diffusion d'images multi-vues 2D qui intègre la reconstruction et le rendu du NeRF 3D dans son débruiteur et est entraîné de bout en bout sans effectuer directement de supervision 3D. Cela évite les problèmes qui peuvent survenir lors de la formation séparée des encodeurs NeRF 3D pour la diffusion spatiale latente (par exemple, des modèles à deux étages) et des méthodes fastidieuses d'optimisation pour chaque objet (par exemple, SDS)
 Essence de la méthode dans cet article Ce qui précède est une reconstruction 3D basée sur le cadre de la diffusion multi-vues 2D. Cette approche s'inspire de la méthode RenderDiffusion, une méthode de génération 3D via diffusion mono-vue. Cependant, la limitation de la méthode RenderDiffusion est que les données d'entraînement nécessitent une connaissance préalable d'une catégorie spécifique et que les objets contenus dans les données nécessitent des angles ou des poses spécifiques, sa généralisation est donc médiocre et elle ne peut générer de 3D pour aucun type d'objet
Essence de la méthode dans cet article Ce qui précède est une reconstruction 3D basée sur le cadre de la diffusion multi-vues 2D. Cette approche s'inspire de la méthode RenderDiffusion, une méthode de génération 3D via diffusion mono-vue. Cependant, la limitation de la méthode RenderDiffusion est que les données d'entraînement nécessitent une connaissance préalable d'une catégorie spécifique et que les objets contenus dans les données nécessitent des angles ou des poses spécifiques, sa généralisation est donc médiocre et elle ne peut générer de 3D pour aucun type d'objet
Selon les chercheurs, en comparaison, seul un ensemble de quatre projections clairsemées multi-vues contenant un objet est nécessaire pour décrire un objet 3D non masqué. Ces données d'entraînement proviennent de l'imagination spatiale humaine, qui permet aux utilisateurs de construire un objet 3D complet à partir de vues planaires autour de plusieurs objets. Cette imagination est généralement très précise et spécifique. Cependant, lors de l'application de cette entrée, la tâche de reconstruction 3D sous des vues clairsemées doit encore être résolue. Il s'agit d'un problème de longue date qui est très difficile même lorsque l'entrée est bruyante
Notre méthode est capable de réaliser une génération 3D basée sur une seule image/texte. Pour l'entrée d'image, ils corrigent une vue clairsemée comme entrée sans bruit et effectuent un débruitage sur d'autres vues similaire à l'inpainting d'image 2D. Pour réaliser une génération 3D basée sur du texte, les chercheurs ont utilisé des conditions de texte basées sur l'attention et des classificateurs indépendants du type couramment utilisés dans les modèles de diffusion 2D.
Ils n'ont utilisé la supervision de l'espace image que pendant la formation et ont utilisé un vaste ensemble de données composé d'images synthétisées Objaverse et d'images réelles capturées par MVImgNet. Selon les résultats, DMV3D a atteint le niveau SOTA en matière de reconstruction 3D à image unique, surpassant les méthodes précédentes basées sur SDS et les modèles de diffusion 3D. De plus, la méthode de génération de modèle 3D basée sur du texte est également meilleure que la méthode précédente
Adresse papier : https://arxiv.org/pdf/2311.09217.pdf
Site officiel adresse : https ://justimyhxu.github.io/projects/dmv3d/



Comment entraîner et déduire un modèle de diffusion 3D en une seule étape ?
Les chercheurs ont d'abord introduit un nouveau cadre de diffusion qui utilise un débruiteur basé sur la reconstruction pour débruiter les images multi-vues bruitées pour la génération 3D. Deuxièmement, ils ont proposé un nouveau débruiteur multi-vues basé sur LRM qui est conditionnel à la diffusion ; pas de temps, débruitant ainsi progressivement les images multi-vues grâce à la reconstruction et au rendu 3D NeRF. Enfin, le modèle est davantage diffusé pour prendre en charge l'ajustement du texte et de l'image, permettant ainsi une génération contrôlable ;
Le contenu à réécrire est : la diffusion multi-vues et le débruitage. Contenu réécrit : Diffusion de vues multi-angles et réduction du bruit
Diffusion multi-vues. La distribution x_0 originale traitée dans le modèle de diffusion 2D est une distribution d'image unique dans l'ensemble de données. Au lieu de cela, nous considérons une distribution conjointe d'images multi-vues 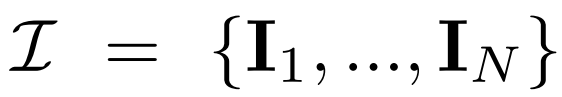 , où chaque groupe
, où chaque groupe 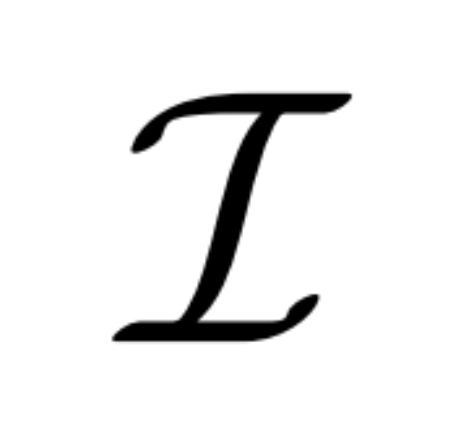 est une observation d'image de la même scène 3D (actif) depuis le point de vue C = {c_1, .. ., c_N}. Le processus de diffusion équivaut à effectuer une opération de diffusion sur chaque image indépendamment en utilisant le même programme de bruit, comme le montre l'équation (1) ci-dessous.
