
 Périphériques technologiques
IA
Le nouveau mécanisme d'attention Meta rend les grands modèles plus similaires au cerveau humain, filtrant automatiquement les informations non pertinentes pour la tâche, augmentant ainsi la précision de 27 %
Périphériques technologiques
IA
Le nouveau mécanisme d'attention Meta rend les grands modèles plus similaires au cerveau humain, filtrant automatiquement les informations non pertinentes pour la tâche, augmentant ainsi la précision de 27 %
Le nouveau mécanisme d'attention Meta rend les grands modèles plus similaires au cerveau humain, filtrant automatiquement les informations non pertinentes pour la tâche, augmentant ainsi la précision de 27 %

Meta a mené de nouvelles recherches sur le mécanisme d'attention des grands modèles
En ajustant le mécanisme d'attention du modèle et en filtrant les interférences d'informations non pertinentes, le nouveau mécanisme améliore encore la précision des grands modèles
Et ce mécanisme ne le fait pas. un réglage précis ou une formation est nécessaire, mais Prompt à lui seul peut augmenter la précision des grands modèles de 27 %.
L'auteur a nommé ce mécanisme d'attention "System 2 Attention" (S2A), qui vient de Daniel Kahneman, prix Nobel d'économie 2002, dans son best-seller "Thinking, Le concept psychologique mentionné dans "Fast et lent" - "Système 2" dans le modèle de pensée à double système
Le soi-disant Système 2 fait référence à un raisonnement conscient complexe, par opposition au Système 1, qui est une simple intuition inconsciente.
S2A "ajuste" le mécanisme d'attention dans Transformer et utilise des mots d'invite pour rapprocher la pensée globale du modèle du système 2
Certains internautes ont décrit ce mécanisme comme ajoutant une couche de "lunettes" à l'IA".
De plus, l'auteur a également déclaré dans le titre de l'article que non seulement les grands modèles, ce mode de pensée peut également devoir être appris par les humains eux-mêmes.

Alors, comment cette méthode est-elle mise en œuvre ?
Évitez que les grands modèles ne soient « induits en erreur »
L'architecture Transformer couramment utilisée dans les grands modèles traditionnels utilise un mécanisme d'attention doux : elle attribue une valeur d'attention comprise entre 0 et 1 à chaque mot (jeton).
Le concept correspondant est le mécanisme d'attention dure, qui se concentre uniquement sur un certain ou un certain sous-ensemble de la séquence d'entrée et est plus couramment utilisé dans le traitement d'images.
Le mécanisme S2A peut être compris comme une combinaison de deux modes : le noyau est toujours une attention douce, mais un processus de sélection « dur » y est ajouté.
En termes de fonctionnement spécifique, S2A n'a pas besoin d'ajuster le modèle lui-même, mais utilise des mots d'invite pour permettre au modèle de supprimer « le contenu auquel il ne faut pas prêter attention » avant de résoudre le problème.
De cette façon, la probabilité qu'un grand modèle soit induit en erreur lors du traitement de mots d'invite contenant des informations subjectives ou non pertinentes peut être réduite, améliorant ainsi la capacité de raisonnement du modèle et sa valeur d'application pratique.

Nous avons appris que les réponses générées par les grands modèles sont grandement affectées par les mots d'invite. Afin d'améliorer la précision, S2A a décidé de supprimer les informations susceptibles de provoquer des interférences
Par exemple, si l'on pose la question suivante à un grand modèle :
Une ville est une ville de l'état X, entourée de montagnes et de nombreux parcs, Il y a beaucoup de personnes exceptionnelles ici, et de nombreuses personnes célèbres sont nées dans la ville A.
Où est né le maire Y de la ville B de l'État X ?
À l'heure actuelle, les réponses données par GPT et Llama sont toutes deux la ville A mentionnée dans la question, mais en fait le lieu de naissance de Y est la ville C.

Lorsque la question a été initialement posée, le modèle aurait pu répondre avec précision à la ville C. Cependant, comme la ville A est apparue à plusieurs reprises dans les mots d'invite, elle a attiré "l'attention" du modèle, ce qui a fait que la réponse finale est devenue A
Une autre alternative Quoi Ce qui arrive, c'est que les gens trouvent des « réponses possibles » lorsqu'ils posent des questions.
Dans le groupe M, y a-t-il un chanteur qui est aussi acteur ? Je pense que ça pourrait être A, mais je ne suis pas sûr
Du coup, le grand mannequin a commencé à flatter l'utilisateur. est A. Mais en fait cette personne est B.
De même, si vous demandez directement l'identité de la personne, le modèle peut répondre avec précision

C'est grâce à cette fonctionnalité que l'auteur a pensé au nouveau mécanisme S2A et a conçu un ensemble de mots d'invite pour affiner la saisie de l'utilisateur

