

Traducteur | Chen Jun
Chonglou
Dans cet article, je vais vous présenter l'apprentissage "quelques coups (Few-shot)" , et concentrez-vous sur la méthode SetFit qui est largement utilisée dans la classification de texte.

Dans l'apprentissage automatique supervisé (Supervised), de grands ensembles de données sont utilisés pour la formation du modèle afin d'affiner le modèle afin de rendre la capacité de prédire avec précision. Une fois le processus de formation terminé, nous pouvons utiliser les données de test pour obtenir les résultats de prédiction du modèle. Cependant, cette approche traditionnelle d’apprentissage supervisé souffre d’un inconvénient majeur : elle nécessite un ensemble de données d’entraînement volumineux et sans erreur. Mais tous les domaines ne sont pas en mesure de fournir de tels ensembles de données sans erreur. C’est pourquoi le concept d’« apprentissage en quelques étapes » est né.
Avant de nous plonger dans le réglage précis du Sentence Transformer (SetFit), il est nécessaire pour nous de passer brièvement en revue le traitement du langage naturel (Traitement du langage naturel, NLP Un aspect important de ) est : "l'apprentissage en quelques étapes".
L'apprentissage en quelques coups signifie : utiliser un ensemble de données d'entraînement limité pour entraîner le modèle. Le modèle peut obtenir des connaissances à partir de ces petites collections appelées ensembles de supports. Ce type d'apprentissage vise à enseigner un modèle en quelques coups pour reconnaître les similitudes et les différences dans les données d'entraînement. Par exemple, au lieu de demander au modèle de classer une image donnée comme un chat ou un chien, nous lui demandons de saisir les points communs et les différences entre les différents animaux. Comme on peut le constater, cette approche se concentre sur la compréhension des similitudes et des différences dans les données d’entrée. C'est pourquoi on l'appelle aussi souvent méta-apprentissage (meta-learning) ou apprendre à apprendre (apprendre à apprendre).
Il convient de mentionner que l'ensemble de support pour l'apprentissage en quelques coups est également appelé k à (k-way) n apprentissage par échantillons (n-shot). Parmi eux, "k" représente le nombre de catégories dans l'ensemble de support. Par exemple, en classification binaire, k est égal à 2. Et "n" représente le nombre d'échantillons disponibles pour chaque catégorie dans l'ensemble de support. Par exemple, si la classification positive a 10 points de données et que la classification négative a également 10 points de données, alors n est égal à 10. En résumé, cet ensemble de supports peut être décrit comme un apprentissage d'échantillons bidirectionnel 10.
Maintenant que nous avons une compréhension de base de l'apprentissage en quelques étapes, apprenons rapidement en utilisant SetFit et effectuons une classification de texte sur des ensembles de données de commerce électronique dans des applications pratiques.
a été développé conjointement par l'équipe de Hugging Face et Intel Labs SetFit, est un outil open source pour quelques- exemple de classification de photos. Vous pouvez trouver des informations complètes sur SetFit dans le lien de la bibliothèque du projet-https://github.com/huggingface/setfit?ref=hackernoon.com.
En termes de résultat, SetFit n'utilise que huit exemples annotés de chaque catégorie dans l'ensemble de données d'analyse des sentiments des avis clients (avis clients, CR). Le résultat est le même que celui du RoBERTa Large réglé sur l'ensemble de formation complet composé de 3 000 exemples. Il convient de souligner qu'en termes de volume, le modèle RoBERTa légèrement optimisé est trois fois plus grand que le modèle SetFit. L'image ci-dessous montre l'architecture SetFit :
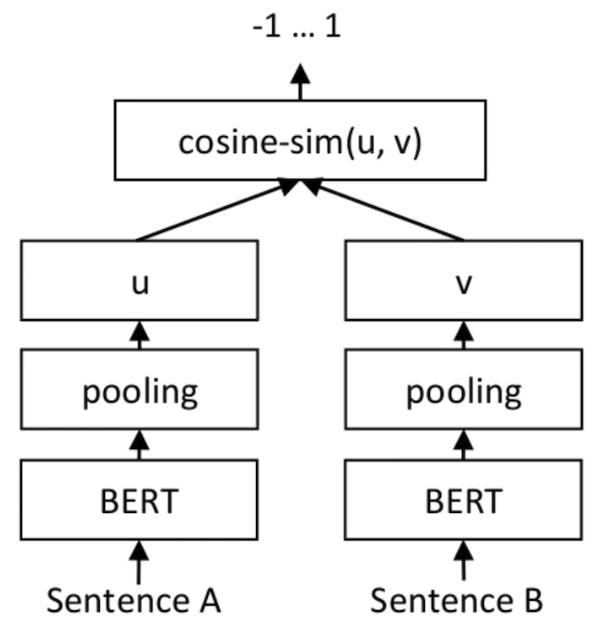
Source de l'image : https://www.php.cn/link/2456b9cd2668fa69e3c7ecd6f51866bf
SetFit est très rapide et efficace. Ses performances sont extrêmement compétitives par rapport aux grands modèles tels que GPT-3 et T-FEW. Voir l'image ci-dessous :
Comparaison du modèle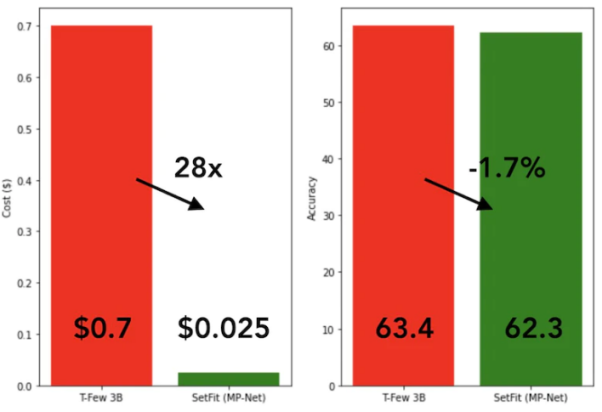 SetFit et T-Few 3B
SetFit et T-Few 3B
Comme le montre la figure ci-dessous, SetFit fonctionne mieux que RoBERTa en apprentissage en quelques coups.