est une observation d'image de la même scène 3D (actif) depuis le point de vue C = {c_1, .. ., c_N}. Le processus de diffusion équivaut à effectuer une opération de diffusion sur chaque image indépendamment en utilisant le même programme de bruit, comme le montre l'équation (1) ci-dessous.
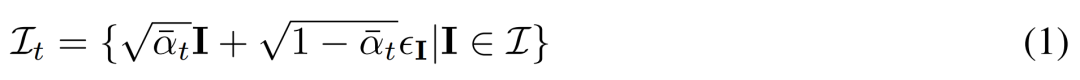
Débruitage basé sur la reconstruction. L’inverse du processus de diffusion 2D est essentiellement le débruitage. Dans cet article, les chercheurs proposent d'utiliser la reconstruction et le rendu 3D pour obtenir un débruitage d'images multi-vues 2D tout en produisant des modèles 3D propres pour la génération 3D. Plus précisément, ils utilisent le module de reconstruction 3D E (・) pour reconstruire la représentation 3D S à partir de l'image multi-vue bruitée 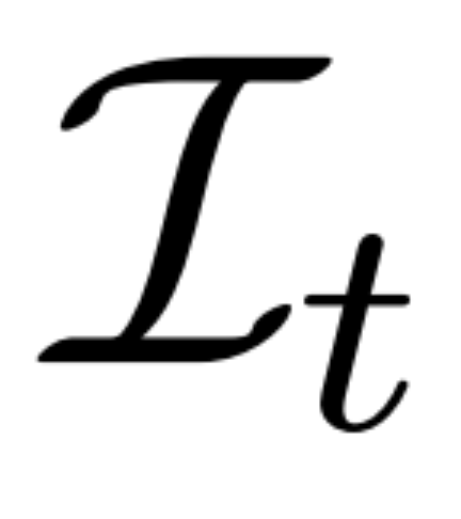 , et utilisent le module de rendu différentiable R (・) pour restituer l'image débruitée, comme indiqué ci-dessous. formule (2) comme indiqué.
, et utilisent le module de rendu différentiable R (・) pour restituer l'image débruitée, comme indiqué ci-dessous. formule (2) comme indiqué.
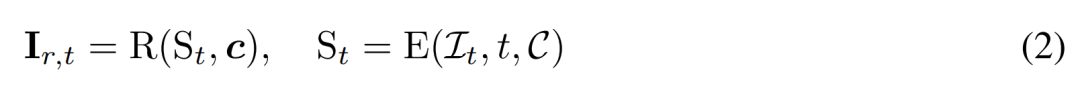
Débruiteur multi-vues basé sur la reconstruction
Les chercheurs ont construit un débruiteur multi-vues basé sur LRM et ont utilisé un grand modèle de transformateur pour reconstruire à partir d'images de pose à vue clairsemée et bruyantes Un trois propre Le NeRF à trois plans est généré, puis le rendu du NeRF à trois plans reconstruit est utilisé comme sortie débruitée.