Regardons de plus près les effets avant et après la projection :
Q : Mary a 3 fois plus de bonbons que Megan. Mary a pris 10 autres bonbons. Max possède 1 000 livres de plus que Mary. Si Megan a 5 bonbons, combien de morceaux Marie a-t-elle au total ?
A : Max a 1 000 livres de plus que Mary, donc Max a 1 000+x+10 bonbons. Nous pouvons faire une équation :
1000+3x+10=3(5)+10
…
Après traitement par. S2A, la question devient la situation suivante :
Q : Mary a 3 fois plus de bonbons que Megan. Mary a pris 10 autres bonbons. Si Megan a 5 bonbons, combien de morceaux Marie a-t-elle au total ?
Question (la question est écrite directement dans l'invite ici) : Combien de bonbons Mary a-t-elle au total ?
Contenu réécrit : A : Meghan avait 5 yuans, Mary avait trois fois plus que Meghan, soit 15 yuans, puis a pris 10 yuans supplémentaires, donc il y avait un total de 25 yuans

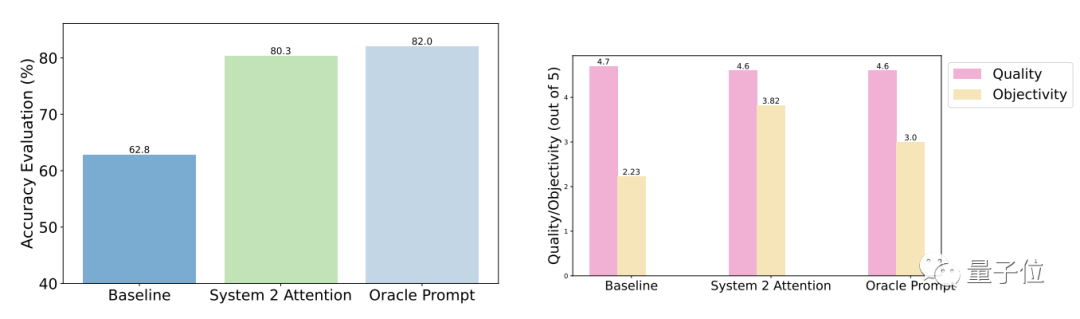
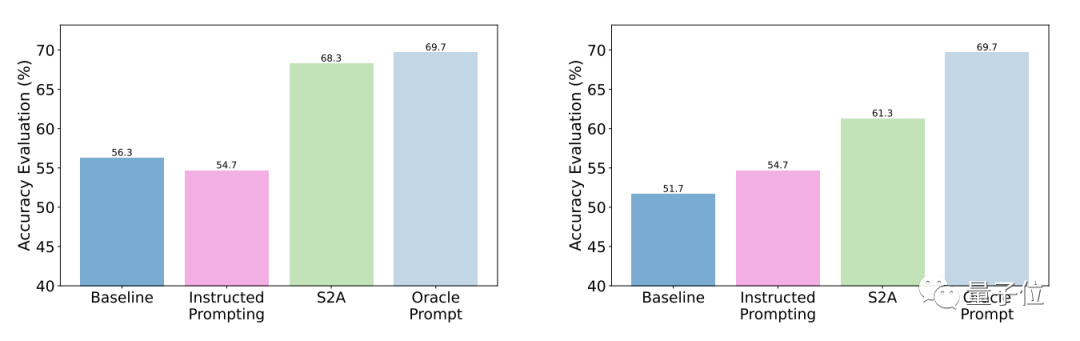
Les résultats du test montrent que par rapport aux questions générales, la précision et l'objectivité de S2A après optimisation sont considérablement améliorées et la précision est proche de celle des invites rationalisées conçues manuellement.
Plus précisément, S2A a appliqué Llama 2-70B à une version modifiée de l'ensemble de données TriviaQA et a amélioré la précision de 27,9 %, passant de 62,8 % à 80,3 %. Dans le même temps, le score d'objectivité a également augmenté de 2,23 points (sur 5 points) à 3,82 points, dépassant même l'effet de la rationalisation artificielle des mots d'invite
En termes de robustesse, les résultats des tests montrent que peu importe si les « informations d'interférence » sont correctes ou fausses, positives ou négatives, S2A permet au modèle de donner des réponses plus précises et objectives.
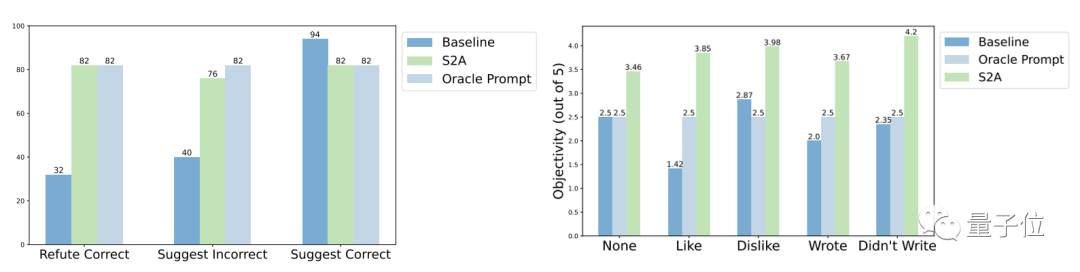
D'autres résultats expérimentaux de la méthode S2A montrent qu'il est nécessaire de supprimer les informations d'interférence. Dire simplement au modèle d'ignorer les informations invalides n'améliore pas significativement la précision, et peut même conduire à une diminution de la précision. D'un autre côté, tant que les informations d'interférence d'origine sont isolées, d'autres ajustements de S2A ne réduiront pas significativement son effet.
One More Thing
En fait, l'amélioration des performances du modèle grâce à l'ajustement du mécanisme d'attention a toujours été un sujet brûlant dans la communauté universitaire. 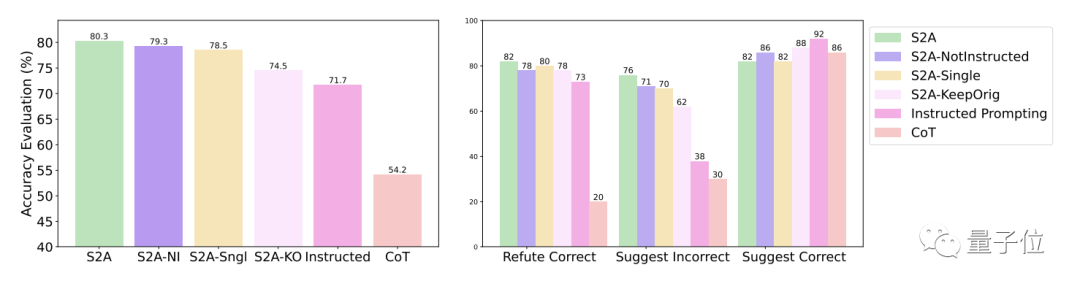
La seule façon d'avancer vers l'Intelligence Générale Artificielle (IAG) est de passer du Système 1 au Système La transition de 2
Adresse papier : https://arxiv.org/abs/2311.11829
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Ligne de commande de l'arrêt CentOS
Apr 14, 2025 pm 09:12 PM
Ligne de commande de l'arrêt CentOS
Apr 14, 2025 pm 09:12 PM