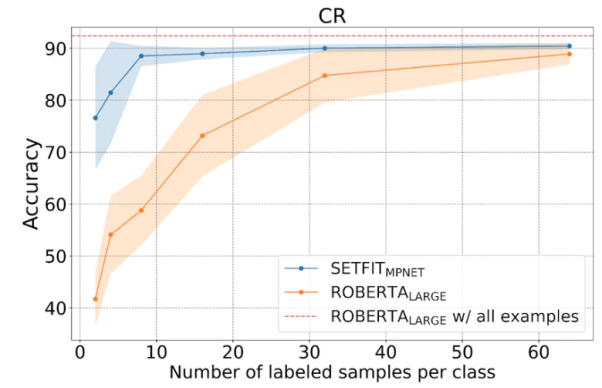
Comparaison entre SetFit et RoBERT, source photo : https://www.php.cn/link/3ff4cea152080fd7d692a8286a587a67
ci-dessous, nous utiliserons un ensemble de données unique sur le commerce électronique composé de quatre catégories différentes : livres, vêtements et accessoires, appareils électroniques et articles d'ameublement. L'objectif principal de cet ensemble de données est de classer les descriptions de produits des sites Web de commerce électronique dans des balises spécifiées.
Afin de faciliter l'utilisation de la méthode de formation à quelques échantillons, nous sélectionnerons huit échantillons dans chacune des quatre catégories, ce qui donnera un total de 32 échantillons de formation. Les échantillons restants seront réservés à des fins de tests. En bref, l'ensemble de supports que nous utilisons ici est 4 apprentissage à partir de 8 échantillons. La figure ci-dessous montre un exemple d'ensemble de données de commerce électronique personnalisé :
 Échantillon d'ensemble de données de commerce électronique personnalisé
Échantillon d'ensemble de données de commerce électronique personnalisé
Nous utilisons le nom "all-mpnet-base-v2" Modèles pré-entraînés de Sentence Transformers pour transformer les données textuelles en diverses intégrations vectorielles. Ce modèle peut générer des intégrations vectorielles de dimension 768 pour le texte d'entrée.
Comme indiqué dans la commande suivante, nous allons démarrer SetFit en installant les packages requis dans l'environnement conda (qui est un système de gestion de packages open source et un système de gestion d'environnement).
!pip3 install SetFit !pip3 install sklearn !pip3 install transformers !pip3 install sentence-transformers
Après avoir installé le progiciel, nous pouvons charger l'ensemble de données via le code suivant.
from datasets import load_datasetdataset = load_dataset('csv', data_files={"train": 'E_Commerce_Dataset_Train.csv',"test": 'E_Commerce_Dataset_Test.csv'})Référons-nous à la figure ci-dessous pour voir le nombre d'échantillons d'entraînement et d'échantillons de test.
