

L'introduction du modèle de diffusion a favorisé le développement de la technologie vidéo de génération de texte. Cependant, ces méthodes sont souvent coûteuses en termes de calcul et difficiles à réaliser des vidéos de mouvement d'objet fluide.
Afin de résoudre ces problèmes, des chercheurs de Shenzhen. L'Institut de technologie avancée, l'Académie chinoise des sciences, des chercheurs de l'Université de l'Académie chinoise des sciences et le laboratoire d'intelligence artificielle VIVO ont proposé conjointement un nouveau cadre appelé GPT4Motion qui peut générer des vidéos textuelles sans formation. GPT4Motion combine les capacités de planification de grands modèles de langage tels que GPT, les capacités de simulation physique fournies par le logiciel Blender et les capacités de génération de texte des modèles de diffusion, dans le but d'améliorer considérablement la qualité de la synthèse vidéo

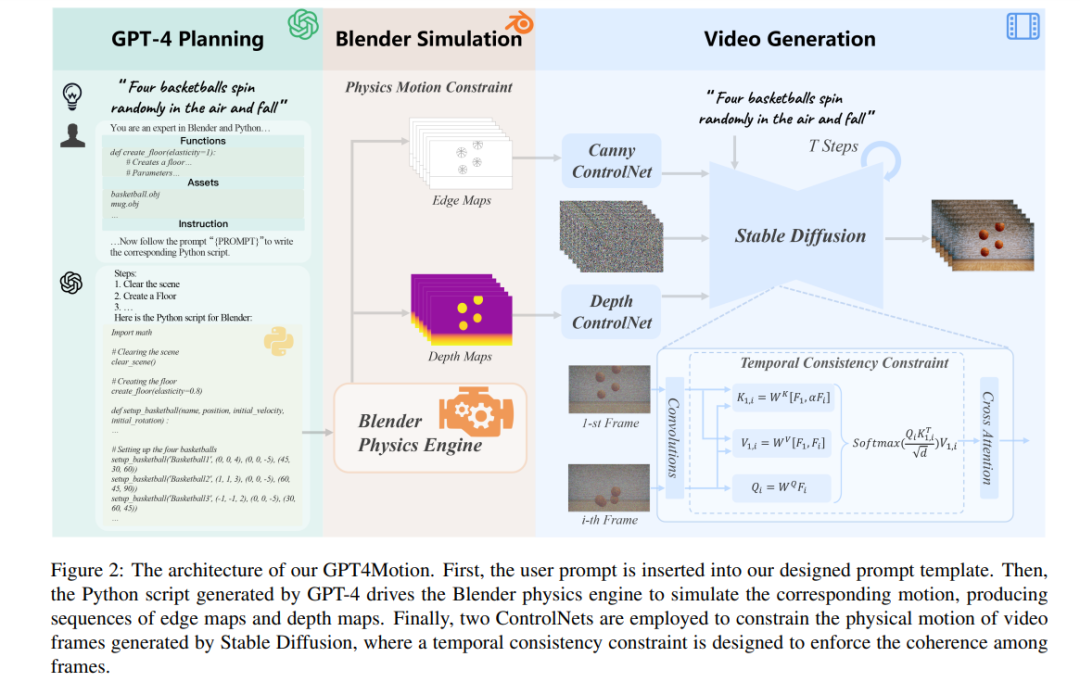
GPT4Motion utilise GPT-4 pour générer des scripts Blender basés sur les invites de texte saisies par l'utilisateur. Il exploite le moteur physique de Blender pour créer des composants de scène de base et les encapsule sous forme de mouvement continu entre images. Ces composants sont ensuite entrés dans un modèle de diffusion pour générer une vidéo qui correspond à l'invite de texte
Les résultats expérimentaux montrent que GPT4Motion peut générer efficacement des vidéos de haute qualité tout en maintenant la cohérence du mouvement et la cohérence des entités. A noter que GPT4Motion utilise un moteur physique pour rendre la vidéo générée plus réaliste. Cela offre une nouvelle perspective pour les vidéos de génération de texte
Jetons d'abord un coup d'œil à l'effet de génération de GPT4Motion, comme la saisie d'invites de texte : "Un T-shirt blanc flotte dans la brise", "Un T-shirt blanc" "Une chemise flotte dans le vent", "un T-shirt blanc flotte dans le vent fort". En raison des différentes forces du vent, l'amplitude du T-shirt blanc flottant dans la vidéo générée par GPT4Motion est également différente :