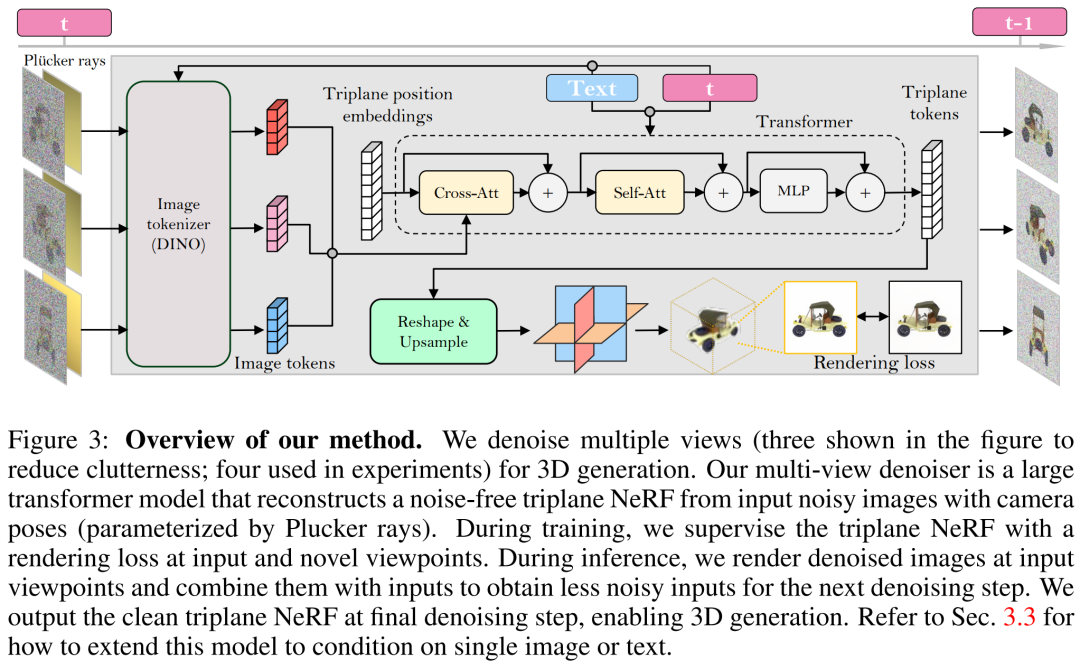
Reconstruction et rendu. Comme le montre la figure 3 ci-dessous, le chercheur utilise un transformateur de vision (DINO) pour convertir l'image d'entrée  en un jeton 2D, puis utilise le transformateur pour mapper la position apprise à trois plans intégrée au trois plans final pour représentent la représentation 3D de l’actif. Les trois plans prédits sont ensuite utilisés pour décoder la densité volumique et la couleur via un MLP pour un rendu volumique différentiable.
en un jeton 2D, puis utilise le transformateur pour mapper la position apprise à trois plans intégrée au trois plans final pour représentent la représentation 3D de l’actif. Les trois plans prédits sont ensuite utilisés pour décoder la densité volumique et la couleur via un MLP pour un rendu volumique différentiable.
Réglage de l'heure. Comparé au DDPM (Denoising Diffusion Probabilistic Model) basé sur CNN, notre modèle basé sur un transformateur nécessite une conception d'ajustement temporel différente.
Lors de la formation du modèle dans cet article, le chercheur a souligné que sur des ensembles de données de paramètres intrinsèques et extrinsèques très divers de la caméra (tels que MVImgNet), les ajustements de la caméra d'entrée doivent être conçus efficacement pour aider le modèle à comprendre la caméra et à effectuer Raisonnement 3D
Lors de la réécriture du contenu, vous devez convertir la langue du texte original en chinois, mais le sens du texte original ne change pas
La méthode ci-dessus permet au modèle proposé par le chercheur de servir de modèle génératif inconditionnel. Ils décrivent comment exploiter les débruiteurs conditionnels 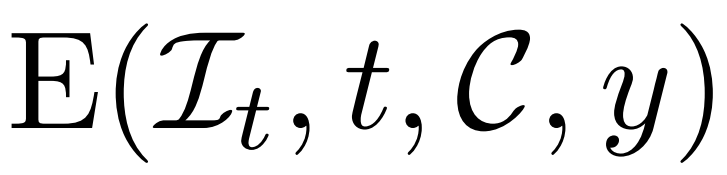 pour modéliser des distributions de probabilité conditionnelles, où y représente du texte ou des images, afin d'obtenir une génération 3D contrôlable.
pour modéliser des distributions de probabilité conditionnelles, où y représente du texte ou des images, afin d'obtenir une génération 3D contrôlable.
En termes de conditionnement d'images, les chercheurs ont proposé une stratégie simple et efficace qui ne nécessite pas de modifications de l'architecture du modèle
Conditionnement de texte. Pour ajouter le conditionnement de texte à leur modèle, les chercheurs ont adopté une stratégie similaire à la diffusion stable. Ils utilisent un encodeur de texte CLIP pour générer des intégrations de texte et les injecter dans un débruiteur en utilisant une attention croisée.