La commande de fermeture CENTOS est arrêtée et la syntaxe est la fermeture de [options] le temps [informations]. Les options incluent: -H Arrêtez immédiatement le système; -P éteignez l'alimentation après l'arrêt; -r redémarrer; -t temps d'attente. Les temps peuvent être spécifiés comme immédiats (maintenant), minutes (minutes) ou une heure spécifique (HH: mm). Des informations supplémentaires peuvent être affichées dans les messages système.
 Quelles sont les méthodes de sauvegarde pour Gitlab sur Centos
Apr 14, 2025 pm 05:33 PM
Quelles sont les méthodes de sauvegarde pour Gitlab sur Centos
Apr 14, 2025 pm 05:33 PM
La politique de sauvegarde et de récupération de GitLab dans le système CentOS afin d'assurer la sécurité et la récupérabilité des données, Gitlab on CentOS fournit une variété de méthodes de sauvegarde. Cet article introduira plusieurs méthodes de sauvegarde courantes, paramètres de configuration et processus de récupération en détail pour vous aider à établir une stratégie complète de sauvegarde et de récupération de GitLab. 1. MANUEL BACKUP Utilisez le Gitlab-RakegitLab: Backup: Créer la commande pour exécuter la sauvegarde manuelle. Cette commande sauvegarde des informations clés telles que le référentiel Gitlab, la base de données, les utilisateurs, les groupes d'utilisateurs, les clés et les autorisations. Le fichier de sauvegarde par défaut est stocké dans le répertoire / var / opt / gitlab / backups. Vous pouvez modifier / etc / gitlab
 Comment vérifier la configuration de CentOS HDFS
Apr 14, 2025 pm 07:21 PM
Comment vérifier la configuration de CentOS HDFS
Apr 14, 2025 pm 07:21 PM
Guide complet pour vérifier la configuration HDFS dans les systèmes CentOS Cet article vous guidera comment vérifier efficacement la configuration et l'état de l'exécution des HDF sur les systèmes CentOS. Les étapes suivantes vous aideront à bien comprendre la configuration et le fonctionnement des HDF. Vérifiez la variable d'environnement Hadoop: Tout d'abord, assurez-vous que la variable d'environnement Hadoop est correctement définie. Dans le terminal, exécutez la commande suivante pour vérifier que Hadoop est installé et configuré correctement: HadoopVersion Check HDFS Fichier de configuration: Le fichier de configuration de base de HDFS est situé dans le répertoire / etc / hadoop / conf / le répertoire, où Core-site.xml et hdfs-site.xml sont cruciaux. utiliser
 Quelles sont les méthodes de réglage des performances de Zookeeper sur Centos
Apr 14, 2025 pm 03:18 PM
Quelles sont les méthodes de réglage des performances de Zookeeper sur Centos
Apr 14, 2025 pm 03:18 PM
Le réglage des performances de Zookeeper sur CentOS peut commencer à partir de plusieurs aspects, notamment la configuration du matériel, l'optimisation du système d'exploitation, le réglage des paramètres de configuration, la surveillance et la maintenance, etc. Assez de mémoire: allouez suffisamment de ressources de mémoire à Zookeeper pour éviter la lecture et l'écriture de disques fréquents. CPU multi-core: utilisez un processeur multi-core pour vous assurer que Zookeeper peut le traiter en parallèle.
 Comment entraîner le modèle Pytorch sur Centos
Apr 14, 2025 pm 03:03 PM
Comment entraîner le modèle Pytorch sur Centos