En termes de modèles d'écoulement de liquide, la vidéo générée par GPT4Motion peut également montrer bien :

Le basket-ball tourne et tombe des airs :
Le but de cette recherche est de générer une vidéo conforme aux caractéristiques physiques en fonction des invites de l'utilisateur pour certains scènes de mouvements physiques de base. Les propriétés physiques sont souvent liées au matériau de l'objet. Les chercheurs se concentrent sur la simulation de trois matériaux d'objets courants dans la vie quotidienne : 1) les objets rigides, qui peuvent conserver leur forme sans changer lorsqu'ils sont soumis à une force ; 2) le tissu, qui se caractérise par sa douceur et sa facilité de flottement ; 3) les liquides ; présenter un mouvement continu et déformable.
De plus, les chercheurs ont accordé une attention particulière à plusieurs modes de mouvement typiques de ces matériaux, notamment la collision (impact direct entre des objets), l'effet du vent (mouvement provoqué par le flux d'air) et l'écoulement (continu et se déplaçant dans une direction). La simulation de ces scénarios physiques nécessite souvent des connaissances en mécanique classique, en mécanique des fluides et en autre physique. Le modèle de diffusion actuel qui se concentre sur les vidéos générées par texte est difficile à acquérir ces connaissances physiques complexes par la formation, et ne peut donc pas produire des vidéos conformes aux propriétés physiques. L'avantage de GPT4Motion est de garantir que la vidéo générée n'est pas seulement cohérente avec les propriétés physiques. invite l'utilisateur à saisir, et c'est également physiquement correct. Les capacités de compréhension sémantique et de génération de code de GPT-4 peuvent convertir les invites utilisateur en scripts Python de Blender, qui peuvent piloter le moteur physique intégré de Blender pour simuler les scènes physiques correspondantes. De plus, l'étude a également utilisé ControlNet, prenant les résultats dynamiques de la simulation de Blender comme entrée pour guider le modèle de diffusion afin de générer une vidéo image par image
 Utiliser GPT-4 pour activer Blender pour les opérations de simulation
Utiliser GPT-4 pour activer Blender pour les opérations de simulation
Les chercheurs ont observé que bien que GPT-4 ait une certaine compréhension de l'API Python de Blender, sa capacité à générer des scripts Python de Blender basés sur les invites de l'utilisateur fait toujours défaut. D’une part, demander à GPT-4 de créer même un simple modèle 3D (comme un ballon de basket) directement dans Blender semble être une tâche ardue. D'un autre côté, étant donné que l'API Python de Blender dispose de moins de ressources et que les versions de l'API sont mises à jour rapidement, il est facile pour GPT-4 d'abuser de certaines fonctionnalités ou de commettre des erreurs en raison de différences de version. Pour résoudre ces problèmes, l'étude propose la solution suivante : La figure 3 montre l'étude Modèle d'invite générique conçu pour GPT-4. Il comprend des fonctions Blender encapsulées, des outils externes et des commandes utilisateur. Les chercheurs ont défini les normes de taille du monde virtuel dans le modèle et ont fourni des informations sur la position et la perspective de la caméra. Ces informations aident GPT-4 à mieux comprendre la disposition de l'espace tridimensionnel. Ensuite, les instructions correspondantes sont générées en fonction de l'invite saisie par l'utilisateur et guident GPT-4 pour générer le script Blender Python correspondant. Enfin, grâce à ce script, Blender restitue les bords et la profondeur de l'objet et le génère sous forme de séquence d'images. Contenu réécrit : réaliser des vidéos qui suivent les lois de la physique Cette étude vise à générer, sur la base des invites fournies par l'utilisateur et des conditions de mouvement physique correspondantes fournies par Blender, des vidéos cohérentes avec le texte et visuellement réalistes. À cette fin, l'étude a adopté le modèle de diffusion Propriétés physiques de contrôle
La figure 7 montre trois vidéos montrant le versement d'eau de différentes viscosités dans des tasses. Lorsque la viscosité de l'eau est faible, l'eau qui coule entre en collision avec l'eau dans la tasse et fusionne, formant un phénomène d'écoulement turbulent complexe. À mesure que la viscosité augmente, le débit d'eau devient plus lent et les liquides commencent à coller les uns aux autres Comparaison avec la méthode de base Dans la figure 1, GPT4Motion est comparé visuellement à d'autres méthodes de base. Il est évident que les résultats de la méthode de base ne correspondent pas aux invites de l'utilisateur. DirecT2V et Text2Video-Zero présentent des défauts de fidélité de texture et de cohérence de mouvement, tandis qu'AnimateDiff et ModelScope améliorent la fluidité de la vidéo, mais il reste encore place à l'amélioration de la cohérence de texture et de la fidélité de mouvement. Par rapport à ces méthodes, GPT4Motion peut générer des changements de texture fluides lors de la chute et du rebond du ballon de basket après une collision avec le sol, ce qui semble plus réaliste Comme le montre la figure 8 (première rangée), AnimateDiff et la vidéo générée par Text2Video-Zero présentait des artefacts/distorsions sur le drapeau, tandis que ModelScope et DirecT2V étaient incapables de générer en douceur le dégradé du drapeau flottant au vent. Cependant, comme le montre le milieu de la figure 5, la vidéo générée par GPT4Motion peut montrer le changement continu des rides et des ondulations du drapeau sous l'influence de la gravité et du vent. Les résultats de toutes les lignes de base ne correspondent pas aux invites de l'utilisateur, comme le montre la deuxième ligne de la figure 8. Bien que les vidéos d'AnimateDiff et ModelScope reflètent les changements de débit d'eau, elles ne peuvent pas capturer les effets physiques de l'eau versée dans une tasse. D'un autre côté, la vidéo générée par Text2VideoZero et DirecT2V a créé une tasse qui tremblait constamment. En comparaison, comme le montre la figure 7 (à gauche), la vidéo générée par GPT4Motion décrit avec précision l'agitation lorsque le débit d'eau entre en collision avec la tasse, et l'effet est plus réaliste Les lecteurs intéressés peuvent lire l'article original pour en savoir plus. Beaucoup de contenu de recherche