Le contenu qui doit être réécrit est : la formation et l'inférence
la formation. Pendant la phase d'entraînement, nous échantillonnons les pas de temps t uniformément dans la plage [1, T] et ajoutons du bruit selon la planification du cosinus. Ils échantillonnent l'image d'entrée en utilisant des poses de caméra aléatoires et échantillonnent également de manière aléatoire de nouveaux points de vue supplémentaires pour superviser le rendu et obtenir une meilleure qualité.
Le chercheur utilise le signal conditionnel y pour minimiser l'objectif de formation
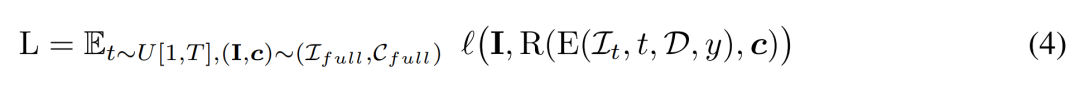
inférence. Au cours de la phase d'inférence, nous avons sélectionné des points de vue qui entouraient uniformément l'objet dans un cercle pour garantir une bonne couverture des ressources 3D résultantes. Ils ont fixé l'angle du marché de la caméra à 50 degrés pour les quatre vues.
Dans l'expérience, les chercheurs ont utilisé l'optimiseur AdamW pour entraîner leur modèle avec un taux d'apprentissage initial de 4e^-4. Ils ont utilisé 3K étapes d'échauffement et de désintégration du cosinus pour ce taux d'apprentissage, utilisé 256 × 256 images d'entrée pour entraîner le modèle de débruitage et utilisé 128 × 128 images recadrées pour le rendu supervisé
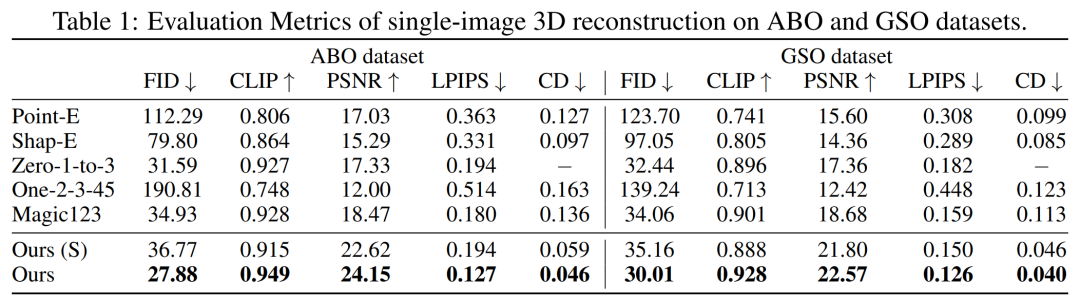
À propos de l'ensemble de données nécessaire Réécrit comme : Le le modèle du chercheur doit uniquement être formé à l'aide d'images de pose multi-vues. Par conséquent, ils ont utilisé des images multi-vues rendues d’environ 730 000 objets de l’ensemble de données Objaverse. Pour chaque objet, ils ont effectué 32 rendus d’images à des points de vue aléatoires avec un champ de vision fixe de 50 degrés et un éclairage uniforme selon les paramètres LRM. Premièrement, une reconstruction d’image unique. Les chercheurs ont comparé leur modèle de conditionnement d’images avec des méthodes précédentes telles que Point-E, Shap-E, Zero-1-to-3 et Magic123 sur une seule tâche de reconstruction d’image. Ils ont utilisé des métriques telles que PSNR, LPIPS, CLIP similarity score et FID pour évaluer la nouvelle qualité de rendu de vue de toutes les méthodes.