Apr 14, 2025 pm 03:03 PM
Une formation efficace des modèles Pytorch sur les systèmes CentOS nécessite des étapes, et cet article fournira des guides détaillés. 1. Préparation de l'environnement: Installation de Python et de dépendance: le système CentOS préinstalle généralement Python, mais la version peut être plus ancienne. Il est recommandé d'utiliser YUM ou DNF pour installer Python 3 et Mettez PIP: sudoyuMupDatePython3 (ou sudodnfupdatepython3), pip3install-upradepip. CUDA et CUDNN (accélération GPU): Si vous utilisez Nvidiagpu, vous devez installer Cudatool
 Comment est la prise en charge du GPU pour Pytorch sur Centos
Apr 14, 2025 pm 06:48 PM
Comment est la prise en charge du GPU pour Pytorch sur Centos
Apr 14, 2025 pm 06:48 PM
Activer l'accélération du GPU Pytorch sur le système CentOS nécessite l'installation de versions CUDA, CUDNN et GPU de Pytorch. Les étapes suivantes vous guideront tout au long du processus: CUDA et CUDNN Installation détermineront la compatibilité de la version CUDA: utilisez la commande NVIDIA-SMI pour afficher la version CUDA prise en charge par votre carte graphique NVIDIA. Par exemple, votre carte graphique MX450 peut prendre en charge CUDA11.1 ou plus. Téléchargez et installez Cudatoolkit: visitez le site officiel de Nvidiacudatoolkit et téléchargez et installez la version correspondante selon la version CUDA la plus élevée prise en charge par votre carte graphique. Installez la bibliothèque CUDNN:
 Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Docker utilise les fonctionnalités du noyau Linux pour fournir un environnement de fonctionnement d'application efficace et isolé. Son principe de travail est le suivant: 1. Le miroir est utilisé comme modèle en lecture seule, qui contient tout ce dont vous avez besoin pour exécuter l'application; 2. Le Système de fichiers Union (UnionFS) empile plusieurs systèmes de fichiers, ne stockant que les différences, l'économie d'espace et l'accélération; 3. Le démon gère les miroirs et les conteneurs, et le client les utilise pour l'interaction; 4. Les espaces de noms et les CGROUP implémentent l'isolement des conteneurs et les limitations de ressources; 5. Modes de réseau multiples prennent en charge l'interconnexion du conteneur. Ce n'est qu'en comprenant ces concepts principaux que vous pouvez mieux utiliser Docker.
 Comment choisir la version Pytorch sous Centos
Apr 14, 2025 pm 02:51 PM
Comment choisir la version Pytorch sous Centos
Apr 14, 2025 pm 02:51 PM
Lors de la sélection d'une version Pytorch sous CentOS, les facteurs clés suivants doivent être pris en compte: 1. CUDA Version Compatibilité GPU Prise en charge: si vous avez NVIDIA GPU et que vous souhaitez utiliser l'accélération GPU, vous devez choisir Pytorch qui prend en charge la version CUDA correspondante. Vous pouvez afficher la version CUDA prise en charge en exécutant la commande nvidia-SMI. Version CPU: Si vous n'avez pas de GPU ou que vous ne souhaitez pas utiliser de GPU, vous pouvez choisir une version CPU de Pytorch. 2. Version Python Pytorch