tissu soufflé dans le vent. Les figures 5 et 6 démontrent la capacité de GPT4Motion à générer un mouvement de tissu sous l’influence du vent. En tirant parti des moteurs physiques existants pour les simulations, GPT4Motion peut générer des vagues et des vagues sous différentes forces de vent. La figure 5 montre le résultat généré par un drapeau agité. Le drapeau affiche des motifs complexes d'ondulations et de vagues dans diverses conditions de vent. La figure 6 montre le mouvement d'un objet en tissu irrégulier, un T-shirt, sous différentes forces de vent. Affecté par les propriétés physiques du tissu, telles que l'élasticité et le poids, le T-shirt tremble et se tord, et développe des rides visibles.



Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment lier des données dans une liste déroulante
Comment lier des données dans une liste déroulante
 Introduction à la signification d'un mot de passe invalide
Introduction à la signification d'un mot de passe invalide
 Analyse comparative de iqooneo8 et iqooneo9
Analyse comparative de iqooneo8 et iqooneo9
 propriété de gradient linéaire
propriété de gradient linéaire
 Introduction au protocole xmpp
Introduction au protocole xmpp
 vue de clé sans fil
vue de clé sans fil
 Qu'est-ce que le fil coin ?
Qu'est-ce que le fil coin ?
 Quelle est la différence entre éclipse et idée ?
Quelle est la différence entre éclipse et idée ?








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