Les résultats quantitatifs sur les ensembles de tests GSO et ABO sont présentés dans le tableau 1 ci-dessous. Notre modèle surpasse toutes les méthodes de base et atteint un nouveau SOTA pour toutes les métriques sur les deux ensembles de données
 Les résultats générés par notre modèle ont de meilleurs détails géométriques et d'apparence que les lignes de base. Haute qualité, ce résultat peut être démontré qualitativement grâce Figure 4
Les résultats générés par notre modèle ont de meilleurs détails géométriques et d'apparence que les lignes de base. Haute qualité, ce résultat peut être démontré qualitativement grâce Figure 4
DMV3D est un modèle en une seule étape avec des images 2D comme cible de formation. En revanche, il ne nécessite pas d'optimisation individuelle de chaque actif et peut éliminer plusieurs vues diffuses et générer directement des modèles NeRF 3D. Dans l'ensemble, DMV3D est capable de générer rapidement des images 3D et d'obtenir les meilleurs résultats de reconstruction 3D sur une seule image
 Réécrit comme suit : Les chercheurs ont également évalué DMV3D sur les résultats de la génération 3D basée sur du texte. Les chercheurs ont comparé DMV3D avec Shap-E et Point-E, qui prennent également en charge un raisonnement rapide dans toutes les catégories. Les chercheurs ont laissé ces trois modèles générer sur la base de 50 invites de texte de Shap-E et ont utilisé la précision CLIP et la précision moyenne de deux modèles ViT différents pour évaluer les résultats de la génération, comme le montre le tableau 2
Réécrit comme suit : Les chercheurs ont également évalué DMV3D sur les résultats de la génération 3D basée sur du texte. Les chercheurs ont comparé DMV3D avec Shap-E et Point-E, qui prennent également en charge un raisonnement rapide dans toutes les catégories. Les chercheurs ont laissé ces trois modèles générer sur la base de 50 invites de texte de Shap-E et ont utilisé la précision CLIP et la précision moyenne de deux modèles ViT différents pour évaluer les résultats de la génération, comme le montre le tableau 2
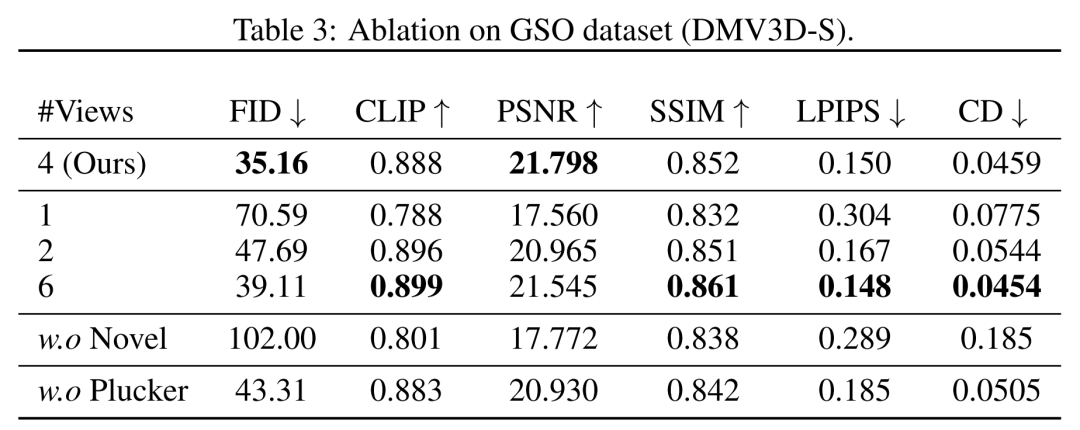
Selon les données du tableau, DMV3D affiche la meilleure précision. Comme le montrent les résultats qualitatifs de la figure 5, par rapport aux résultats générés par d'autres modèles, les graphiques générés par DMV3D contiennent évidemment des détails géométriques et d'apparence plus riches, et les résultats sont également plus réalistes Besoin à réécrire Oui : Autres résultats En termes de vues, les chercheurs montrent des comparaisons quantitatives et qualitatives de modèles formés avec différents nombres de vues d'entrée (1, 2, 4, 6) dans le tableau 3 et la figure 8. En termes de génération multi-instance, similaire à d'autres modèles de diffusion, le modèle proposé dans cet article peut générer une variété d'exemples basés sur une entrée aléatoire, comme le montre dans la figure 1, qui démontre la généralisabilité des résultats générés par le modèle. DMV3D possède une grande flexibilité et polyvalence dans les applications, et possède un fort potentiel de développement dans le domaine des applications de génération 3D. Comme le montrent les figures 1 et 2, la méthode de cet article peut promouvoir des objets arbitraires dans des photos 2D en dimensions 3D dans les applications d'édition d'images grâce à des méthodes telles que la segmentation (telle que SAM) Veuillez lire l'article original pour en savoir plus. De nombreux détails techniques et résultats expérimentaux



Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Que faire si la page Web n'est pas accessible
Que faire si la page Web n'est pas accessible
 Analyse comparative entre la version familiale Win10 et la version professionnelle
Analyse comparative entre la version familiale Win10 et la version professionnelle
 Quels sont les conseils d'utilisation de Dezender ?
Quels sont les conseils d'utilisation de Dezender ?
 Quels sont les serveurs web ?
Quels sont les serveurs web ?
 Que signifie la fréquence d'images ?
Que signifie la fréquence d'images ?
 Exigences de configuration de l'ordinateur de programmation Python
Exigences de configuration de l'ordinateur de programmation Python
 Comment ouvrir le fichier vcf sous Windows
Comment ouvrir le fichier vcf sous Windows
 La différence entre rom et bélier
La différence entre rom et bélier
 Comment modifier element.style
Comment modifier element.style








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