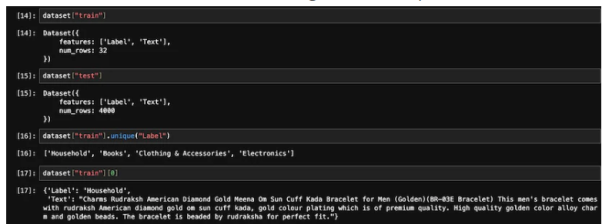 Données de formation et de test
Données de formation et de test
Nous utilisons LabelEncoder du package sklearn pour convertir les étiquettes de texte en étiquettes codées.
from sklearn.preprocessing import LabelEncoder le = LabelEncoder()
Avec LabelEncoder, nous encoderons les ensembles de données d'entraînement et de test et ajouterons les étiquettes encodées à la colonne "Étiquette" de l'ensemble de données. Voir le code ci-dessous :
Encoded_Product = le.fit_transform(dataset["train"]['Label']) dataset["train"] = dataset["train"].remove_columns("Label").add_column("Label", Encoded_Product).cast(dataset["train"].features)Encoded_Product = le.fit_transform(dataset["test"]['Label']) dataset["test"] = dataset["test"].remove_columns("Label").add_column("Label", Encoded_Product).cast(dataset["test"].features)Ci-dessous, nous initialiserons le modèle SetFit et le modèle de transformation de phrases.
from setfit import SetFitModel, SetFitTrainer from sentence_transformers.losses import CosineSimilarityLossmodel_id = "sentence-transformers/all-mpnet-base-v2" model = SetFitModel.from_pretrained(model_id)trainer = SetFitTrainer( model=model, train_dataset=dataset["train"], eval_dataset=dataset["test"], loss_class=CosineSimilarityLoss, metric="accuracy", batch_size=64, num_iteratinotallow=20, num_epochs=2, column_mapping={"Text": "text", "Label": "label"})Après avoir initialisé les deux modèles, nous pouvons maintenant appeler le programme d'entraînement.
trainer.train()
Après avoir terminé 2 cycles de formation (époques), nous évaluerons le modèle entraîné sur eval_dataset.
trainer.evaluate()
Après les tests, notre modèle d'entraînement a atteint la plus haute précision de 87,5%. Bien que la précision de 87,5% ne soit pas élevée, après tout, notre modèle n'a utilisé que 32 échantillons pour la formation. En d'autres termes, compte tenu de la taille limitée de l'ensemble de données, atteindre une précision de 87,5 % sur l'ensemble de données de test est en fait assez impressionnant.
De plus, SetFit peut également enregistrer le modèle entraîné sur le stockage local pour un chargement ultérieur à partir du disque pour des prédictions futures.
trainer.model._save_pretrained(save_directory="SetFit_ECommerce_Output/")model=SetFitModel.from_pretrained("SetFit_ECommerce_Output/", local_files_notallow=True)Le code suivant montre les résultats de prédiction basés sur de nouvelles données :
input = ["Campus Sutra Men's Sports Jersey T-Shirt Cool-Gear: Our Proprietary Moisture Management technology. Helps to absorb and evaporate sweat quickly. Keeps you Cool & Dry. Ultra-Fresh: Fabrics treated with Ultra-Fresh Antimicrobial Technology. Ultra-Fresh is a trademark of (TRA) Inc, Ontario, Canada. Keeps you odour free."]output = model(input)
On peut voir que la sortie de prédiction est 1 et que la valeur LabelEncoded de l'étiquette est "Vêtements et Accessoires" . Les modèles d’IA traditionnels nécessitent une grande quantité de ressources de formation (y compris du temps et des données) pour produire un niveau de sortie stable. En revanche, notre modèle est à la fois précis et efficace.
À ce stade, je pense que vous maîtrisez fondamentalement le concept « d'apprentissage en quelques coups » et comment utiliser SetFit pour la classification de texte et d'autres applications. Bien sûr, afin d'acquérir une compréhension plus approfondie, je vous recommande fortement de choisir un scénario réel, de créer un ensemble de données, d'écrire le code correspondant et d'étendre le processus à l'apprentissage zéro-shot et à l'apprentissage single-shot.
Julian Chen est le rédacteur en chef de la communauté 51CTO. Il a plus de dix ans d'expérience dans la mise en œuvre de projets informatiques, est doué pour gérer les ressources et les risques internes et externes et est concentré. Partager les connaissances et l'expérience en matière de sécurité des réseaux et de l'information
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 ajouter l'utilisation
ajouter l'utilisation
 Qu'est-ce que CONNECTION_REFUSED ?
Qu'est-ce que CONNECTION_REFUSED ?
 quelle est l'adresse mac
quelle est l'adresse mac
 Quel logiciel est Flash ?
Quel logiciel est Flash ?
 Que faire si le jeton de connexion n'est pas valide
Que faire si le jeton de connexion n'est pas valide
 Comment afficher le HTML au centre
Comment afficher le HTML au centre
 Quelles sont les vulnérabilités courantes de Tomcat ?
Quelles sont les vulnérabilités courantes de Tomcat ?
 Comment supprimer mon adresse WeChat
Comment supprimer mon adresse WeChat
 Comment télécharger le fichier FLV
Comment télécharger le fichier FLV








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



